在物流行业,每一秒的决策都关乎千万包裹的流转效率。对于日均处理数亿订单的京东物流而言,其一站式自助分析平台 UData 承载着超过 10万一线业务人员 的实时分析需求。然而,随着数据量激增至 日均新增行数十亿、更新次数达百亿量级,传统的存算一体 StarRocks 集群正面临严峻挑战:硬件成本飙升、运维复杂度高、资源利用率低下。
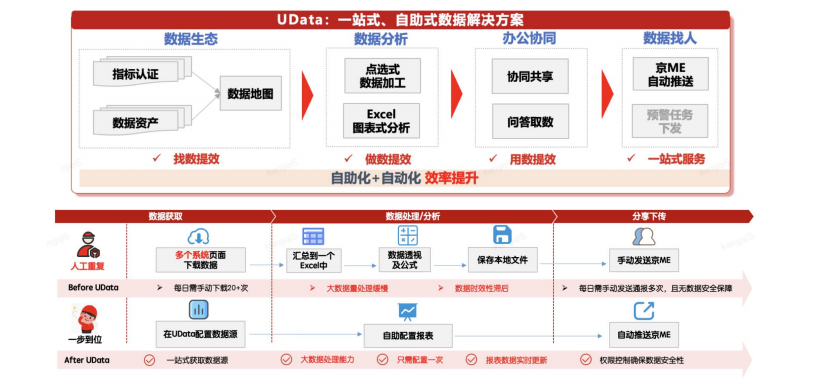
正如技术峰会上所言:“海量数据近实时写入,长周期留存与查询 -> 降低存储成本,保证用户体验”。本文将深入剖析京东物流如何通过 存算分离 StarRocks 架构升级,在保障 5分钟内数据新鲜度 和 P95/P99查询性能持平 的前提下,实现 单TB存储成本降低90%、计算资源成本降低30% 的成果,并为同行提供一份可落地的实战指南。
一、 痛点诊断:为什么存算一体走到了尽头?
京东物流的原有 StarRocks 架构是典型的存算一体模式:

- 数据规模:30+集群,600+节点,承载800+内表
- 访问压力:峰值 RPS 超过800,数据流量峰值达500+ GBPS
但这种架构带来了三大核心问题:
- 高昂的存储成本:
百TB级的历史数据(如180天的百亿级订单日志)需要长期留存以供分析,但存算一体模式下,存储必须与昂贵的计算节点绑定,导致大量SSD资源被冷数据占用,成本居高不下。
- 僵化的资源伸缩:
业务流量存在明显波峰波谷(如大促期间),但存算一体集群扩缩容需数小时甚至数天,无法做到按需弹性,造成资源浪费或性能瓶颈。
- 沉重的运维负担:
运维团队需同时管理数百台物理机的硬件、网络、磁盘,故障定位和容量规划极其困难。
核心诉求:构建一个 “计算无状态、存储可共享、弹性秒级” 的新架构,在不牺牲用户体验的前提下,实现极致降本。
二、 解决之道:京东云原生存算分离架构全景图
京东物流并未盲目上云,而是依托 京东云 JDOS K8s 平台,设计了一套务实且高可用的存算分离架构:
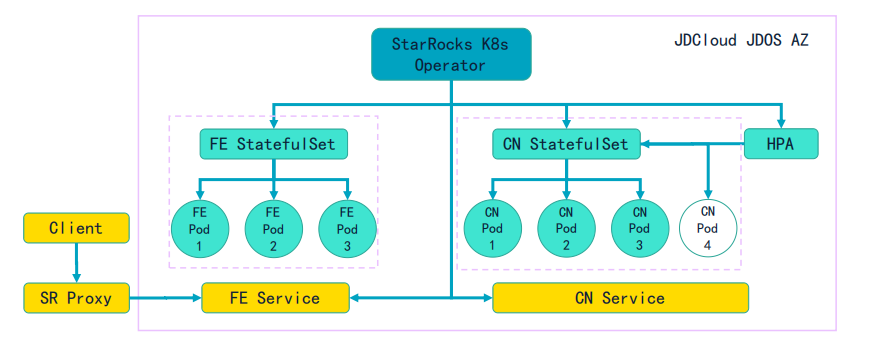
核心组件:
- 计算层(CN):无状态的 StarRocks Compute Node,部署在 K8s StatefulSet 中,由 HPA 实现自动扩缩容。这正是 云原生 理念的典型实践。
- 存储层:京东云 OSS 对象存储,作为统一、低成本、高可靠的底座。
- 元数据层(FE):有状态的 Frontend 节点,同样运行在 K8s 上,负责元数据管理和查询调度。
- 接入层:SR Proxy,提供灵活的流量切分和负载均衡能力。
架构优势:
- 极致弹性:计算资源可根据负载 秒级扩缩容,从容应对流量洪峰。
- 成本分离:热数据缓存在 CN 节点 SSD,温/冷数据下沉至 OSS,存储成本降至存算一体的 1/10。
- 双AZ容灾:依托 JDOS K8s,实现跨可用区部署,保障高可用。
三、 实施流程:四步走战略,稳扎稳打
京东物流的迁移并非一蹴而就,而是分阶段推进:
-
集群部署与验证(初期):
- 环境搭建:在 JDOS K8s 上部署 FE/CN StatefulSet,配置 SR Proxy。
- 网络优化:为 CN 节点配备 万兆网卡及本地 SSD,确保网络和缓存 I/O 性能。
- 存储映射:设计 大表独享 Bucket、小表共享 Bucket 的策略,规避 OSS 带宽和 IOPS 限制。
-
实时写入链路打通(核心):
- 低代码平台赋能:通过自研平台,1~5分钟 即可配置 Flink Job,实现 MQ -> StarRocks Stream Load。
- 参数调优:为存算分离 Sink 自动配置宽松的攒批参数(如
sink.buffer-flush.max-bytes=900MB),在保证 5分钟内数据新鲜度 的前提下提升吞吐。
-
查询性能与稳定性压测:
- Cache 策略:设置 20天 Cache TTL,确保热点数据命中缓存。
