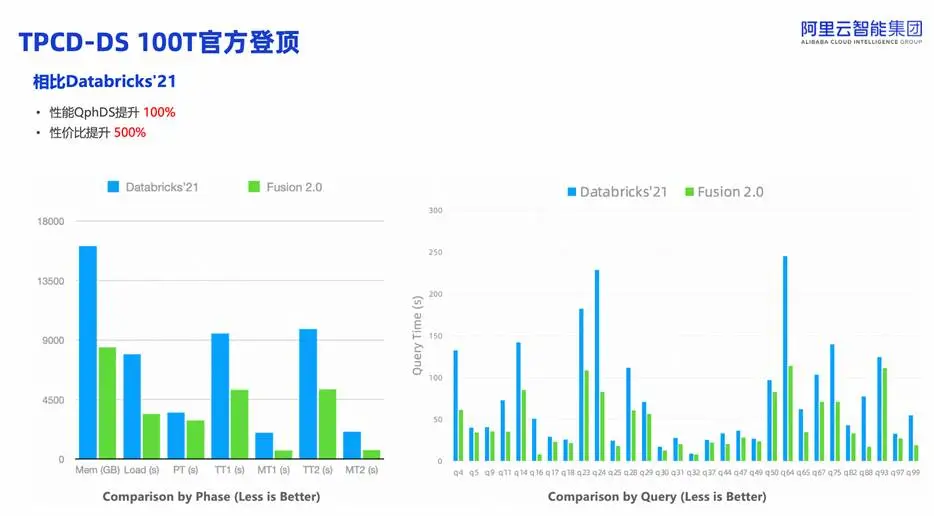
2025年9月,阿里云 EMR Serverless Spark 以 QphDS 超 6568 万分的性能结果成功登顶 TPC-DS 100T 榜单,这是全球大数据领域最具权威性和挑战性的性能测试基准。
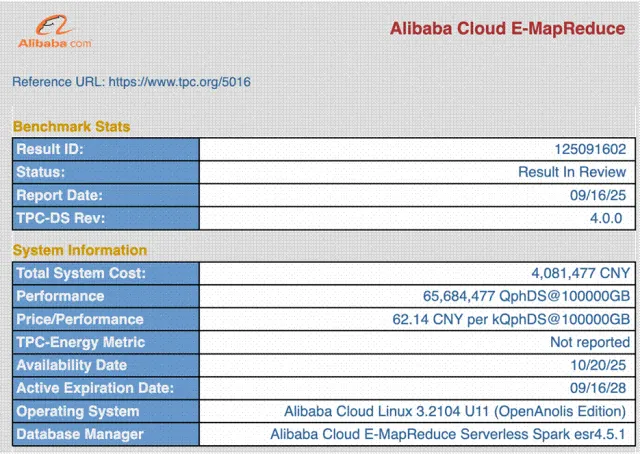
TPC-DS Benchmark 是数据仓库领域最新和最复杂的权威测试标准,被工业界和学术界广泛认可,也是数据仓库选型的重要参考指标。TPC-DS 包含 99 个查询,从简单的全局聚合到复杂的 20 以上多表连接,体现了真实分析场景日益增长的复杂度。其中,100T 是 TPC-DS 提供的最大测试数据集,最大表有 288,017,344,252(2880 亿)条数据,迄今为止只有阿里云 EMR 和 Databricks 成功通过了该榜单的官方评审。
阿里云 EMR Serverless Spark 实现了 性能提升 100%、性价比提升 500% 的突破,证明了 EMR Serverless Spark 在 OpenLake 湖仓底座架构下,超大规模、超高复杂度的数据分析、数据更新、数据处理的市场领先能力。

本文将深入剖析支撑这一成绩背后的技术内核,从产品定位、架构设计到核心优化策略,全面解读 EMR Serverless Spark 如何实现“高性能、低成本、高弹性、强兼容”的统一。
产品定位与核心场景
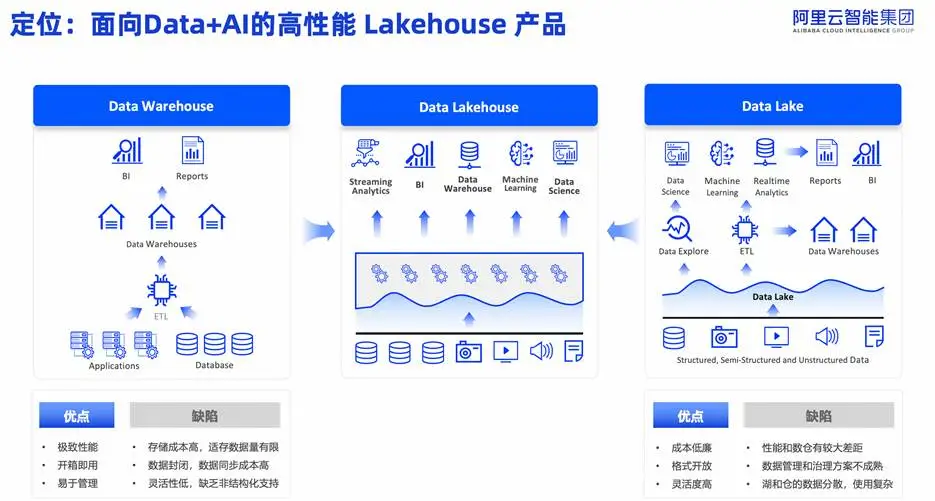
EMR Serverless Spark 定位为新一代 Lakehouse(湖仓一体)平台,旨在融合传统数据仓库的极致查询性能与数据湖的低成本、开放性优势。
其核心聚焦三大场景:
- 湖仓分析场景:以高度优化的 Spark 替代 Hive 执行 ETL/ELT 任务,替代Trino/Presto 提供高性价比交互式分析。支持 SQL、DataFrame、Pandas、RDD 等多种接口,并全面兼容 Paimon、Iceberg、Delta、Hudi 等主流湖表格式。
