这个问题其实很典型,只要你做过搜索、推荐,或者 RAG,一路做到线上,基本都会撞上 rerank 这一关。
前面的召回像撒网,先把可能相关的东西捞上来。到了 rerank 阶段,核心任务就是判断“谁该真的排前面”。问题也刚好出在这儿:这一步最考验模型的判断力,同时也最消耗时间。
我后来越来越觉得,rerank 的难点不在于“怎么让模型推理再快一点”,而在于“有限的几十毫秒预算,到底该花在哪些候选样本上”。因为用户不会因为你把第 87 名和第 96 名区分得更清楚,就愿意多等 200ms。
如果在面试中被追问这个问题,我通常不会一上来就讲技术细节,而是先摆明一个基本判断:别一上来就想着换更轻量的模型。通常,最先调整的应该是候选集规模,其次才是单条打分的成本。随着系统演进,基本都会引入分层 rerank、动态预算分配这些策略。因为这件事的本质,不是在拼命寻找一个“最强的 rerank 模型”,而是在有限的延迟约束下,挑选出更值得消耗计算资源的那批候选。
为什么 Rerank 老是卡在这
很多人第一次审视搜索推荐链路时,会觉得 rerank 不就是中间打个分吗,能有多复杂?真到线上部署才发现,它经常是整条路径里计算成本最高的一段。
一个很直接的原因是,它的成本基本与候选数量成正比。你召回 200 条,不是“做一次更重的判断”,而是把这个打分操作重复执行 200 次。单条推理多花 1ms,看起来不多,但乘上基数后就非常可观了。
另一个麻烦在于,它不像召回阶段那样适合提前离线化处理。召回前面的向量索引、倒排索引都是预先构建好的;可 rerank 往往需要实时考察 query 和 doc 的现场交互信息,比如标题匹配度、字段冲突、query 所在段落的相关性等,这些不等用户请求进来,很多时候无法预先计算。
还有一点经常被忽略:它在链路中通常处于偏后的位置。前面的召回、过滤、权限校验、特征拉取已经吃掉了一截时间预算,留给它的时间天然就紧张。很多时候不是它本身特别慢,而是它几乎没有犯错和缓冲的余地。
所以,我一般不太喜欢把问题简单归结为“模型推理慢”。在真实的线上系统中,更令人头疼的往往是这类组合拳:候选太多、文本太长、特征组装流程里还夹杂着几个远程调用,高峰期 batch 处理再一波动,P99 延迟立刻就难看了。
很多人第一刀就砍错了
不少团队一发现 rerank 慢,第一反应就是换更轻、更快的模型。这个思路不能算错,但通常不是最优解,也不是最应该优先考虑的。
因为 rerank 的总延迟,粗略来看符合这个公式:总耗时 ≈ 候选数/并发线程数 × 单条打分成本 + 固定开销
这里面最容易产出巨大收益的,往往是公式前半部分的“候选数”。
举一个直观的例子:假设当前有 180 个候选进入 rerank,单条打分成本 1.5ms,固定开销 20ms,总体耗时大约是 290ms。如果你先把模型优化 20%,单条成本降到 1.2ms,总耗时仍有 236ms。但如果你先把 rerank 的候选数从 180 砍到 90,哪怕模型一点没变,总耗时也能直接降到 155ms 左右。
因此,在真实的工程实践中,第一刀往往不是去优化模型速度,而是先想办法让“不值得进入精排的候选”别进来。常见的做法包括:对多路召回的结果进行去重,在前面增加一层非常轻量的 pre-rank 进行粗筛过滤,以及为不同召回通道设置配额,防止某一路召回把候选池撑爆。
最后这一点尤为重要。对于“官网登录入口”这类意图明确的 query,你很可能不需要给它 150 个候选慢慢排序。但对于“推荐系统效果不好怎么办”这种发散性问题,候选之间的差异很细微,这时候多分配一点计算预算进行精细排序,通常更值得。
真正拖慢速度的,往往不止模型本身
这件事如果真正在线上实践过,通常会有一种体感:模型推理不一定是最慢的环节,模型外围的那一圈数据处理流程经常更令人烦恼。
比如特征组装。很多人脑海中想象的流程是“把 query 和 doc 扔进模型,直接输出一个分数”。但在真实系统里,在此之前通常还需要完成这些操作:文本清洗、字段拼接、长文本截断、统计特征读取、用户侧实时特征拉取,以及标签、类目和质量分的补全。
这里面只要混入几个慢 IO、远程 RPC 调用或者复杂的序列化操作,你就会发现,即使模型本身只跑 20ms,整个 rerank 阶段的总延迟还是可能被拖到 100ms 以上。
很多时候,最有效的优化不是“压榨模型”,而是先把模型之外的“脏活累活”收拾干净:能离线计算的特征尽量提前算好并缓存;文档侧的静态信息提前展开,避免实时拼接;减少不必要的 RPC 调用以规避尾延迟风险;将几个小 IO 操作合并,避免碎片化请求。
