在移动互联网竞争日益激烈的今天,用户对“实时”的要求已从“秒级响应”升级为“毫秒级决策”。对于像 vivo 这样拥有数亿用户的科技公司而言,传统的 T+1 Hive 数仓架构面临着严峻挑战:营销活动效果无法实时追踪、用户行为分析严重滞后、BI报表失去决策价值。正如其技术团队所言:“即席分析、敏捷 BI、研效工具平台等业务场景对数据时效性提出了更高要求”。
本文将深入剖析 vivo 大数据团队如何通过湖仓一体架构升级,实现 “分钟级数据可见、秒级查询响应” 的性能飞跃,并为同行提供一份可落地的实战指南。
一、 痛点诊断:为何传统架构走到了尽头?
vivo 原有的架构是典型的 Lambda 架构变种:
- 离线层:
Hive + Spark,进行 T+1 批处理。
- 实时层:
Kafka + Flink + HBase/Druid,处理实时流。
但这种架构带来了三大致命问题:
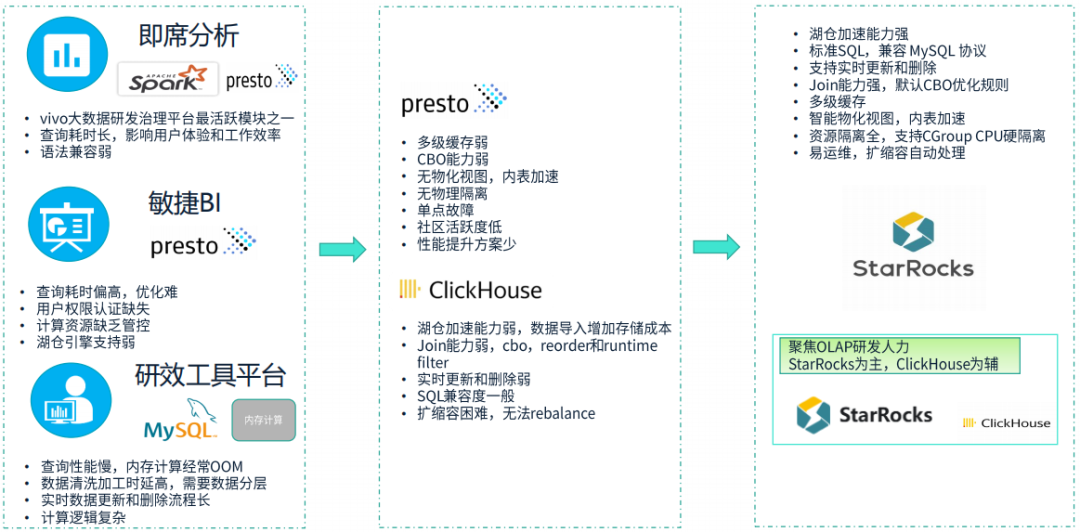
- 数据孤岛与一致性困境:
离线与实时两套链路,Schema 不一致、口径不统一,导致“同一个指标,两个结果”,业务方无所适从。
- 运维复杂度爆炸:
需要同时维护 Hive、HBase、Druid、Kafka 等多套系统,人力成本高、故障点分散。
- 时效性天花板:
即使有实时链路,从数据产生到 BI 可见仍需小时级,无法满足“敏捷 BI”和“即席分析”的分钟级需求。
团队的核心诉求变得清晰:构建一个 “一套存储、统一流批、开放标准” 的新架构,让数据 “写入即可见、查询即响应”。
二、 解决之道:vivo 湖仓一体架构全景图
vivo 并未盲目追逐技术潮流,而是基于 “稳定性优先、平滑演进” 原则,设计了一套务实的湖仓架构。这不仅是简单的技术组件堆砌,更是对其原有大数据平台的一次系统性重构。
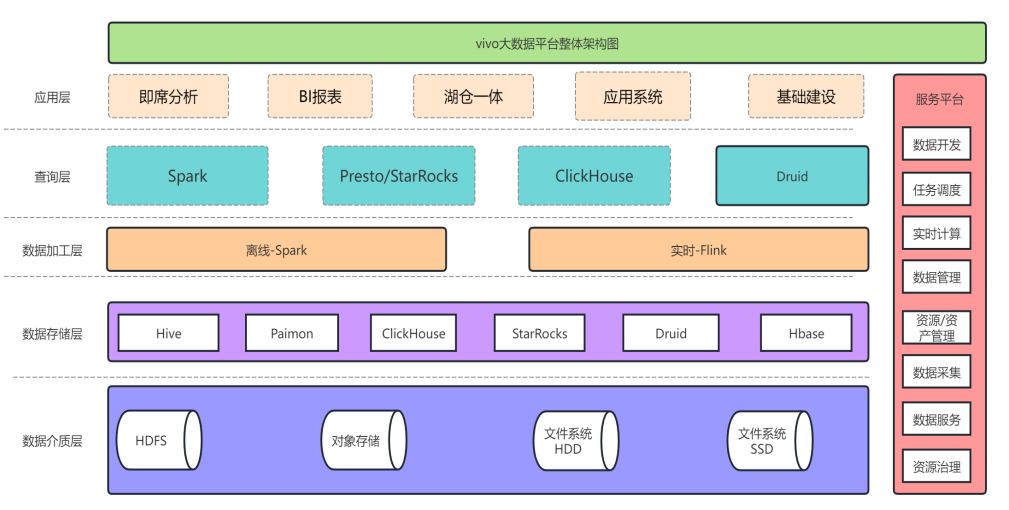
核心组件:
- 存储层:对象存储 + Iceberg 表格式
- 计算引擎:Flink(流) + Trino/Spark(批/交互)
- 元数据:自研 HMS(Hive Metastore)增强版
- 调度与治理:自研调度平台 + 认证鉴权、监控告警体系
架构优势:
- 存算分离:计算资源弹性伸缩,存储成本显著降低。
- ACID 事务:
Iceberg 表格式保证了流批写入的数据一致性。
- 开放生态:兼容 Hive 生态,现有 SQL 脚本几乎无需改造。
三、 实施流程:四步走战略,稳扎稳打
vivo 的迁移并非一蹴而就,而是分阶段、分场景稳步推进的,下图清晰展示了从立项到规模化的完整时间线:
