
ChatGPT的爆火带动了大模型浪潮,紧随其后的检索增强生成(RAG)技术,又将向量数据库推到了聚光灯下。
一时间,朋友圈里隔三差五就能看到“某某向量数据库碾压传统数据库”的论调,让不少DBA朋友感到焦虑,甚至琢磨着要不要赶紧报个班学学新技术。
上个月和一位架构师朋友吃饭,他提到领导一拍桌子决定:“我们要上AI项目,先把MySQL换成向量数据库!” 朋友当时差点把咖啡喷出来。
那么,这种替换真的有必要吗?今天我们就来仔细聊聊这个话题。
向量数据库究竟解决了什么痛点?
坦白说,向量数据库并非一个全新的概念。早在十多年前,做搜索引擎的那批工程师就在玩近似近邻搜索(ANN),用的无非是KD树、局部敏感哈希(LSH)、分层可导航小世界(HNSW)这些算法。
它为什么在今天突然火了起来?核心驱动力来自于大模型。
大模型在生成内容时需要精准的上下文,不可能把整个知识库都塞进有限的上下文窗口——成本太高,而且容易导致信息混乱。因此,RAG架构几乎成了标配:先从知识库中检索出相关文档片段,再将这些片段喂给大模型生成答案。
而这个“检索”过程,搜的不是关键词,是语义。例如,用户查询“支付宝额度”,系统需要能把关于“花呗提额”的文章也找出来。这就必须将文本转化为高维向量,然后计算它们之间的余弦相似度。
这正是向量数据库最擅长的事情:大规模高维向量的快速相似性搜索。
它在技术上的优势非常明显:
- 性能卓越:对于千万甚至亿级规模的向量,能做到毫秒级的检索响应,这是传统关系型数据库难以企及的。
- 语义精准:基于向量的语义匹配,比基于关键词的全文检索精准得多,尤其擅长处理长文本和多轮对话场景。
- 运维便捷:支持向量的动态插入、更新和删除,相比将向量索引存为静态文件(如FAISS索引文件)的方案,更易于维护和集成。
但问题在于,很多人把“擅长”误解成了“万能”,恨不得把所有数据都往向量数据库里塞。
MySQL真的就落伍了吗?
说出来你可能不信,MySQL 8.0 已经原生支持向量检索了。
没错,就是那个我们日常开发中最常打交道的关系型数据库。从 8.0.32 版本开始,MySQL 悄然引入了 VECTOR 数据类型以及近似最近邻搜索的功能。
性能如何?根据一些基准测试,在百万级向量规模以内,其检索延迟与专用向量数据库的差距并不大,完全能够满足绝大多数中小型公司的业务需求。
更关键的是,我们业务系统中90%的数据,天生就是结构化的:
- 用户ID、订单时间、商品价格
- 标签分类、状态流转、权限控制
- 需要事务保证、ACID特性、复杂联表查询的业务逻辑
对于上述需求,向量数据库天生就不擅长。强行用向量库来实现,不是做不到,就是会让代码变得异常复杂和别扭,后期维护成本高昂。
我见过一个团队,为了追求“全栈AI化”,将用户的姓名、年龄、地址等基本信息也存入向量库。结果,实现一个简单的分页查询功能就需要编写数百行代码,维护起来苦不堪言。
说白了,MySQL能活跃这么多年,并非因为开发者守旧,而是因为它确实能打。强大的事务支持、严格的数据一致性、极其成熟的生态圈、以及海量会写SQL的工程师——这些都是经过时间和无数项目验证的宝贵资产。
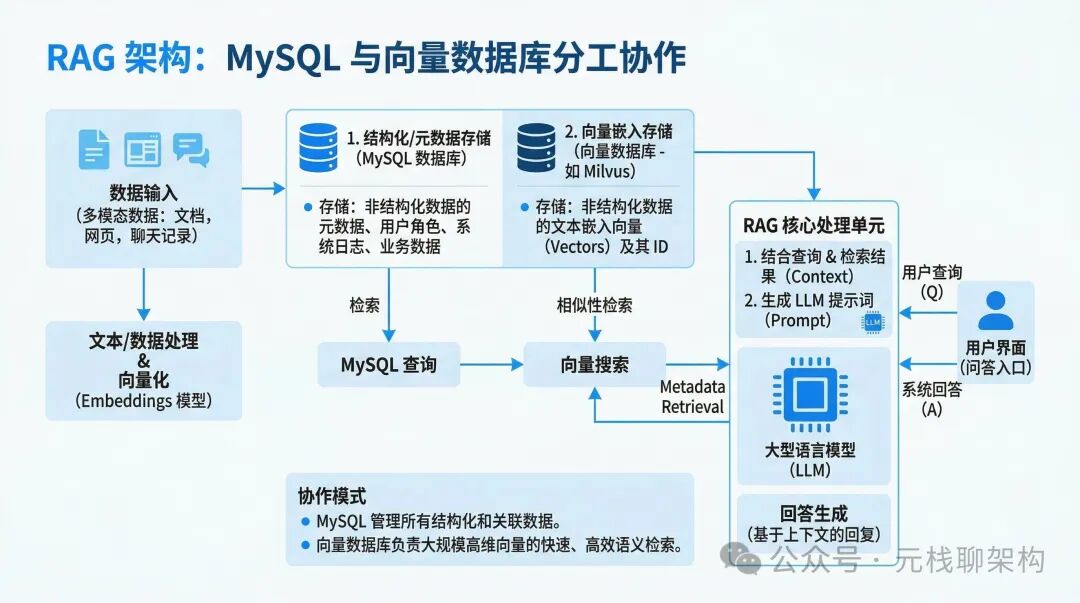
取代?不,分工协作才是正解
如果你去观察那些真正运行在生产环境中的RAG系统,超过九成采用的是混合架构:
| 数据类型 |
存储位置 |
| 原始业务数据、结构化信息、元数据 |
MySQL |
| 文档的嵌入向量(Embeddings)、向量索引 |
向量数据库(如 Milvus, Pinecone) |
举一个实际的例子:构建一个企业内部知识库问答机器人。
用户提问:“我去年报销的差旅费里,交通费超过五千的有哪几笔?”
