在汽车产业加速数字化转型的浪潮中,车联网数据平台正经历着一场深刻的架构变革。面对海量并发、极致时效与成本控制的多重挑战,传统多组件堆砌的架构已显疲态。本文基于多个头部车企的实战经验,深入剖析车联网数据平台面临的典型困境,并详细解读向“Single Engine, One SQL”湖仓一体架构演进的路径与成效,为同行提供可借鉴的优化思路。

很多人提到车联网数据,第一反应是“数据量大”。一辆智能网联汽车每日可产生1-2TB数据,头部车企数百万的车辆保有量,轻松带来日增数十TB乃至EB级的数据压力。然而,数据量大仅是表象,其背后隐藏着四个更为本质的技术特性,共同构成了独特的挑战。
首先是高并发的写入压力。数百万车辆实时在线,秒级甚至百毫秒级的采集频率,使得平台入口的TPS(每秒事务处理量)动辄达到千万级,对数据实时入湖能力提出了极限要求。
其次是极低的数据价值密度。车辆正常运行产生的数据占99%以上,真正有价值的异常数据(如电池突温、驾驶行为突变)占比可能不足万分之一。但为了分析异常,又必须存储完整的上下文数据,这导致了高昂的存储成本。
第三是极致的时效要求。远程诊断、预警推送、智能驾驶决策等场景依赖分钟级甚至秒级的数据响应能力,传统的“T+1”(今日数据明日可见)离线模式完全无法满足业务需求。