- 机器学习场景:作为成熟的分布式 ML 框架,Spark 支持从数据清洗、特征工程到模型训练与批量推理的全流程。内置 MLlib,集成 XGBoost、LightGBM、scikit-learn 等生态工具,并提供 GPU 加速能力,实现 Data + AI 一体化。
- 多模态数据处理场景:随着大模型兴起,PySpark 成为处理文本、图像、视频等非结构化数据的理想选择。产品推出的 AI Function 功能,允许用户在 Spark 作业中直接调用大模型。针对基模训练数据预处理做了专门优化,在文本去重任务中实现 5 倍性能提升。
产品架构与极致弹性
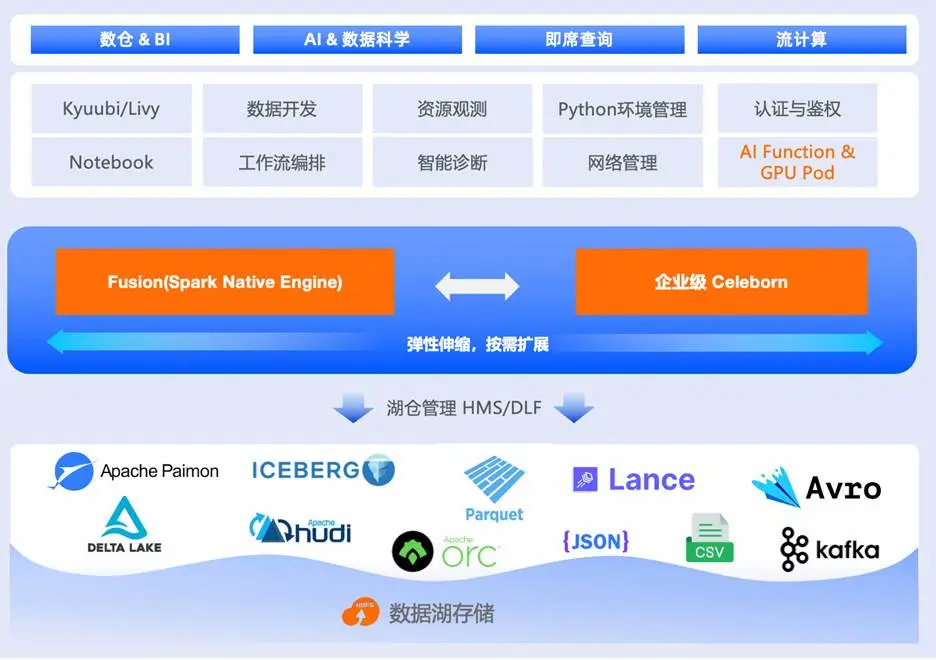
EMR Serverless Spark 采用标准 Lakehouse 架构:
- 存储层:基于阿里云 OSS 对象存储与 OSS-HDFS 接口,提供高吞吐、低成本的持久化能力;
- 元数据层:兼容 Hive Metastore(HMS)与 Data Lake Formation(DLF),支持 ACID 事务;
- 资源层:依托阿里云全 Region 的 ECS 资源池,实现近乎无限的弹性供给;
- 引擎层:核心创新包括 Fusion 向量化执行引擎 与 Celeborn Remote Shuffle Service;
- 产品层:提供认证鉴权、开发 IDE、资源监控、智能诊断等企业级功能。
极致弹性 是其关键竞争力:
- 支持 进程级弹性,最小资源单位低至 1 Core;
- 容器启动时间 <15 秒,会话模式、Standalone 模式下实现“零冷启”;
- 采用 Workspace + 队列的双层 Quota 机制,满足多租户资源隔离需求;
- 实际客户案例显示,资源使用波动可从数万核骤降至零,Serverless 架构帮助客户 节省 40% 资源成本。
