摘要:
本文通过对比Palantir Ontology与传统数仓建模方法,揭示了“本体论”如何成为企业构建可信语义层与灵活数据模型的核心工具。文章详细介绍了本体论的概念、发展脉络、现实挑战,以及LLM驱动的自动本体生成与协作优化方案,旨在为数据治理与智能分析领域的专业人士解锁新范式。
什么是Ontology?企业数据模型的语义革命
本体论(Ontology)的起源与演变
Ontology,或译为“本体论”,其根源可追溯至哲学领域,用于系统性地描述事物、属性及其间关系的形式化结构。随着企业对数据语义一致性需求的日益增长,本体论逐渐演变为构建可信数据语义层和可靠业务模型的关键方法论。
以Palantir为代表的领先厂商,正将Ontology理念推向实践前沿。它们通过提供具备语义理解能力的动态数据关系模型,帮助企业灵活、快速地映射并响应实时变化的业务逻辑。
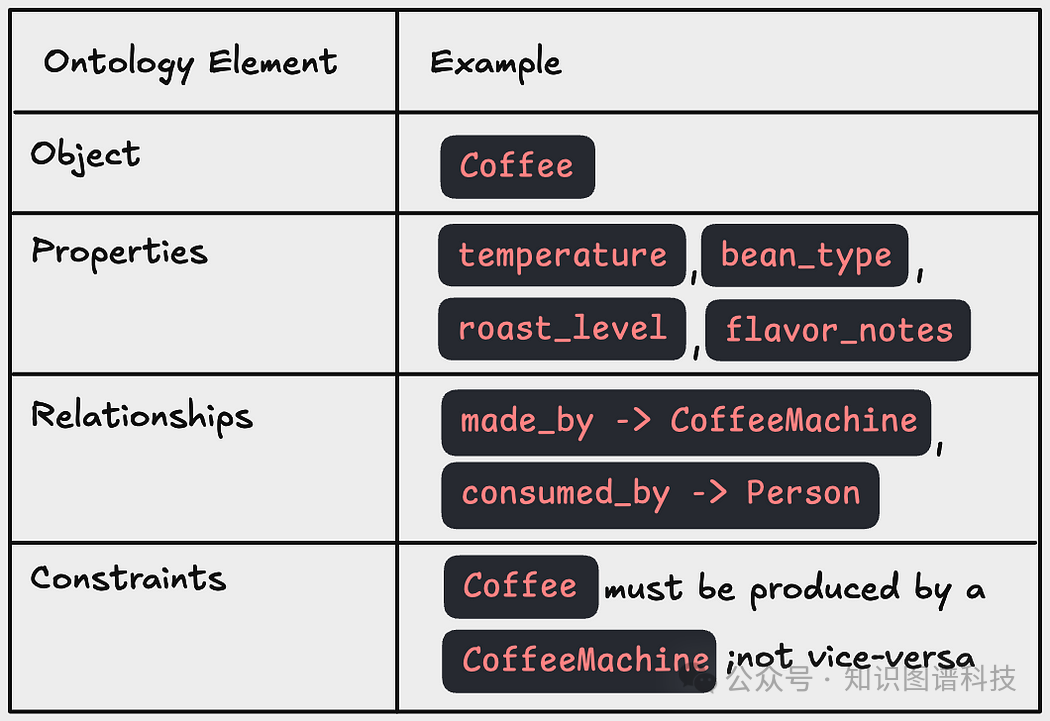
举个例子,一个简单的“咖啡本体论”就能囊括饮品类型、配料、烘焙程度、风味笔记以及用户偏好等多个实体和属性,构建出一个能反映真实世界语义关系的数据图谱。
为什么企业需要语义层?