- 结果验证:在 5个CN节点 规模下,Cache hit 场景的 P95/P99 查询延迟与同规模存算一体集群持平;即使 Cache miss,查询响应也极少超过1分钟,远快于 Hive。
-
规模化推广与治理(当前):
- 成果量化:已接入 10+张大表,总数据量100TB+,单表最大超10TB。
- 成本收益:每TB存储成本降低90%,同等查询量下计算资源成本降低30%。
四、 关键优化:性能与稳定的五大核心技术
文件详细披露了京东物流在调优上的硬核实践:
-
Compaction 调优:
- 问题:存算分离下,Compaction I/O 压力更大。
- 对策:根据 CN 节点规格,调大 Compaction 线程数和队列;降低每次 Cumulative Compaction 的 Rowset 数,使任务更快完成。
-
Vacuum 调优:
- 问题:Vacuum 不及时会导致 OSS 上残留大量垃圾文件。
- 对策:监控
queued_delete_file_tasks 指标;根据 CN 规格和 OSS 吞吐,调整 release_snapshot 线程池容量和分区并行度。
-
分区查询硬限制:
- 问题:海量历史数据下,用户易发起全表扫描,拖垮集群。
- 对策:为 LakeTable 添加参数,硬性限制单个查询可 Scan 的分区数,但放行带 Tablet Hint 的统计信息收集任务,保障 CBO 准确性。
-
统计信息收集优化:
- 问题:默认全量收集在业务高峰期影响大表查询。
- 对策:对大表,固定在业务低峰期进行全量收集,平时采用抽样采集。
-
OSS 性能保障:
- 问题:担心对象存储成为瓶颈。
- 对策:得益于 StarRocks 与京东云 OSS 的深度协同优化,Bucket 吞吐无瓶颈,100TB+数据平稳运行。
五、 避坑指南:京东物流踩过的那些“深水雷”
-
攒批参数配置不当:
初始使用存算一体的严格参数,导致 Stream Load 频繁失败。
对策:为存算分离 Sink 专门设计更宽松的容错和攒批策略。
-
Vacuum 导致元数据404:
查询高峰期,若 Vacuum 过于激进,会提前删除 meta 文件,导致查询报错。
对策:适当放宽历史版本区间,确保正在被查询的版本不会被误删。
-
分区裁剪失效:
用户习惯性不加分区过滤,直接查询大表。
对策:强制实施分区查询硬限制,从源头杜绝“炸集群”行为。
六、 未来展望:存算分离的下一程
京东物流的存算分离之旅并未止步。文件最后展望了四大方向:
- 更灵活的扩缩容 (VPA):
从 HPA(水平扩缩容)迈向 VPA(垂直扩缩容),实现 CPU/Memory 的精细化弹性。
- 更高效的主动、分级缓存:
探索基于查询模式的智能预热和多级缓存策略,进一步提升 Cache Hit Rate。
- 实验特性支持:
引入 行列混存 (Hybrid Row-Column) 和 GIN 索引,加速特定场景(如高并发点查、全文检索)。
- Stream Load 任务合并:
优化写入链路,减少小文件产生,降低后续 Compaction 压力。
结语
京东物流的存算分离 StarRocks 实践,不是一场为了技术而技术的秀,而是一次 以业务价值为导向、以成本效益为核心 的深度变革。它证明了:存算分离不是牺牲性能换成本,而是通过架构革新,实现性能、成本、弹性的三重飞跃。
对于所有正在经历数据量爆炸式增长的企业而言,京东物流的经验——从架构选型到参数调优、从稳定性保障到未来规划——都是一份宝贵的行动纲领。正如文件所强调的,这场变革的核心在于 “降本”与“增效”的完美平衡。
数据基础设施的终局,不是堆砌最昂贵的硬件,而是以最优雅的架构,支撑最敏捷的业务。在这条路上,京东物流的探索为大数据处理平台的云原生化转型提供了极具价值的参考。更多关于云原生与数据库技术的深度讨论,欢迎访问 云栈社区 进行交流。 |  发表于 2026-1-26 11:31:39
|
查看: 163|
回复: 0
发表于 2026-1-26 11:31:39
|
查看: 163|
回复: 0
