👔面试官:来说说什么是向量数据库?你有没有做过向量数据库的对比选型?
🙋♂️我:向量数据库我知道,就是在 MySQL 里加个向量字段,然后用 LIKE 语句做模糊匹配检索,差不多就是存向量的数据库吧。
👔面试官:MySQL 加个向量字段?那是存向量,不是向量数据库。你用 LIKE 做语义检索?LIKE 是字符串模糊匹配,跟向量相似度搜索完全是两码事。你对向量数据库的理解就停留在「存了个向量字段」?
🙋♂️我:那应该是用 Elasticsearch 吧?ES 不是也能做向量检索吗,加个 dense_vector 字段类型就行了,没必要专门引入一个新的数据库吧。
👔面试官:ES 的向量检索能力是后来加的补丁,不是原生设计,数据量一大性能根本扛不住。而且你连专门的向量数据库和传统数据库的本质区别都说不清楚,还怎么做选型?选型的时候你考虑哪些因素?索引算法了解吗?HNSW 和 IVF 听说过吗?
🙋♂️我:选型嘛,就看哪个 Star 多用哪个呗,Chroma Star 挺多的,生产环境直接上 Chroma 就行了吧?
👔面试官:Chroma 是本地嵌入式数据库,连分布式都不支持,你拿它上生产?百万级数据你怎么扛?面试前连基本的选型标准都没搞清楚,Star 数量能当技术选型依据?回去好好了解一下各家的适用场景再来吧。
好吧,这段面试对话几乎踩遍了向量数据库理解上的所有坑。为了方便大家在未来的面试或技术选型中避雷,本文将从一个更全面的视角,为你从头梳理清楚:向量数据库究竟是什么、为什么我们一定需要它、以及到底该如何做选型。
引言
如果你是正关注着 AI 应用开发,特别是 RAG (Retrieval-Augmented Generation) 技术的开发者,那么“向量数据库”这个词对你来说一定不陌生。它在将非结构化数据与大模型连接起来的过程中,扮演着至关重要的“记忆中枢”角色。今天,我们就来深入探讨这个热门技术,确保你不仅知其然,更能知其所以然。本文源于笔者在 云栈社区 与同行交流后的一次系统梳理,希望能带来清晰的认知。
💡 一句话说清本质
向量数据库是专门设计用于存储和高效检索高维向量的数据库。其最核心的能力是近似最近邻搜索,能够在百万甚至亿级别的向量集合中,快速找出与查询向量语义上最相似的若干个结果。