无论是“单一事实来源”、“黄金记录”还是“语义层”,企业的核心诉求始终如一:确保任何人(无论是分析师还是业务人员)都能准确、高效地查询并获得真实反映业务状况的数据答案。
例如,当一位分析师提问:“上个月有多少高级用户购买了意式浓缩咖啡?”,其背后支撑的本体论必须确保“高级用户”、“购买”、“意式浓缩咖啡”这些术语的定义和计算逻辑与业务实际完全一致,从而避免查询结果的歧义和数据失真。
传统建模:星型与雪花模式的挑战
星型模式
在20世纪90年代,星型模式以其事实表为中心、维度表环绕的结构,显著提升了数据查询的速度和简洁性。它将数据严格划分为“维度”(如客户、产品等描述性数据)和“事实”(如交易、订单等度量数据)。然而,这种刚性划分一旦遇到业务的快速变化(如定价策略调整、产品线更新),原先精心设计的结构就会变得僵化,难以适应。
雪花模式
雪花模式在星型模式基础上,对维度表进行了进一步的规范化,以减少数据冗余。但代价是引入了更复杂的多层联接(Join),不仅增加了查询的复杂性,也对性能构成了潜在风险。
无论是星型还是雪花模式,其“事实-维度”二元对立的范式,本质上要求业务世界相对静态,工程师才能雕刻出“整齐划一”的数据模型。但现实中的企业业务千变万化,传统建模方法往往难以灵活响应。
Palantir Ontology:将数据模型升级为图结构
Palantir的创新之处在于,它彻底抛弃了事实与维度的传统分类限制,转而将每一张数据表都建模为一个有向图中的节点,节点之间通过类型明确的边(如一对一、一对多)进行连接。
这样一来,分析师无需再猜测表与表之间该如何关联(Join),只需沿着图中已定义好的明确路径进行探索,即可轻松查找实体关系。当业务引入新的对象或关系时,建模人员只需在图中添加一个新的节点或一条新的边即可,极大地提升了模型的迭代速度和灵活性,无需为了适配早期定下的数据结构而“削足适履”。
这种图结构的语义逻辑具有高度的流动性,使得企业能够实时映射业务变迁,持续保持数据模型与业务现状的同步。
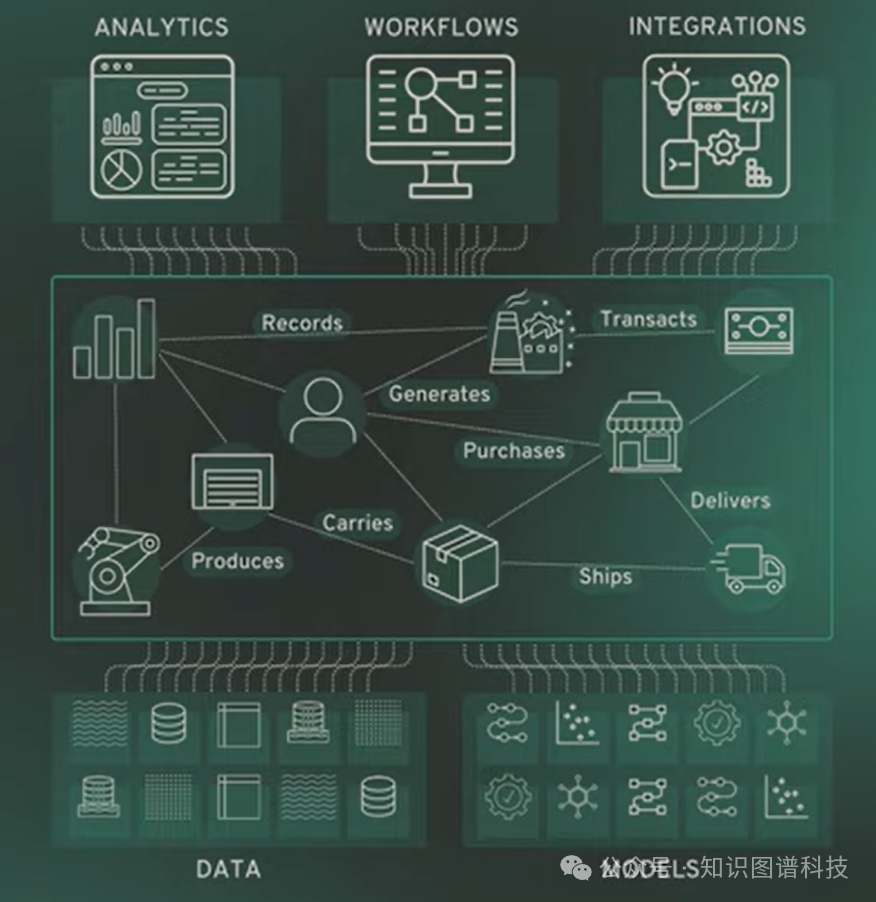
持续变化为何让本体论变得至关重要?