此外,系统默认提供 跨可用区高可用 能力,Spark 控制面与 Celeborn 服务均多 AZ 部署,作业自动故障迁移,SLA 达 99.9%,且无额外费用。
全方位生态兼容
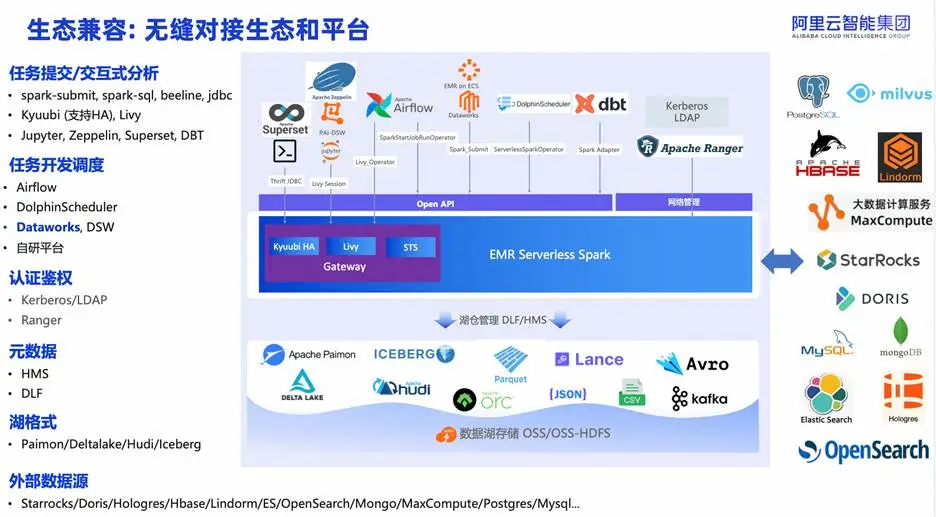
EMR Serverless Spark 坚持 开放生态优先 的设计理念,这使其在大数据平台选型中极具吸引力:
- 接口兼容:完整支持 spark-submit、spark-sql、beeline、JDBC 等经典方式,也集成 Kyuubi(含 HA)、Livy 等交互式查询服务;
- 工具链集成:无缝对接 Jupyter、Zeppelin、Superset、DBT 等主流开发分析工具;
- 调度系统:深度适配 Airflow、DolphinScheduler,并在阿里云生态内与DataWorks 原生集成——作为 DataWorks“一等公民”,支持 SQL 节点、Notebook、工作流编排、统一权限与数据血缘等;
- 安全与元数据:支持 Kerberos、LDAP、Ranger;
- 湖格式:湖格式覆盖 Paimon/Delta/Hudi/Iceberg;
- 外部数据源:连接 StarRocks、Doris、Hologres、HBase、Elasticsearch、MongoDB、MaxCompute、MySQL、Postgres 等数十种系统。
这种广泛的兼容性极大降低了用户迁移和集成成本,真正实现“开箱即用”。
TPC-DS 100T 背后的四大核心技术
官方 TPC-DS 100T 测试包含数据生成、导入、Power Test(单并发 99 查询)、Throughput Test(4 并发 396 查询)、Maintenance Test(Upsert 操作)等环节,最终通过 QphDS 分数衡量综合性能。
阿里云的突破源于以下四大技术创新:
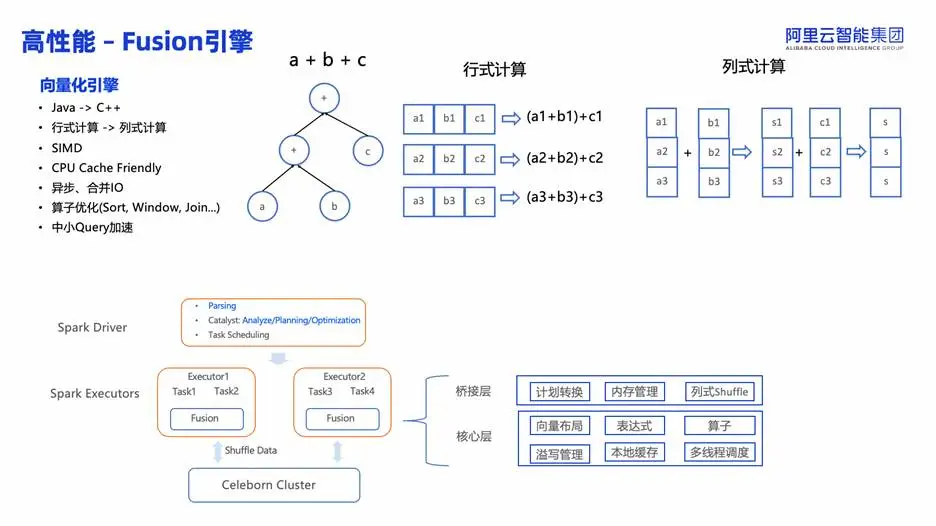
1. Fusion 向量化执行引擎
