本文主要分享作业帮在2025年使用 StarRocks 替换 Presto 作为核心即席查询引擎的探索与实践,内容涵盖历史背景、技术选型思考、具体技术方案以及迁移过程中遇到的核心问题与解决方案。
历史背景
在启动迁移项目前,我们面临的几个主要背景是:
- Presto 主要应用于即席查询场景,天级查询量约2000~5000次,平均查询耗时在分钟级别,整体体验偏慢。
- Presto、Yarn、HDFS 混部部署,进程间仅有内存资源限制。在业务高峰期,宿主节点的CPU几乎被占满,严重影响了查询体验,业务方反馈不佳。
- 团队在 toB 系统的 OLAP 场景已使用 StarRocks 多年,对其理解比对 Presto 更为深刻。并且高版本的 StarRocks 在存算分离架构下已支持 Trino Dialect。
- 线上 Presto 版本较老,无法支持查询已有的 Iceberg 表。
技术选型与方案
StarRocks 采用了全面向量化引擎和基于 CBO(成本优化器)的智能查询规划,在复杂的多表关联查询场景下性能表现优异。同时,它原生支持 Iceberg 表查询能力,且社区活跃,技术迭代速度快。鉴于我们在存算一体场景已有丰富的 StarRocks 使用经验,最终决定采用 StarRocks 来全面替换 Presto。
我们的核心目标是在避免对业务产生扰动的前提下实现正向收益,因此工作的重点在于平台层面的架构适配、解决语法兼容性问题、进行性能调优以及平滑迁移任务。
整体架构
下图展示了替换后的即席查询整体架构:
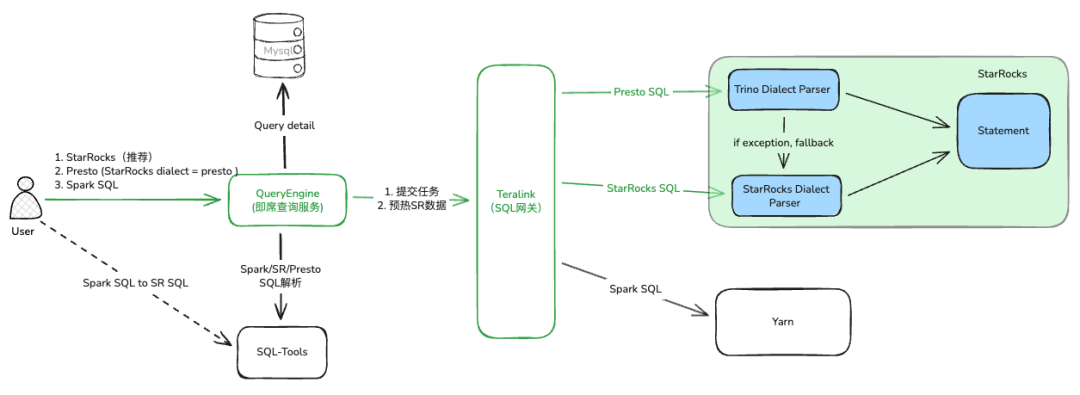
用户通过数据平台编辑 SQL 任务,提交给 QueryEngine(即席查询服务,负责任务管理、语法校验、结果脱敏等)。QueryEngine 再将任务提交给计算网关 Teralink(负责权限认证、审计、分发、收敛引擎入口等)。Teralink 根据具体的执行引擎,将查询提交给对应的集群。
在此架构中,StarRocks 采用存算分离模式部署,通过 Catalog 机制查询 Hive、Iceberg 等数据源。为适应未来的弹性需求,我们将 StarRocks 和 Spark 均部署在 Kubernetes 上。
为了最大化兼容原有 Presto SQL 语法,降低业务改造成本,我们在 StarRocks 内部采用了双解析器策略:优先使用 Trino Dialect Parser 进行解析;当解析异常时,会回退到 StarRocks 原生 Dialect Parser 作为补充。
