湖仓一体技术正进入“去商业化”的新阶段。面对Databricks的高成本、Delta Lake的沉重以及Iceberg陡峭的学习曲线,许多企业,尤其是中小企业,都在迫切寻找一个轻量、开源且支持高并发实时写入的解决方案。
Apache Paimon(原 Flink Table Store)正是在此背景下应运而生。它源于阿里内部五年的打磨,于2024年成为Apache顶级项目,其核心优势非常明确:
- 原生支持 Flink CDC 实时入湖。
- 兼容 Hive、Trino、Spark、StarRocks 等多种查询引擎。
- 单表支持每秒10万+ Upsert操作。
在某跨境电商(日均订单300万+)的实际落地中,我们使用Paimon成功替换了原有的 Hive + Kafka + MySQL 三套独立系统。成效显著:实时看板的数据延迟从小时级优化至秒级,年基础设施成本下降了约70%。当然,过程并非一帆风顺,我们也曾因CDC配置不当导致数据重复,这些经验教训后文会详细拆解。
今天,我们不空谈概念,只聚焦于可复制的实践,拆解Paimon在实时湖仓场景下的正确打开方式。
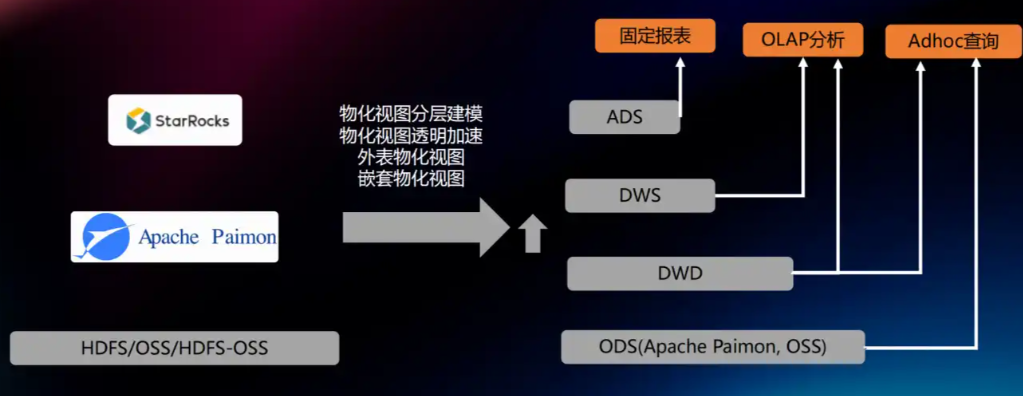
一、为什么选择Paimon?2026年的三大核心诉求
-
实时Upsert必须高效
传统方案如 Kafka + Flink + HBase 架构复杂,维护成本高。Paimon的创新在于能够直接在对象存储(如OSS/S3)上实现高效的主键更新,无需引入额外的数据库,简化了架构。
-
成本压力倒逼存算分离
Paimon将数据存储在廉价的OSS/S3上,计算则可采用Flink Serverless等弹性资源。实践表明,其存储成本仅为传统HDFS的 1/3,这对控制日益增长的数据成本至关重要。
-
统一离线与实时数据入口
这是消灭冗余的Lambda架构的关键。同一张Paimon表,可以被Flink流式持续写入,同时也能被Trino或StarRocks进行近实时查询(延迟通常小于30秒),真正实现一份数据、多种处理模式。
结论很清晰:Paimon并非“又一个数据湖格式”,而是一个为实时场景深度优化的湖仓存储引擎。
二、实战案例:使用Paimon重构用户行为分析湖仓
项目背景
原系统架构复杂且低效:
- 离线层:Hive(T+1产出)
- 实时层:Kafka + Flink + Redis(用于状态存储)
- 查询层:ClickHouse(需要从离线、实时链路双写)
主要痛点在于数据链路复杂导致运维成本高、实时与离线数据口径难以对齐,以及Redis作为状态存储带来的内存成本飙升。
新架构目标
- 统一实时与离线数据湖仓。
- 支持按用户ID(User_id)进行主键Upsert(例如实时更新用户标签)。
- 确保查询端延迟小于5秒。
| 2026年主流技术选型 |
组件 |
选型 |
| 湖仓存储 |
Apache Paimon 1.2+ |
| 计算引擎 |
Flink 1.18 + CDC 3.0 |
| 查询引擎 |
StarRocks 3.2(通过Hive Metastore接入Paimon) |
| 底层存储 |
阿里云OSS(或AWS S3) |
三、四步落地Paimon(完整可复现流程)
第一步:创建支持主键Upsert的Paimon表
在Flink SQL Client中,我们首先创建Catalog和表。关键在于表定义中的主键和合并引擎设置,这决定了它如何处理CDC变更数据。
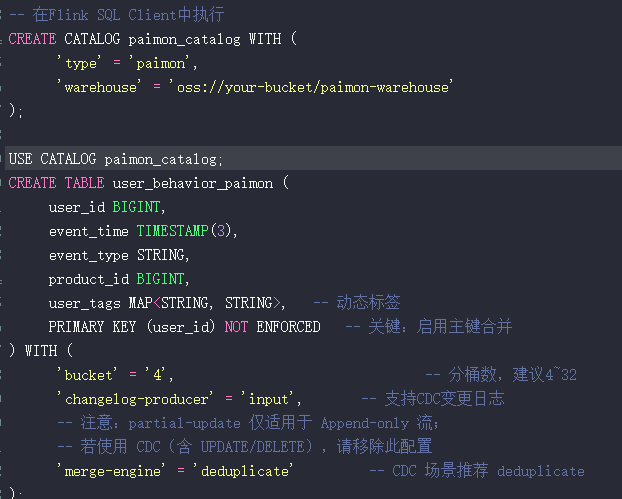
CREATE CATALOG paimon_catalog WITH (
'type' = 'paimon',
'warehouse' = 'oss://your-bucket/paimon-warehouse'
);
USE CATALOG paimon_catalog;