这和我们熟悉的 MySQL、PostgreSQL 等关系型数据库截然不同。关系型数据库的索引结构(如 B-tree)擅长精确匹配查询,但对于高维向量的“相似度”搜索基本无效,所以才催生了专门的向量数据库来处理这个场景。
📝 详细解析:从概念到选型
什么是向量数据库?(不只是“存向量”)
首先,我们必须明确什么是“向量”。在 AI 语境下,向量通常指的是通过嵌入模型将文本、图片、音频等非结构化数据转换成的、一串代表其语义的浮点数数组,例如 [0.12, -0.87, 0.34, ... ]。语义越相近的内容,其向量在高维空间中的距离(如余弦距离)就越近。
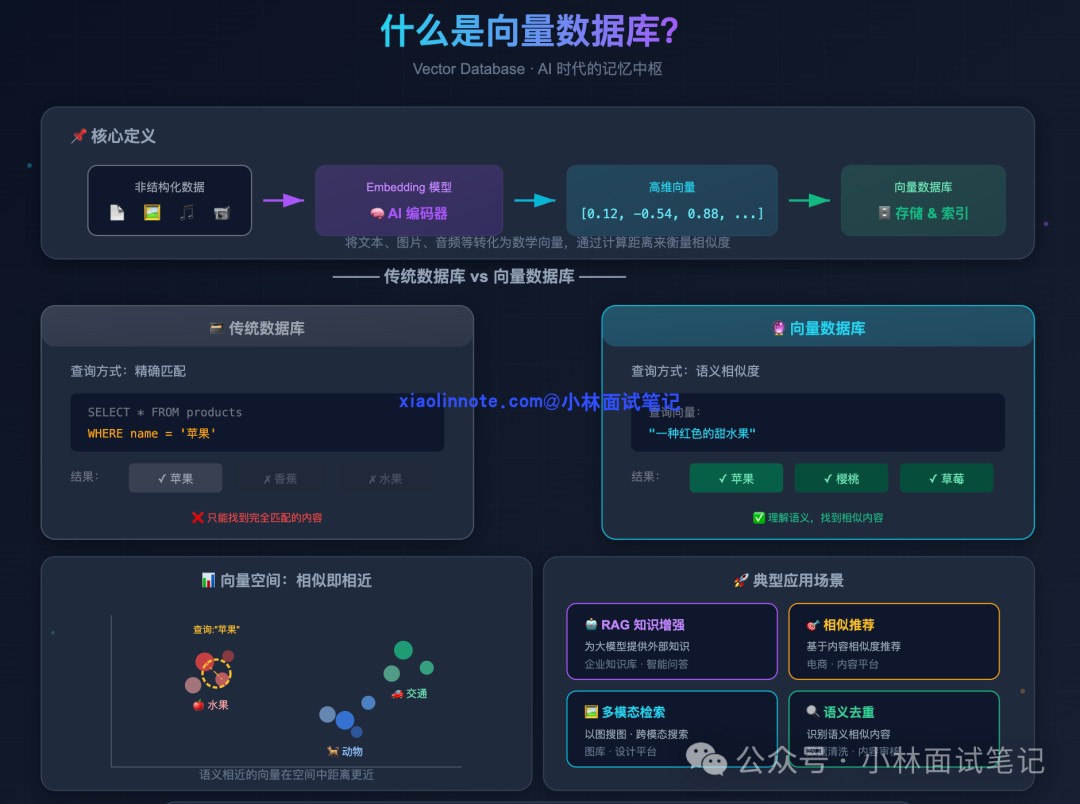
向量数据库的核心任务,就是支持一种叫做 近似最近邻搜索 的操作:给定一个查询向量,在库中快速找出和它最相似的 K 个向量,并返回对应的原始数据。这正是 RAG 流程中“检索”环节的基石:将用户问题转换为向量,再从向量数据库中召回最相关的文档片段,最后交给大模型生成答案。
关键区别:很多人容易混淆“在 MySQL 里加个向量字段”和“使用向量数据库”。本质上,MySQL 等擅长的是精确匹配,而向量数据库擅长的是语义相似检索。二者解决的是不同维度的问题,不存在互相替代的关系。
为什么不能直接用 MySQL/ES? (索引结构的根本差异)
理解了向量数据库做什么,自然会产生疑问:为什么不直接在现有的 MySQL 或 Elasticsearch 中存储向量,非要引入一个新组件?
原因在于“搜索模式”和“索引效率”的鸿沟:
- 传统数据库(MySQL/PostgreSQL):依赖 B-tree 等索引处理精确匹配查询,如
WHERE id = 123,效率极高。但 B-tree 是一维有序索引,对于需要综合衡量 1024 维向量各维度距离的“相似度搜索”无能为力。
- 暴力搜索不可行:如果对百万级数据做遍历计算(计算查询向量与库中每个向量的距离),延迟无法接受。
- ES 的局限性:Elasticsearch 的向量检索功能是后期扩展,并非原生架构,在处理海量向量数据时,性能和效率往往不如专门的向量数据库。
