ETL(抽取、转换、加载)工具是企业数据集成与治理落地的核心支撑,它直接决定了数据链路的稳定性、处理效率与复用性。面对市场上功能侧重、技术架构、适用场景差异巨大的众多工具,到底应该如何选择?
答案很简单:没有绝对的最优工具,关键在于是否与你的业务需求高度适配。本文将深入盘点市面上10款主流的ETL工具,从核心功能、优缺点到适用场景,为你提供一份清晰的选型地图。

一、选型前的核心考量维度
在盲目比较工具之前,明确自身需求更为关键。梳理清楚以下5个维度,选型方向自然清晰。
- 业务适配:明确你的数据类型(结构化、半结构化、非结构化)、处理时效要求(实时、准实时、批量)以及处理的数据量级(GB、TB、PB)。
- 技术能力:重点关注数据源兼容性、转换逻辑的灵活性、任务调度的稳定性以及系统的扩展性(是否支持分布式、集群)。
- 易用性:工具的可视化程度、低代码支持情况以及学习曲线,这直接关系到团队的开发效率和运维成本。
- 综合成本:除了软件授权费用,还需考虑实施、后期运维、团队培训等隐形成本。
- 安全与合规:数据加密、细粒度权限管理、操作审计日志,以及国产化适配(信创)要求,在金融、政务等行业尤为重要。
- 生态与支持:社区的活跃度、厂商的技术支持响应速度,确保遇到问题时能够获得及时有效的帮助。
二、10款主流ETL工具深度测评
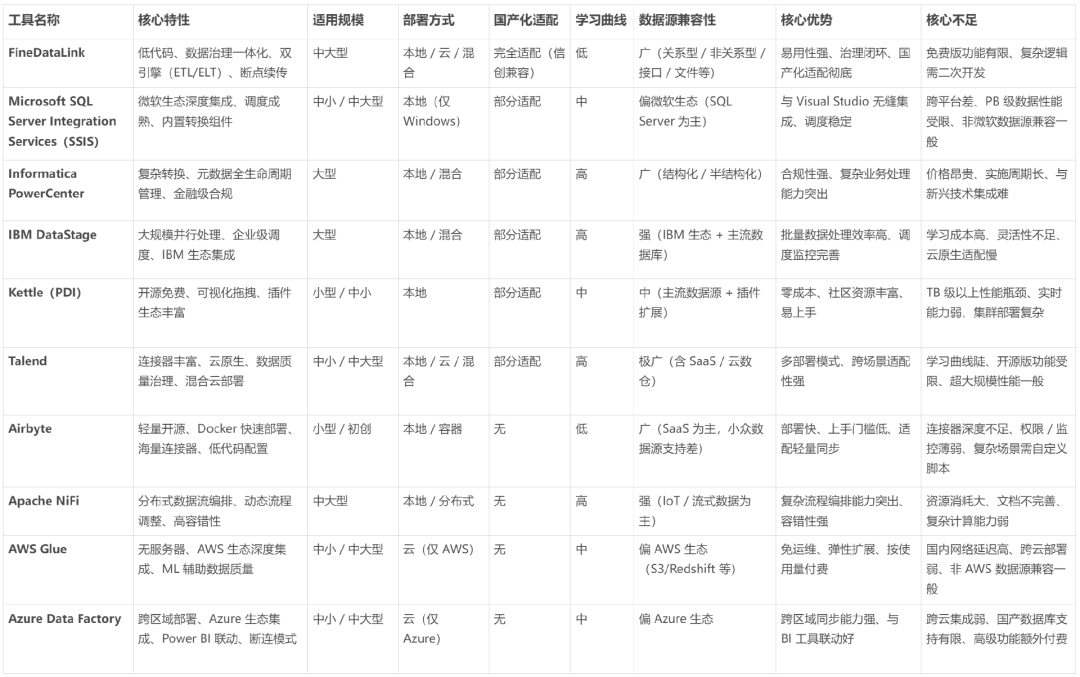
1. FineDataLink
定位:国产数据集成与治理一体化平台,主打低代码与易用性。
核心功能:
- 双引擎驱动:支持高并发实时数据同步与批量ETL/ELT定时计算,具备毫秒级同步能力,并支持表结构变更同步、断点续传,保障大数据场景下的稳定性。
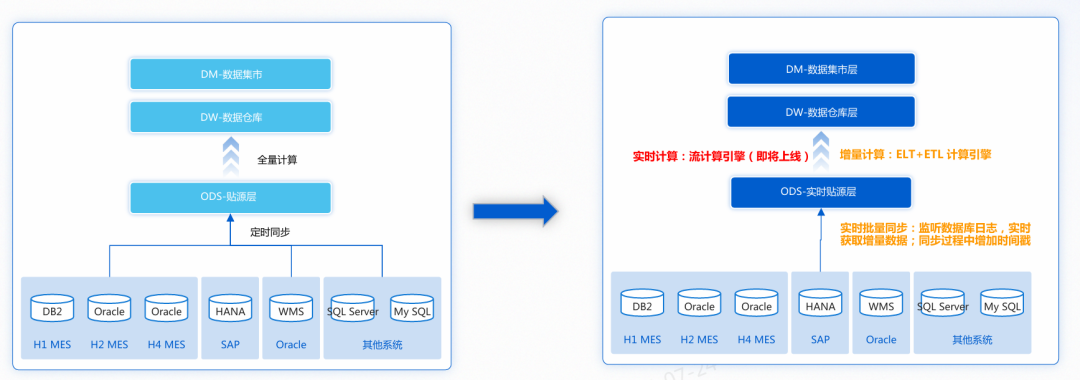
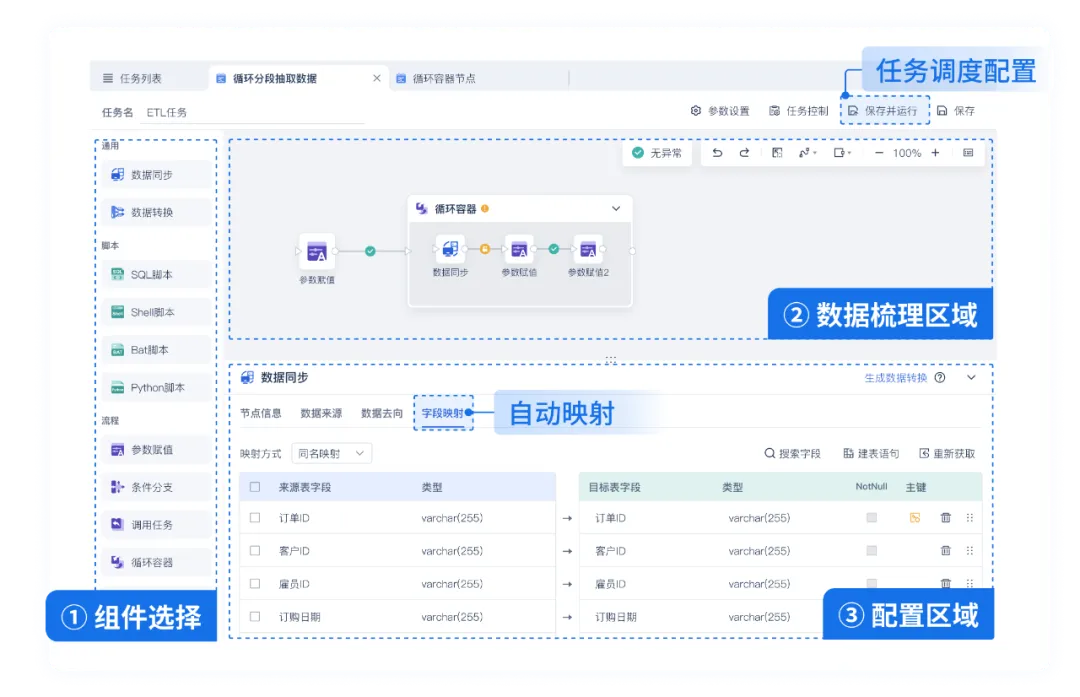
- 低代码可视化开发:通过拖拽式操作即可完成复杂数据处理流程,极大降低了学习和使用门槛。
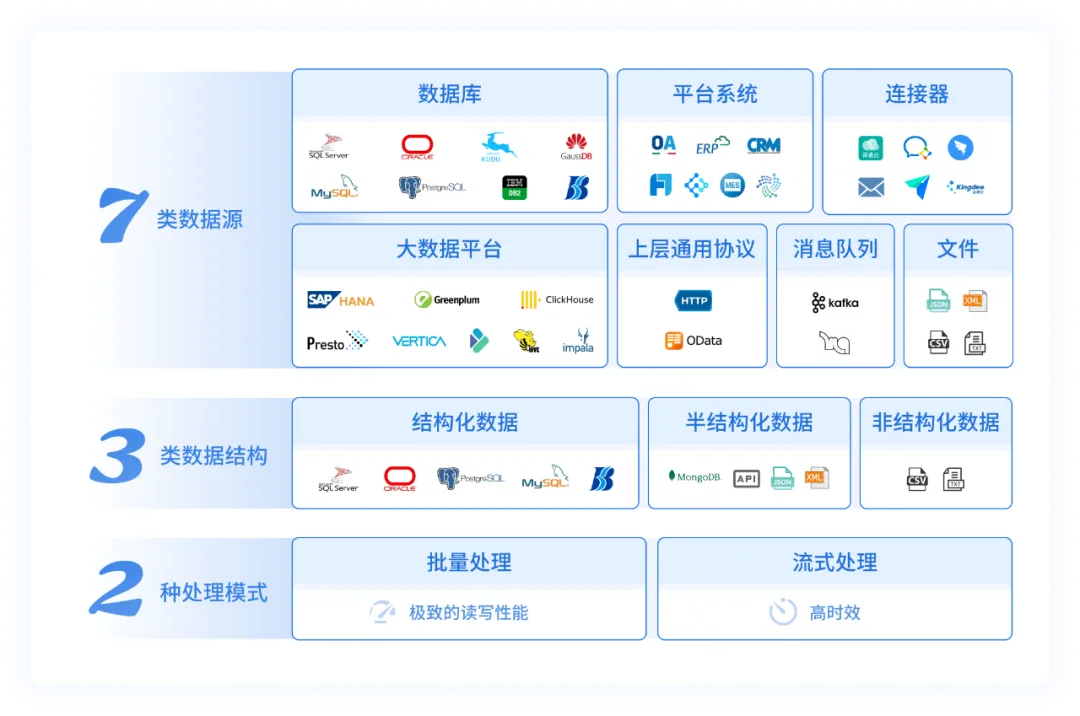
- 多源数据采集:广泛支持关系型数据库、NoSQL数据库、API接口、各类文件等多种数据源。
