
软件开发领域有一个著名的“不可能三角”——质量、成本、时间,三者往往难以兼得。这同样是 IT 领域没有“银弹”的根本原因。当我们采用分布式系统来突破单机的计算与存储瓶颈时,一个棘手的副产品也随之而来:数据一致性问题。
市面上讨论数据一致性的文章不少,大多从算法层面切入。本文将换个视角,从服务架构的角度出发,为你详细拆解主从、主主、无主这三种架构模式下,数据一致性面临的挑战与主流解决方案。如果你想深入探讨更多架构设计,不妨来云栈社区交流分享。
背景
随着业务规模增长,服务从单体应用走向分布式部署是大势所趋。分布式架构极大地提升了系统的并发处理能力,突破了单机 CPU 和磁盘的限制。但技术从来不是银弹,我们在享受其红利的同时,也必须面对它带来的“副作用”——数据一致性问题。
在分布式场景下,数据的处理和存储从单节点扩展到了多节点。为了保证服务对外表现一致,这些节点之间必须协同工作,保持数据同步。然而,达成这种一致性远非易事,其背后需要精心的设计与大量的努力。

下面,我们就以一个常见的场景,来看看分布式是如何影响数据一致性的。
1.1 数据存储读取
数据库是我们打交道最多的中间件,负责数据的持久化存储。但在分布式场景下,这带来了不小的挑战。想象一下这个场景:情人节,小明给女朋友小红发了一个520元的红包。然而,小红却没有收到,非常生气。小明也很委屈,明明刚发的红包,去哪儿了?
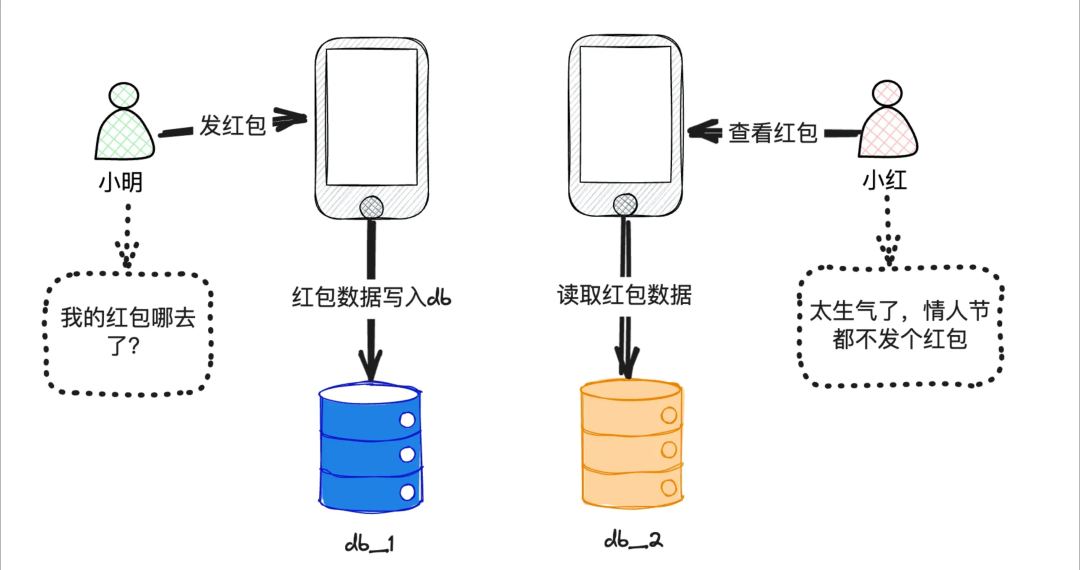
问题的根源在于,小明发红包时写入的数据节点,和小红读取红包数据时的节点不一致。并且,写入节点的数据没有及时同步到读取节点。
接下来,我们就从数据存储和读取的角度,深入分析分布式环境下可能出现的问题以及对应的解决思路。
数据存储一致性
在深入探讨之前,我们先思考一个根本问题:分布式环境下存储不稳定的本质原因是什么?其实是 “无法保证读到正确的写”。要解决“读正确写”的问题,就必须理解分布式存储节点之间是如何协同工作的,只有厘清数据流向,才能对症下药。
你可能又会问,为什么单体应用不存在这个问题?答案很简单:单体情况下,数据的存储和读取节点是唯一的,没有同步的困扰。但在分布式世界里,多个节点间必然涉及数据同步,而同步策略又与服务的部署架构紧密相关。因此,我们不妨从架构入手,分类讨论。
2.1 主从架构
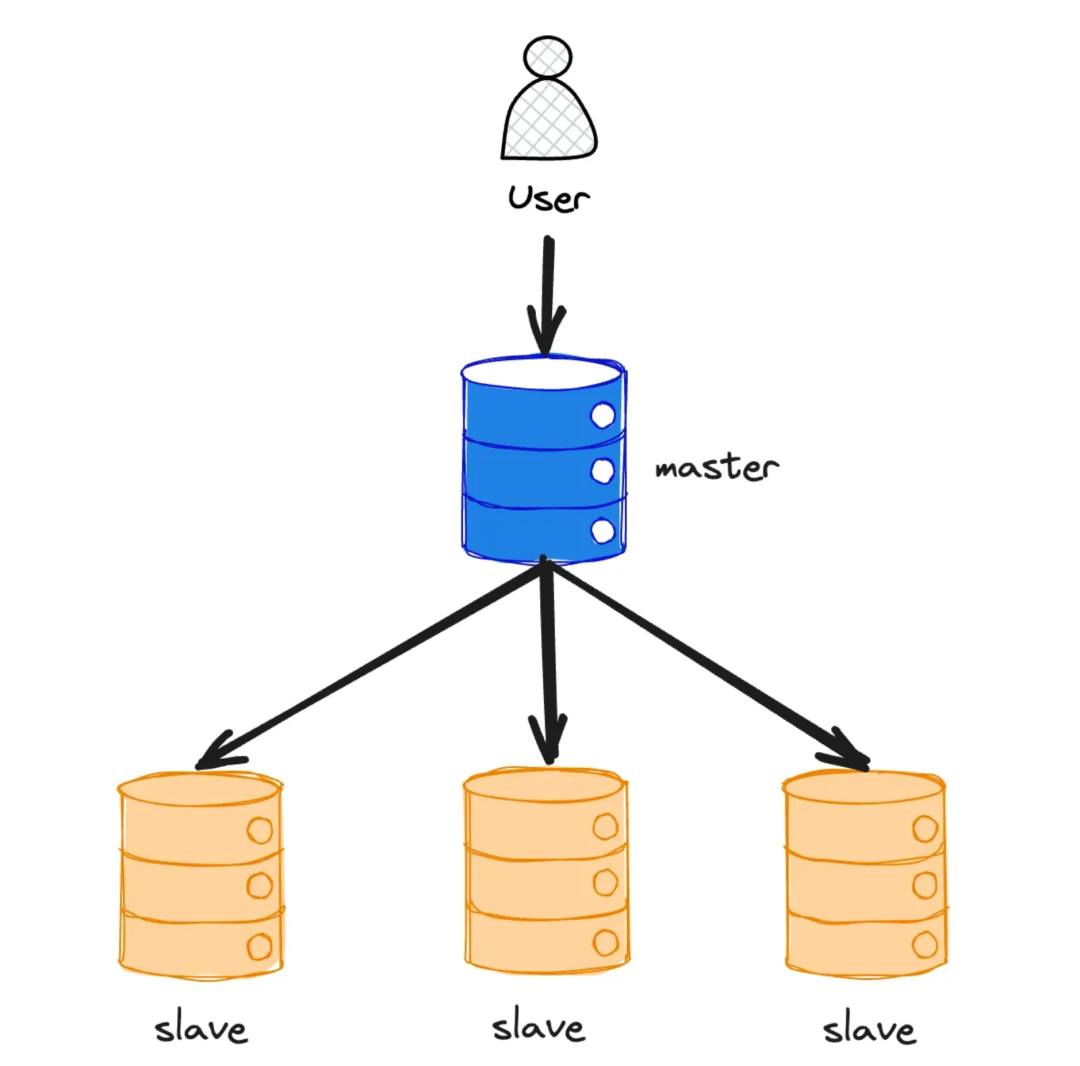
