
Why Your Enterprise AI is Built on Sand: The Power of Evidence-Backed Ontology
摘要
当前,许多企业AI系统都深陷于“数据清洁幻觉”的困境。本文将介绍一种名为3DI(证据驱动本体论)的解决方案。该方法从最原始的源文件入手,通过“源文档重构”、“语义映射”和“事实提取”三大核心技术层,将混乱无序的证据材料转化为可追溯、可验证的结构化真实。这种方法尤其适用于金融、保险、法律等高监管与高风险领域。
正文
一、企业AI的基础困境:“清洁数据”的虚假梦想
主流的企业AI叙事,往往建立在一个看似舒适实则危险的假设之上:你的数据已经是“干净”且“结构化”的,它们正井然有序地躺在数据仓库中,等待被算法调用。在这个“清洁表格”的完美梦想里,信息以整齐的行列形式存在于中心化的云环境中。
但现实远比这复杂和混乱。对于在强监管或对抗性行业——例如抵押贷款、保险、治理合规风险(GRC)——中运营的组织而言,真实信息的源头并非整洁的表格,而是一个由PDF、TIFF、电子邮件附件和扫描笔记构成的混乱“证据平面”。
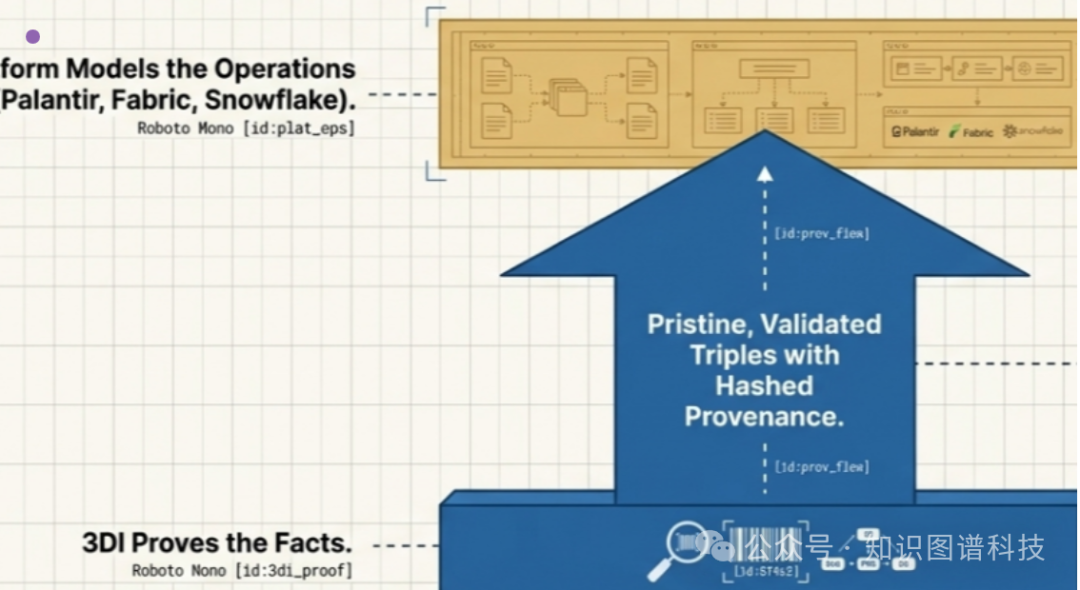
现有的大多数AI架构只专注于“控制平面”——即对已摄入数据进行治理和管理。然而,如果从混乱文档到结构化三元组的初始转换过程本身就存在缺陷,那么整个AI堆栈无异于建立在沙堡之上。解决问题的关键在于转变第一性原理:真实必须被测量,而不仅仅是建模。
问题的根源在于,传统企业AI系统默认数据损耗已经发生。当你把PDF转换成结构化表格,从电子邮件里提取信息,或将扫描的合同进行标准化处理时,每一步都在丢失信息。一旦这种丢失发生,后续所有的分析都将建立在这个不完美的基础上。
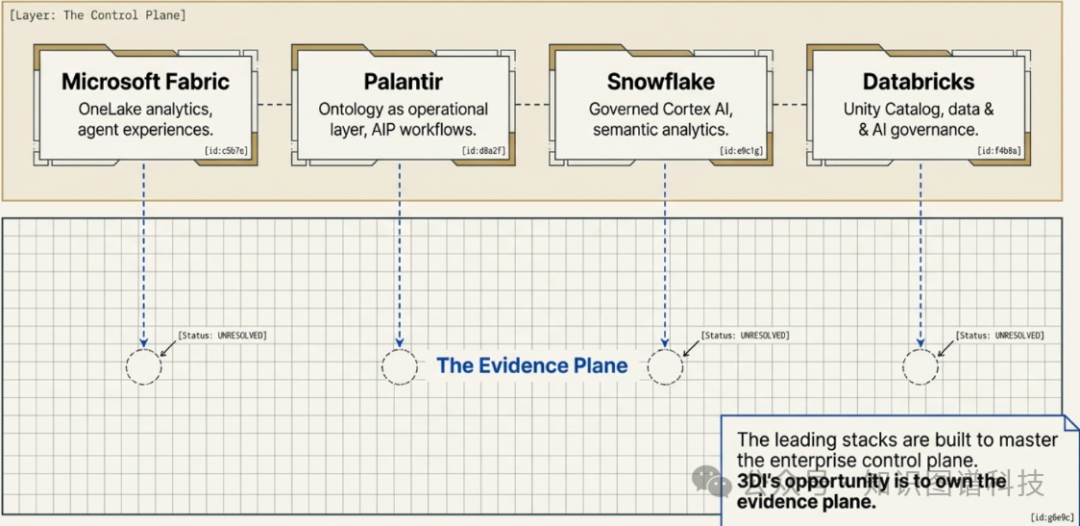
二、掌握“证据平面”而非仅仅“控制平面”
像 Microsoft Fabric 或 Snowflake 这样的主流平台提供了卓越的治理能力,但它们所针对的是一个数据已经“在屋内”的世界。它们是为已经完成清洗和结构化过程的数据而优化的。
