上一个周末,我从 400 行核心代码起步,逐步将一个工程演进成完整的、支持多租户的 AI Agent 平台。本文将完整记录这段从零开始的技术构建旅程。
为什么要从零开始构建这个平台?
市面上的 AI Agent 平台要么体系过于臃肿,动辄需要部署几十个微服务;要么过于封闭,无法自由地自定义工具和技能。我们真正想要的其实很简单:
- 单二进制部署,做到零外部依赖,简化运维。
- 多用户隔离,确保每个用户都有独立的沙箱化工作区,互不影响。
- 真正的智能体,不是简单的聊天套壳,而是能够自主调用工具、执行代码、并且记忆上下文的 Agent。
- 可插拔的生态,支持通过 MCP 协议接入数百个外部工具,并集成 SkillHub 技能市场。
最终,我们使用 Rust 实现了所有这些目标,并用 Tauri + React 构建了轻量级的桌面客户端。
架构设计全景图
整个系统的架构设计如下,清晰地划分了前后端与核心组件:
┌─────────────────────────────────────────────────────┐
│ Tauri Desktop App │
│ React + Tailwind (shadcn rose) │
│ ┌──────────┐ ┌──────────┐ ┌────────────────┐ │
│ │ ChatView │ │ ToolCard │ │ SkillHub Panel │ │
│ │ 流式渲染 │ │ 工具展示 │ │ 技能市场浏览 │ │
│ └────┬─────┘ └────┬─────┘ └───────┬────────┘ │
│ │ SSE / WebSocket │ │
├───────┼──────────────────────────────┼─────────────┤
│ ▼ Gateway (Axum) ▼ │
│ ┌─────────┐ ┌──────┐ ┌──────┐ ┌────────┐ │
│ │JWT Auth │ │ REST │ │ WS │ │ SSE │ │
│ └────┬────┘ └──┬───┘ └──┬───┘ └───┬────┘ │
│ └─────────┼────────┼─────────┘ │
│ ┌──────▼────────▼──────┐ │
│ │ Session Manager │ DashMap │
│ └──────────┬───────────┘ │
│ ▼ │
│ ┌─────────────────────┐ │
│ │ Agent Runner │ │
│ │ ┌───────────────┐ │ │
│ │ │ Agent Loop │ │ 最多 20 轮自主决策│
│ │ │ LLM ⇄ Tools │ │ │
│ │ └───────────────┘ │ │
│ │ ┌───────┐┌──────┐ │ │
│ │ │Memory ││Skills│ │ │
│ │ └───────┘└──────┘ │ │
│ └──────────┬──────────┘ │
│ ┌───────────────┼───────────────┐ │
│ ▼ ▼ ▼ │
│ ┌────────┐ ┌────────────┐ ┌──────────┐ │
│ │10 Tools│ │MCP Servers │ │ SkillHub │ │
│ │内置工具 │ │外部工具协议 │ │ 技能市场 │ │
│ └────────┘ └────────────┘ └──────────┘ │
│ ▼ │
│ ┌─────────────────────┐ │
│ │ Sandbox Backend │ │
│ │ 文件夹隔离 / 路径防穿越 │ │
│ └─────────────────────┘ │
└─────────────────────────────────────────────────────┘
备注:这里的技能市场是直接接入的腾讯 SkillHub。
核心引擎:Agent Loop 的设计
许多所谓的“AI应用”本质上只是一个聊天转发器:用户输入,调用LLM API,返回文本。这远远称不上是一个真正的智能体。
真正的 Agent 核心在于 工具调用循环 (Tool Calling Loop),一个动态的决策-执行过程。例如:
用户: “帮我创建一个 hello.py 并运行它”
↓
LLM 决定: 调用 file_write 工具