因此,向量数据库的价值就在于,它采用了专门为高维向量相似性搜索设计的索引算法,在可接受的精度损失内,将检索延迟从不可接受降至毫秒级。
核心是如何做到的?——索引算法:HNSW vs IVF
向量数据库实现毫秒级检索的秘密,全在于其底层索引算法。目前主流的有两大阵营。
-
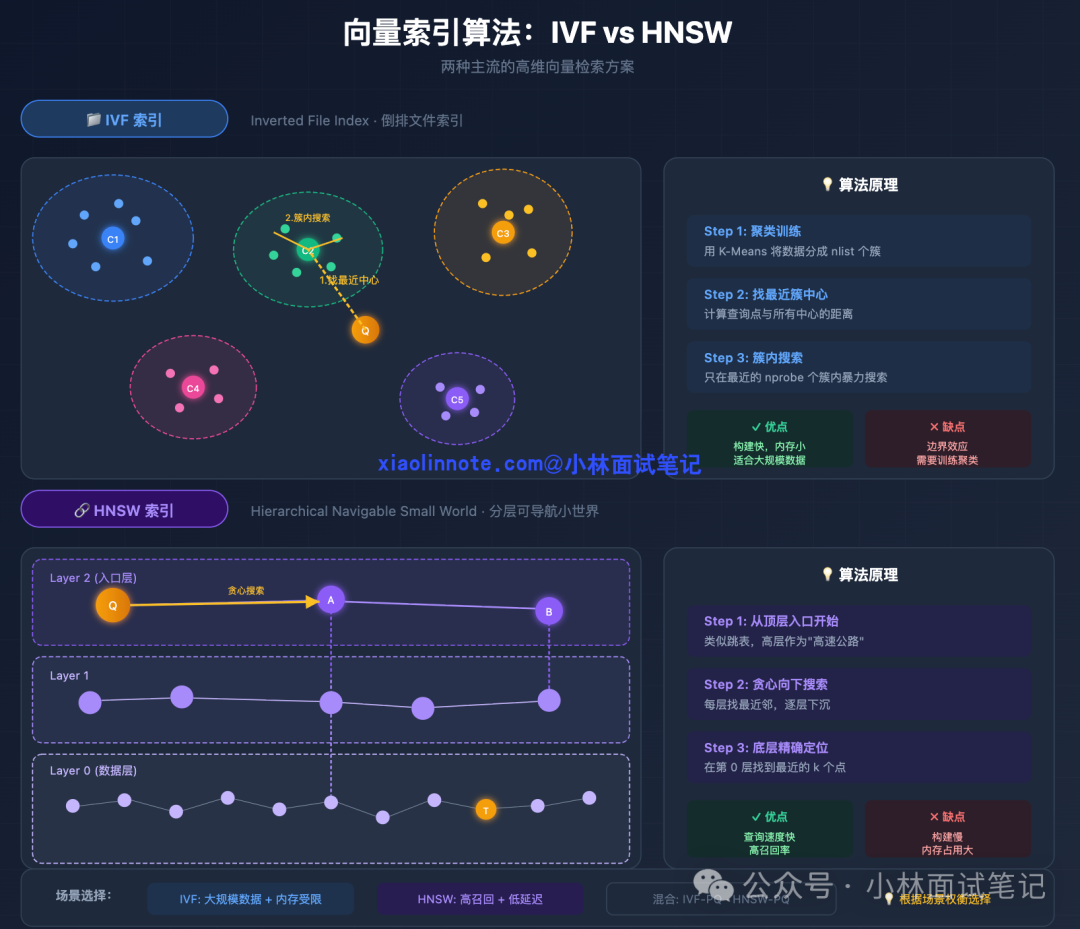
HNSW(分层可导航小世界图)
- 原理:构建一个类似“多层跳表”的图结构。查询时从最稀疏的顶层开始“导航”,像查地图一样,先锁定大区域,再逐层向下,在更密集的底层精确定位目标点。
- 特点:查询速度极快,召回率(精度)通常很高(95%以上),是目前许多向量数据库(如 Qdrant, Milvus)的默认选择。缺点是构建索引时内存消耗较大。
-
IVF(倒排文件索引)
- 原理:先对全部向量进行聚类(比如用 K-Means),将相似的向量归入同一个“簇”。查询时,先找到距离最近的几个簇中心,然后只在这些簇内部进行精细搜索。
- 特点:通过牺牲少量精度,大幅减少了需要搜索的数据量,内存占用相对较小,非常适合处理超大规模(亿级)数据集。Milvus 在大规模场景下常采用此类索引。
为什么需要两种? HNSW 虽好,但其内存消耗与数据量成正比。当数据规模达到亿级时,IVF 这种“以精度换内存和规模”的方案就成为更务实的选择。
生产级向量数据库必备的核心能力
除了底层的 ANN 搜索,一个成熟的、可用于生产环境的向量数据库,通常还需要具备以下几项关键工程能力:

-
Metadata 过滤(混合检索)
实际业务中,数据往往带有各种属性标签。例如,在企业知识库中,文档可能属于不同部门、不同年份。向量数据库需要支持在检索时附加元数据过滤条件,仅在符合条件的子集中进行相似度搜索,确保返回的结果既相关又符合业务约束。
-
实时/增量更新
RAG 知识库需要频繁增删改文档。向量数据库必须支持数据的在线写入和索引的增量构建,而不是每次更新都需要重建整个索引,这对于保证服务的可用性至关重要。
-
与关键词检索融合
纯向量检索有时对精确词(如产品型号“GPT-4o”)效果不佳。因此,许多向量数据库支持将向量相似度检索与传统的关键词检索(如 BM25)相结合,进行混合召回,综合两者的优势提升效果。
实战选型指南:我该用哪个?