3DI代表了一种结构性的转变,因为它从文件级别就开始工作。这是一个根本性的差异。
3DI方法是一种证据驱动的本体论,而非仓库驱动的本体论。当传统技术栈假设“有损转换”已经发生时,3DI通过特定技术层从底层构建真实:
- 源文档重构:将混乱的输入规范化成UTF-8格式的3DI JSON。这不仅是一次文本转换,更保留了原始文档的所有上下文和结构信息。
- 语义映射:对每个文件片段应用规范化的 WHAT(什么)/ WHERE(在哪)/ WHEN(何时)/ WHO(谁)映射。这确保了信息被正确分类和关联。
- 事实提取:为每个被提取和推断出的事实生成语义三元组。这创建了一个可追溯的知识图谱,其中每个事实都附有其源头和支持证据。
通过从原始证据而非预处理过的表格出发,3DI确保了数据提取的“第一公里”与AI推理的“最后一公里”同样严谨。3DI的核心优势不在于它比那些平台更适合企业应用,而在于它从源证据本身开始。这种对源头的精确处理,对于后续在人工智能系统中构建可靠的推理链条至关重要。
三、文档的物理结构本身就是语义信号
传统本体论将文本视为简单的字符串——一个扁平的字符序列,对文档的物理现实基本是“视而不见”的。3DI则基于一个不同的前提运作:版面即数据。
3DI利用位置和排版线索——例如字体大小、粗体、居中对齐和行状态——来提供一层“空间智能”。在这个模型中,字符和单词的位置被视作地理空间坐标。这允许进行“扫雷式聚类”,系统通过分析文本的邻近性和几何特性,来区分文档标题和脚注。
这一几何感知层防止了纯文本模型经常遗漏的关键实体被错误分类,它将文档的物理结构转变为了主要的语义信号。
想象一份抵押贷款合同:标题在页面顶部、居中且字号最大;关键条款可能在主体正文中,常用粗体或缩进表示;利率信息在特定的表格里,带有列标签;警示信息则可能在边栏。传统的OCR和文本提取可能会混淆这些元素,但3DI凭借其几何敏感性能够准确识别每个元素的角色和重要性。
四、面对“真实冲突”的现实世界
标准的语义模型通常是为单一、统一的真相而设计的。但在诉讼和抵押贷款回购风险等高危领域,信息很少如此“配合”。