在迁移阶段,我们在 QueryEngine 层设置了防御措施:当查询在 StarRocks 集群上失败时,会自动回退到 Presto 集群执行,以保证查询的可用性。在数据准确性保障方面,我们基于双跑结果建立了 StarRocks SQL “指纹库”。对于指纹库之外的查询,我们会进行结果差异(diff)比对,确保数据准确,并不断完善指纹库信息。遇到预期之外的差异,则人工介入分析解决。
双跑验证流程
从资源节省的角度考虑,我们没有让 Presto 和 StarRocks 使用完全对等的资源。Presto 沿用现有混部集群(约2500多核,白天CPU有空闲),而 StarRocks 则使用一个较小的测试集群(6个 CN 节点,共192核)。
我们在业务低峰期,针对过去一段时间内产生的成功查询进行双跑验证,具体流程如下图所示:
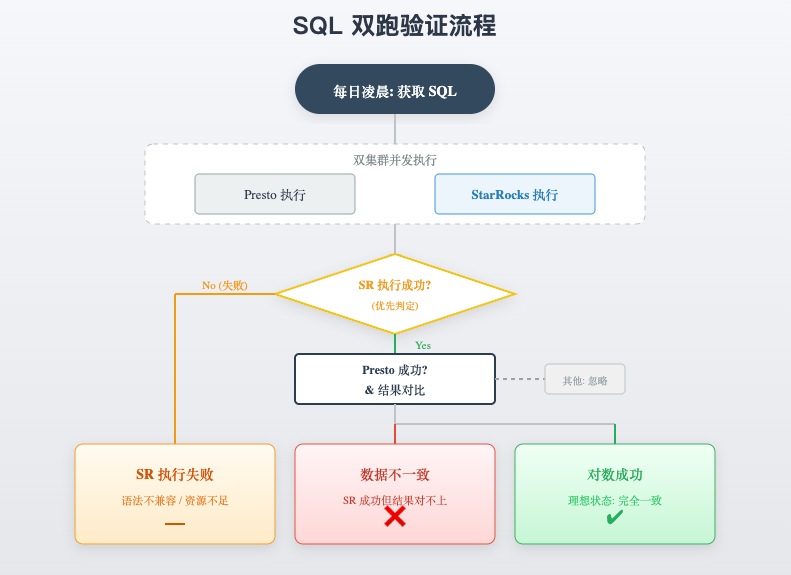
主要步骤如下:
- 过滤出 Presto 执行成功的 SQL。
- 对这些 SQL 进行
EXPLAIN,如果 EXPLAIN 不通过则跳过并记录。
- 让 SQL 在 Presto 和 StarRocks 集群上串行执行(StarRocks 会执行多次以观察缓存效果),记录执行耗时、结果数据等信息。
- 分析耗时差异,并利用
SUM(HASH(column)) 等方式对比两个引擎的查询结果是否一致。
验证结果分析
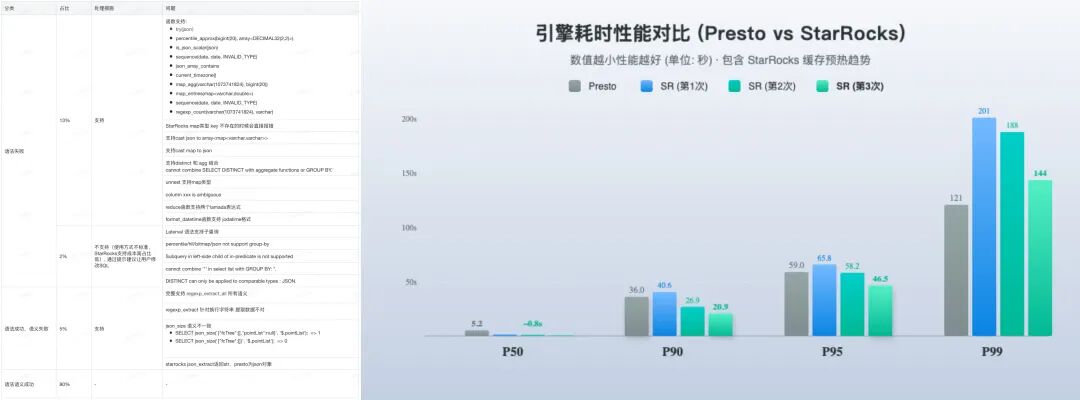
- 语法兼容性结果:经过三个多月的双跑验证和差异分析,我们遇到了一些语法或语义不兼容的问题。其中大多数问题通过平台侧或引擎侧的改造得以解决;少数开发成本高且使用频率低的语法,我们采取报错并提供替代方案的方式处理。
- 性能结果:StarRocks 的整体查询性能符合预期。尤其是在数据缓存预热后,查询性能提升非常明显。下图展示了 Presto 与 StarRocks 在不同分位数(P50, P90, P95, P99)下的引擎耗时对比,数值越小越好。
缓存加速策略
由于历史原因,我们使用对象存储(Cos)替代了 HDFS,实现了离线场景的存算分离。查询远端 Cos 上的数据与查询 StarRocks Data Cache 中的数据,在性能上有巨大差距。Cos 本身没有数据格式的概念,查询引擎难以利用 Parquet 等格式的特性进行数据裁剪(Data Pruning),加之网络请求开销,查询速度会显著下降。
为了尽可能提升查询性能,我们实施了缓存预热策略:通过解析历史查询 SQL,获取最近 N 天内被查询过的表,并监听这些表的新增分区事件,自动触发查询以将数据预热到 StarRocks 的 Data Cache 中。预热后的缓存命中率情况如下图所示:
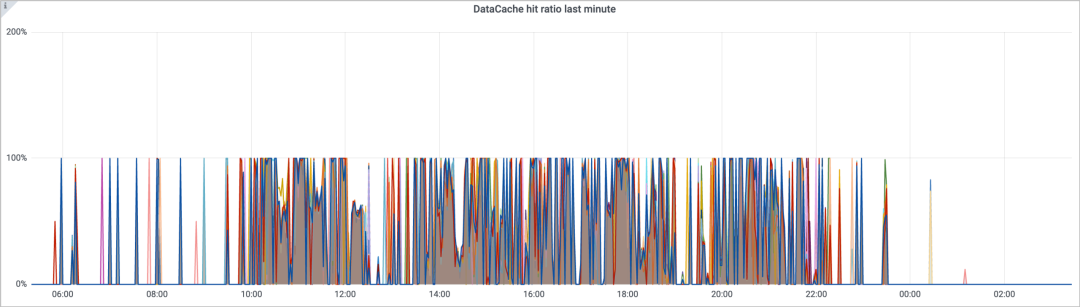