第四是巨大的流量波动。早晚高峰、节假日出行带来的数据流量波动可达5-10倍。按峰值配置资源会造成巨大浪费,按平均值配置则会在高峰时段引发系统崩溃。
三大典型问题:从理性选型到复杂度爆炸
在服务多家头部车企的实践中,我们反复观察到三个共性问题,它们并非个案,而是行业通病。
1. 组件全家桶带来的运维黑洞
典型的车联网数据平台架构图往往布满了各类组件:Kafka 作消息队列,Flink 做流式处理,数据存储在 HDFS 或对象存储,Spark 负责离线计算,ClickHouse 或 Presto 用于即席查询,再加上元数据管理、任务调度等系统。
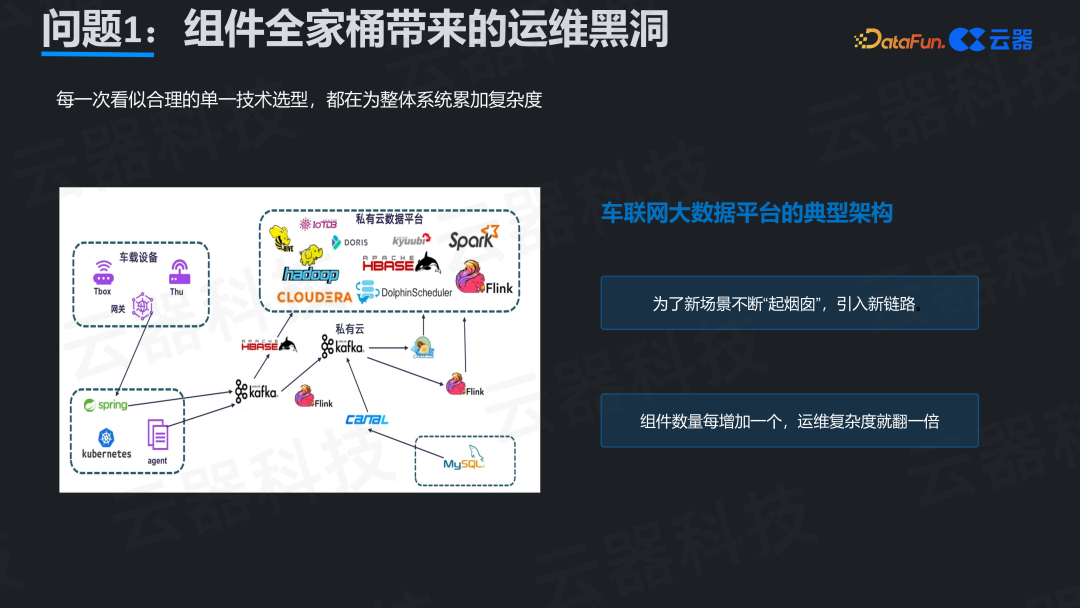
单独看,每个组件选型都合理。但组合在一起,六七个甚至更多组件的运维复杂度呈指数级上升。版本兼容、组件通信、故障排查、性能调优,每一项都是巨大的负担。团队需要掌握多种技术栈,往往从一个架构师变成了四处救火的消防员。
2. 存算一体架构的“捆绑消费”
早期许多企业选择存算一体架构(如HBase、InfluxDB),其优势是数据本地性好、延迟低。但在车联网场景下,其致命缺陷暴露无遗:存储与计算必须同步扩容,无法独立伸缩。