↓
系统执行: 写入 hello.py
↓
LLM 看到结果,决定: 调用 exec 工具
↓
系统执行: python3 hello.py → “hello world”
↓
LLM 综合结果: “文件已创建并运行,输出是 hello world”
我们的 Rust 实现简洁而高效,核心逻辑如下:
for iteration in 0..MAX_TOOL_ITERATIONS {
let response = self.llm
.chat_with_tools(&messages, Some(&tools)).await?;
if has_tool_calls(&response) {
// 执行工具,并将结果追加到对话上下文
for tc in tool_calls {
let result = self.tool_registry.execute(&tc.name, params).await;
messages.push(ChatMessage::tool(&tc.id, &result.content));
}
// 继续循环,让 LLM 基于工具执行结果进行下一步决策
} else {
// LLM 返回纯文本回复,循环结束
return Ok(response.content);
}
}
几个关键的设计决策确保了系统的健壮性:
- 设置最大迭代轮数,防止 Agent 陷入无限循环,此上限可由管理员配置。
- 严格的超时控制:每个工具调用最长 60 秒,
exec 命令执行最长 30 秒。
- 超时后自动清理:强制终止相关子进程,并将错误返回给 LLM,由它来决定如何处理失败。
内置工具:少而精的核心能力
我们只内置了 10 个核心工具,因为许多特定工具可以通过后文提到的 MCP 协议动态注入,内置工具追求的是“够用”。
| 工具 |
能力 |
exec |
执行任意 shell 命令(sh -c,支持管道、重定向) |
file_read |
读取工作区内的文件内容 |
file_write |
创建或写入文件 |
file_edit |
查找并替换,编辑文件内容 |
list_files |
列出目录内容(支持递归) |
apply_patch |
应用 unified diff 格式的补丁 |
web_search |
调用 DuckDuckGo 进行网页搜索 |
web_fetch |
抓取网页内容,并自动将 HTML 转换为 Markdown |
memory_search |
在用户的记忆文件中进行搜索 |
memory_get |
读取指定的记忆文件 |
所有工具都通过一个统一的 Tool trait 来定义,保证了接口的一致性:
#[async_trait]
pub trait Tool: Send + Sync {
fn name(&self) -> &str;
fn description(&self) -> &str;
fn parameters_schema(&self) -> serde_json::Value; // JSON Schema
async fn execute(&self, params: Value) -> ToolResult;
}
工具由 ToolRegistry 统一管理,它能自动将这些工具的接口描述转换为 OpenAI function calling 格式的 JSON Schema,并传递给大语言模型。
无限扩展:通过 MCP 协议接入外部工具生态
MCP (Model Context Protocol) 是由 Anthropic 推出的开放协议,它让 AI Agent 可以连接到任意的外部工具服务器,极大地扩展了能力边界。
我们实现了完整的 MCP 客户端。只需在配置文件中声明,即可接入海量工具:
# config/default.toml
[[mcp.servers]]
name = “playwright”
command = “npx”
args = [“-y”, “@playwright/mcp@latest”]
平台启动时会自动:
- 通过 stdio 启动 MCP Server 子进程。
- 完成 JSON-RPC 2.0 握手流程。
- 发现该服务器提供的所有工具。
- 将其注册到全局的
ToolRegistry 中。
之后,Agent 就可以像使用内置工具一样,无缝调用 Playwright 进行浏览器自动化操作:
用户: “打开 https://example.com 并截图”