自 2019 年起研发,Fusion 将 Spark 从行式计算升级为 列式向量化执行:
- 利用 SIMD 指令并行处理多列数据;
- 连续内存布局显著提升 CPU Cache 命中率;
- 异步 IO 与 IO 合并优化读取效率;
- 关键算子(Sort/Window/Join)优化,性能提升达 300%。
在 TPC-DS 场景中,Fusion 还引入 Subplan Reuse、Broadcast Join Reuse、Semi Join 哈希表去重等优化,大幅减少重复计算与内存占用。
2. 与 Paimon 深度协同
Fusion 与阿里自研湖表格式 Paimon 深度整合:
- 向量化读写使读性能提升 70%,写性能提升 30%;
- Variant 类型相比原始 JSON 提升 178%;
- Shredding 技术进一步加速 JSON 解析,性能再提升 364%。
3. Celeborn Remote Shuffle Service
作为 Apache 顶级项目,Celeborn 采用 推送式 Shuffle 架构:
- 在大规模作业中提供更高吞吐与更低延迟;
- 支持副本容错与 Stage 重算,保障作业稳定性;
- 大规模生产验证,成为业界事实标准。
4. DLF 3.0 与优化器增强
基于 Paimon 的 DLF 3.0 提供高性能 ACID 能力,满足 TPC-DS Maintenance 测试要求;同时优化器在 Join 顺序选择、代价模型等方面持续迭代,提升复杂查询效率。
最终成果:在仅使用一半内存的情况下,QphDS 性能翻倍,性价比提升 5 倍,所有结果均通过 TPC 官方严格审计。
AI 时代的新功能:让 Spark 成为 AI 基础设施
面对 AI 浪潮,EMR Serverless Spark 推出多项创新功能,使其在人工智能数据处理场景中发挥更大价值:
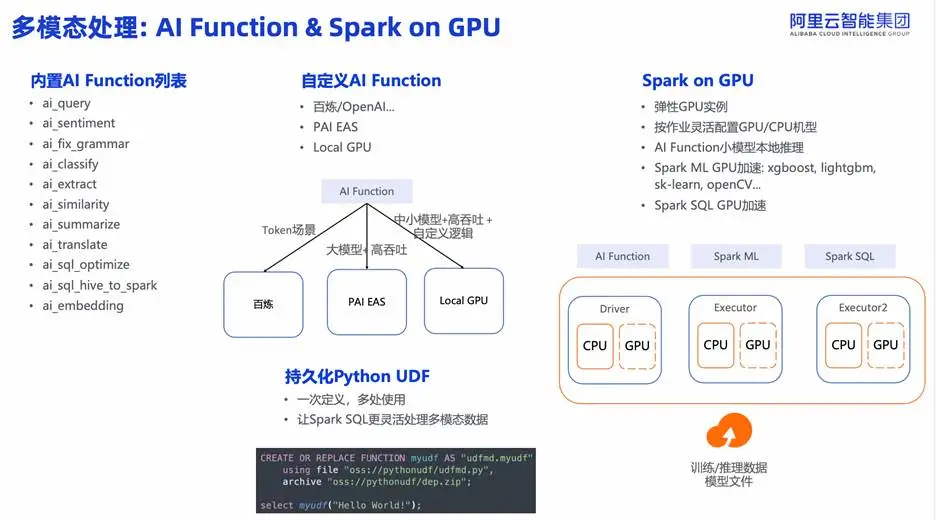