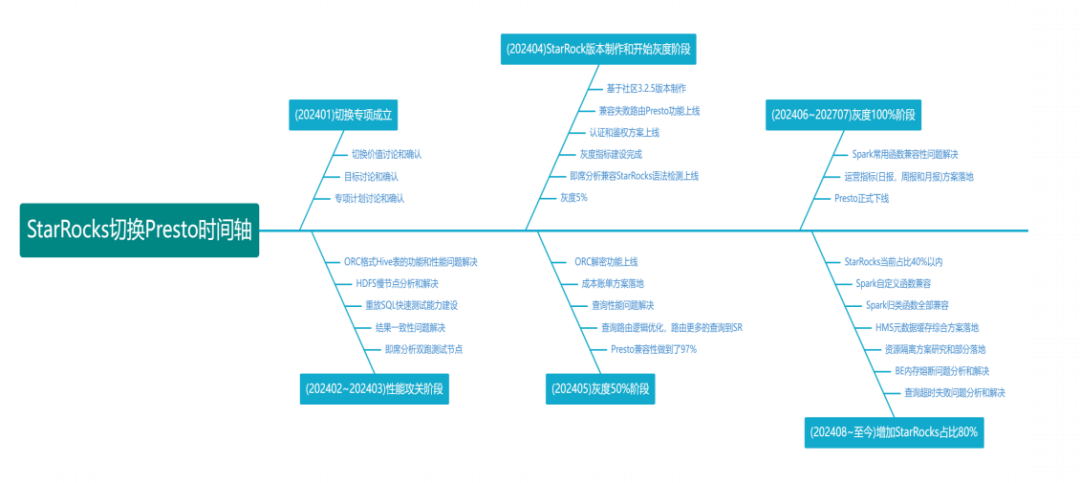
-
试点验证:
- 场景选择:选取 “研效工具平台” 这一非核心但高价值场景。
- 目标:验证
Iceberg + Trino 在 即席查询 场景下的性能与稳定性。
- 成果:查询性能提升 5-10 倍,P99 延迟从分钟级降至秒级。
-
核心场景迁移:
- 场景扩展:将 “敏捷 BI” 和 “运营日报/周报” 迁移至湖仓。
- 关键技术:使用
Flink CDC 实时同步 MySQL Binlog 到 Iceberg,并通过 Iceberg 的 Time Travel 特性轻松实现数据回溯。
- 成果:BI 报表数据延迟从 T+1 缩短至 10 分钟内。
-
全量推广与治理:
- 稳定性:实现 Crash 自动恢复、守护进程监控。
- 安全性:落地 Hive 表字段级加密、细粒度认证鉴权。
- 能力建设:构建 审计日志平台,实现全链路追踪。
- 收益量化:集群资源利用率提升 40%,运维人力节省 50%。
-
平台化与价值收集:
- 将湖仓能力 平台化,赋能业务自助分析。
- 建立 运营指标体系,持续收集业务价值反馈。
四、 关键优化:性能提升的核心技术细节
实现性能飞跃的背后,是一系列硬核的优化实践。下图汇总了从数据源到查询加速的关键优化工作:
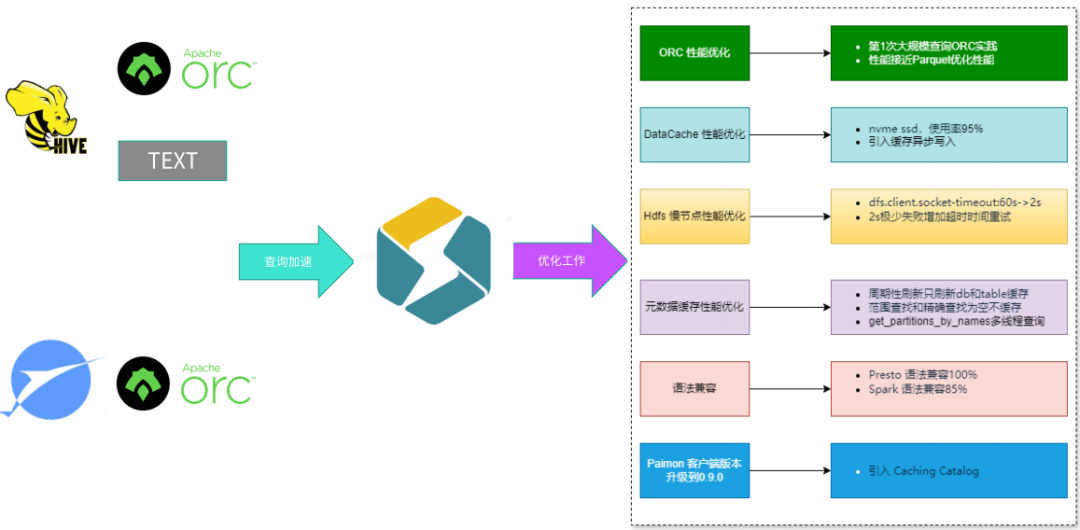
-
Iceberg 表设计优化:
- 分区策略:采用
event_date/hour 分区,避免小文件问题。
- 文件合并:配置 Auto-Compaction,自动合并小文件,提升查询效率。
- 列式存储:利用
Parquet 的 谓词下推 和 列裁剪。
-
Flink 写入 Iceberg 调优:
- Checkpoint 间隔:从 5min 优化至 1min,降低端到端延迟。
- Write-Ahead Log (WAL):开启 WAL,保证 Exactly-Once 语义。
- 并行度调整:根据
Kafka Topic Partition 数动态调整 Flink 并行度。
-
查询引擎加速(以 Trino 为例):
- 连接器优化:使用
Alluxio 作为缓存层,加速对象存储访问。
- 查询下推:将
Filter、Limit 等操作下推至 Iceberg 层执行。
- 资源隔离:通过 Resource Group 保证高优先级查询的 SLA。
-
元数据服务(HMS)增强:
- 缓存机制:对频繁访问的元数据进行本地缓存。
- 异步通知:当