了解了原理和能力,我们来解决最实际的问题:面对众多选择,我该如何决策?主要从三个维度考量:数据规模、部署方式和功能需求(如混合检索)。
以下是一个清晰的选型路径和对比:
| 数据库 |
部署方式 |
适合规模 |
混合检索 |
主要优势 |
主要劣势 |
| Chroma |
本地/嵌入式 |
小规模(开发测试) |
否 |
零配置,上手极快 |
不适合生产,无分布式支持 |
| Qdrant |
自托管/云 |
中小规模(百万级) |
是 |
性能好,API简洁,文档完善 |
超大规模需针对性调优 |
| Milvus |
自托管(分布式) |
大规模(亿级) |
是 |
可水平扩展,功能丰富 |
部署和运维复杂度高 |
| Pinecone |
全托管云服务 |
中大规模 |
是 |
无需运维,开箱即用 |
费用较高,需考虑数据合规与出境问题 |
| pgvector |
PostgreSQL 插件 |
中小规模 |
是(配合全文检) |
无新增组件,可与业务数据SQL JOIN |
性能通常弱于专用向量库 |
选型建议:
- 快速原型/本地开发:无脑选 Chroma。
pip install chromadb 即可开始,与 LangChain 等框架集成无缝。但请务必记住,它的定位是开发测试工具。
- 中小规模生产应用(百万级向量):推荐 Qdrant。用 Rust 编写,性能有保障,Docker 部署简单,API 设计友好,是很多团队从 Chroma 过渡到生产环境的首选。
- 超大规模、需要分布式:选择 Milvus。这是国内大厂采用较多的方案,社区活跃,支持多种索引和完整的集群方案,但需要相应的运维能力。
- 不想操心运维、快速验证业务:可以考虑 Pinecone 这类全托管云服务。按需付费,但需评估数据安全和合规要求。
- 已深度使用 PostgreSQL,数据量不大:直接用 pgvector 插件。无需引入新的基础设施,学习成本最低,还能方便地与现有业务数据关联查询。
🎯 面试要点总结
让我们回到开头的面试场景。如果被问到“什么是向量数据库”,一个合格的回答应该清晰区分它与传统数据库的本质不同,并准确指出其核心能力是 高维向量的近似最近邻搜索。
当面试官追问选型时,切忌用“Star 多”作为理由。你应该从 数据规模、部署方式和功能需求 三个维度展开,结合具体场景(如开发测试、中小生产、超大规模)给出像 Chroma -> Qdrant -> Milvus 这样清晰的演进路径,并能够阐述 HNSW 和 IVF 等核心索引算法的区别与适用场景。
对于希望在 AI 应用开发,特别是 RAG 领域深耕的开发者而言,深刻理解向量数据库是构建可靠、高效 AI 系统的基础。希望本文能帮助你构建起清晰的知识框架,在未来的 技术面试 或项目实践中更加从容。
 发表于 2026-4-18 02:41:33
|
查看: 152|
回复: 0
发表于 2026-4-18 02:41:33
|
查看: 152|
回复: 0
