上周经过一番折腾,Flink on Kubernetes 的环境终于部署完成。这算是我在技术探索上迈出的一小步,脱离了熟悉的舒适区。
环境既然搭建好了,接下来自然要验证其成色,看看这些天投入的精力是否值得。因此,我决定提交几个生产级的 Flink 应用到这套环境上进行测试,检验其实际表现。
先说结论:表现与预期大致相符,但相比相同场景下的 Flink on YARN,体验上确实存在一些差距,主要体现在稳定性方面。
(本次测试基于 Flink 1.19 + Kubernetes 1.21 版本)
0. 测试方式
为了让结论更具说服力,我向这个 K8s 集群提交了超过 20 个真实的 Flink 任务。这些任务的目标,是将 MongoDB 中的数据同步至 Doris 数据仓库。
本次测试采用 Flink Session on Kubernetes 模式进行(具体部署方法可参考上一期内容):
在使用过程中,我特意将其与 Flink on YARN 的 Session 模式进行了对比。从操作流程来看,两者几乎没有区别。
然而,经过反复多次的任务提交和压力测试,差异还是显现了出来。
最明显的区别在于:Flink on YARN 在任务运行的“稳定性”表现上,要优于 Flink on Kubernetes。
换言之,完全相同的 Flink 任务(任务类型和数量保持一致),提交到 Kubernetes 后,运行一段时间后有概率会失败。而提交到 YARN 集群,则几乎不会出现这个问题。
在这次测试中,20 多个任务分多次提交到 K8s 后,在我眼皮底下失败的任务就有 3 个。而同样的任务提交到 YARN 后,暂时没有发现此类问题。
1. 失败案例分析
下面是被我捕捉到的,3 个提交到 K8s 后不久即失败的 Flink 任务。
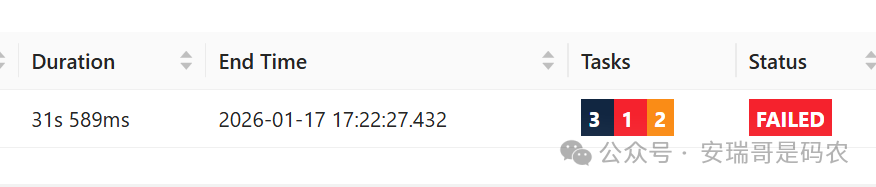
1.1 案例一:TaskManager 神秘消失
任务运行了不到 1 分钟,状态就变成了失败:
随后,我立刻打开 Flink UI 界面查看日志,发现了如下错误:

提交 Flink 任务时,明明分配了对应的 TaskManager,我当时还特意确认过。但不知为何,一眨眼的功夫,这个编号为 51 的 TaskManager 就“消失”了,这非常奇怪。
我确认没有手动终止或取消这个任务。关键是,同一时期创建的其他几个 TaskManager 都运行正常,唯独这一个不知为何提前退出了。
1.2 案例二:Slot 分配异常
首先声明,我的这几台 K8s 服务器资源相当充裕。集群由 5 台物理机构成,每台配置如下:
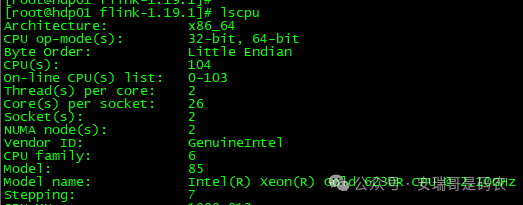
从系统负载来看,CPU 资源也非常空闲:

然而,即便是这样的高配置,居然还是因为 CPU 资源分配问题,导致同一个任务失败了两次。
第一次,运行了不到半分钟:

第二次,运行了不到一分钟:

