导语:本文将从监控系统整体架构设计、技术方案落地与优化两部分,深入阐述百亿级大数据实时监控系统的建设过程,旨在为大家提供专业的设计思路与实践指导,帮助快速构建高性能监控系统。
一、为什么要构建监控系统
在后移动互联网时代,稳定的用户体验是所有增长的基础。对于大型互联网公司,尤其是面向C端用户的企业,业务系统的稳定性要求极高,对线上问题的发现和处理速度通常需要达到分钟级。
想象一下,像滴滴这样的出行服务平台,如果核心打车服务中断10分钟,就足以引发乘客和司机的大规模投诉,不仅造成直接的经济损失,更会严重损害平台的信誉和用户口碑。
大型互联网的业务系统往往是复杂的分布式架构,各类业务应用与基础组件(如数据库、缓存、消息队列等)相互依赖,形成一个错综复杂的网络。在这个网络中,任何一个节点都可能发生故障,导致服务不可用。因此,一套健壮的业务监控系统至关重要,它能帮助我们及时发现并介入处理问题,从而避免事故发生或控制其影响范围。
二、监控系统整体设计
(一)监控系统需求
我们必须承认,世界上不存在完全可靠的系统。程序、硬件、网络都可能在运行时出现故障,进而引发服务异常。监控的核心目标,就是高效、及时地发现并定位这些系统异常,目标是缩短平均修复时间(MTTR),从而最小化异常带来的损失。
为了实现这个目标,一个理想的监控系统应该具备以下能力:
- 数据采集能力:全面、准确、快速且低损耗地获取监控日志与指标数据。
- 数据汇聚能力:将相关数据进行汇总,便于后续的统一加工与分析。
- 数据分析与处理能力:提供异常检测、故障诊断等方法,以及对数据进行过滤、采样、转换等处理手段。
- 数据存储能力:为海量的日志与监控指标提供高性能、可扩展的存储方案。
- 监控告警能力:支持灵活的监控规则定义,并能在规则触发时通过电话、邮件、微信、短信等多种渠道发送告警。
- 数据展示能力:提供直观的监控数据与告警 Dashboard,加速问题定位与排查。
- 高可用性:监控系统自身必须具备高可用性。如果因为系统异常导致监控本身失效,那将失去其根本价值。
(二)监控系统架构
基于对监控需求的梳理,我们可以将监控系统的数据流转过程抽象为以下几个阶段:采集 -> 汇聚 -> 处理 -> 存储 -> 分析 -> 展示 -> 告警。
据此,可以总结出监控系统的一般性架构:
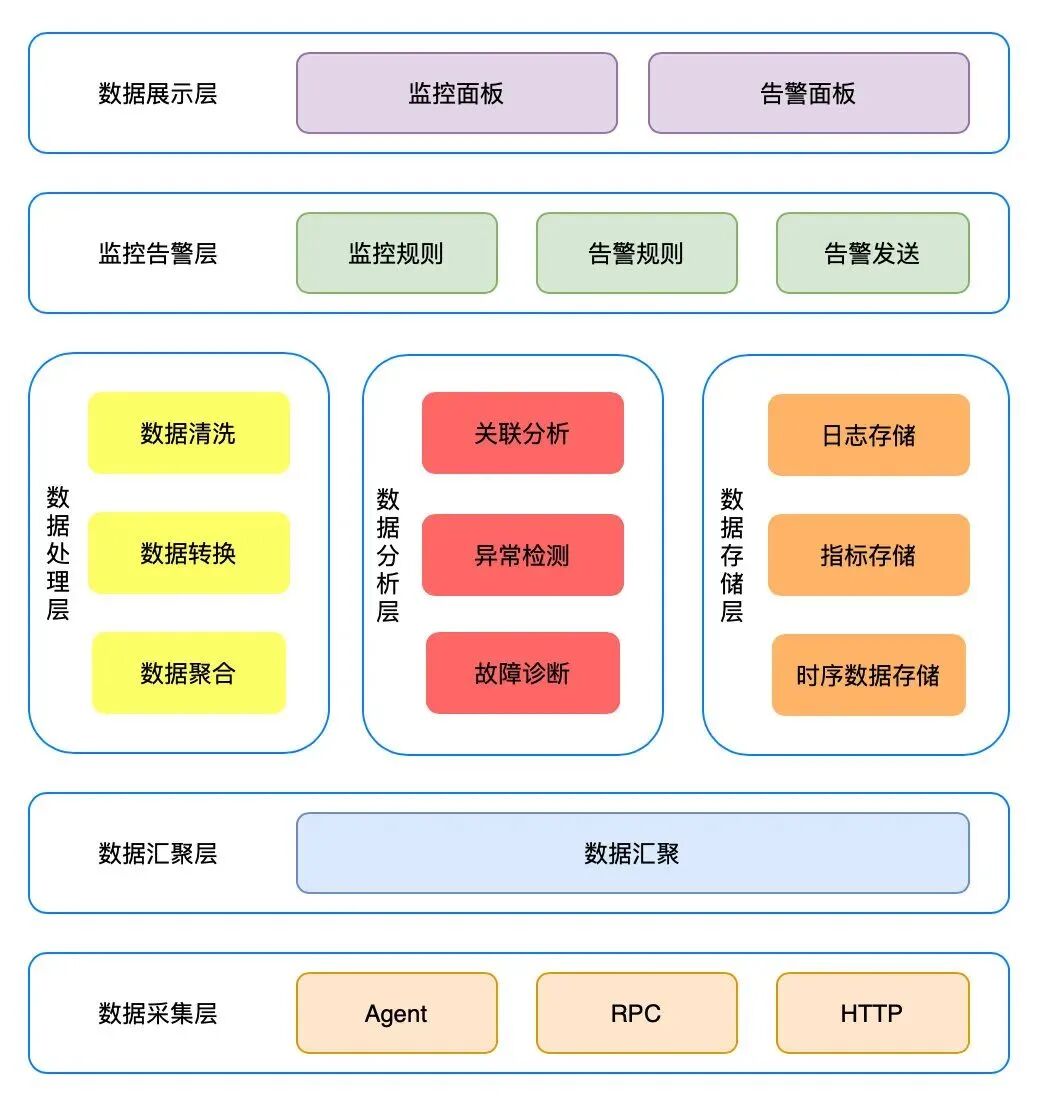
让我们从下至上解析这个架构:
首先是数据采集层。这一层提供了多种采集手段,包括 Agent 采集、RPC 埋点、HTTP 上报等。你可以通过部署 Agent 来采集服务器主机的监控数据和日志,也可以通过 RPC 框架埋点自动上报,或者允许用户直接通过 HTTP API 推送数据。
采集到的数据需要经过统一的数据汇聚层,将相关联的数据汇聚在一起。例如,将同一业务系统的所有服务器数据发送到同一个消息队列中,为后续的关联分析和异常检测做准备。
数据完成汇聚后,通常会分为三条主要的数据流进行处理:数据处理、数据分析和数据存储。
- 数据处理层:负责对原始监控数据进行加工。通过数据清洗与转换将数据标准化,并进行基础的聚合计算,例如统计某个服务集群在过去一分钟内的总错误日志条数。
