在传统数据架构中,企业常常面临模型缺乏版本控制、测试依赖人工、文档分散、血缘关系缺失等一系列问题,这直接导致了数据迭代缓慢、变更风险高、团队协作困难。
为了解决这些痛点,SJM Resorts 基于 dbt + DataOps + StarRocks 构建了一套“三合一”的数据体系,其核心目标明确:
- 实现数据模型的快速迭代与秒级回滚能力。
- 显著缩短从业务需求提出到最终上线的交付周期。
- 从根本上确保数据资产的准确性、一致性与可审计性。
本文整理自相关实践者在 StarRocks Connect 2025 大会上的分享,重点探讨如何通过 dbt、DataOps 与 StarRocks 的深度融合,打造一个高效、可靠且全链路可追溯的企业级数据平台。
二、核心组件与实践
(1)dbt:以工程化方式管理数据模型
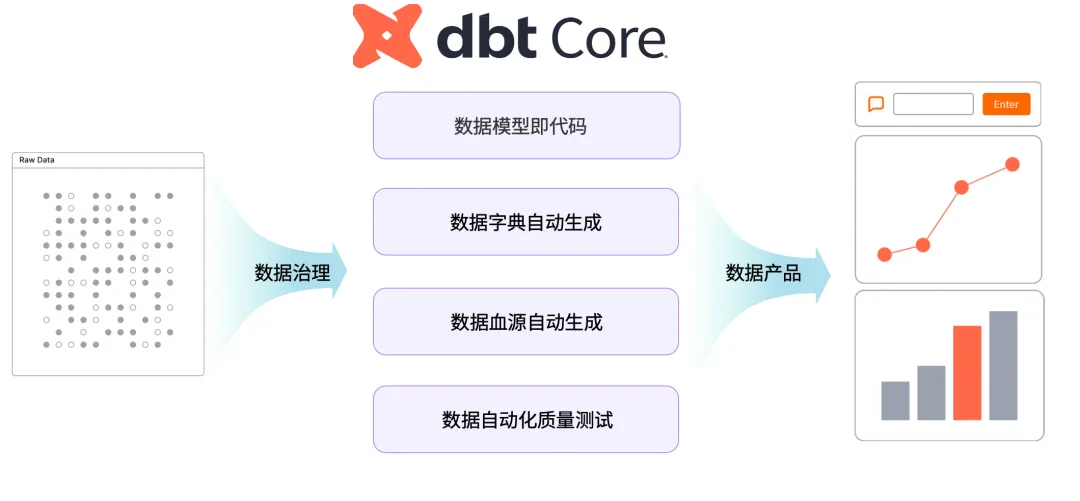
首先需要明确,dbt 并非传统的 ETL 工具,它是一个 “数据模型即代码”(Data as Code) 的实现框架。它将数据建模、测试和文档编写都纳入代码管理的范畴。其主要提供几项核心能力:
- 模型构建:每个 dbt model 本质上是一个 SQL 模板,支持 staging -> marts 的分层建模范式。例如,先定义
stg_customer 清洗模型,再基于它构建下游的聚合业务模型。
- 依赖自动调度:dbt 能够根据
ref() 函数自动解析模型之间的依赖关系,并按照拓扑顺序执行,无需依赖额外的调度器。
- 版本控制:所有模型定义、YAML 配置文件、文档都纳入 Git 进行管理,通过 Pull Request (PR) 流程进行审核后发布,实现了代码化协作。
- 对象支持:原生兼容 StarRocks 的 Table、View、物化视图(MV)、Task 等多种对象,实现从数据湖到数据服务全链路的版本化管理。