分析 Data Cache 的原理,缓存文件的位置是由 CN 节点数量、Host IP 和 Port 共同决定的。在 K8s 上,我们的 StarRocks CN 节点采用 StatefulSet 方式部署。虽然目前尚未启用弹性扩缩容,但 CN Pod 的重启或重建会影响 Data Cache 的分布(缓存失效)。因此,我们目前的部署策略是:固定资源池 + Pod 滚动重启/重建 + Pod 规格基本占满物理节点,以此控制 Pod 不发生漂移。后续,待云上能力支持完善后,我们计划采用 Local PVC 来防止 Pod 漂移,并考虑引入 StarRocks 4.0 新增的缓存共享能力。
迁移过程中遇到的核心问题与解决方案
在从 Presto 迁移至 StarRocks 的过程中,我们遇到了多个技术挑战。以下是一些典型问题的分析及我们的解决思路。
1. 平台侧语法解析慢
- 问题背景:平台侧通过
EXPLAIN 语句来实现 SQL 语法检测。Presto 的 EXPLAIN 基本秒级返回,而 StarRocks 的 EXPLAIN 有时耗时超过 30 秒甚至 1 分钟。
- 原因分析:StarRocks 的
EXPLAIN 过程包含多个阶段:Parse、Analyze、Logical Plan、SQL Optimize、生成 Plan Fragment。分析 Profile 发现,耗时主要发生在 SQL Optimize 阶段,特别是 RBO/CBO 优化器获取查询元信息(如表分区、文件列表等)时。StarRocks 现有的 EXPLAIN 能力不支持跳过 SQL 优化阶段。
- 解决方案:调整语法检测的 SQL 为:
EXPLAIN SELECT * FROM ( {用户原始SQL} ) WHERE 1!=1。这样可以在不真正读取数据的情况下,更快地完成语法和部分逻辑计划的检查。
2. 查询取消(Cancel)无效
- 问题背景:平台侧需要对运行中的查询(包括 StarRocks、Presto、长时 Spark 任务)提供取消能力。
- 原因分析:这实际上是两个问题:
- 在 Teralink(基于 Kyuubi 二次开发)中,
JdbcSQLEngine 通过调用 MySQL Statement.close() 来处理取消请求。但 Statement.close() 需要获取一个内部操作锁,而该锁只有在 SQL 执行结束后才会释放,导致取消请求被阻塞,无法真正中断 SQL 执行。
- MySQL
Statement.cancel() 会创建一个新连接。而 StarRocks 对外暴露的是负载均衡器(LB),默认未开启会话保持。新建的连接可能会被路由到不同的后端 FE 节点上,导致取消命令无法找到原查询所在的会话。
- 解决方案:
- 改造
