引言
“以前跑个报表要泡杯咖啡等结果,现在刚点‘查询’,数据就出来了。”
—— 某业务分析师在上线 StarRocks 后的真实反馈。
一、问题背景:实时数仓为何陷入性能泥潭?
在数字化转型成为共识的当下,数据响应的“实时性”已成为业务竞争力的关键。然而,我们团队在半年前构建的实时数仓系统,却面临着严重的性能瓶颈:
- 核心看板查询动辄 20~30 秒,用户频繁刷新导致系统雪崩;
- Kafka + Flink + Hive + ClickHouse 的混合架构,不仅技术栈复杂,维护成本也极高;
- 数据延迟高达 5~10 分钟,“实时”名存实亡;
- 资源消耗巨大:为支撑高峰查询,不得不堆叠大量计算节点,成本持续飙升;
- 开发体验差:不同引擎SQL语法各异,兼容性问题频发,调试困难。
一个令人困惑的问题是:我们已经使用了以高性能著称的 ClickHouse,为何性能依然不尽如人意?
根本原因剖析:
- 多表 JOIN 性能瓶颈:ClickHouse 对宽表查询友好,但在面对星型或雪花等多维模型下的多表关联时,其性能会急剧下降。
- 缺乏真正的 MPP 架构:ClickHouse 虽然是列式存储,但并非完整的 MPP 架构,无法高效并行处理复杂查询计划。
- 实时写入与查询冲突:高频数据写入导致后台 Merge 操作压力巨大,严重拖慢了前台的查询响应速度。
- 运维复杂度高:强依赖 ZooKeeper 进行元数据管理,副本同步异常、分区管理混乱等问题频发,故障排查如同盲人摸象。
我们最终认识到:问题的根源并非工具本身不够强大,而是整体架构设计存在缺陷。
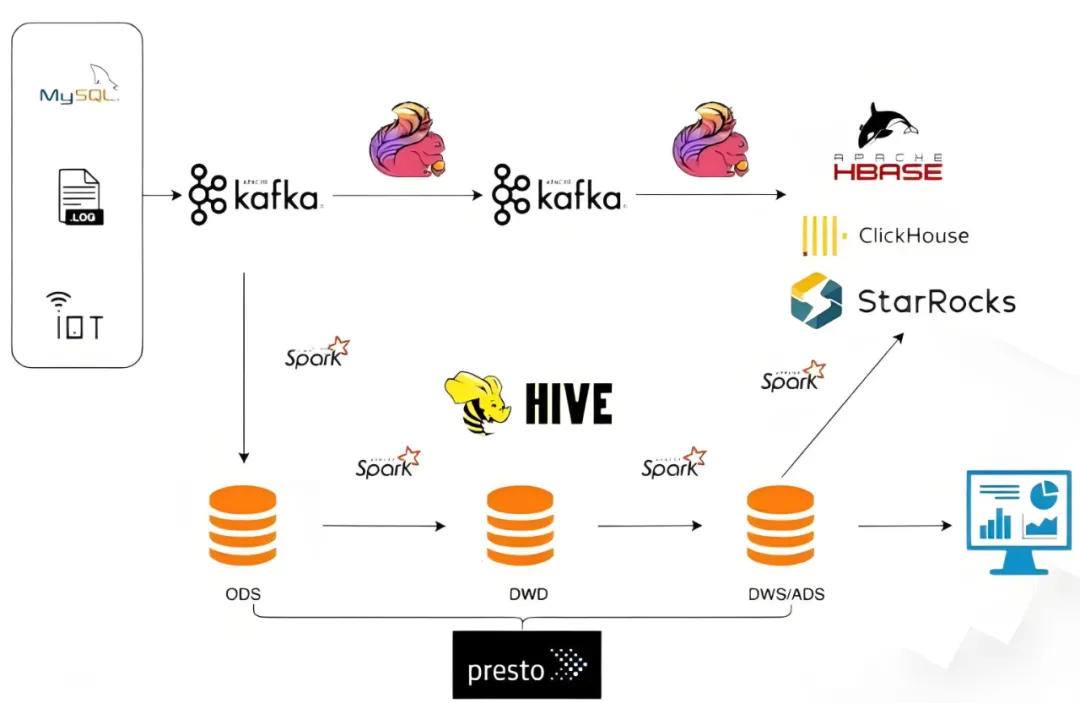
二、技术选型:为何最终选择 StarRocks?