以典型的“单车明细查询”场景为例,业务要求输入车架号,秒级返回该车历史数据。随着车辆增多,存储需求持续增长,但查询的QPS(每秒查询量)并未同比增加。在存算一体架构下,为扩容存储就不得不购买用不完的CPU,导致资源利用率长期低下(可能仅30%),造成严重浪费。
3. 实时与离线的两条冗余链路
经典的Lambda架构用离线链路保证数据一致性,用实时链路满足低延迟需求。但在实践中,这种“双链路”设计带来了巨大负担。
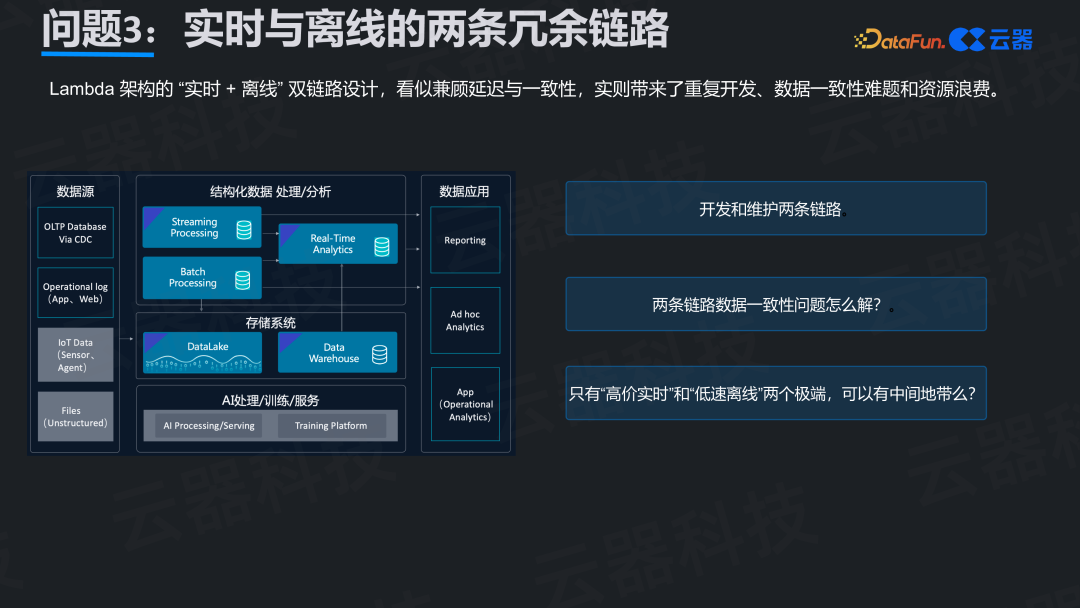
- 开发成本翻倍:同一业务逻辑需用Spark写批处理代码,再用Flink写流处理代码,双倍开发、测试和维护工作量。
- 数据一致性难题:两条链路计算结果一旦出现差异,排查工作如同大海捞针。
- 成本压力:实时链路需24小时运行,对于不需要极低延迟的场景,高昂成本实属浪费。系统被迫在“高代价实时”和“低速离线”间二选一,缺乏中间选项。
四个迭代方向:从复杂到简洁的演进路径
面对上述困境,架构演进需回归第一性原理:“如无必要,勿增实体”。我们总结出四个关键的迭代方向。
方向一:Single Engine, One SQL
核心思想是:能用一个引擎解决的问题,就不要用两个;能用SQL表达的,就不写代码。这依赖于湖仓一体架构与增量计算技术的成熟。