3DI本质上是为冲突而设计的。考虑一份抵押贷款文件:结算披露可能列出一个利率,票据列出另一个,而贷款估算又列出第三个。传统的仓库或中心系统通常会强制做出选择,用“新”数据覆盖“旧”数据以保持记录清洁。但3DI保留了每一个断言。它对冲突进行建模,应用源头优先级来解决争议,并维护冲突的完整谱系。
这种方法专为相互验证和分歧而构建,使其在对抗性领域中更加诚实和有弹性,因为在那些领域,没有证据支持的主张就意味着法律责任。这不仅仅是选择一个“正确”的利率,而是记录所有三个利率、它们出现的位置、时间以及它们之间的潜在冲突。这种完整的历史记录在高风险场景下至关重要——无论是在审计、诉讼还是风险评估中。
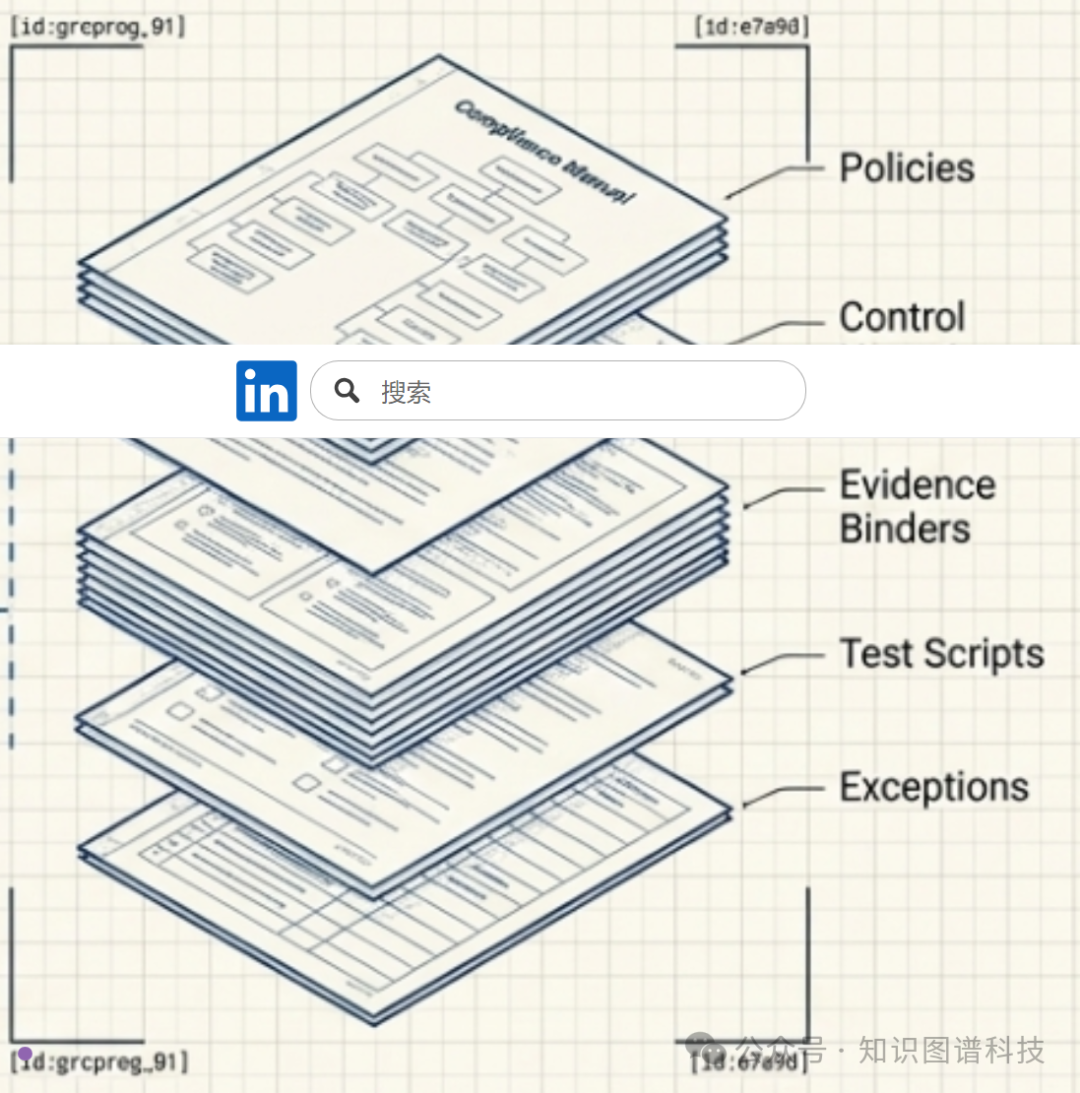
五、将“展示你的工作”作为结构性要求
企业AI中最大的风险之一是“幻觉”——一个与证据现实脱节的逻辑结论。3DI通过将每个声明的出处作为结构性要求来缓解这个问题。
在3DI模型中,每个语义三元组都附带一个全面的证明包:包括文件哈希、页码、具体文本范围和边界上下文。这创建了一条更短、不可中断的、能够追溯到源证据的路径。当AI代理提供一个答案时,它不仅给出一个结论,还提供一个可审计的、“展示你的工作”的支持工件列表。
这种颗粒度对于人工审查至关重要;它确保AI不仅仅是在推理,而且确实扎根于源记录的底层“像素”。在金融合规或法律诉讼中,这种可追溯性不是奢侈品,而是必需品。一个声称“这份贷款的利率是4.5%”的系统,必须能够指向文档中的确切位置、具体的数字以及围绕该陈述的上下文。只有这样,人类审查者才能真正验证结论。这种对证据链的严格管理,是数据治理的最高要求。
六、本体论解释现实;3DI证明现实
自上而下和自下而上的系统之间存在根本区别。传统本体论是自上而下的;它们预先声明了事实和关系。3DI是自下而上的;它从证据中推导和测量事实。
没有3DI作为基础,本体论仅仅是“用干净的逻辑处理脏数据”。3DI提供了传统本体论在规模上真正需要的证据基础。它确保在你对现实进行建模之前,你首先证明了它。
“本体论解释现实。3DI证明现实。”
