在数据驱动决策的时代,企业对实时数据分析的需求日益增长。然而,传统的数据处理架构常常面临一个尴尬的境地:以 Kafka 为代表的消息队列擅长高吞吐、低延迟的数据流转,但难以直接进行复杂分析;而以 ClickHouse、Doris 为代表的批处理分析引擎,虽然分析能力强大,但其固有的分钟级数据延迟又无法满足真正的实时性要求。
这就留下了一片空白——我们如何实现对海量流数据进行亚秒级的即时、复杂分析?这正是“分析型流存储”这一新兴技术范式旨在解决的核心问题。
传统架构的痛点与分析型流存储的定位
在讨论解决方案之前,我们先通过一个四象限图来审视当前主流大数据处理系统的分布格局。
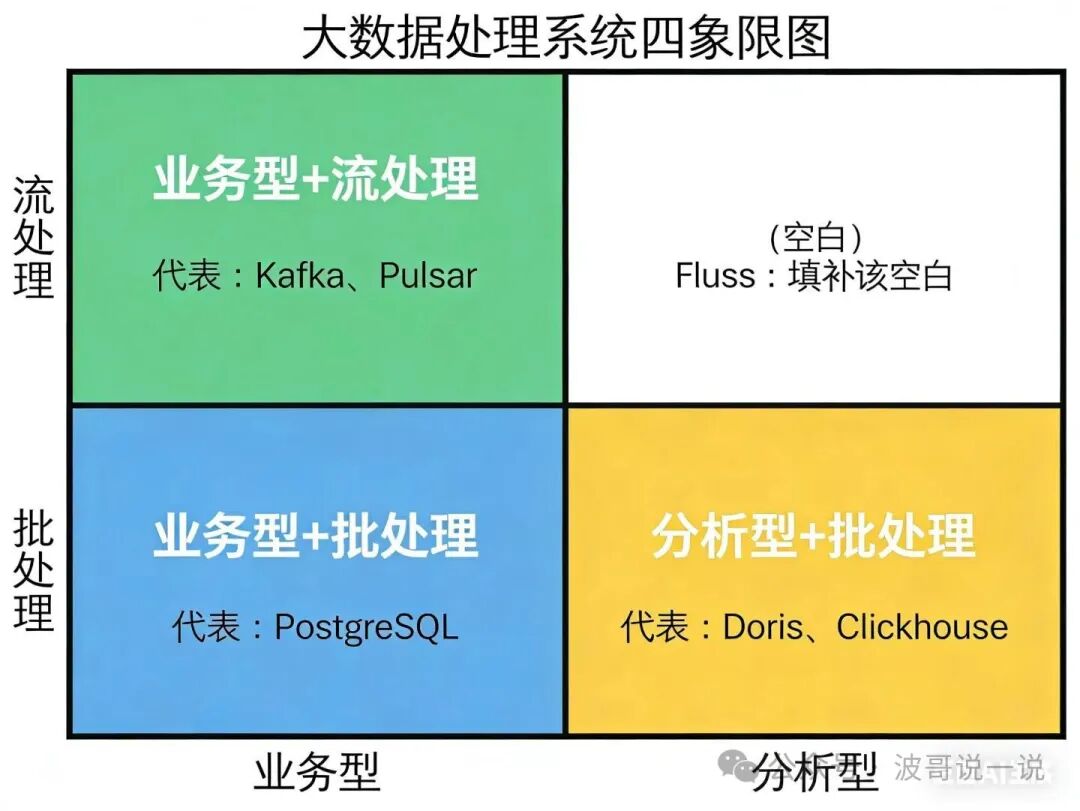
这张图清晰地揭示了现有技术的分野:
- 业务型流处理:以 Kafka、Pulsar 为代表,核心是高性能的流式数据传输。
- 业务型批处理:以 PostgreSQL、MySQL 等关系型数据库为代表,支撑在线事务处理。
- 分析型批处理:以 Doris、ClickHouse 为代表,专为海量数据的快速分析而设计。
可以看到,在“分析型”与“流处理”的交汇处,存在一个显著的空白。这直接导致了企业在构建实时分析系统时,不得不采用一种冗长且复杂的“拼装”架构:数据先通过 Kafka 等流系统收集,再通过 ETL 作业同步到数据湖仓,最后才能被分析引擎查询。这个链路不仅延迟高,还带来了数据冗余、存储成本高昂、运维复杂等一系列问题。
什么是分析型流存储?Apache Fluss 的诞生
Apache Fluss 正是为了填补上述空白而生的项目。它的定位非常明确:一个面向分析型场景设计的实时流存储系统。
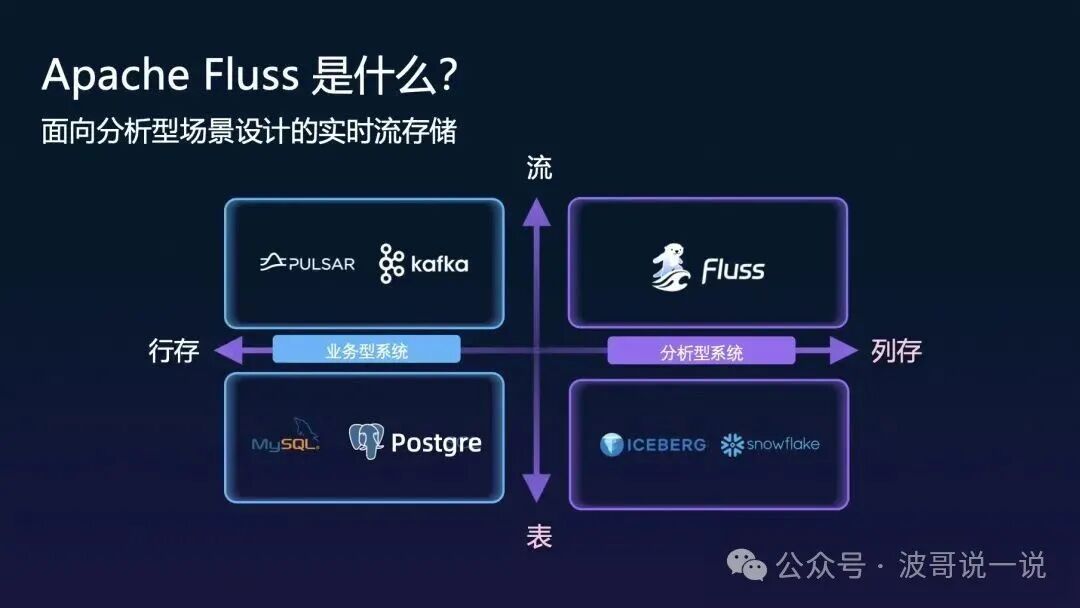