翻看日志,错误信息如下:
Caused by: org.apache.flink.util.FlinkExpectedException: TaskExecutor pekko.tcp://flink@10.244.4.4:6122/user/rpc/taskmanager_0 has no more allocated slots for job 3b79954faad1a4fd805c94654b697c80.
这上哪说理去?不过好在,任务重启后就能恢复正常。
但同样的任务,提交到 YARN 集群运行,则基本不会出现这种问题,至少在我的集群环境中从未遇到。
2. 使用过程中的两个常见问题
2.1 新增节点无法调度问题
这是什么意思呢?
我最初创建的 K8s 集群只有 3 个节点(1 个 Master,2 个 Slaver)。为了提升集群的处理能力,后续我又增加了 2 个 Slaver 节点,目的是在运行更高并行度的 Flink 任务时,有更多机器可以分担负载。
在 Kubernetes 中添加 Slaver 节点,原则上只需要在目标机器上执行 kubeadm join 命令即可(当然,前提是已安装 kubeadm 和 kubectl)。例如:
kubeadm join 192.168.xxx.xxx:6443 --token brezio.lqxxxxxxxxxqi9 \
--discovery-token-ca-cert-hash sha256:9bfe3xxxxxxaeeafa7827fca7876xxxxxxx98ef02d4eb55783d
查看集群节点状态,确认新增节点已就绪:
[root@hdp01 flink-1.19.1]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
hdp01.xxxx.xx Ready control-plane,master 3d23h v1.21.0
hdp02.xxxx.xx Ready <none> 3d23h v1.21.0
hdp03.xxxx.xx Ready <none> 3d23h v1.21.0
hdp05.xxxx.xx Ready <none> 9h v1.21.0
hdp06.xxxx.xx Ready <none> 9h v1.21.0
但是,当我提交一个并行度为 6 的 Flink 任务后,观察到的 Pod 启动情况却是这样的:
[root@hdp01 flink-1.19.1]# kubectl get pods -n flink -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
flink pod/my-first-flink-cluster-79c9db8fdb-8hk7g 1/1 Running 0 2m11s 10.244.2.53 hdp03.xxxx.xx <none> <none>
flink pod/my-first-flink-cluster-taskmanager-1-1 1/1 Running 0 39s 10.244.1.43 hdp02.xxxx.xx <none> <none>
flink pod/my-first-flink-cluster-taskmanager-1-2 1/1 Running 0 39s 10.244.2.55 hdp03.xxxx.xx <none> <none>
flink pod/my-first-flink-cluster-taskmanager-1-3 1/1 Running 0 39s 10.244.1.42 hdp02.xxxx.xx <none> <none>
flink pod/my-first-flink-cluster-taskmanager-1-4 1/1 Running 0 39s 10.244.1.41 hdp02.xxxx.xx <none> <none>
flink pod/my-first-flink-cluster-taskmanager-1-5 1/1 Running 0 39s 10.244.2.54 hdp03.xxxx.xx <none> <none>
flink pod/my-first-flink-cluster-taskmanager-1-6 1/1 Running 0 39s 10.244.2.56 hdp03.xxxx.xx <none> <none>
所有 TaskManager Pod 都挤在 hdp02 和 hdp03 这两个旧节点上,新增的两个 Slaver 节点完全成了摆设(后续多个任务亦是如此)。关键是没有产生任何报错,这就比较尴尬。
咨询 AI 得到的答案,无非是节点被打上了“污点”标签或资源不足等,但这些原因并不符合实际情况。最终还得靠自己排查。
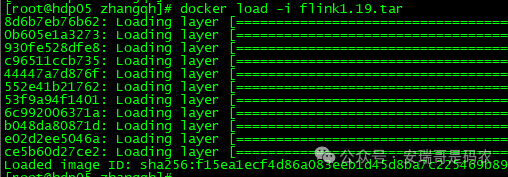
一番摸索后,问题根源找到了:新增节点上缺少 Flink 运行所需的 Docker 镜像,且已有镜像的名称不符合预期。
由于网络问题无法直接拉取,需要手动加载镜像文件:
但这还不够,加载后镜像的名称不符合 K8s 的预期:

还需要为镜像重新打上正确的标签:
至此,新增节点无法调度的问题才得以解决。
回想 Flink on YARN 的部署模式,就没有这么繁琐。参与计算的节点本身并不需要预装 Flink 环境,由 YARN 统一分发和管理,这正是其 容器化 资源调度优势的体现之一。
2.2 客户端配置问题
在使用 Flink on YARN 时,我们只需要在提交任务的节点上准备好 Flink 安装包,并配置好 YARN 的环境变量即可。
但在 Kubernetes 环境下,要求则更为复杂一些。如上一节所述,所有需要运行 Flink TaskManager Pod 的节点,都必须预先准备好 Flink 的 Docker 运行镜像。
而对于提交 Flink 任务的客户端节点来说,除了需要 Flink 安装包外,还必须配置一个关键文件。否则,客户端将无法找到 K8s 集群的 API Server:
[root@hdp06 ~]# kubectl get nodes
The connection to the server localhost:8080 was refused - did you specify the right host or port?
这个配置文件的目的,是让当前客户端节点能够定位到 K8s Master。其作用类似于 Flink on YARN 中配置 HADOOP_CONF_DIR,目的是让提交的任务能够找到 ResourceManager。
具体做法是,将 K8s Master 节点上的 /etc/kubernetes/admin.conf 文件,复制到目标客户端节点的 ~/.kube/config 路径下:
scp /etc/kubernetes/admin.conf flink@hdp0X.xxxx.xx:~/.kube/config
此操作无需额外步骤,效果立竿见影。这充分体现了在 云原生 环境下,对基础设施访问权限的集中化管理需求。
3. 总结与展望
经过数天真实 Flink 任务的运行测试,并与相同模式下的 on YARN 进行对比后,我发现 Flink on Kubernetes 在执行效率、运行过程的稳定性以及集群无缝扩容的便捷性方面,目前的表现确实略逊一筹。
当然,这并非是说 Flink on Kubernetes 难以使用。相反,它为我提供了一种运行 Flink 任务的全新体验,我对此并不排斥。许多初期的不稳定因素,或许可以通过更细致的配置调优和版本升级来解决。
那么,Flink on Kubernetes 到底是“夯”还是“拉”?这个话题,我们留到下一期,再看看它在其他类型任务以及更复杂 大数据 场景下的表现如何。如果你对相关实践经验感兴趣,欢迎前往 云栈社区 参与更多讨论。
 发表于 2026-1-21 03:28:58
|
查看: 149|
回复: 0
发表于 2026-1-21 03:28:58
|
查看: 149|
回复: 0