实践案例:当某个客户标签的逻辑出现错误时,数据团队可以在独立的 feature 分支上进行修复和回滚,经过 CI/CD 流水线验证后快速部署上线,整个过程可以控制在 30 分钟以内。
(2)自动化数据治理能力
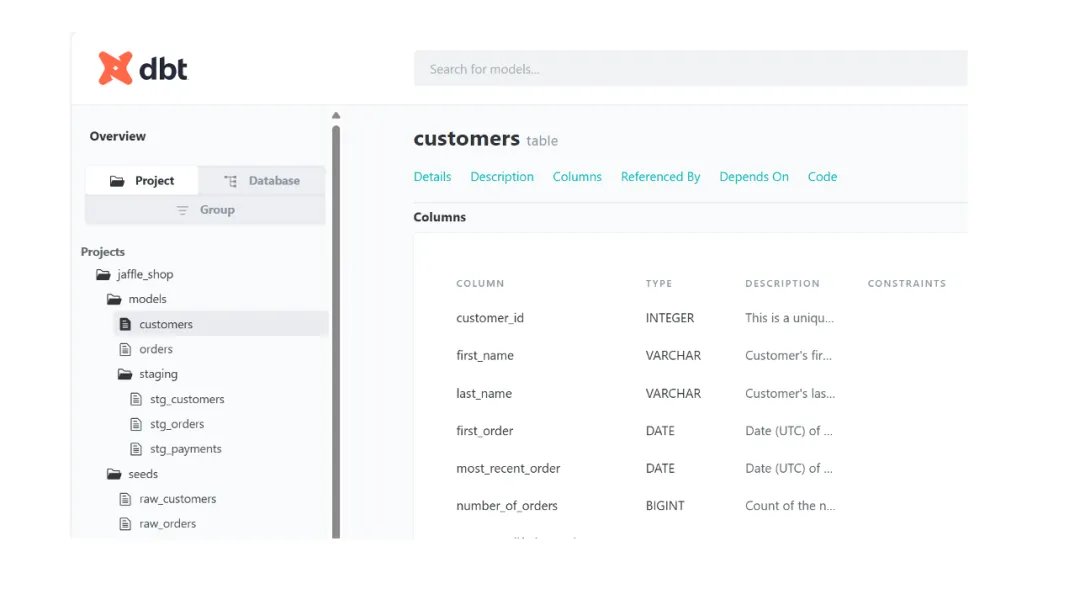
除了模型管理,dbt 在数据治理层面也提供了三大关键自动化输出,这对于提升团队协作效率和数据可信度至关重要。你可以在 云栈社区 的大数据板块找到更多关于数据治理的深度讨论。
- 数据字典:能够自动生成美观的 HTML 文档,其中包含字段的业务含义、详细描述、背后的代码实现逻辑以及上下游依赖关系,并支持根据企业品牌进行界面定制。
- 数据血缘:自动可视化展示从原始数据表到最终业务报表的完整链路。例如,在酒店集团的“Customer 360”项目中,当修改 PMS 系统的核心订单表时,系统能自动识别并提示此变更将影响下游的 12 个数据模型和 8 张业务看板。
- 质量测试:通过 YAML 文件配置字段级别的数据质量规则(如
not_null、unique、relationships 等),并支持每日定时运行。一旦发现异常,系统会自动告警,有效阻止脏数据流入消费端。
优化点:部分团队开始尝试利用 AI 辅助生成 YAML 测试配置模板,这在一定程度上提升了配置效率,但核心的业务逻辑校验仍然需要人工把关。
(3)DataOps:将 DevOps 理念落地到数据领域
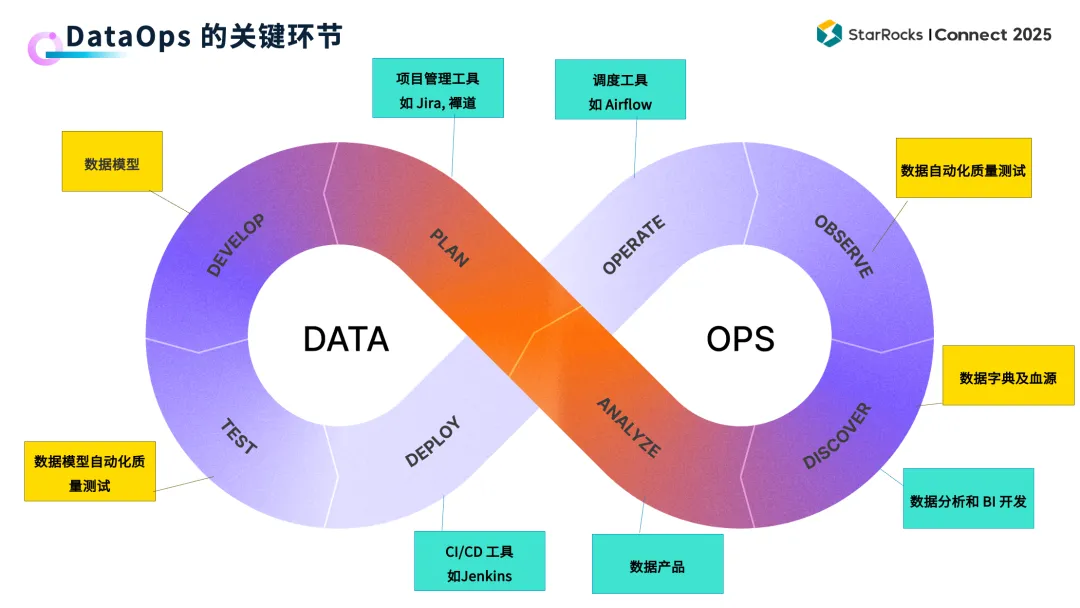
DataOps 不是某个具体的新工具,而是一套 覆盖数据全生命周期的工程实践与方法论,旨在将软件开发中成熟的 DevOps 文化引入数据领域:
- 协作流程:使用 Jira 或禅道等工具管理数据需求与缺陷,用 Git 管理所有数据模型代码,并通过 Jenkins 或 GitLab CI 等工具驱动自动化流水线。这种将开发流程规范化的做法,正是现代 运维/DevOps/SRE 实践的核心。