传统离线计算是全量模式,数据量达EB级时根本无法运行。增量计算只处理新增或变化的数据,合并更新结果,能以接近离线的成本实现近实时的时效性。例如,计算过去七天车辆平均能耗,增量计算只需处理今日新增数据并与历史结果合并,计算量骤减,并可实现分钟级的调度频率。
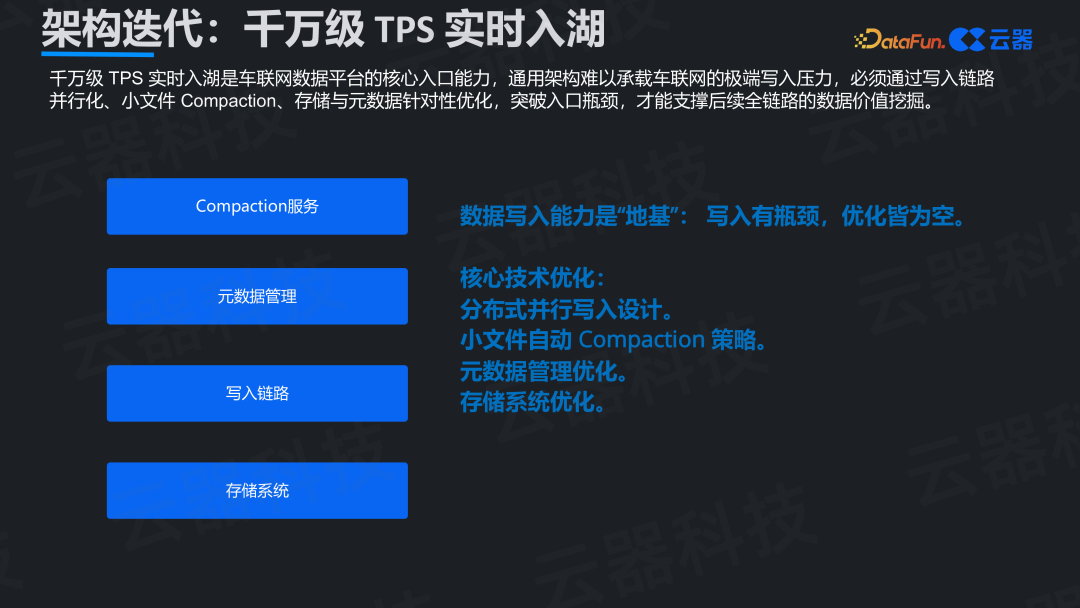
方向二:千万级TPS实时入湖能力
车联网千万级TPS的写入压力是通用架构难以承受的,必须进行专项优化。这包括写入链路的分布式并行化设计、小文件自动Compaction策略、元数据管理优化以及存储系统的针对性调优。写入能力是数据平台的“地基”,此处的瓶颈会制约后续所有数据价值的挖掘。
方向三:云原生存算分离与弹性扩缩容
存算分离并非新概念,但直到云原生技术成熟才真正好用。它对车联网的潮汐式流量意义重大。
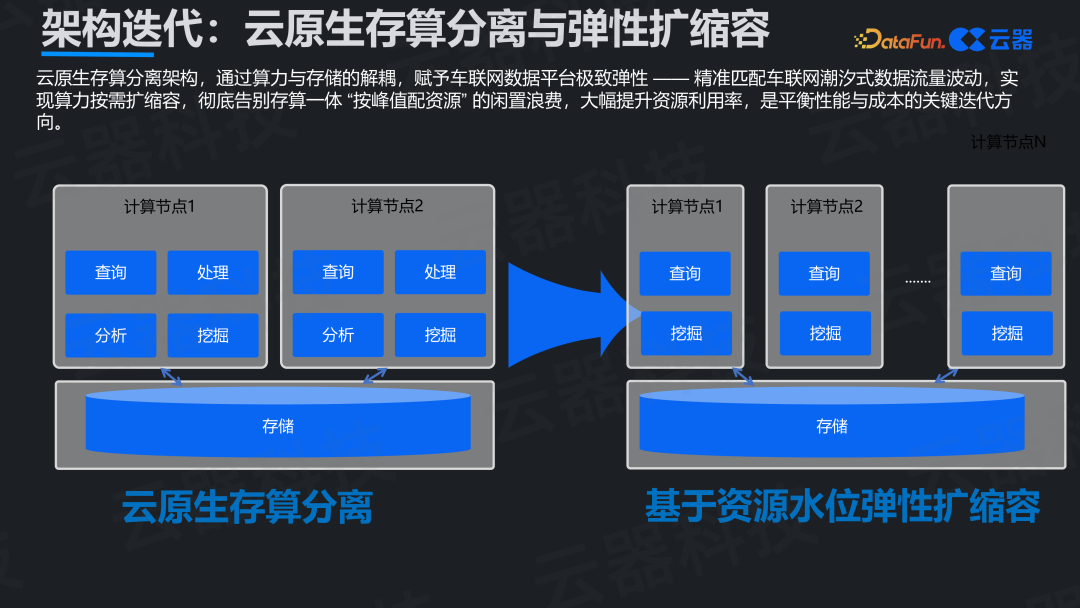
在存算分离架构下,计算资源可以根据实时负载动态伸缩:高峰期自动扩容,低峰期自动缩容。这可以将资源利用率从传统架构的30%左右提升至90%以上,成本控制效果立竿见影。
方向四:极致压缩与冷热分层
面对日增数十TB的存储成本压力,组合优化策略效果显著。车联网数据具有模式重复的特点,采用专用压缩算法配合数据排布优化,压缩比可达1:15甚至更高。同时,根据数据访问频次(近期为热数据,历史为冷数据)进行自动化冷热分层,将热数据放在高性能存储,冷数据迁移至低成本对象存储,可降低存储成本50%以上。