无论是瞬息万变的监管要求、层出不穷的网络安全威胁,还是初创公司产品策略的频繁切换和用户的指数级增长,现代企业的数据结构可能在短时间内就面目全非。
原本一个季度才需要修改一次的数据表结构,如今可能每周都在变动。这直接导致原有的数据仓库管道、业务度量标准全部失效,其代价最终会体现在数据仪表板的延迟、数据的重复矛盾以及基于错误信息的决策失误上。
传统上,Palantir等公司通过派驻“现场工程师”深度嵌入客户团队,手动维护和迭代本体论,为全球500强企业提供定制化服务。而初创企业则往往为了追求发展速度,不得不承受“分析债务”,接受数据层面暂时的混乱。

LLM彻底改变本体论建设方式
LLM的出现,为本体论的生成和维护带来了革命性的变化,使其成本急剧降低。只需连接到企业的数据仓库,LLM就能够快速扫描数千张数据表,通过分析字段名、主外键分布以及值的语义相似性,自动总结出数据模型,同时识别出对象关系(如表间的主从、类型关联)以及关系的多重性。
以往,一位资深数据分析师可能需要耗费数周时间才能梳理清楚的数据结构,如今LLM在几分钟内就能形成初步理解,并生成结构化的本体图谱。
然而,LLM并非万能。它缺乏具体的业务上下文,很容易产生“幻觉”或遗漏关键的边界场景。例如,它可能无法判断“客户”这个实体是否应该包含“免费试用用户”?某些关键业务指标的计算逻辑是否具有企业特定的语境?这些细微但至关重要的区别,仍然需要依赖领域专家的知识和经验来把关和修正。
Astrobee协作层:让本体论持续生长
Astrobee可以看作是一个介于领域专家和LLM运行环境之间的智能协作层。它的工作流程通常包括以下几步:
- 数据提取:自动抓取数据仓库中的表结构、血缘关系等信息,为LLM生成本体论提供原材料。
- 初稿生成:LLM基于提取的信息,提出候选的实体、关系、验证条件,甚至生成相应的SQL或数据管道代码。
- 协同评审:业务专家和数据分析师可以像使用Git Diff审阅代码一样,审查、评论、修改LLM提出的每一处变动。Astrobee会记录下每一次决策和反馈。
- 全民赋能:最终,全公司员工都可以基于这套不断优化的本体论,使用业务语义直接查询数据,这套本体论就是公司统一的“事实来源”。
随着查询请求的累积,Astrobee能够识别出常用的联接模式,并自动生成可复用的数据管道。而那些成本高昂的一次性临时查询,则可能被建议转化为全公司统一的标准化指标。每一次人机协作的问答,都在持续优化本体论,从而提升后续数据决策的洞察力。
知识图谱工具链带来的效果是显著的:大型企业可以在不急剧扩张数据团队规模的前提下,从容应对“模式漂移”(Schema Drift);而初创企业则能够以种子轮的预算,实现企业级的数据建模敏捷性。
总结:Ontology驱动的企业智能数据新范式
本体论作为数据语义层的核心,正不断推动企业面向动态业务环境,实现实时的数据治理和智能分析。它将数据与真实的业务对象一一映射,并通过LLM与Astrobee等新一代协作工具的赋能,实现了从“静态建模”到“动态演进”的关键跃迁。
这最终将帮助企业随时应对业务变革,有效提升数据的准确性、一致性和决策的响应速度。如果你对人工智能如何重塑数据基础设施这类话题感兴趣,欢迎在云栈社区交流探讨。
 发表于 2026-4-13 06:49:32
|
查看: 206|
回复: 0
发表于 2026-4-13 06:49:32
|
查看: 206|
回复: 0