如图所示,Fluss 在技术光谱中占据了一个独特的位置。它一端连接着以行存为主的业务型系统(如 Pulsar/Kafka),另一端连接着以列存为主的分析型系统(如 Iceberg/Snowflake)。它自身则作为“流”与“表”的统一抽象,将流数据的实时性与分析型存储的高效查询能力结合起来,实现了数据“写入即可分析”。
Apache Fluss 的核心架构
要理解 Fluss 如何工作,我们来看一下其整体架构设计。
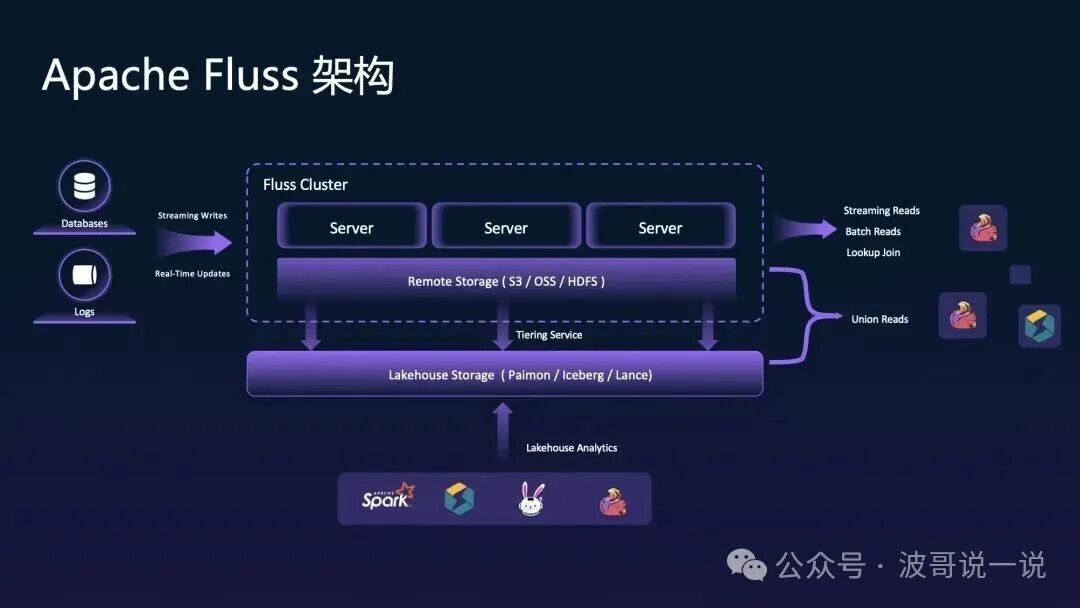
Fluss 的架构清晰地体现了其设计理念:
- 多源数据接入:支持从数据库(通过 Change Data Capture)或应用日志等源头进行实时流式写入。
- 分布式集群处理:数据写入 Fluss Cluster,由多个 Server 节点协同处理,保障高可用与水平扩展。
- 分层存储与湖仓集成:数据存储在远程对象存储(如 S3/OSS/HDFS)中,并通过 Tiering Service 实现冷热数据智能分层。热数据提供低延迟访问,冷数据可自动归档到 Iceberg、Lance 等开放的湖仓格式,便于长期存储与批处理分析。
- 多样化数据消费:下游应用可以通过流式读取、批量读取、点查(Lookup Join)、多流合并(Union Reads)等多种方式,使用 Flink、Spark 或其他计算引擎直接对 Fluss 中的数据进行实时分析。
Apache Fluss 解决的九大核心问题
基于其独特的架构,Apache Fluss 旨在系统性解决传统实时分析链路中的一系列痛点,主要可以归纳为以下九个方面:
1. 贴源层高效分析
传统流存储仅能传输数据,无法在数据源头直接进行复杂分析。Fluss 允许在贴源层就完成多维度聚合、窗口计算等分析需求,将分析逻辑下沉,减少数据搬移。

2. 贴源层高压缩比
采用列式存储和智能编码,相比传统以行存为主的消息队列,能实现更高的压缩率,据称可节省 50% 以上的存储成本。
3. 减少分布式文件系统无效 IO