- 全流程数据治理:涵盖元数据自动采集、端到端数据血缘追踪、多维度数据质量监控与细粒度权限控制,满足等保合规要求。

- 完善的任务调度与监控:提供强大的任务调度、依赖管理、失败告警与实时状态监控功能。
不足:免费版功能限于基础数据同步;面对极其特殊的业务逻辑时可能需要二次开发。
适用场景:国产化替代项目、中大型企业数据仓库建设、政务及金融机构、追求快速落地的数据治理需求。
2. Microsoft SQL Server Integration Services (SSIS)
定位:微软生态专属ETL工具,与SQL Server数据库深度集成。
核心功能:
- 内置丰富的数据转换组件和任务模板。
- 与Visual Studio开发环境无缝集成,开发体验流畅。
- 通过SQL Server Agent实现成熟稳定的任务调度和依赖管理。
- 支持增量数据同步与数据清洗规则配置。

不足:跨平台支持差,主要在Windows环境部署;处理PB级超大数据时性能可能受限;对非微软系数据源兼容性一般。
适用场景:以SQL Server为核心数据库的企业、微软技术栈团队、中小企业的离线数据集成场景。
定位:国际老牌企业级ETL工具,金融、电信等行业首选的合规型平台。
核心功能:
- 支持复杂的业务逻辑转换,处理结构化和半结构化数据能力突出。
- 提供完善的元数据管理,实现数据全生命周期可追溯。
- 安全合规功能全面,满足金融级数据加密与审计要求。
- 支持分布式部署与大规模并行处理(MPP)。
不足:价格昂贵,实施和许可成本高;部署与配置复杂,周期长;技术架构相对传统,与新兴技术栈集成有一定难度。
适用场景:大型金融/电信企业、业务逻辑极其复杂的场景、对合规性要求极高的项目。
4. IBM DataStage
定位:大型企业级ETL工具,以强大的并行处理能力著称的传统数据仓库解决方案。
核心功能:
- 基于大规模并行处理(MPP)架构,处理TB级数据效率高。
- 与IBM生态系统(如DB2、WebSphere)集成紧密。
- 提供企业级任务调度和监控功能。
- 支持通过可视化方式编排复杂业务规则。