- 数据分析层:对标准化后的数据进行更深层次的分析,如关联分析、异常检测、根因诊断等,为后续的告警决策提供依据。
- 数据存储层:负责对日志、指标、时序数据等进行持久化存储,既服务于 Dashboard 的实时展示,也为未来的数据挖掘提供基础。
数据经过上述处理后,进入监控告警层。这里定义了各种监控与告警规则,一旦有事件触发规则,系统便会通过预设的渠道(如钉钉、企业微信)进行告警推送。
最终,数据流抵达数据展示层。这一层为用户提供交互界面,如监控大盘、告警列表、日志查询面板等,方便运维和开发人员直观地掌握系统状态。
三、监控系统方案落地
(一)技术选型
方案1: 流计算Oceanus + Elastic Stack
一提到监控系统,很多人首先会想到 Elastic Stack(即 Elasticsearch、Logstash、Kibana、Beats)。其活跃的社区、相对简单的部署和便捷的使用方式,吸引了大量用户,许多公司的监控架构都基于此搭建。
- Elasticsearch:实时分布式搜索和分析引擎,是 Elastic Stack 的核心,负责数据的存储、索引和复杂查询。
- Logstash:动态数据收集、处理和转发管道。它功能强大,但基于 JVM,资源消耗较高。
- Kibana:数据可视化平台,为 Elasticsearch 中的数据提供图表、图形等可视化分析能力。
- Beats:轻量级数据采集器家族(如 Metricbeat 采集指标,Filebeat 采集日志),资源占用极低。
早期的 ELK 架构使用 Logstash 进行采集和解析,但其资源消耗较大。因此,现代架构更倾向于使用轻量级的 Beats 进行数据采集。基础架构如下:
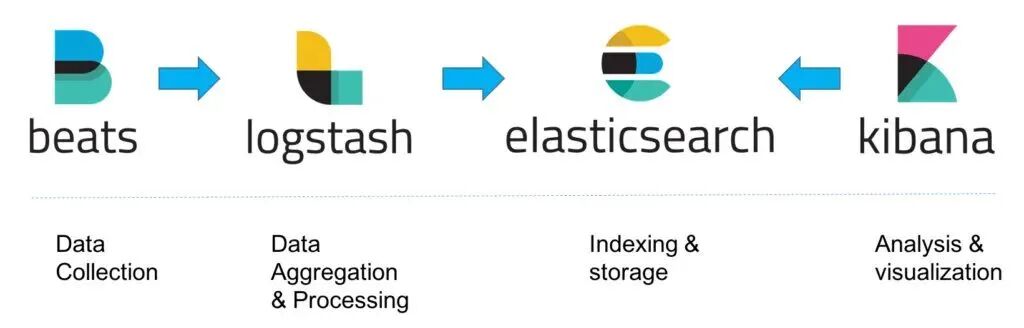
Elastic Stack 提供了一个强大的平台,用于对海量日志和监控数据进行集中管理和近乎实时的搜索分析。它能够帮助运维人员快速定位故障、排查问题。
然而,原生 Elastic Stack 也存在一些不足:Beats 仅负责采集,缺乏数据处理能力;Logstash 的处理能力在面对复杂场景时可能捉襟见肘,且不支持数据缓存,存在丢失风险。
因此,一个更健壮的方案是:在数据写入 Elasticsearch 之前,引入消息队列(如 Kafka)进行缓冲,并引入实时计算引擎对数据进行清洗、转换和聚合。
腾讯云流计算 Oceanus 正是为此而生。它是基于 Apache Flink 构建的企业级实时大数据分析平台,具备亚秒级延迟、无缝连接各种数据源/存储、安全稳定等特点。利用 Oceanus 的实时计算能力,监控系统可以对海量日志和指标进行实时处理与分析,结果直接用于告警和展示,极大地提升了故障响应速度。
另外,在监控面板的选择上,Kibana 虽擅长日志分析,但其可视化能力和对非技术用户的上手难度是一大挑战。相比之下,Grafana 在指标数据可视化方面更胜一筹,支持丰富的数据源和灵活的图表配置。因此,我们可以让 Kibana 专注于日志分析,而使用 Grafana 作为核心监控面板。
