面试官问到你用的向量数据库时,一句“我用Chroma,感觉挺快”可应付不过去。这背后考察的是你是否有真实的生产环境经验和性能优化能力。下面,我将以 Milvus 为例,分享在百万级数据量下的实战经验、性能表现以及踩过的坑。
简要回答
我们在生产环境中使用的是 Milvus,数据量级在百万条向量左右。每条向量为1024维,采用 HNSW 索引,单次查询的 P50 延迟可以控制在 20 到 50 毫秒。
选择 Milvus 主要看中其支持分布式部署和读写分离的特性,适合数据量大、并发高的场景。在实际使用中,遇到过两个典型的性能瓶颈:
- 内存压力:百万级的1024维向量原始数据占用内存巨大,后来通过开启标量量化(SQ8),将 float32 压缩为 int8,内存占用直接降为原来的四分之一。
- 写入影响查询:大批量写入会触发后台 Segment 合并,导致查询延迟抖动。我们的解决方案是将批量写入安排到业务低峰期,并改为分批小批量写入。
详细解析
先搞清楚:向量数据库是干什么的?
在深入 Milvus 之前,首先要理解向量数据库解决的核心问题。它和普通数据库(如 MySQL)有本质区别。
普通数据库存储的是结构化数据,查询基于精确匹配,例如 WHERE name = '张三'。然而,在 RAG 这类场景中,我们存储的是文本的“语义向量”,查询方式是基于相似度的搜索,目标是“找到与查询语义最接近的文档”。

这两种模式的底层机制完全不同。语义向量是一个由数百甚至上千个浮点数组成的高维数组。你无法使用 WHERE embedding = xxx 进行查询,只能计算查询向量与库中每个向量之间的距离(如余弦相似度或欧氏距离),然后找出距离最近的 K 个向量。
这就引出一个关键问题:如果向量库中有100万条数据,每次查询都进行100万次距离计算(即暴力搜索),时间复杂度是 O(N),这在生产环境中是无法接受的。向量数据库的核心价值就在于:通过索引(最常用的是 HNSW)技术,将查询时间复杂度降至接近 O(log N),以微小的精度损失换取巨大的速度提升。理解这一点,是分析后续所有性能问题和优化策略的基础。
为什么选 Milvus?
明确了向量数据库的价值,接下来就是技术选型。市面上选择很多,可以根据数据规模和场景来判断:
- Chroma:上手极快,
pip install 即可,数据存于本地文件,非常适合原型验证和 Demo 开发,但缺乏分布式能力,不适用于生产环境。
- Qdrant:使用 Rust 编写,单机性能出色,部署简单(Docker 一条命令),适合中小规模、运维资源有限的团队。
- Weaviate:功能较为全面,支持多种搜索模式,适合需要将向量搜索与结构化查询结合的场景。
- Milvus:是功能最全、扩展性最强的开源选项之一。它支持分布式部署、读写分离、横向扩容,非常适合数据量在百万到十亿级别、并发查询量大的生产场景。
我们选择 Milvus,正是因为数据量增长后单机无法承载,需要分布式能力。同时,知识库需要每日增量更新,读写分离的架构能确保写入操作不影响线上查询服务的稳定性。
Milvus 的核心概念