不足:学习与配置成本高;灵活性不足,实现高度定制化需求较难;对云原生环境的适配速度较慢。
适用场景:采用IBM技术栈的大型企业、传统大型数据仓库建设、复杂批处理业务场景。
5. Kettle (Pentaho Data Integration, PDI)
定位:开源ETL工具中的经典,拥有庞大的社区用户群体。
核心功能:
- 完全免费开源,采用可视化的拖拽式流程设计。
- 插件生态丰富,可通过社区插件扩展支持多种数据源。
- 支持完整的数据抽取、清洗、转换、加载流程。
- 社区资源丰富,有大量现成的转换模板可供参考。
不足:处理TB级以上数据时易遇性能瓶颈;实时处理能力弱;集群化部署配置复杂,运维成本较高。
适用场景:预算有限的中小企业、技术能力较强的团队、简单的ETL任务或数据迁移项目。
6. Talend
定位:由Qlik公司推出的、从开源转向商业的云原生数据集成工具,以丰富的连接器生态闻名。
核心功能:
- 提供超多的预构建组件和连接器,支持本地、云及混合云部署。
- 强化数据质量与治理能力,深度适配Snowflake等现代云数据仓库。
- 支持实时和批量数据处理,擅长处理JSON、XML等半结构化数据。
不足:学习曲线较陡,掌握复杂配置需要时间;开源版本功能受限,复杂场景需商业版;处理超大规模数据时的性能有待优化。
适用场景:采用云架构的中大型企业、多源异构数据整合、重视数据治理的跨国企业。
7. Airbyte
定位:轻量级开源ELT工具,凭借模块化设计和海量连接器快速崛起。
核心功能:
- 支持超过300个数据源/目的地的连接器,可通过Docker快速部署。
- 提供低代码配置界面,上手门槛极低。
- 支持增量同步和数据同步状态监控。
- 可与Apache Airflow等外部调度工具轻松集成。
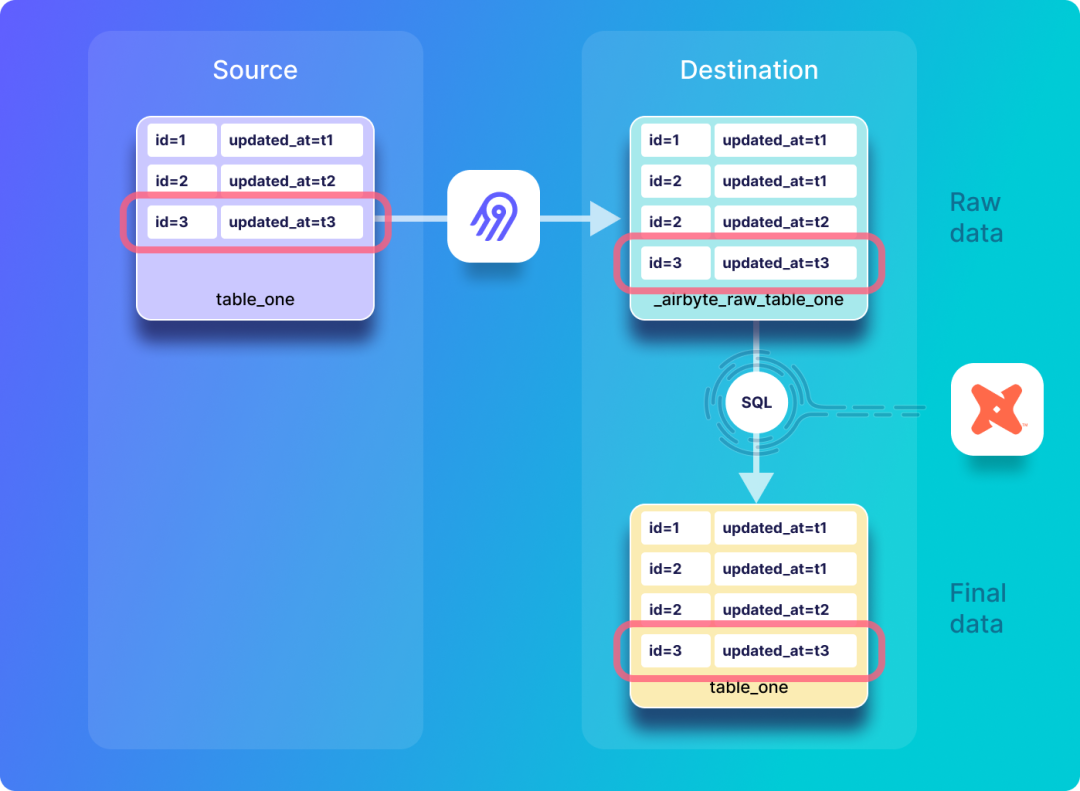
不足:部分连接器功能深度不足,对老旧或小众系统的支持较差;复杂转换需编写自定义脚本(dbt集成);数据权限管理与监控告警体系较为简单。
适用场景:初创公司、小团队、轻量级数据同步、SaaS应用数据集成、快速原型验证。
8. Apache NiFi