- 提交规范:采用 Conventional Commits 规范(如
feat: add region field、fix: correct revenue calc),这不仅使提交历史清晰可读,还能自动推导语义化版本号(例如从 v2.1.0 升级到 v2.2.0)并自动生成 Release Note。
- CI/CD 流程:
- 提交 PR 后自动触发代码规范检查(如 SQL 格式、命名规范校验)。
- 自动部署到 staging(预发)环境,并运行单元测试与数据验证。
- 由负责人工审核变更的影响范围。
- 合并至主干代码库后,自动发布至生产环境。
避坑经验:初期曾因追求速度而跳过 staging 环境的测试直接上线,导致某张核心维度表的逻辑错误,影响了全站的 GMV 报表。此后团队强制规定,所有数据模型变更都必须通过 staging 环境的完整验证才能进入生产。
(4)StarRocks:统一实时与离线分析底座
在传统架构中,实时分析(Kafka+Flink)与离线分析(Hive+Spark)通常是两套独立的链路,带来了高昂的开发和维护成本。而 StarRocks 通过其 Lakehouse 架构 实现了二者的融合:
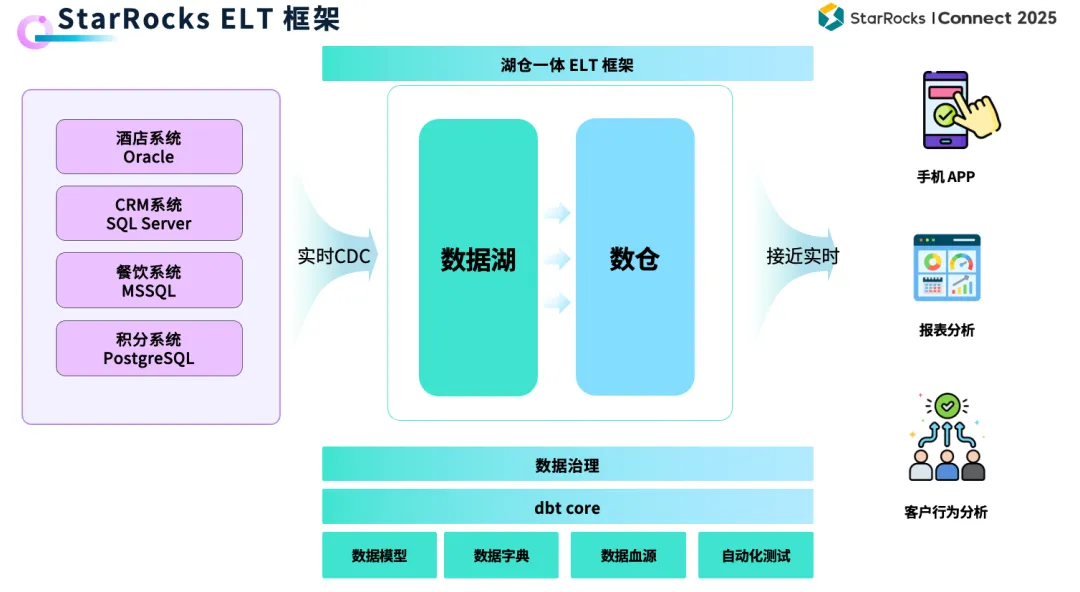
- 数据摄入:通过 Flink CDC 等技术,将来自多种业务源(如 Oracle、MySQL、SQL Server)的数据实时同步至 StarRocks 的内部表或外部湖表(如 OSS/S3)。
- ELT 模式:原始数据进入数据湖后,转换(Transform)的负载主要由 dbt 在强大的 StarRocks 引擎内部完成,实现了轻量、灵活的 ELT 模式,避免了复杂的重型 ETL 流程。
- 统一服务:同一份数据可以同时支撑手机 App 的实时查询、BI 团队的报表分析、以及客户行为分析等多种场景,将数据查询延迟控制在分钟级别。