JdbcSQLEngine,在 JdbcDialect 中引入自定义的 cancel 方法。在取消流程中,先尝试取消 Statement 的执行,然后再进行 close,以确保 SQL 能被正确终止。
- 在 Teralink 层为取消操作设置重试策略。当检测到因连接路由问题导致的取消失败时,自动重试取消命令,并设置重试上限。
3. 查询 Iceberg 表导致 FE OOM
- 问题背景:查询 Iceberg 表时,FE 节点内存波动剧烈,偶发 OOM 导致 Pod 重启。
- 原因分析:查询 Iceberg 表时,StarRocks FE 的大致逻辑是:1) 检测
metadata.json 文件更新时间判断元数据缓存是否过期;2) 若过期,则拉取对应的 snapshot 文件并获取 manifest list (如 m0.avro) 文件列表;3) 解析 m0.avro 文件列表以定位实际的数据文件。当 Iceberg 表非常大或频繁更新时,会产生大量 m0.avro 文件。第2步会缓慢增加 FE 内存,第3步则可能导致 FE 内存急剧上升,引发 OOM。
- 解决方案:
- 关闭 Iceberg 表的元数据缓存,避免缓存大量 manifest 信息。
- 利用 StarRocks 自身的
skip_manifest 文件扫描能力,在查询时快速进行分区过滤并定位 m0.avro 文件,减少不必要的元数据加载。
4. Iceberg 表 plan_mode = distributed 报错
- 问题背景:查询某些 Iceberg 表时,稳定报错:
metadata table not found。

- 原因分析:StarRocks 处理 Iceberg 表有两种计划生成模式:
- 本地模式:使用 FE 解析
metadata.json + snap.avro + m0.avro 文件。
- 分布式模式:预设一个虚拟的 metadata 表及其结构,将 Iceberg 表的元数据 avro 文件当作普通 Hive 表的 avro 文件,利用 CN 节点进行分布式处理。
StarRocks 会根据待扫描的 m0.avro 文件总大小和数量自动选择模式。当选择 distributed 模式时,在权限验证阶段会强制从 Hive Metastore 获取这个虚拟的 metadata 表的元数据,而该表并不真实存在,因此报错。
- 解决方案:修改 StarRocks 源码,在权限验证阶段,如果检测到表类型是 Iceberg 的虚拟元数据表(metadataTable),则跳过元数据获取步骤。
5. multi_distinct_count 执行慢
- 问题背景:当 SQL 中含有多个
COUNT(DISTINCT column) 表达式时,单个 CN 节点内存使用极高、CPU 空闲,执行速度慢,且无法并发执行。