定位:Apache基金会旗下的分布式数据流处理工具,擅长复杂数据管道的可视化编排。
核心功能:
- 提供强大的可视化数据流编排能力,支持运行时动态调整流程。
- 数据流监控完善,支持数据路由、过滤、转换等全流程处理。
- 具备高扩展性和容错性,支持集群化部署。
- 采用元数据与内容分离的设计,优化了系统资源占用。
不足:资源消耗较大,对服务器硬件配置要求高;学习曲线陡峭,官方文档对初学者不够友好;内置的复杂计算(如关联、聚合)能力相对薄弱。
适用场景:IoT数据采集与分发、复杂数据流编排场景、大规模系统间的数据协同。
9. AWS Glue
定位:AWS云原生的无服务器ETL服务,深度集成于AWS数据生态。
核心功能:
- 无服务器架构,自动弹性伸缩,用户无需管理底层基础设施。
- 与Amazon S3、Redshift、RDS等AWS服务深度集成。
- 提供基于机器学习的数据质量检测与去重等功能。
- 按实际数据处理量计费,成本可控。
不足:国内用户可能面临网络延迟高、访问不稳定问题;对非AWS生态的数据源兼容性一般;跨云或混合云部署能力弱。
适用场景:全面基于AWS云原生架构的企业、海外业务、云上数据湖构建、有弹性扩展需求的ETL任务。
10. Azure Data Factory
定位:微软Azure生态的云原生数据集成服务,跨区域部署能力突出。
核心功能:
- 深度适配Azure SQL Database、Synapse Analytics、Blob Storage等服务,与Power BI联动性强。
- 支持实时和离线数据集成,具备“断连”模式以应对网络不稳定情况。
- 提供低代码可视化设计界面,支持复杂数据流编排。
- 支持跨区域的数据管道部署与同步。
不足:跨云集成能力较弱,非Azure用户使用成本高;部分高级功能(如数据流)需额外付费;对国产数据库的支持有限。
适用场景:Azure云生态企业、微软技术栈团队、有跨区域数据同步需求、需与Power BI深度联动的数据分析场景。
三、工具总结对比表格
为了更直观地进行对比,以下是各工具核心维度的横向总结:
四、常见问题解答(FAQ)
Q1:开源工具和商业工具到底怎么选?