CREATE TABLE user_behavior_paimon (
user_id BIGINT,
event_time TIMESTAMP(3),
event_type STRING,
product_id BIGINT,
user_tags MAP<STRING, STRING>, -- 动态标签
PRIMARY KEY (user_id) NOT ENFORCED -- 关键:启用主键合并
) WITH (
'bucket' = '4', -- 分桶数,建议4~32
'changelog-producer' = 'input', -- 支持CDC变更日志
-- 注意:partial-update 仅适用于 Append-only 流;
-- 若使用 CDC(含 UPDATE/DELETE),请移除此配置
'merge-engine' = 'deduplicate' -- CDC 场景推荐 deduplicate
);
关键参数说明:
PRIMARY KEY:这是开启Upsert能力的前提。merge-engine = ‘deduplicate’:适用于CDC流,系统将根据主键保留最新记录。bucket:直接影响写入并发度,需根据主键的分布情况合理设置。
第二步:配置Flink CDC实时同步数据入湖
接下来,我们创建CDC源表,将MySQL的binlog变更实时同步到Paimon中。
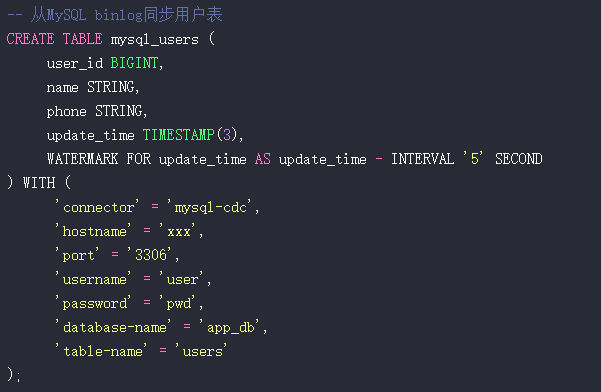
-- 从MySQL binlog同步用户表
CREATE TABLE mysql_users (
user_id BIGINT,
name STRING,
phone STRING,
update_time TIMESTAMP(3),
WATERMARK FOR update_time AS update_time - INTERVAL ‘5’ SECOND
) WITH (
‘connector’ = ‘mysql-cdc’,
‘hostname’ = ‘xxx’,
‘port’ = ‘3306’,
‘username’ = ‘user’,
‘password’ = ‘pwd’,
‘database-name’ = ‘app_db’,
‘table-name’ = ‘users’
);
然后,通过一个简单的INSERT INTO SELECT语句,将CDC数据写入Paimon表。Paimon会自动根据主键进行Upsert。

-- 写入Paimon(自动Upsert)
INSERT INTO user_behavior_paimon
SELECT
user_id,
update_time AS event_time,
‘profile_update’ AS event_type,
-1L AS product_id,
MAP[‘name’, name, ‘phone’, phone] AS user_tags
FROM mysql_users
核心避坑点:必须保证CDC事件的有序性!如果MySQL主从切换或网络抖动导致binlog事件乱序到达,Upsert的结果将不可预测。强烈建议在Flink CDC任务中启用 exactly-once 语义,并在Paimon表配置中设置 ’sequence.field’ = ‘update_time’,以时间字段作为顺序保证。
第三步:集成StarRocks实现高性能查询
StarRocks 3.2版本提供了良好的Hive Metastore兼容性,可以无缝查询已注册到HMS的Paimon表,为实时分析提供强大助力。

-- 前提:Paimon 表已注册到 Hive Metastore
CREATE EXTERNAL CATALOG hive_catalog
PROPERTIES (
“type” = “hive”,
“hive.metastore.uris” = “thrift://hms:9083”
);