主从架构是数据库最常见的部署模式之一:主节点(Master)负责处理写请求,而从节点(Slave)则分担读流量。在这种架构下,主从之间的数据同步主要有三种方式:同步复制、半同步复制和异步复制。
2.1.1 同步复制
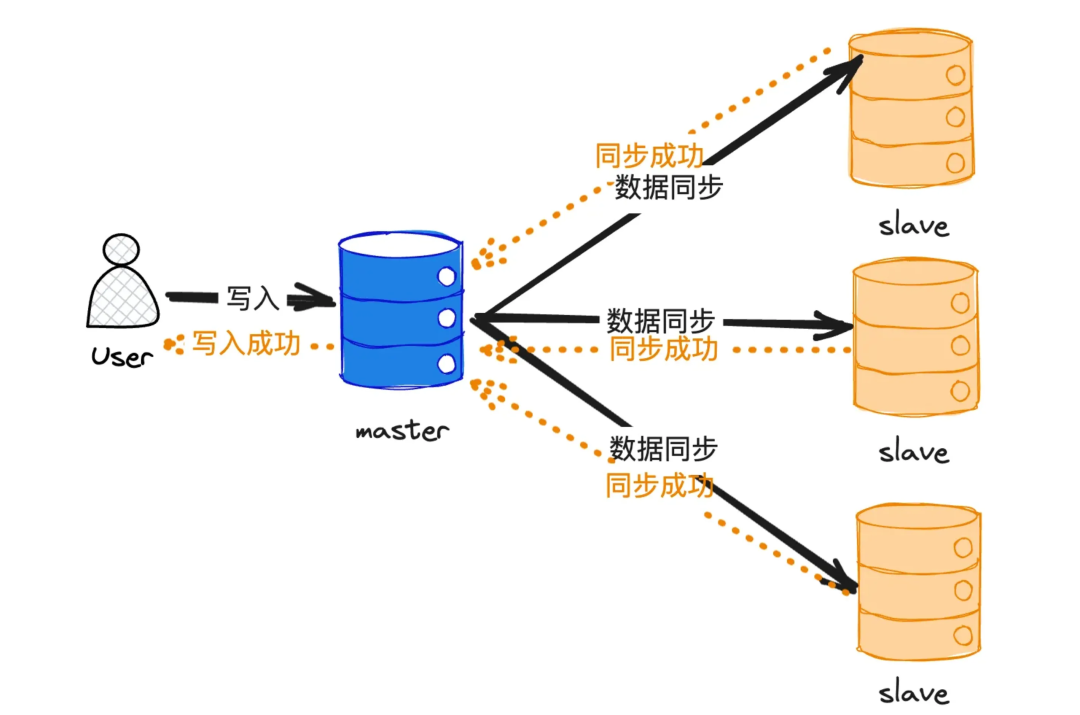
同步复制指的是,数据在主节点写入成功后,必须确保所有从节点都同步成功,才向上游返回成功确认。这种方式通常用于对数据可靠性要求极高的场景,例如金融级数据库 TDSQL,其生产环境常采用“一主两备强同步”的模式。
- 优点:主从间数据保持强一致,数据可靠性极高。
- 缺点:对网络延迟非常敏感。从节点数量越多,写入效率越低,受网络波动影响越大。相比其他复制方式,数据复制效率较低。
在这种同步模式下,数据的写入和读取是对等的。因为一旦返回成功 ACK,就意味着主从数据已完全一致,稳定性很高。
2.1.2 半同步复制
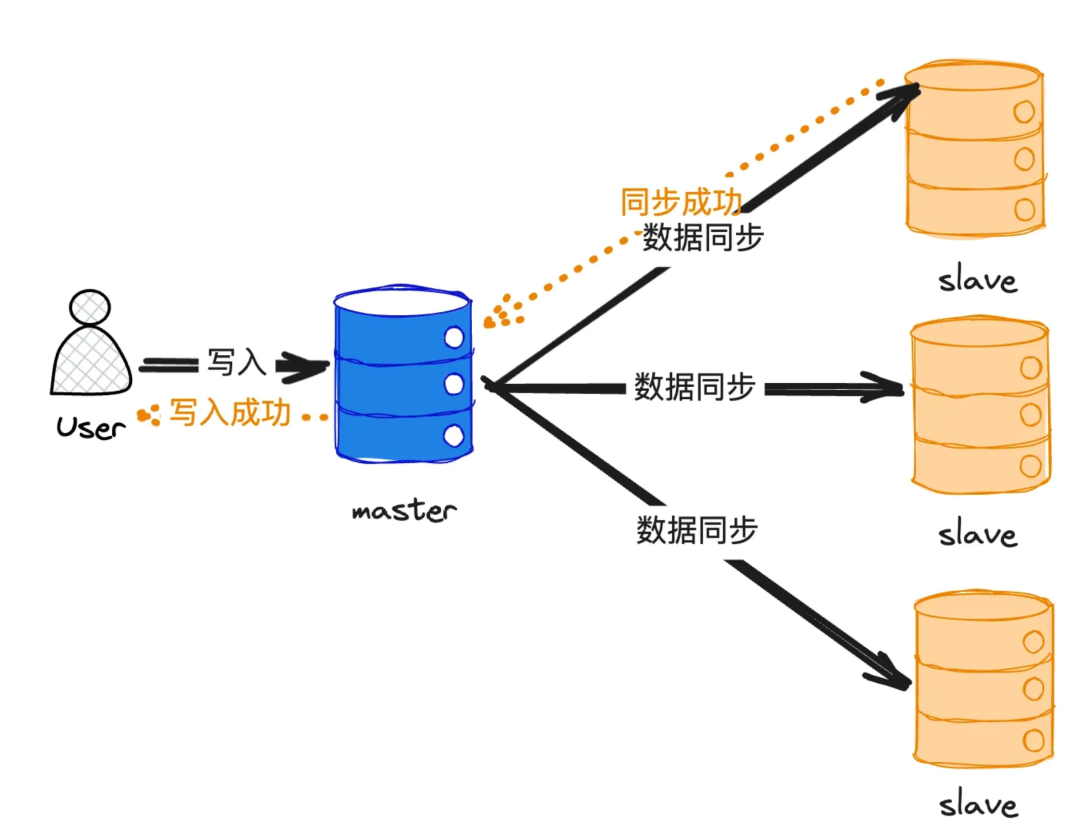
半同步复制是指,数据在主节点写入成功后,只要其中任意一个从节点同步成功,即返回成功 ACK。这种方式适用于对写入效率有较高要求的场景。据笔者了解,Shopee 的数据库同步就主要采用这种模式。
- 优点:主从同步效率较高,对网络延迟相对不敏感。