Agent: [调用 playwright.navigate] → [调用 playwright.screenshot] → 完成
整个 MCP 传输层的 Rust 实现非常精简,核心结构体仅约 150 行代码:
pub struct StdioTransport {
child: Child,
writer: Arc<Mutex<BufWriter<ChildStdin>>>,
pending: Arc<DashMap<u64, oneshot::Sender<Result<Value>>>>,
next_id: AtomicU64,
}
大脑升级:技能 (Skill) 系统
如果说工具 (Tool) 是 Agent 执行任务的手脚,那么技能 (Skill) 就是指导它如何思考的大脑。
一个技能本质上是一个结构化的 SKILL.md 文件——一份详细的提示词(Prompt),教导 Agent 在特定场景下,应该按什么流程、使用哪些工具。
---
name: weather
description: Check current weather for any city
---
When the user asks about weather:
1. Use web_search to find current weather data
2. Use web_fetch to get details from a weather site
3. Present: temperature, conditions, humidity, wind speed
技能的三种获取方式
1. 内置技能 — 开箱即用
我们内置了 6 个核心技能,如 weather(天气查询)、coding(代码助手)、research(研究助手)等。
2. SkillHub 技能市场 — 一键安装
我们集成了腾讯 SkillHub 和 ClaHub 双数据源,提供了 100+ 个开箱即用的技能。后端并行请求两个数据源,合并去重后返回给前端;用户在前端的 SkillHub 面板中即可浏览、搜索并一键安装。
3. 对话创建 — 让 Agent 帮你写技能
内置的 skill-creator 技能允许用户通过自然语言对话,让 Agent 帮助生成自定义技能文件,并自动写入 workspace/skills/ 目录,即刻生效。
持久化记忆:实现跨会话的上下文
一个强大的 Agent 需要记忆。我们的记忆系统不局限于聊天记录,而是借鉴了 OpenClaw 风格的文件式记忆体系。
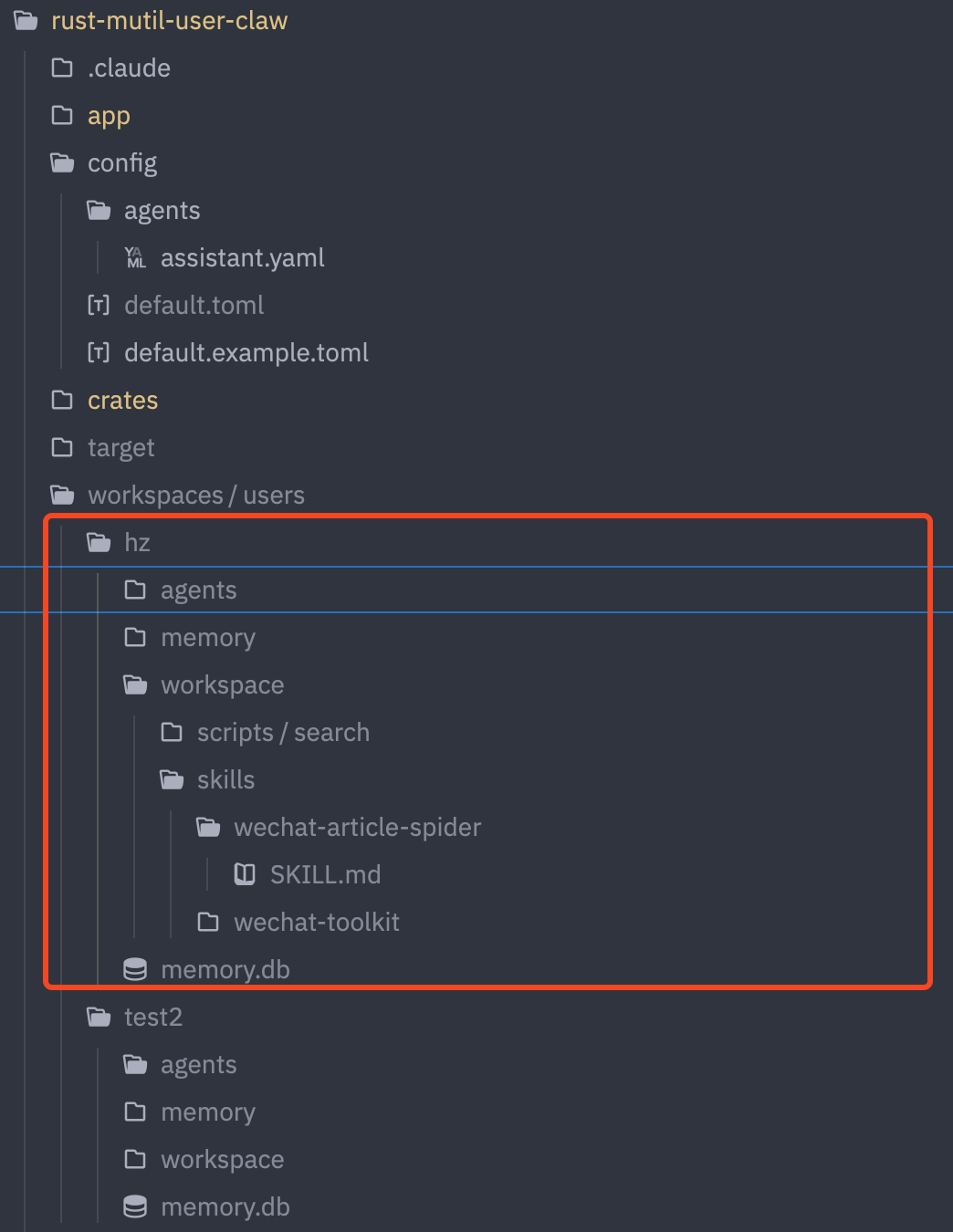
每个用户的工作区目录结构如下:
workspaces/users/{user_id}/
├── workspace/
│ ├── MEMORY.md ← 长期记忆文件,每次对话开始时自动加载到上下文中
│ └── memory/
│ └── 2026-04-03.md ← 按日期生成的记忆日志
└── memory.db ← SQLite 数据库,存储结构化的聊天历史
每次 Agent 启动时,系统会自动将 MEMORY.md 和最近两天的日志内容注入 System Prompt。同时,Agent 在运行过程中也可以通过 file_write 等工具,主动向记忆文件中写入重要信息。用户可以在前端侧边栏实时查看和管理自己的记忆内容。
流式响应:提升用户体验的关键
为了不让用户在等待 LLM 生成完整回复时感到焦虑,我们实现了完整的 Token 流式输出。实现原理清晰:
// LLM 客户端:解析 SSE 流,逐个 Token(delta)发送
pub async fn chat_stream(
&self, messages, tools, tx: &Sender<StreamChunk>
) -> Result<ChatMessage> {
// stream: true → 获取 reqwest bytes_stream → 逐行解析 → 发送 Delta
}
// Agent Runner 端:将收到的 Delta 转发到前端事件通道
while let Some(chunk) = stream_rx.recv().await {
match chunk {
StreamChunk::Delta(text) => {
tx.send(AgentEvent::Text { content: text }).await;
}
...