另一个很容易被低估的点是文本长度。对于交互性更强的 rerank 模型(如基于 Transformer 的交叉编码器),输入文本的长度几乎直接决定了计算成本。标题只有几十个字,但正文可能有几千字。如果把整篇正文都喂给模型,效果或许能提升一点点,但系统的吞吐量和延迟很快就会失控。
我更认同的做法是分层保留文本信息:优先保留标题,其次保留摘要,正文只截取前几个信息密度最高的段落;如果能通过召回定位到命中位置,则优先保留 query 附近的文本窗口。
这背后的思路并不复杂:并非所有文本都对排序决策有同等价值。真正在排序中起决定性作用的,很多时候就是最能表达文档主题的那一小段内容。
分层 Rerank 基本是迟早的事
如果系统的流量和复杂度达到一定规模,最终大概率会走向分层 Rerank 的架构。原因也不神秘:单层方案很容易陷入一个尴尬境地——模型太轻,效果不够好;模型太重,延迟又超标。这时最自然的解法,就是让不同层级的候选接受不同成本和精度的判断。
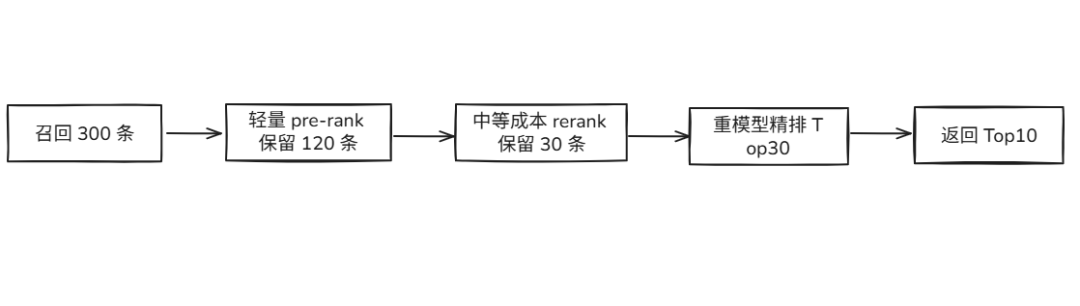
这套思路之所以有效,不是因为它“高级”,而是因为它符合收益递减的规律。排在靠后位置的大量候选,本来进入最终结果列表的概率就很低,对它们全部使用最重的模型,很多算力其实是浪费的。反过来,越接近 TopN 的头部候选,越值得你投入更多计算资源进行精细审阅。
这里面的取舍,到底怎么做
面试中如果被继续追问“那你们具体怎么权衡”,我会把讨论的焦点从平均延迟转移到头部结果质量和尾延迟上。做 rerank 优化最容易犯的一个错误,就是只盯着平均耗时(mean)看。
平均 80ms 看起来没问题,不代表线上体验就稳定。假设 P95 延迟已经到了 180ms,P99 更是超过 300ms,那么用户的感知就不是“整体还行”,而是“怎么偶尔卡得这么厉害”。 因此,我更关注 TopN 的结果有没有因为优化而受损,P95 / P99 这些尾延迟指标有没有变差,以及在高峰期、长 query、长文档等极端场景下系统表现有没有明显退化。
这里面真正困难的地方,不是“要不要牺牲效果”,而是“你打算牺牲哪一部分效果”。如果你通过前置过滤把候选数从 150 降到 100,Top10 的结果基本不变,只是长尾部分的排序有些波动,这种优化通常值得做。因为你砍掉的是对用户直接感知影响不大的边缘候选。
但如果你为了节省时间,直接把一个强交互的复杂模型换成特别轻量的模型,导致前 3 条、前 5 条的结果开始错乱,那这事大概率就不划算了。因为用户真正会查看的,往往就是第一页最前面的那几条。后面的排序再精细,很多人其实根本不会翻到。
所以,真到了必须削减预算的时候,我一般更倾向于在长尾部分做文章,而不太愿意动头部。第 80 名和第 120 名之间谁先谁后,很多时候没人在意;但前 10 名一旦顺序不稳,点击率、用户满意度,甚至下游的生成效果,都会受到影响。在算力紧张时,就应该把重计算尽量留给头部这段关键区域。
线上系统,别硬撑
只要 rerank 是跑在线上实时链路的,就别把它想得太理想化。高峰流量一来,下游特征服务抖动几下,缓存命中率下降一点,或者某个 query 突然特别长,尾延迟马上就会飙升。这个时候,有没有降级和退路,比你平时的平均耗时好不好看更重要。因为真正出问题时,拖垮系统的往往不是平均请求,而是后面那一小撮超慢的请求。
我一般会先给系统补上几样听起来很“土”但非常实用的机制:硬超时控制、失败时回退到更简单的排序规则、高负载时自动减少候选数或截短文本长度,以及对热点 query 的排序结果进行缓存。这些方法听起来不高级,但线上系统很多时候就是靠它们活下来的。
很多优化策略在离线评测集上看起来都很漂亮,可一旦放到线上,首先要问的还是那句老话:它到底稳不稳。一个效果稍弱一点,但能保证按时返回结果的方案,通常比一个更精准但老超时的方案实用得多。
再往深处想,rerank 之所以难做,不是概念有多复杂,而是它刚好踩在一个很别扭的位置上:对最终结果影响巨大,计算成本又高,同时还是实时链路中不可或缺的一环。
如果一定要为这个话题做个总结,我大概会说:rerank 这件事,怕的不是你做减法,怕的是你把预算减错了地方。 优化的艺术,在于精准地识别并保留那些对用户体验影响最大的计算,同时果断舍弃那些边际收益极低的消耗。对于更深入的工程实践与 面试 技巧探讨,欢迎在 云栈社区 交流分享。
 发表于 2026-4-23 02:46:40
|
查看: 146|
回复: 0
发表于 2026-4-23 02:46:40
|
查看: 146|
回复: 0