- AI Function:内置 ai_query、ai_sentiment、ai_classify、ai_embedding等函数,用户可在 SQL 中直接调用大模型,如同使用内置 UDF。支持接入百炼、OpenAI、PAI EAS 或本地 GPU 模型。
- Spark on GPU:提供弹性 GPU 实例,按需配置 CPU/GPU 混合机型,避免固定集群成本。支持:
AI Function 本地 GPU 推理;
Spark ML(XGBoost/LightGBM)GPU 加速;
Spark SQL 向量化 GPU 计算。
- 即将上线功能:
Spark + Ray 双引擎融合:满足 Python 分布式与异构计算需求;
DuckDB 集成:针对中小数据分析,在 Notebook 中已内置,未来支持直连 DLF 3.0;
文本去重加速:在 FineWeb-edu(8TB、30亿文档)上,800 核仅需 72 分钟,提速 5 倍。
携手客户共同成长
EMR Serverless Spark 已在多家金融、互联网、智能硬件及零售企业的生产环境中稳定运行,广泛应用于数据仓库加速、实时风控、向量检索、机器学习等核心场景。
同时,Celeborn 社区也在多个头部互联网平台和科技企业中落地,支撑高并发、大规模的数据计算需求。这种云原生架构提供的极致弹性和稳定性,是企业应对业务波动的关键。
阿里云 EMR Serverless Spark 的 TPC-DS 登顶,不仅体现了优异性能,更体现了架构理念、工程能力和生态战略。在 Data + AI 融合的新时代,它正成为企业构建下一代智能数据基础设施的核心引擎。欢迎来到 云栈社区 交流更多大数据与云原生技术实践。
新用户现可免费领取1000 CU·H 试用额度,立即体验全球领先的 Serverless Spark 服务:
👉https://x.sm.cn/EpHNTcw
 发表于 2026-2-12 17:01:48
|
查看: 246|
回复: 0
发表于 2026-2-12 17:01:48
|
查看: 246|
回复: 0