避免了数据从流存储到数据湖仓的冗余拷贝过程,大幅降低了底层分布式文件系统(如 HDFS)的无效读写开销。
4. 填补实时性缺口
突破了传统批处理分析分钟级延迟的瓶颈,实现了亚秒级的实时分析,真正做到数据产生即可查询。
5. 简化冗长数据链路
一站式承接“流数据写入 - 实时存储 - 即时分析”全链路,替代“Kafka + 数据湖仓 + 分析引擎”的复杂组合架构,显著减少中间环节带来的性能和运维损耗。

6. 原生复杂分析能力
无需额外集成 Flink 等流计算引擎,在存储层原生提供支持复杂实时分析的能力,降低了整体架构的复杂度和运维成本。
7. 冷热数据智能分层
自动管理数据生命周期,热数据存储在低延迟介质中保障查询性能,冷数据自动归档到成本更低的 Lakehouse 存储,在成本与性能间取得平衡,且对用户透明无感知。
8. 高并发查询资源优化
列式存储配合智能索引,能够大幅降低高并发查询场景下的 IO 与内存占用,避免计算资源的无谓浪费。

9. 保障数据一致性
得益于流存储与分析能力的一体化设计,数据一旦写入即可保证一致性视图,无需在后续分析前进行额外的数据校准,保障了分析结果的准确性和可信度。
总结
总而言之,Apache Fluss 所代表的“分析型流存储”,并非对现有流处理或分析技术的简单替代,而是一次重要的架构演进和范式补充。它瞄准了传统 大数据 架构在实时分析领域的固有缺陷,通过将流式存储与列式分析能力深度融合,为企业提供了一条更简洁、更高效、更低成本的实时数据价值挖掘路径。对于正在被复杂实时数据栈困扰的团队来说,了解并评估这类新兴技术,或许能为下一个数据平台的建设找到更优解。想了解更多前沿技术实践与架构思考,欢迎访问 云栈社区 与广大开发者交流探讨。
 发表于 2026-2-23 04:50:19
|
查看: 265|
回复: 0
发表于 2026-2-23 04:50:19
|
查看: 265|
回复: 0