-- 直接查询
SELECT user_id, user_tags[‘name’]
FROM hive_catalog.paimon_db.user_behavior_paimon
WHERE event_time > NOW() - INTERVAL 1 HOUR;
注意事项:需要将Paimon的客户端JAR包放入StarRocks FE和BE节点的lib目录中,并确保StarRocks集群能够访问Hive Metastore服务。
第四步:必要的运维治理与监控
- 小文件合并:定期执行压缩命令,例如
CALL sys.compact(‘default’, ‘user_behavior_paimon’)。
- 数据生命周期管理:通过表属性设置数据过期,如
’partition.expiration-time’ = ‘7 d’。
- 数据血缘:可考虑接入Apache Atlas与Paimon Metastore,实现数据血缘的追踪。
四、三大避坑指南(来自实战的血泪教训)
坑1:主键设计不合理导致写放大
- 问题:若使用高基数的业务流水ID(如
event_id)作为主键,每条记录都是新的,完全丧失了Upsert的意义,导致存储急剧膨胀。
- 对策:主键必须是业务实体标识,如
user_id、order_id、product_id 等。
坑2:Bucket数量设置不当引发性能问题
- 问题:
bucket=1 会导致所有写入串行,性能瓶颈;bucket 设置过大(如1000)则会产生大量小文件,影响查询性能。
- 对策:
- 写入并发度约等于bucket数量。
- 建议公式:
bucket = ceil(预期写QPS / 1000)。对于大多数场景,设置为 4~32 之间即可获得良好平衡。
坑3:忽略CDC事件顺序导致最终数据错乱
- 问题:这是最危险的陷阱。MySQL集群故障切换、网络分区等情况可能导致binlog事件乱序到达处理层。
- 对策:
- 在Flink CDC任务配置中务必启用
exactly-once 语义。
- 在Paimon表属性中设置
’sequence.field’ = ‘update_time’,告诉Paimon用哪个字段来判断记录的新旧,从而保证乱序下的最终一致性。
五、展望:Paimon 2026-2027的演进方向
- 向量化查询加速:Paimon 1.3+ 版本将加强对Parquet列式存储的支持,并引入向量化读取,预计能使查询性能提升 3~5倍。
- AI特征湖原生支持:为迎接AI与大数据融合的趋势,Paimon计划内置向量数据类型(如
VECTOR<FLOAT, 128>)并支持近似最近邻(ANN)索引,直接服务于AI特征存储与检索。
- 跨云数据共享:正在探索类似Delta Sharing的开放协议,实现Paimon湖表的安全跨云共享,让合作伙伴能够直接读取数据而无需繁琐的迁移拷贝。
结语:Paimon是2026年务实之选
Paimon的成功,并非因其技术最为炫酷,而在于它精准地击中了当前企业大数据建设的核心痛点:用尽可能简单的架构,解决实时Upsert与成本控制两大难题。同时,它全面拥抱Flink、StarRocks等主流开源生态,大幅降低了中小型企业玩转湖仓一体的门槛。
给你的行动建议:
- 从小范围试点开始:选择用户画像表、商品状态表等场景进行验证。
- 优先替换高成本链路:重点针对那些依赖“Kafka + Redis”的复杂实时计算场景。
- 储备核心技能:团队中至少需要有一位同学深入掌握 Flink 与 Paimon 的调优技巧。
希望这份融合了实战经验与未来展望的路径图,能帮助你在数据架构演进中少走弯路。如果你对实时数仓或数据湖技术有更多想法,欢迎在云栈社区与更多的技术同行交流探讨。
 发表于 2026-2-6 06:00:38
|
查看: 160|
回复: 0
发表于 2026-2-6 06:00:38
|
查看: 160|
回复: 0