A:这取决于你的核心约束条件。如果预算有限、技术团队实力强、数据处理需求相对简单,可以选择Kettle、Airbyte等开源工具,它们能有效控制前期成本。反之,如果面向企业级核心业务、高度重视系统稳定性与厂商技术支持、且有严格的合规性要求,那么选择像FineDataLink、Informatica这类成熟的商业工具更为稳妥。切勿为了节省初期许可费用而在核心业务上使用开源工具,后期高昂的运维和定制开发成本可能远超预期。
Q2:国产化项目是否只能选择国产工具?
A:并非绝对,但国产工具在适配性上优势明显。如果项目有严格的信创要求,必须优先选择像FineDataLink这类对国产芯片、操作系统、数据库完成全面适配的工具。如果只是部分国产化或没有硬性规定,Talend等海外工具经过兼容性测试后也可能满足基础需求,但务必提前进行充分的POC测试,避免项目后期因兼容性问题而返工。
Q3:云原生工具和本地部署工具如何抉择?
A:核心决策依据是现有的IT基础设施架构。如果企业已经完全上云,并且主要依赖单一云厂商(如AWS或Azure)的生态,那么选择对应的AWS Glue或Azure Data Factory集成成本最低、运维最省心。但如果是混合云或多云架构,或者数据出于安全考虑必须保留在本地,则更应选择支持多种部署模式(本地/云/混合)的工具,如FineDataLink、Talend等,为未来的架构演进预留灵活性。需要提醒的是,不应盲目追逐“云原生”热潮,如果所在地区网络条件不理想,本地部署工具的稳定性和数据安全性可能更具保障。
总结
ETL工具选型的核心在于“适配”,即与业务需求、团队技术栈、项目预算以及长期IT战略的精准匹配。希望这篇涵盖主流工具深度测评与选型思路的指南,能够帮助你在2026年及未来的数据项目中做出更明智的决策。数据集成是构建可靠数据底座的第一步,选择一款合适的工具至关重要。如果你在实际选型中遇到具体场景的困惑,欢迎在云栈社区的技术论坛中与更多同行交流探讨。
 发表于 2026-3-12 02:23:14
|
查看: 122|
回复: 0
发表于 2026-3-12 02:23:14
|
查看: 122|
回复: 0