经过深入的技术调研与概念验证测试,我们将目光锁定在 StarRocks(原 DorisDB) 上。这一选择并非盲目跟风,而是基于严谨的功能对比与场景匹配分析:
| 能力维度 |
ClickHouse |
StarRocks |
| MPP 架构 |
单机列存为主 |
全向量化 MPP |
| 多表 JOIN |
性能较差 |
CBO 优化器 + Runtime Filter |
| 实时写入 |
需批量导入 |
支持主键模型与 Upsert |
| SQL 兼容 |
非标准 SQL 方言 |
高度兼容 MySQL 协议 |
| 运维复杂度 |
高,依赖 ZooKeeper |
低,无外部依赖 |
更为关键的是,StarRocks 原生支持湖仓一体、智能物化视图、物化索引等特性,这恰好契合了我们构建下一代高并发、低延迟实时数仓的核心需求,能够有效整合和简化我们复杂的大数据技术栈。
三、重构实战:从混沌到丝滑的四步走策略
第一步:场景聚焦——优先攻克最痛点
我们没有采取“一刀切”的全盘推翻策略,而是聚焦于 核心业务看板,例如 DAU(日活跃用户)、GMV(成交总额)、订单转化漏斗等场景。这些场景具备以下共同特征:
- 高频查询(QPS > 100)
- 涉及多表关联(如用户维表、事件事实表、商品维表)
- 对实时性要求极高(要求数据延迟小于 1 分钟)
第二步:数据模型重构——告别冗余宽表,拥抱范式化模型
过去为了适配 ClickHouse 的特性,我们将所有维度字段冗余进一张超宽事实表(字段数超过 200 个),这导致了数据写入膨胀、维度更新困难、存储冗余等一系列问题。
我们的 StarRocks 优化方案如下:
- 采用星型模型:将数据拆分为一张事实表和多张维度表,回归范式化设计。
- 利用 Colocate Join:通过创建 Colocate 表组,确保需要频繁关联的表数据分布在同一数据分片上,从而在 JOIN 时避免网络 Shuffle,大幅提升关联性能。
- 建立前缀索引与 BloomFilter:对高频过滤字段(如日期
dt、应用ID app_id)建立合适的索引,加速数据定位。
-- 示例:Colocate 表组定义
CREATE TABLE user_events (
event_id BIGINT,
user_id INT,
app_id INT,
event_time DATETIME,
...
) ENGINE=OLAP
PRIMARY KEY(event_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 32
PROPERTIES("replication_num" = "3", "colocate_with" = "user_group");
第三步:实时链路改造——拥抱 Flink + StarRocks 主键模型
旧有链路:Kafka -> Flink -> 写入 Kafka -> ClickHouse(每5分钟批量导入)
优化后链路:Kafka -> Flink SQL -> StarRocks(Primary Key 模型)
- 利用 StarRocks 2.0+ 版本强大的 Primary Key 模型,直接支持 Upsert 和 Delete 操作,完美应对业务数据变更。
- 通过 Flink CDC 直接对接业务数据库(如 MySQL),实现端到端的 Exactly-Once 语义保障。
- 改造后,数据端到端的延迟从 5分钟降至 10秒以内,真正实现了实时可见。
// Flink 写入 StarRocks 示例(JDBC 或 Stream Load)
stream.addSink(new StarRocksSink(table, properties));
第四步:查询优化——让亚秒级响应成为常态
- 物化视图自动匹配:针对常用的聚合查询模式(如
SUM(gmv) GROUP BY dt, channel)创建物化视图。StarRocks 的优化器能自动将查询路由至物化视图,避免重复计算。
- Runtime Filter 动态下推:在执行多表 Join 时,StarRocks 能够动态生成 BloomFilter 等过滤条件,并下推至事实表扫描层,提前过滤大量无关数据。
- 全链路向量化执行引擎:从存储层到计算层全面采用向量化处理,利用 SIMD 指令集大幅提升 CPU 利用率,实测性能提升可达 3 倍以上。
四、性能效果:数据是最有力的证明
| 指标 |
重构前(ClickHouse) |
重构后(StarRocks) |
提升倍数 |
| 平均查询延迟 |
28.6 秒 |
0.28 秒 |
102倍 |
| P99 查询延迟 |
42 秒 |
0.6 秒 |
70倍 |
| 数据端到端延迟 |
8 分钟 |
8 秒 |
60倍 |
| 集群节点数 |
12 节点 |
6 节点 |
资源减少50% |
| 开发 SQL 迁移成本 |
高(需重写约70%) |
低(主要修改DDL) |
成本降低90% |
注:上述测试环境为 6 台 32核 128GB 内存的服务器,数据总量为 10 亿行。
五、总结与思考:StarRocks 带来的不仅是性能提升
我们并非要全盘否定 ClickHouse,它在单表海量数据扫描、日志分析等场景下依然表现卓越。但是,当你的业务场景涉及多维分析、实时数据更新、复杂多表关联时,StarRocks 凭借其 MPP 架构、向量化执行引擎与智能优化器的组合优势,提供了一个更优的解决方案。
更重要的是,StarRocks 所体现的 “一体化”设计理念,让我们能够基于一个系统实现以下目标:
- 一套引擎同时服务实时数据分析与离线批处理场景。
- 一套高度兼容 MySQL 的 SQL 语法,同时满足数据工程师与业务分析师的需求。
- 一套集群稳定支撑即席查询与固定报表看板。
这次重构的成功,不仅是技术指标上的胜利,更是一次 数据架构思维的升级——让我们从过去依赖多种工具“拼凑”系统,转向构建一个统一、高效、易维护的湖仓一体数据体系。如果你也在经历类似的数仓性能与架构之痛,或许现在正是重新评估与选择正确技术方向的最佳时机。
 发表于 2026-1-20 03:26:24
|
查看: 205|
回复: 0
发表于 2026-1-20 03:26:24
|
查看: 205|
回复: 0