- 缺点:在同步过程中,由于只要一个节点成功就算写入成功,如果其他从节点后续异步复制失败,而请求又恰好路由到该节点,就可能出现“幻写”(刚写入的数据再次读取时丢失),数据可靠性较低。
因此,在这种模式下,数据一致性并非最强,只能通过未同步节点的异步追赶来达到最终一致。如果业务对一致性要求极高,可以采用“主写主读”的方式来规避问题。半同步复制通过牺牲部分数据强一致性,换取了更高的写入效率,是一种不错的折中方案。
2.1.3 异步复制
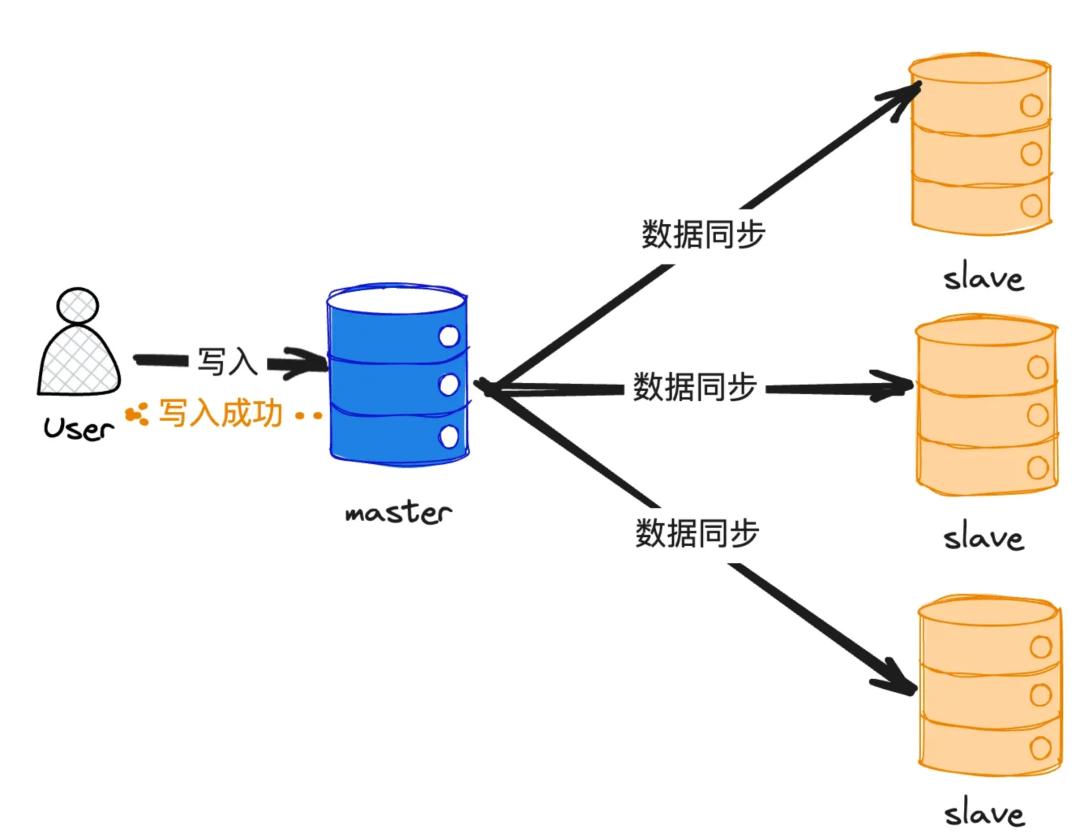
异步复制最为“激进”:数据在主节点写入成功后立即返回,从节点异步地、非实时地去复制主节点的数据。这种方式常用于对写入吞吐量要求极高,或需要做灾备、异地多活的场景,例如跨地域的数据同步。
- 优点:主从同步对主节点写入几乎无影响,写入效率最高。
- 缺点:从节点无法与主节点保持实时同步,极容易出现主从数据不一致的情况。
在这种模式下,数据可靠性最低。同样,对一致性要求高的场景,仍需依赖“主写主读”来保证。
综上所述,主从模式下数据的可靠性主要通过复制机制来保证。同时,主节点作为单一写入点,存在单点故障风险。那么,为了保证一致性,我们该如何处理节点失效呢?