实战案例:头部车企的架构演进之路
案例一:长安汽车——从Lambda到湖仓的架构收敛
长安汽车原有Lambda架构面临组件多、运维复杂、数据时效T+1等痛点。重构核心是“精简”,将多组件架构收敛至一体化湖仓平台。
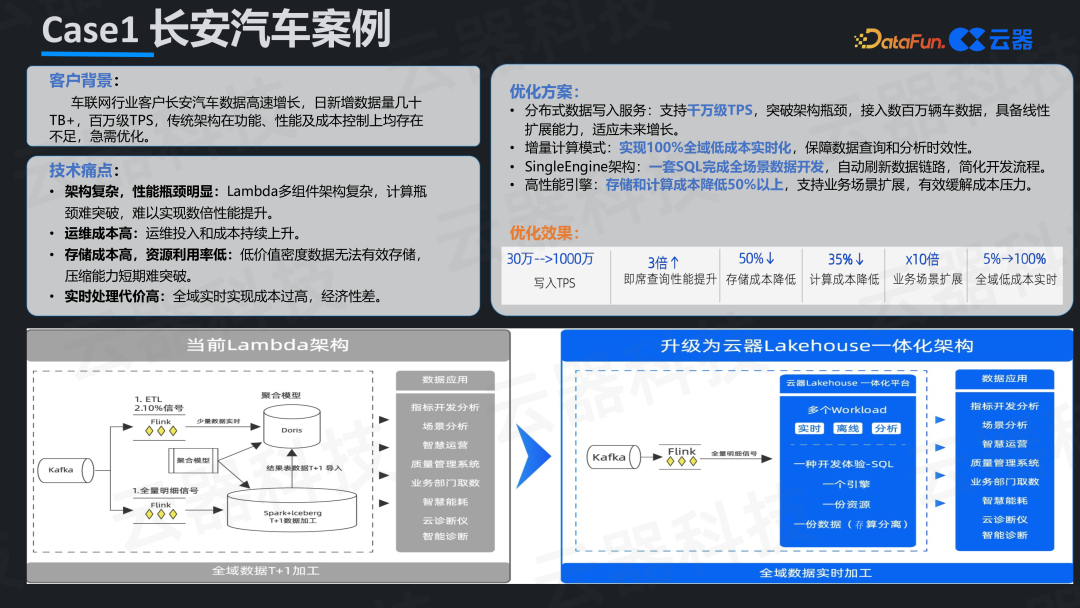
通过写入链路专项优化,入湖TPS从30万提升至1000万。全面采用增量计算模式后,数据可见性从T+1提升至分钟级。例如车辆故障预警,可及时发现前兆并推送,大幅提升安全性。架构统一后,即席查询性能提升3倍,存储与计算成本降低50%,团队得以从繁重运维中解脱,聚焦业务创新。
案例二:长城汽车——单车明细查询的极致优化
长城汽车聚焦“单车明细查询”场景,需在万亿级数据量上实现百毫秒级响应。原架构采用HBase和InfluxDB等存算一体数据库,存储增长被迫连带扩容计算资源,浪费严重。
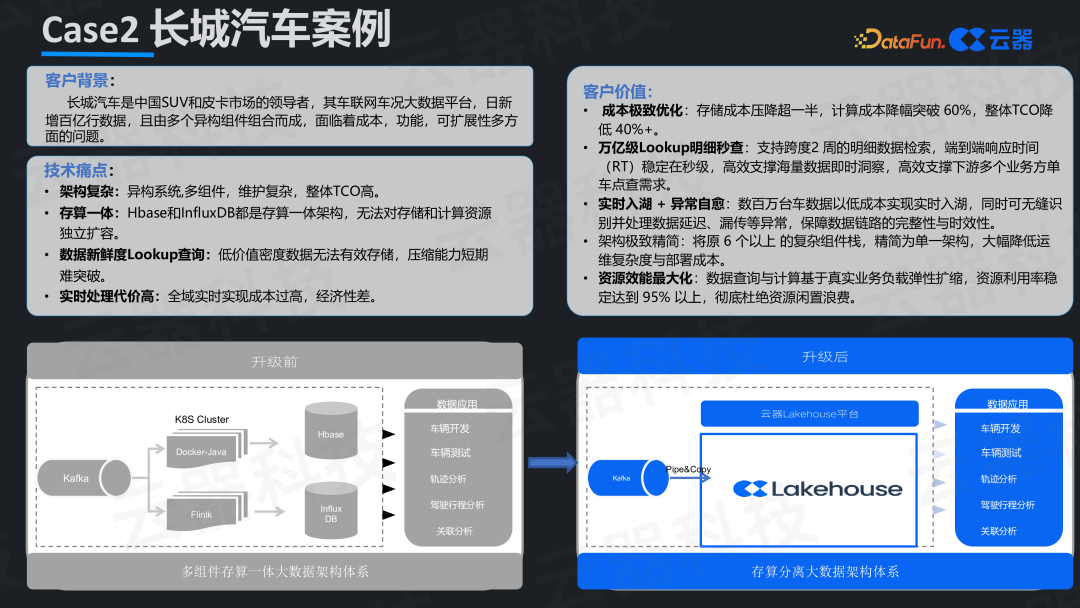
新架构通过数据分桶分区、多层缓存体系(热数据内存、温数据SSD、冷数据对象存储)及专用查询优化器,在实现百毫秒级查询响应的同时,存储成本降低超50%,计算成本下降超60%,证明了性能与成本可兼得。
案例三:安凯汽车——商用车场景的SaaS化路径