}
}
安全基石:多租户隔离的实现
多租户隔离是企业级平台的核心需求。我们的整体架构清晰地体现了隔离层次。
openclaw/
├── Cargo.toml # workspace 根
├── crates/
│ ├── openclaw-gateway/ # Axum 网关、WebSocket、REST
│ ├── openclaw-agent/ # Agent 运行核心(Runner, Skill, Memory)
│ ├── openclaw-sandbox/ # 沙箱抽象层(核心隔离模块)
│ └── openclaw-config/ # 配置管理
├── config/ # 配置文件
└── workspaces/ # 运行时用户工作区(按用户ID隔离)
└── {user_id}/
├── workspace/ # 用户个人工作文件
├── agents/ # 用户个人Agent配置
└── memory.db # 用户个人聊天数据库
在安全层面,我们采取了分层策略:基础层使用文件夹隔离,并辅以严格的路径安全检查防止目录穿越;高级层则计划支持 macOS 的 sandbox/container 和 Linux 的 namespace/gVisor/Firecracker 等更彻底的沙箱技术。作为一个服务端优先的平台,我们目前主要专注于 Linux/macOS 环境。
这样一来,每个用户都拥有完全独立、互不干扰的:
- 文件工作区(经过沙箱路径校验)。
- SQLite 数据库(存储私密聊天历史)。
- 长期记忆文件(
MEMORY.md)。
- 已安装的技能集合。
- MCP 工具实例。
用户通过注册/登录获得 JWT Token,在任何设备上使用同一账号登录,都将映射到同一个隔离的虚拟工作空间。
核心的路径安全检查函数如下:
// 路径安全校验,防止用户通过相对路径访问系统或其他用户文件
fn safe_path(&self, user_id: &str, relative: &Path) -> Result<PathBuf> {
let root = normalize_path(&self.user_root(user_id));
let normalized = normalize_path(&root.join(“workspace”).join(relative));
if !normalized.starts_with(&root) {
return Err(anyhow!(“Path escape detected”));
}
Ok(normalized)
}
跨平台客户端:基于 Tauri 的桌面应用
我们默认提供了一个使用 Tauri 开发的桌面客户端。得益于清晰的架构设计,这个核心的 Rust Claw Gateway 也可以轻松对接飞书、微信等生态,因为它本质上是一个标准的后端服务。
技术栈:Tauri 2.0 + Vite + React + Tailwind CSS
核心前端组件:
LoginScreen — 处理用户注册/登录,Token 存储于 localStorage。ChatView — 消息列表,支持自动滚动与 Markdown 渲染。ToolCallCard — 折叠式工具调用展示组件(包含状态指示灯、调用参数和执行结果)。MemorySidebar — 实时展示和管-理用户的记忆文件与技能。SkillPanel — 双标签页面板(“我的技能” 和 “SkillHub 市场”)。useChat hook — 封装了 SSE 流式通信的状态管理逻辑。
前端处理流式响应的核心逻辑片段:
// SSE 流式 hook 核心逻辑
for await (const event of chatStream(token, text)) {
switch (event.type) {
case ‘text’: msg.content += event.content; break;
case ‘tool_start’: msg.toolCalls.push({…}); break;
case ‘tool_result’: /* 更新最后一个运行中的工具 */; break;
case ‘done’: msg.isStreaming = false; break;
}
}
总结与展望
这个项目实践证明了:使用 Rust 构建 AI Agent 平台,不仅是可行的,更是优雅且高效的。
单二进制部署、极低的内存占用、强大的类型安全、卓越的异步并发性能——这些都是 Rust 的天然优势。而 Tauri 框架让我们能够利用熟悉的 React 等 Web 技术快速构建出高性能的跨平台桌面客户端,完全避免了 Electron 那样沉重的内存开销。
从 400 行核心代码到功能完备的多租户平台,这是一次充满挑战也极具成就感的 开源实战。我们希望这次的技术分享能为你带来启发。完整代码已开源,欢迎在 云栈社区 与更多开发者交流探讨。
项目地址:https://github.com/coder-brzhang/rust-mutil-user-claw
 发表于 2026-4-5 06:54:18
|
查看: 163|
回复: 0
发表于 2026-4-5 06:54:18
|
查看: 163|
回复: 0