效果验证:某酒店集团的实时预订情况看板,从原来的 T+1 延迟升级为近实时更新,数据延迟从 24 小时大幅降低至 5 分钟以内。
三、整合收益与关键成果
通过将 dbt、DataOps 与 StarRocks 深度整合,企业获得了以下可量化的价值提升:
| 维度 |
改进前 |
改进后 |
| 需求交付周期 |
2~3 周 |
3~5 天 |
| 模型故障恢复 |
数小时(依赖人工排查) |
<30 分钟(支持自动回滚) |
| 文档一致性 |
Word/PPT 分散管理,易不同步 |
Git 统一版本管理,随代码变更强制同步更新 |
| 数据可信度 |
依赖不定期的、抽查式的人工校验 |
每日自动化质量巡检 + 精准的血缘影响分析 |
四、未来展望
当前的三合一数据体系已经验证了其可行性与巨大价值,下一步的探索方向可能包括:
- AI 辅助建模:结合大语言模型(LLM),尝试自动生成 dbt 模型的初版 SQL 代码以及配套的数据质量测试用例,进一步提升开发效率。
- 血缘增强:与 Apache Atlas 等企业级元数据管理平台集成,实现从消息队列(Kafka)、流处理(Flink)到数据仓库(StarRocks)的端到端全链路血缘追溯。
- 成本优化:充分利用 StarRocks 的资源组隔离与弹性扩缩容能力,更精细地管理计算资源,有效降低业务高峰期的负载成本。
结语
dbt + DataOps + StarRocks 的技术组合,其目标并非追求技术的炫酷,而是 以工程化的思维系统性解决数据领域长期存在的协作、质量和效率问题。
成功的核心关键在于:真正将数据视为代码,并用经过验证的软件工程最佳实践来管理和运营数据资产。这一实践路径已在酒店、零售、金融等多个行业得到验证,对于寻求数据驱动转型的企业而言,具有很高的借鉴和参考价值。 |  发表于 2026-4-21 23:24:06
|
查看: 166|
回复: 0
发表于 2026-4-21 23:24:06
|
查看: 166|
回复: 0