安凯汽车作为商用车企,数据量相对较小,但需完整的大数据能力,且面临专业人力不足、安全合规要求高的挑战。自建复杂平台不现实。
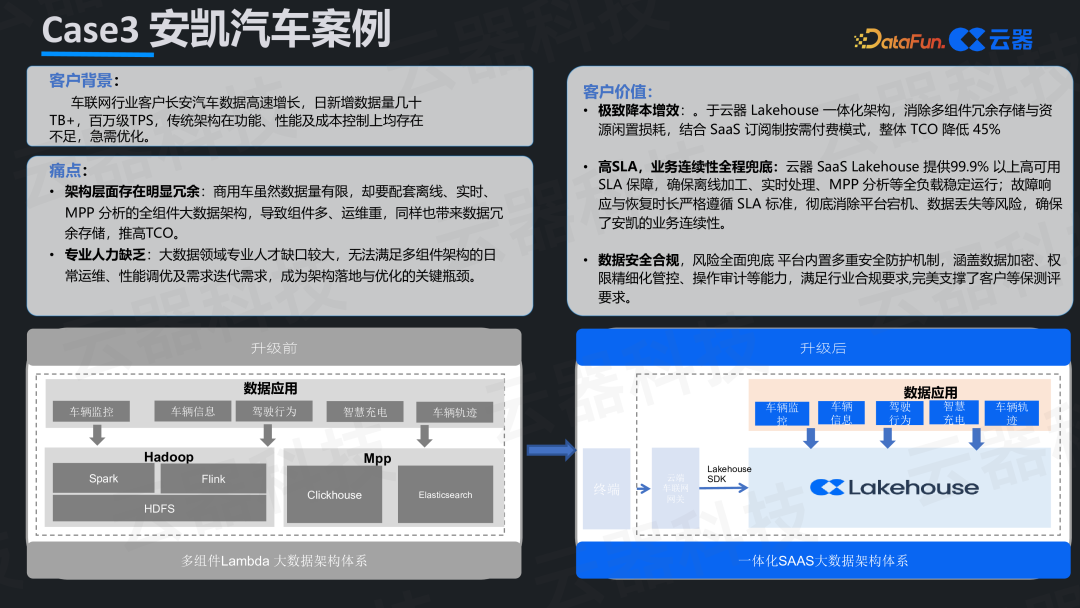
采用SaaS化湖仓平台成为最优解。一体化架构消除了冗余,订阅制按需付费使整体TCO降低45%。平台提供99.9%以上的高可用SLA保障,并内置数据加密、细粒度权限管控、操作审计等安全能力,完美支撑了等保测评要求,为中小规模车企提供了高性价比的现代化数据能力获取路径。
未来趋势与结语
随着AI大模型与智能驾驶的演进,数据平台将迎来新挑战。大模型需要高质量、可快速访问的数据底座;智能驾驶带来的点云、图像等非结构化数据将使规模进入EB时代,对存储与算力管理提出更高要求。

无论技术如何发展,架构设计的黄金法则不变:追求极简与高效。真正的效能提升,源于用最精简的架构支撑最快速的业务增长,让技术团队从“救火队员”回归“价值创造者”的本位。这场从复杂到简洁的架构演进,不仅是技术的优化,更是思维模式的升级。欢迎在云栈社区与我们继续探讨大数据与云原生技术的更多实践。
 发表于 2026-2-26 02:47:40
|
查看: 161|
回复: 0
发表于 2026-2-26 02:47:40
|
查看: 161|
回复: 0