2.1.4 处理节点失效
这个问题我们可以从两方面考虑:
从节点失效:追赶恢复。 在全同步模式下,可以借鉴 Kafka 的 ISR(In-Sync Replicas)机制。维护一个同步状态良好的从节点队列,当某个从节点延迟过大时,将其移出队列并进行数据追赶,待其追上后再重新加入队列。
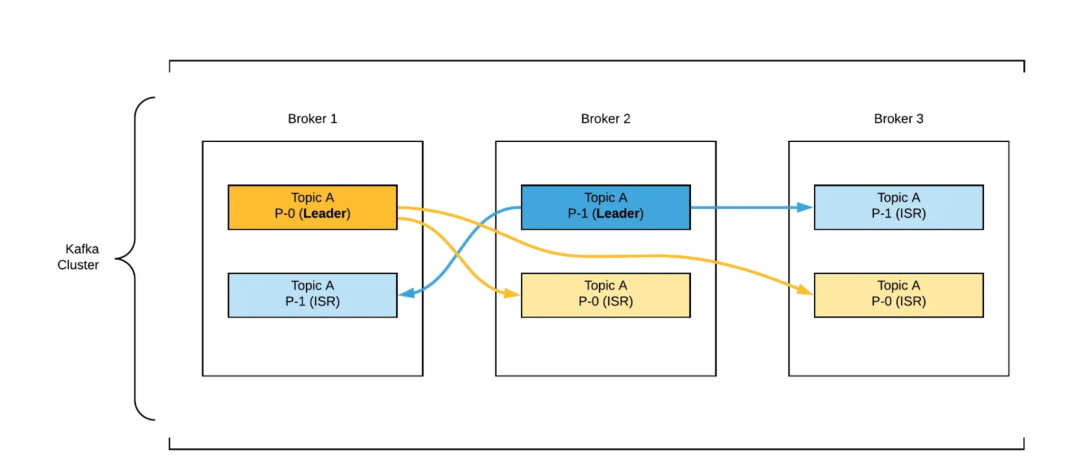
主节点失效:重新选举。 重新选主时需注意两个问题:一是选举出的新主可能存在数据缺失;二是可能发生“脑裂”(网络分区导致出现多个主节点)。可以参考 Redis 解决脑裂的思路,通过配置以下参数来增强健壮性:
min-slaves-to-write:主库必须至少拥有 N 个健康的从库才能执行写命令。这虽不能保证所有从库都收到写操作,但能避免在从库不足时主库盲目写入导致数据丢失。min-slaves-max-lag:从库与主库进行数据复制的 ACK 最大延迟时间。如果从库的 ACK 超时,主库会拒绝写入。
2.2 主主架构
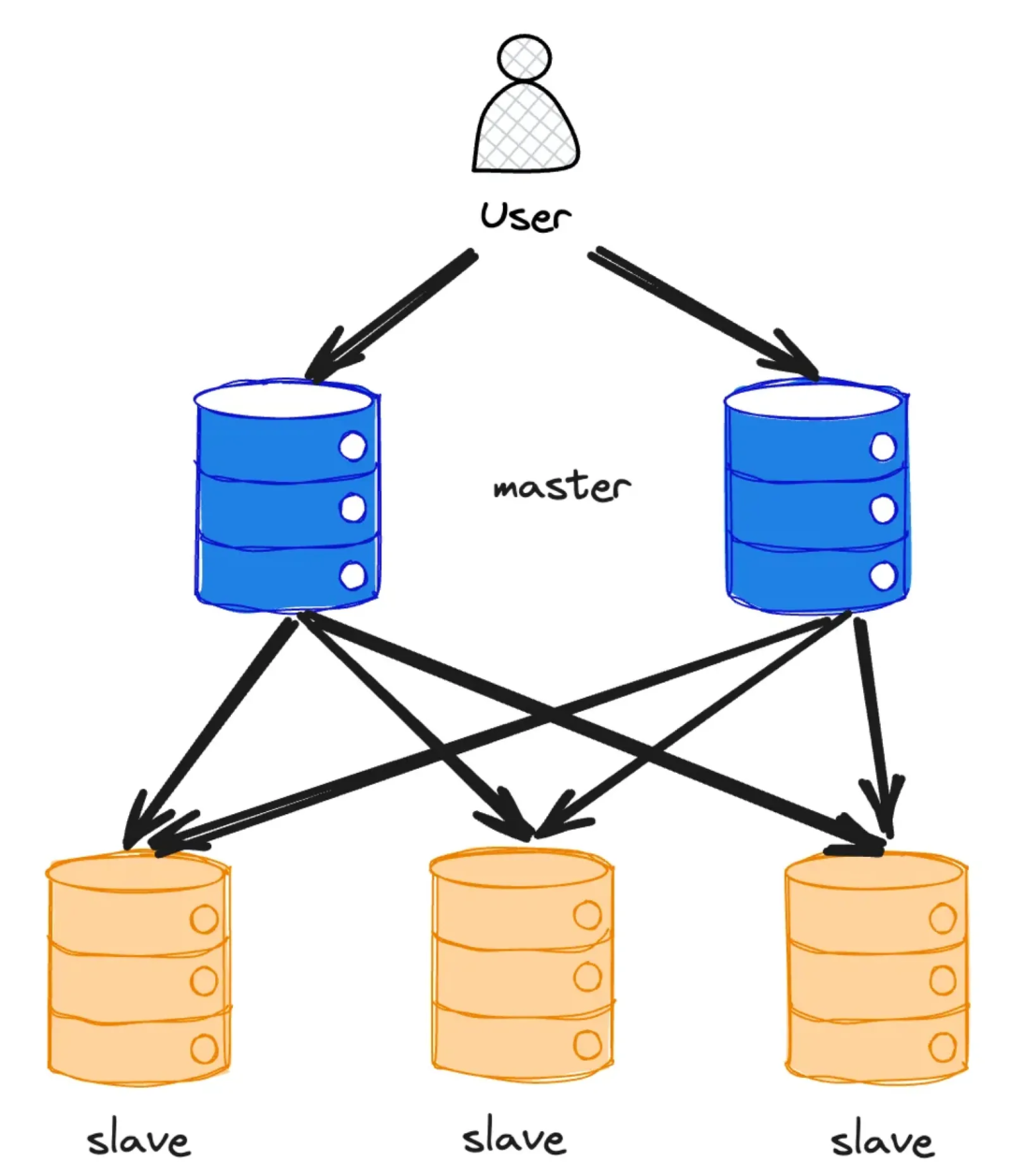
主主架构解决了主从架构中单点写入的瓶颈,允许多个节点同时承接读写流量,并相互同步数据。常见的应用场景包括:
- 多数据中心:为了容忍整个数据中心的故障或让服务更贴近用户,可以将数据库副本部署在多个数据中心。
- 离线客户端操作:例如笔记类软件,支持在手机、电脑等多端写入和同步。
- 协同编辑:如在线文档,多个用户同时编辑,一方修改需立即在其他用户界面生效。