整合后的完整流程如下图所示:
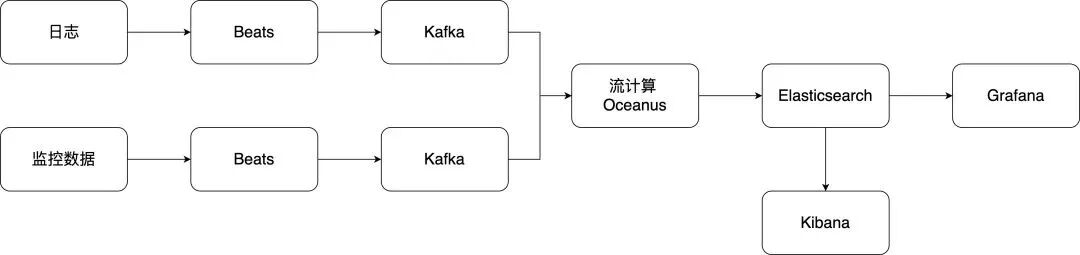
在此架构中,Beats 采集数据并写入 Kafka;Oceanus(Flink)从 Kafka 读取数据进行实时处理;处理结果写入 Elasticsearch;最终通过 Kibana 分析日志,通过 Grafana 展示监控指标。
方案2: Zabbix + Prometheus + Grafana
- Zabbix:一款成熟的开源分布式监控软件,支持可视化配置、多种指标采集和自定义告警。它灵活且功能全面,适合监控硬件、OS、服务进程等。
- Prometheus:基于 Go 语言开发的监控、告警、存储套件,采用 Pull 模型采集数据,并内置时序数据库。它架构简单,数据模型灵活,查询语言(PromQL)功能强大,非常适合云原生和微服务环境的监控。
- Grafana:如前所述,强大的可视化工具,完美支持 Prometheus 等数据源。
这套组合部署简单,功能完善,在容器化环境中尤其流行。但其主要局限性在于面对超大规模数据量时可能存在性能瓶颈:
- Zabbix 的 Pull 模式在监控项极多时可能存在性能压力,深度定制较复杂。
- Prometheus 本质上是一个监控指标(Metrics)系统,不适合处理日志(Logs)、事件(Event)等,其存储默认非持久化,且原生设计更偏向单机,在海量数据存储和水平扩展方面需要额外方案支持。
选型总结
- Elastic Stack + 流计算 Oceanus:构建的是分布式、可扩展、实时化的监控系统,能够统一处理日志和指标,性能强大,扩展性高。缺点是部署和调优相对复杂,资源消耗较高。
- Zabbix + Prometheus + Grafana:部署简单,在容器化环境中表现优异,但存在性能天花板,难以支撑百亿乃至千亿级别的超大规模监控场景。
综合比较,为了支撑百亿级数据的实时监控需求,我们最终选择 流计算 Oceanus 与 Elastic Stack 组合的方案。
(二)系统优化
随着业务量激增,监控数据量可能达到百亿甚至千亿级别,系统会面临严峻挑战:处理性能下降、数据倾斜、存储写入瓶颈等,导致监控延迟从分钟级恶化到小时甚至天级,这完全不可接受。
腾讯云流计算 Oceanus 和 Elasticsearch Service 针对这些超大规模场景进行了深度优化。
流计算Oceanus的优化
流计算 Oceanus 在底层 Apache Flink 的基础上,为企业级实时计算提供了诸多增强特性。
1. SQL 性能优化
- 应对数据倾斜:自动开启 Local-Global Aggregate 与 Mini-Batch 功能。Local Aggregate 预先聚合数据,减少 Global Aggregate 的热点;Mini-Batch 则以微批方式处理,减少状态访问频率和 I/O 压力,从而有效缓解数据倾斜带来的性能问题。
- UDF 复用优化:自动识别并缓存逻辑执行计划中重复调用的 UDF(如 JSON 解析)结果,避免重复计算,提升效率。