这个问题应该如何拆解处理?
- 语义检索:将用户问题转化为向量,在向量数据库中检索与“差旅费报销”相关的制度、政策文档。这是向量数据库的职责。
- 结构化查询:根据当前用户的ID,在MySQL中查询其去年所有的报销记录,并通过SQL语句轻松筛选出“交通费 > 5000”的订单。这是MySQL的专长。
- 合成答案:将第1步检索到的相关制度文本和第2步查询到的具体业务数据,一并组合成上下文,提交给大语言模型(LLM),生成最终的回答。
这个流程中,缺了谁都不行。缺了向量库,无法实现精准的语义召回;缺了MySQL,复杂的结构化查询将举步维艰。
其背后的分工逻辑其实非常朴素:
MySQL 负责管理“事务”和“结构化数据”,向量数据库 负责“语义搜索”和“向量索引”。
两者各司其职,优势互补,难道不香吗?
什么情况下,只用MySQL就够了?
如果你的项目符合以下大部分情况,我建议你先别急着引入独立的向量数据库,用MySQL 8.0的向量功能完全可以胜任,省下的成本和运维精力给团队发点奖金岂不更好?
- 数据规模适中:向量总量在百万级别以内(千万级其实也能应对,只是索引体积会增大)。
- 延迟要求非极致:业务对查询延迟的P99要求不是苛刻到必须毫秒必争。
- 数据结构化为主:你的数据中80%以上仍然是传统的结构化业务数据。
- 团队资源有限:团队没有专职的AI基础设施工程师,遵循“能少维护一个系统就少一个”的原则。
我知道头部大厂有处理万亿级向量的场景,但那是业务规模和技术需求倒逼的结果。作为一个初创公司或中等规模项目,在只有几百万条数据时盲目跟风,往往得不偿失。
技术选型最忌讳的就是“别人用什么,我就必须用什么”。盲目套用抖音、字节的架构,十有八九会消化不良。
什么情况下,必须引入独立向量数据库?
当然,我们也不能说MySQL可以包打天下。如果你的项目满足以下任意一条,那么引入专门的向量数据库就是明智之举:
- 海量数据与高性能要求:向量规模超过千万级,且对查询性能和并发有极高要求。
- 需要企业级特性:业务场景需要多租户隔离、细粒度权限控制、弹性扩缩容等高级功能。
- AI为核心业务:团队已经建立了成熟的AI平台,向量检索是业务的核心组成部分。
- 需要高级检索功能:业务必须使用混合搜索(关键词+向量)、多向量打分排序、稀疏向量等专用特性。
说到底,是业务需求驱动技术选型,而不是让炫酷的技术来驱动业务变形。
一些心里话
AI这阵风确实刮得很大,让很多人产生了技术焦虑,仿佛今天不换上最新的向量数据库,明天就要被时代淘汰。
我见过太多团队,为了追赶技术潮流,将原本清晰稳健的架构拆得七零八落,引入一堆自身能力无法驾驭的新技术栈。最终往往在项目上线前推倒重来,白白浪费数月时间和大量资源。
冷静下来想想,我们技术人的核心目标,从来不是“使用最前沿的技术”,而是“用最合适的技术解决实际的业务问题”。
MySQL诞生快三十年了,见证了一波又一波新技术的兴起与沉寂。声称要取代它的声音从未断绝,但它至今仍是互联网世界不可或缺的基础设施。
向量数据库是个优秀的技术工具,但它应该是来帮你解决问题的,而不是来发动“技术革命”的。
在未来可预见的时间内,并存与协作,才是这两种数据库的常态。
总结
- 向量数据库擅长高维向量的快速语义相似性搜索,是构建高效RAG系统的核心组件。
- MySQL并未过时,在管理结构化数据、处理复杂事务、保证强一致性方面,它依然是无可替代的选择。
- 现实中的生产级架构大多是混合模式:MySQL存储业务实体和元数据,向量数据库存储嵌入向量和索引。
- 对于百万级以内的向量场景,直接使用MySQL 8.0的向量功能往往是更务实、性价比更高的选择,无需盲目引入新技术栈。
- 技术选型的金科玉律是:适合自身业务发展阶段和团队能力的,才是最好的技术。在云栈社区的众多技术讨论中,这一原则也被反复验证。
 发表于 2026-4-5 06:51:55
|
查看: 122|
回复: 0
发表于 2026-4-5 06:51:55
|
查看: 122|
回复: 0