这种架构虽然解放了写入能力,但矛盾也随之转移:如何协调多主节点间的数据同步与冲突,成了一个棘手的新问题。
2.2.1 冲突解决
解决思路可以从以下几个方面入手:
- 处理写冲突:当检测到同时写入同一行数据时,通过锁等机制阻塞后续写请求,直到当前写入完成。但这会极大降低并发效率。对于多设备同步(用户同一时间通常只在一个设备上编辑),冲突概率低;但对于协同编辑,冲突概率高,此方法代价较大。
- 避免冲突:解决冲突的最佳方式就是不让它发生。MySQL 的 MVCC(多版本并发控制)就是这一思想的体现,事务读取的是数据快照,隔离了不同事务间的动态数据访问,仅在提交时检测冲突。在多数据中心场景下,也可以将用户固定路由到最近的数据中心写入,以降低冲突概率。
- 一致性状态收敛:理想情况下,我们希望数据最终对外一致。最直接的方式是在数据提交时,由服务端检测各节点差异,主动或被动进行合并。常用方法有:
- 为每次写入分配全局时间戳,以“后写入者为准”。
- 为每个副本分配唯一ID,制定规则(如ID大的副本写入优先于ID小的副本)。
- 预定义合并规则(如文本合并、计数器相加)自动合并。
- 将合并决定权交给用户,由用户手动解决冲突。
可见,主主架构虽然解决了单点写入问题,却引入了数据冲突的难题。不同解决方案适用于不同场景,开发者在选用时,必须根据自身业务特点谨慎选择策略。
2.3 无主架构
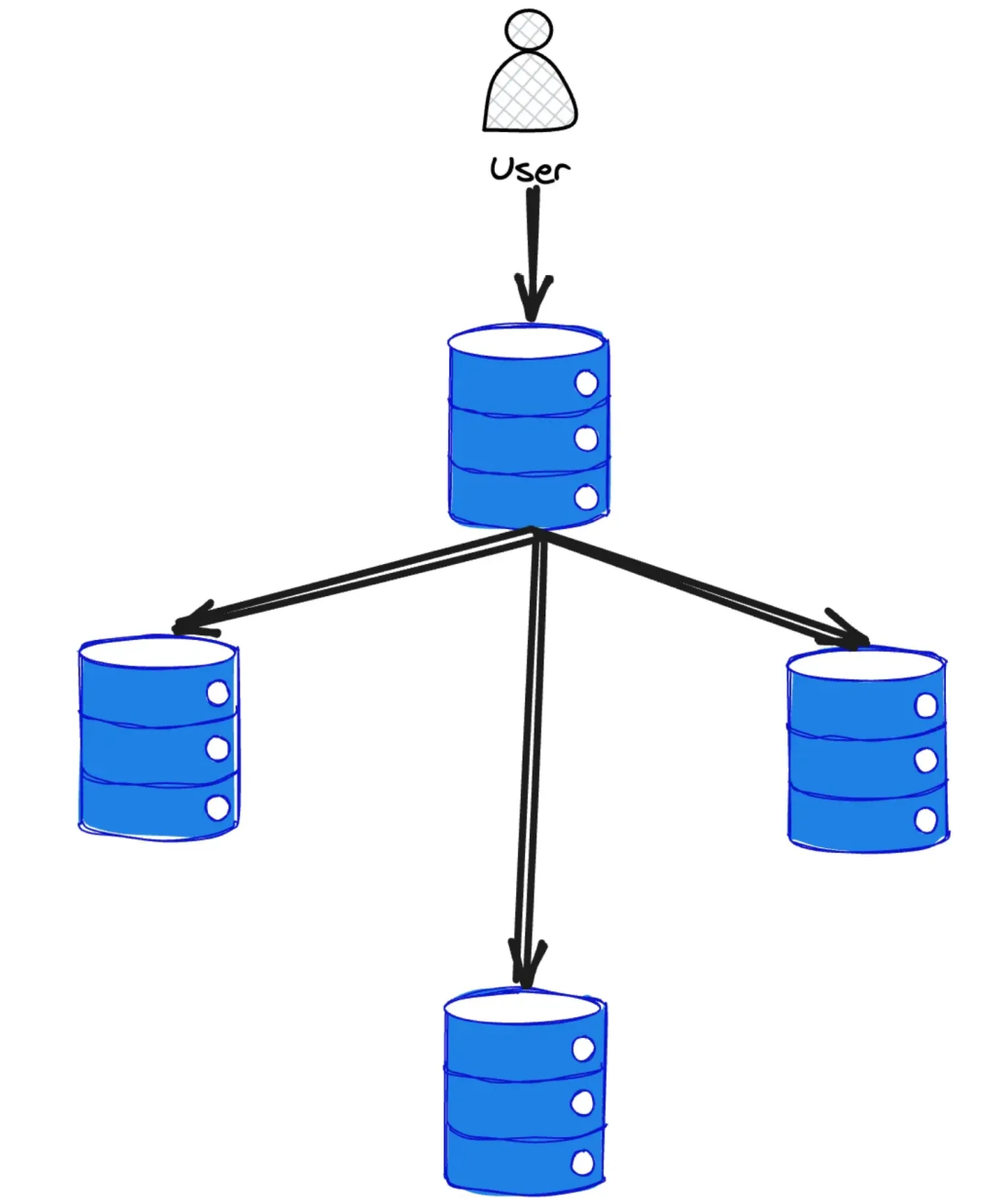