Iceberg 表发生变更时,通过 消息队列 异步通知 HMS,避免轮询。
-
数据生命周期管理:
- 冷热分离:热数据存于高性能存储,冷数据自动归档。
- 自动过期:通过
Iceberg Expire Snapshots 定期清理历史快照,节省存储。
五、 避坑指南:实战中踩过的那些“深水雷”
-
小文件陷阱:
Flink 高频写入极易产生海量小文件,严重拖累查询性能。对策:必须配置 合理的 Checkpoint 间隔 并 开启 Auto-Compaction。
-
Schema 演进兼容性:
Iceberg 的 Schema Evolution 能力虽强,但 下游 Trino/Spark 版本过低会导致解析失败。对策:建立 严格的版本兼容矩阵,升级前充分测试。
-
元数据瓶颈:
HMS 可能成为单点瓶颈,高并发查询时响应缓慢。对策:增强 HMS 缓存 并 探索开源替代方案。
-
权限模型割裂:
Iceberg、Trino、Flink 各有权限体系,管理混乱。对策:统一接入公司 IAM 系统,实现 RBAC 细粒度控制。

六、 未来展望:湖仓一体的下一程
vivo 的湖仓之旅并未止步,团队已着眼三大未来方向:
- AI-Native Lakehouse:
将湖仓与 大模型训练/推理 深度结合,支持向量检索、特征存储等 AI 原生能力。
- Serverless 化:
探索 Flink on K8s、Trino Serverless,实现计算资源的极致弹性,这属于云原生架构的深度应用。
- DataOps 自动化:
构建 端到端的 Data Pipeline CI/CD,从代码提交到生产上线全流程自动化。
结语
vivo 的湖仓架构升级,不是一场炫技的技术秀,而是一次 以业务价值为导向、以稳定性为基石 的务实变革。它证明了:湖仓一体不是解决所有问题的银弹,但确实是攻克“数据时效性”这一核心痛点的有效路径之一。
对于所有正在经历类似转型的团队而言,vivo 的经验——从试点到推广、从性能调优到治理体系构建——都是一份宝贵的行动纲领。正如其内部所强调的:“基础能力建设、稳定性建设、运营指标建设” 三者缺一不可。
数据架构的终局,不在于追求最前沿的技术名词,而在于 让数据以更低的成本、更高的效率,精准驱动每一个关键业务决策。vivo 的实践,无疑为业界点亮了一盏有价值的引路明灯。想了解更多类似的大数据架构实践与深度讨论,欢迎访问 云栈社区。 |  发表于 2026-1-25 12:11:09
|
查看: 206|
回复: 0
发表于 2026-1-25 12:11:09
|
查看: 206|
回复: 0