选定 Milvus 后,在讨论具体性能数据前,必须理解它的几个核心概念。这些概念直接关系到对性能瓶颈的分析。
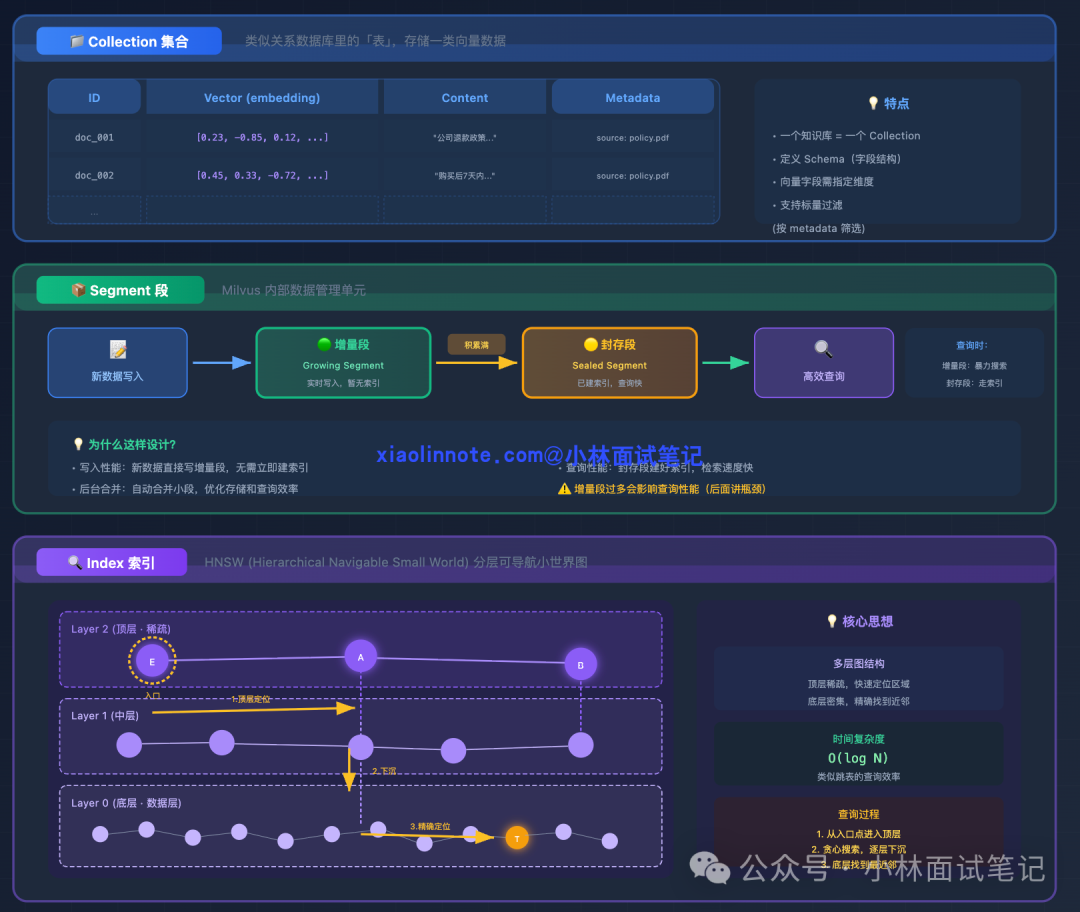
- Collection(集合):类似于关系型数据库中的“表”,用于存储一类向量数据。我们的整个知识库就是一个 Collection,每条记录包含:文本块的 ID、向量(embedding)、原文内容、来源文档等元数据(metadata)。
- Segment(段):这是 Milvus 内部进行数据管理的基本单元,理解它对分析性能瓶颈至关重要。新写入的数据会先进入“增量段”,这类似于一个临时缓冲区。当数据积累到一定规模后,系统会触发合并操作,将其转化为“封存段”。封存段会构建好索引,查询时通过索引检索,速度很快。但是,这个合并过程本身会消耗大量 CPU 和磁盘 I/O 资源。记住这个机制,我们后面会详细讨论它带来的影响。
-
Index(索引):这是加速向量检索的关键结构。最常用的是 HNSW(分层可导航小世界图)。它的核心思想是将向量组织成一个多层图结构:查询时从稀疏的顶层开始,快速定位到目标大致区域,然后逐层向下精确搜索,最终在底层找到最近邻,整体时间复杂度接近 O(log N)。
HNSW 有几个关键参数:
M:控制图中每个节点的最大连接数(可以理解为“每个人最多认识几个朋友”)。M 越大,图越稠密,搜索精度越高,但构建索引所需的内存和时间也越多。通常设置为 16 到 32 之间。ef_construction:控制建图时每个节点考察的候选邻居数量。值越大,构建的索引质量越高,但构建速度越慢。通常设置为 100 到 200。ef(或 search_ef):控制查询时搜索的候选集大小。值越大,召回结果越准确,但查询延迟也越高。需要根据业务对精度和延迟的要求进行权衡,通常在 50 到 200 之间调整。
数据规模和实测性能
了解了基本概念,现在来看实际数据。我们的知识库大约有 150 万条文本片段,每条使用 BGE-large-zh 模型生成 1024 维的向量。索引采用 HNSW(M=16,ef_construction=128)。
首先计算一下原始数据的内存占用:150 万 × 1024 维 × 4 字节(float32)≈ 6 GB。这还仅仅是原始向量数据,加上 HNSW 索引结构本身的开销,Milvus 进程实际运行所需内存大约在 10~12 GB。你可能会觉得现在服务器内存都很大,但这只是向量数据库的消耗,同一台机器上通常还运行着应用服务、缓存、日志收集等其他组件,内存资源是竞争关系。
开启 标量量化(SQ8) 后,我们将每个 float32 数值压缩为 int8(用 1 字节存储代替 4 字节)。可以将其理解为保留数字的主要部分而舍弃一些低位精度,对于高维向量表示的语义信息来说,这种精度损失通常极小(小于1%),但带来的收益是内存占用直接降至原来的约 四分之一。这是性价比极高的优化手段。
实测的查询性能如下:单次 top-5 查询,P50 延迟约为 20ms,P99 延迟约为 60ms。在 100 QPS 的并发压力下,延迟保持基本稳定。这些具体的、可量化的指标,才是面试官希望听到的答案,而非模糊的“感觉挺快”。