无主架构则更为激进,它完全摒弃了“主节点”的概念,允许任何副本节点处理读写请求。写入时,只要保证在“大多数”节点上成功,即认为写入成功。那么,假设其中一个节点写入失败,而读取时又恰好命中了这个节点,岂不是会发生数据丢失?为了解决这个问题,读取时就不能只查一个节点,而是需要查询多个节点,并结合写入时附带的版本号信息。只要我们能信任绝大多数节点,就能从中识别出正确的数据。
因此,在无主架构下,核心矛盾转变为 如何保证读写“大多数”的正确性。
2.3.1 读写 Quorum
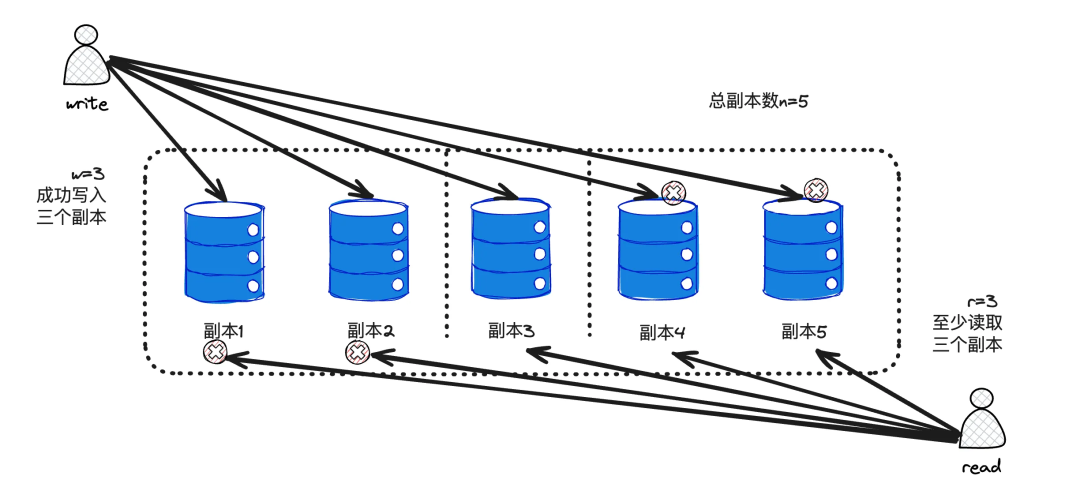
即通过写入一定数量的冗余副本来保证数据可靠性。假设有 n 个副本,每次写入需要 w 个节点确认成功,每次读取必须至少查询 r 个节点。只要满足 w + r > n 这个条件,读取时就一定能包含最新的值。为什么呢?简单来说,写入的 w 个节点和读取的 r 个节点都是总节点 n 的子集,因为 w + r > n,所以这两个子集必然存在交集,这个交集里至少有一个节点拥有最新的数据。这保证了读和写的节点之间存在重叠。
2.3.2 Quorum 面临的问题
这个方案看似完美,但仔细推敲,仍存在一些挑战:
- 牺牲可用性:当宕机节点过多,导致
n < r 时,服务将无法满足读条件,变得不可用。这符合 CAP 理论,即为了保障一致性(C),牺牲了可用性(A)。
- 边缘场景下的不一致:即使在
w + r > n 的条件下,仍可能遇到棘手情况:
- 并发写:两个写操作同时发生,由于时钟偏移,难以确定绝对的先后顺序。