这种区别在实践中至关重要。假设一家保险公司试图确认客户是否对特定风险进行了充分披露。一个基于传统本体论的系统可能会说:“是的,披露存在。”而一个基于3DI的系统则会说:“是的,披露存在。这里是披露文本,这是它出现的文档,这是日期,这是客户签署的证据。”
七、大型平台的现状与3DI的定位
尽管主要的云提供商正在添加本体论层,但他们的重心仍然在受治理的“平台”上。3DI的重心则是源记录本身。
Microsoft Fabric、Snowflake 和 Databricks 是管理已存在的结构化数据的强大工具。但它们很少关注源头问题——即如何首先从混乱的文档中获取准确的结构化数据。这正是3DI的专业领域所在。
对于大多数受监管的企业而言,他们的真实记录并非漂亮的表格,而是文件、电子邮件、扫描件和PDF的混乱集合。在你能够有效地使用 Snowflake 或 Fabric 之前,你需要一个系统来将这些混乱的记录转化为可信赖的结构化数据。
八、结论:迈向证据优先的未来
3DI并非 Databricks、Snowflake 或 Microsoft Fabric 等平台的替代品。相反,它充当了这些平台所需的必要上游伙伴,尤其适用于那些真相始于文档的企业。它提供了一个高保真的重构层,这是这些平台在受监管、对抗性环境中有效运作所必需的。
随着我们更深入地进入AI时代,组织洞察的价值将由其所依赖的数据基础的质量决定。如果你的本体论与支撑它的证据脱节,那么你的推理最终会失败。
“你的系统是在已证明的事实上进行推理,还是仅仅在建模的假设中导航?”
这个问题对每个部署AI的企业都至关重要。在当前的AI热潮中,我们很容易被复杂的算法和强大的模型所吸引。但如果基础不稳固——如果你的系统无法解释它为何得出某个结论——那么你就是在冒着做出错误甚至危险决策的风险。
对于金融、保险、医疗和法律等行业,其中的错误不仅代价高昂,还可能导致监管处罚或法律诉讼,其数据基础必须是证据驱动的。这正是3DI的用武之地。关于更多技术栈的深度探讨和实践分享,可以关注云栈社区,那里汇聚了众多开发者的实战经验。
 发表于 2026-4-5 05:41:38
|
查看: 175|
回复: 0
发表于 2026-4-5 05:41:38
|
查看: 175|
回复: 0