遇到的性能瓶颈
从上面的内存计算就能预见到,百万级高维向量数据在生产中必然会带来挑战。我们确实遇到了两个典型瓶颈。
瓶颈一:内存不足导致查询延迟飙升
初期未开启量化,且服务器内存仅有 8GB。当 Milvus 将向量索引加载到内存后,操作系统剩余内存空间所剩无几。一旦系统稍有内存压力,就会开始频繁地进行 Swap(将内存数据交换到磁盘)。这直接导致查询延迟从正常的 20ms 飙升到 2 秒以上。
很多人在遇到查询变慢时,首先会怀疑索引算法,但根源往往是内存不足。这就如同在内存不足的电脑上打开一个巨大的Excel文件,系统会疯狂读写硬盘,导致界面卡顿。
解决方案:首要措施就是上文提到的启用 SQ8 量化,将内存占用从 10GB 降至约 3GB,从根本上消除了 Swap 的可能性。辅助方案是利用 Milvus 的 mmap 功能,将原始向量数据存储在磁盘上,仅将索引加载到内存中,进一步节省内存。原始向量仅在需要进行精确距离计算(精排)时才被读取,对整体查询延迟影响不大。
瓶颈二:批量写入触发 Segment 合并,引起查询抖动
解决了内存问题后,新的挑战随之而来。我们的知识库每天有增量更新,当一次性写入数十万条新数据时,会触发 Milvus 后台的 Segment 合并操作。这个过程(将多个小增量段合并为大的封存段并构建索引)会消耗大量的 CPU 和磁盘 I/O 资源。
在此期间,查询的 P99 延迟会出现明显抖动,从正常的 60ms 上涨到 300ms 以上,影响服务稳定性。
解决方案:我们采用了两种思路:
- 时间错峰:将大规模的批量写入任务调度到业务低峰期(例如凌晨)执行,避开查询高峰,让 Segment 合并在无干扰的情况下安静完成。
- 化整为零:控制单次写入批次的数据量,将其限制在 500~1000 条以内,并以小间隔分批写入。这样,一次大的合并冲击被拆解为多次小的、快速的合并操作,每次对查询服务的影响微乎其微,基本避免了可感知的延迟抖动。
面试总结
回顾文章开头的面试场景,当被问及向量数据库的使用经验时,一个合格的回答应当包含以下几个层次:
- 清晰的技术选型与理由:说明为什么选择 Milvus(或其他数据库),重点阐述其如何匹配你的数据规模(百万级)和业务场景(高并发、需读写分离)。
- 具体的量化指标:给出准确的数据量级(如150万条1024维向量)、所使用的索引(HNSW)以及核心性能指标(P50/P99延迟、支持的最大QPS)。切忌使用“感觉挺快”这样的模糊表述。
- 真实的踩坑与优化经验:分享一个或两个你在生产环境中实际遇到过的性能瓶颈,并详细说明你的分析思路和解决方案(例如,通过SQ8量化解决内存瓶颈,或通过错峰写入缓解合并抖动)。
这样的回答不仅能证明你“用过”,更能体现你“深入思考过”和“解决过实际问题”,而这正是高级工程师与初级工程师的关键区别所在。希望这篇来自云栈社区的实战分享,能为你未来的技术面试或项目实践提供有价值的参考。
 发表于 2026-4-18 02:38:53
|
查看: 213|
回复: 0
发表于 2026-4-18 02:38:53
|
查看: 213|
回复: 0