- 维表 Join 优化:支持在维表 DDL 中指定分桶(Bucket)信息。流表与维表 Join 时,只会加载对应分片的维表数据,极大减少了全量数据预加载的内存消耗和反压风险。
2. 作业智能诊断与监控
提供作业运行事件(如异常重启、Checkpoint 失败)的可视化提示。通过采集和分析异常日志,智能诊断问题并提供修复建议。同时,定义了从 Task 粒度到作业集群维度的 65 项以上监控指标,实现全方位的监控告警。
3. 作业自动扩缩容
根据 CPU 使用率、内存消耗、反压情况等业务负载指标,自动调整作业并行度,实现资源的弹性伸缩。在业务高峰时扩容保障稳定,在低谷时缩容节约成本,在保障时效性的同时实现降本增效。
腾讯云 Elasticsearch Service 的优化
面对百亿级数据的写入、查询和存储成本压力,开源 Elasticsearch 往往力不从心。腾讯云 Elasticsearch Service(ES)基于开源版本,从内核层面进行了深度优化。
1. 存储模型优化
优化了底层 Lucene 索引文件的合并策略。默认策略可能导致数据时间序混乱,影响查询时文件剪枝效率。腾讯云 ES 实现了按时间序分层合并的策略,保证了数据连续性,显著提升了查询性能。测试表明,搜索场景性能提升约40%,带主键的写入性能提升约一倍。
2. 成本优化
基于监控数据“越新访问越频繁”的特征,实现了冷热数据分离。将热数据存放在 SSD 磁盘保证性能,将冷数据自动迁移至大容量的 HDD 磁盘降低成本,并可将超冷数据备份到成本更低的对象存储 COS 上。通过这一系列措施,整体存储成本可下降近10倍。
3. 内存优化
针对 Elasticsearch 堆内存中占用巨大的倒排索引(FST)结构,腾讯云 ES 将其移至堆外(Off-Heap)管理,实现按需加载和更精准的淘汰策略,并配合多级缓存提升性能。这显著提高了堆内内存利用率,降低了 GC 开销,使单个节点能够管理更大容量的磁盘数据。
四、总结
本文系统地阐述了百亿级大数据实时监控系统的建设思路。首先分析了监控系统的核心需求,并据此推导出通用的分层架构。接着,详细对比了基于流计算 Oceanus + Elastic Stack 和 Zabbix + Prometheus + Grafana 两种主流技术方案,结合超大规模场景的需求,选择了前者。最后,重点介绍了腾讯云流计算 Oceanus 和 Elasticsearch Service 如何通过一系列性能与成本优化策略,来应对百亿级数据带来的挑战。
总而言之,流计算 Oceanus 与 Elasticsearch Service 的组合,能够强有力地支撑起对实时性要求极高的超大规模监控场景,同时在确保性能的前提下,通过智能优化有效降低总体拥有成本。
希望本文分享的架构设计与优化实践,能为你构建或升级自己的高性能监控系统提供有价值的参考。欢迎在云栈社区交流讨论更多大数据与实时计算的相关话题。
 发表于 2026-3-7 13:26:42
|
查看: 104|
回复: 0
发表于 2026-3-7 13:26:42
|
查看: 104|
回复: 0