- 读写重叠:写操作仅在一部分副本上完成时发生了读操作,可能返回旧值或新值。
- 部分成功:写操作在部分节点成功、部分节点失败,已成功的数据无法回滚,可能引入脏数据。
当然,也可以采用宽松的 Quorum(Sloppy Quorum)来缓解:当可用节点不满足 w 时,先将数据写入 n 个节点之外的临时节点(如其他机架的节点),待网络恢复后,再将数据同步回原节点。但这本质上是以牺牲强一致性为代价,换取了更高的可用性。
因此,在无主架构下,写入虽然不受单点限制,但在极端场景下依然无法完美保障数据的强一致性,需要业务层面能够容忍一定时间的数据不一致。
总结
为了探究分布式环境下的数据一致性,我们从数据存储架构入手,逐一剖析了主从架构、主主架构和无主架构。
- 主从架构:通过不同的复制策略(同步、半同步、异步)在一致性、可用性和性能之间权衡。
- 主主架构:解决了写入单点问题,但引入了多节点数据冲突的挑战,需要复杂的冲突解决机制。
- 无主架构:通过 Quorum 机制实现去中心化读写,但依然受限于 CAP 理论,需要在一致性和可用性间做出选择。
每种架构都有其适用的场景和固有的优缺点。在实际开发中,我们应当深入理解业务需求,明确对一致性、可用性和性能的优先级,从而做出合适的技术选型。只有清晰地认识到不同架构可能带来的“数据坑点”,才能有的放矢,构建出更加健壮可靠的软件系统。
 发表于 2026-3-7 13:30:14
|
查看: 107|
回复: 0
发表于 2026-3-7 13:30:14
|
查看: 107|
回复: 0