- 原因分析:对于包含
COUNT(DISTINCT) 的查询,StarRocks 优化器有内部判断逻辑:
- 如果数据量很大,会分出多个数据流分别进行流式聚合,最后通过嵌套循环连接(NestLoop Join)合并结果。执行计划示例如下:

- 如果数据量小且列的基数(Cardinality)低,则会重写为
multi_distinct_count 函数进行单点执行。执行计划示例如下:
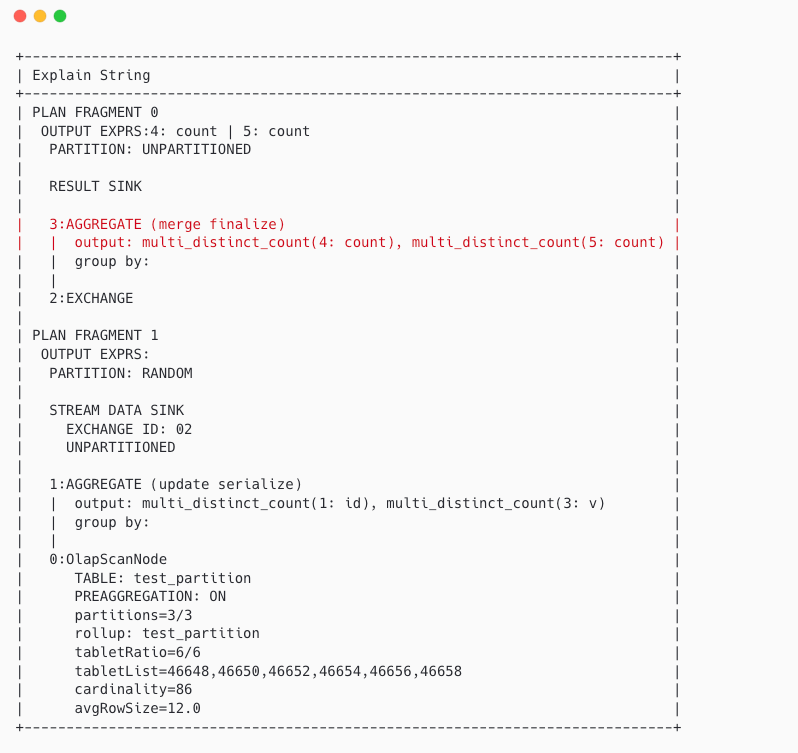
- 问题根因:当表缺乏准确的统计信息时,优化器可能误判,在数据量很大的情况下错误地采用了第2种方案(
multi_distinct_count),导致单点内存爆炸和性能低下。
- 解决方案:由于无法保证所有表都有完整的统计信息,我们选择全局禁止
multi_distinct_count 优化。通过设置 SET GLOBAL prefer_cte_rewrite = true;,牺牲小查询场景下的潜在性能收益,以保障整体查询速度的稳定性。
6. 执行计划生成耗时过长
- 问题背景:StarRocks 为了生成更优的执行计划,会在优化阶段进行详细的统计信息收集,导致 Plan 阶段耗时很长。此外,为保证数据准确性,我们关闭了 FE 的文件元数据缓存,加剧了这个问题。
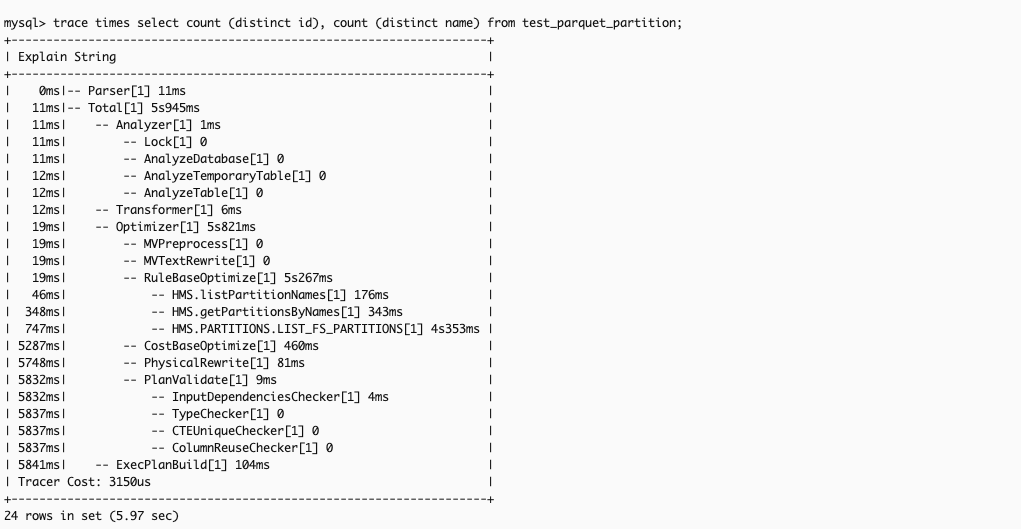
- 原因分析:通过
TRACE TIMES 分析具体 SQL(如下图所示),发现在 Hive 表统计信息缺失时,优化器会尝试获取全量分区文件列表来推导统计信息。当 Hive 表文件数量极多时,RBO 阶段的速度会非常慢。
- 解决方案:
- 增大
async_refresh_max_thread_num 参数至 128,以 128 个线程并发获取分区的文件列表。
- 存算分离查询数据湖时,默认的超时时间可能偏低,通过
SET GLOBAL new_planner_optimize_timeout = 60000; 增大优化器超时时间来缓解。
7. 外层加 LIMIT 导致结果乱序
- 问题背景:为限制 SQL 返回的数据条数,平台代理层会在原始 SQL 外层自动嵌套一层
LIMIT n 表达式。
- 原因分析:增加
LIMIT 后,分析 EXPLAIN 发现,因为外层没有 ORDER BY 条件,优化器可能误判内层的 ORDER BY 是冗余的,从而将其删除,导致查询结果不符合预期。下图展示了增加 LIMIT 前后执行计划的变化:

- 解决方案:使用
SET GLOBAL sql_select_limit = n; 来替代外层嵌套 LIMIT 的方式。该设置会在执行计划树中添加一个 TOP-N Node,从而保留内层的排序逻辑。
8. 中间结果落盘导致 CN Core Dump
- 问题背景:为缓解查询内存不足的问题,我们开启了中间结果落盘(Spill)功能,但在 Spill 过程中偶发 CN 进程 Core Dump。
- 原因分析:中间结果落盘时,如果单批待压缩的数据过大,会触发 LZ4 压缩库的内部限制,导致 CN 进程崩溃。报错信息如下图所示:

- 解决方案:修改 StarRocks 源码,在 Spill 过程中增加判断:当单批数据过大时,跳过 LZ4 压缩,直接将原始数据落盘。
9. CN 节点内存不足
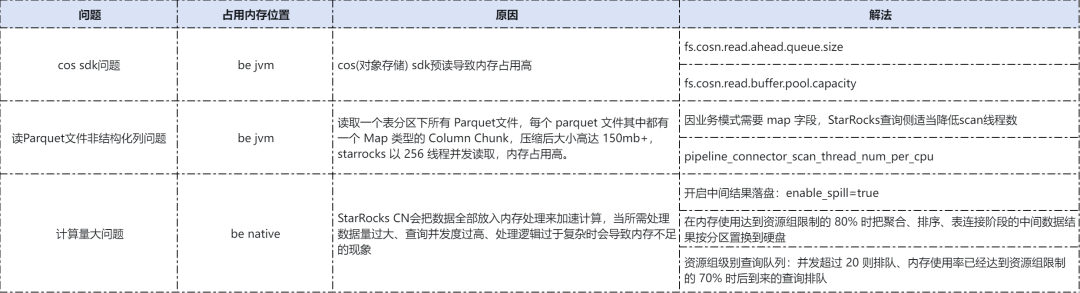
线上环境采用约30多台 32核128GB 规格的机器,数据量 PB 级,最大并发约30。偶尔会出现 StarRocks CN 节点内存过高,导致 Full GC 甚至 Pod 被 Kill 的问题。内存问题通常比较复杂,从实际运行情况看并非单一原因。CN 节点内存占用情况主要分布在以下几个部分,具体原因和解决方案如下表所示:
项目收益
项目上线后,整体运行平稳,主要带来了三方面的收益:
- 资源收益:原有的 Presto 集群总计占用约 4300 核的计算资源。迁移到 StarRocks 后,我们仅使用了约 1000 核的资源,资源利用率显著提升。
- 架构收益:将原先多个独立的 Presto 集群统一为一个 StarRocks 集群进行管理。容器化部署也为后续与 Spark 任务共享资源池、实现弹性扩缩容奠定了基础。
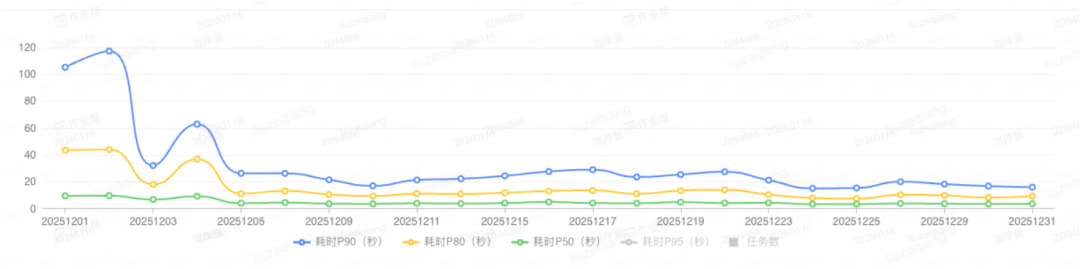
- 性能收益:对比迁移前后,P90 查询耗时缩短了 2 到 3 倍,查询响应速度大幅提升,用户体验得到明显改善。下图展示了上线后的性能趋势:
未来规划
基于当前的成果,我们计划在以下方面继续深化:
- 自动将即席查询中的 Spark SQL 转化为更高效的 StarRocks SQL,进一步加速查询。
- 实现白天即席查询(StarRocks)与晚上例行 Spark ETL 任务之间的资源弹性调度,提高整体资源利用率。
本次从 Presto 到 StarRocks 的迁移,不仅是一次引擎的替换,更是对大数据查询架构的一次重要升级。整个过程涉及了语法兼容、性能调优、稳定性保障等多个层面的挑战,其经验对于面临类似选型或迁移场景的团队具有一定的参考价值。对于更多此类 数据库/中间件/技术栈 的深度实践,欢迎关注 云栈社区 上的技术分享。
 发表于 2026-3-12 02:47:30
|
查看: 407|
回复: 0
发表于 2026-3-12 02:47:30
|
查看: 407|
回复: 0
