概述
你是否曾被 Flink 应用开发的繁琐配置和复杂运维所困扰?Apache StreamPark 的出现,正是为了将流处理应用的门槛降至冰点。它致力于让开发者从框架细节中解放出来,更专注于业务逻辑的创新。
StreamPark 通过规范化的项目配置、函数式编程引导、最佳实践定义以及丰富的即用型连接器,将配置、开发、测试、部署、监控和运维的全流程标准化。它支持 Scala 和 Java 双语言接口,并构建了一个一站式的流处理作业开发管理平台,为作业从构思到上线的全生命周期提供坚实支撑。
环境预备与安装
1. 环境预备
本次实践环境已预先安装以下组件:
- JDK 11.0.30
- MySQL 5.7.25-1
- Flink 1.20.3
- Hadoop 3.4.22
2. 安装 StreamPark
首先,下载并解压安装包:
tar -zxvf apache-streampark_2.12-2.1.7-bin.tar.gz
mv apache-streampark_2.12-2.1.7-bin streampark
配置调整:进入 conf 目录,修改 config.yaml 文件。核心步骤是将默认的 H2 数据源切换为你正在使用的 MySQL 或其他数据库。

URL 配置参考如下(请根据实际情况调整):
jdbc:mysql://localhost:3306/streampark?useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=false&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=GMT%2B8
接着,修改本地工作空间路径:
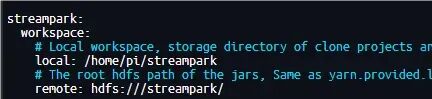
数据库初始化:
- 在你的 MySQL 中创建一个名为
streampark 的数据库。
- 依次执行
script/schema/mysql-schema.sql 和 script/data/mysql-data.sql 脚本以完成表结构和基础数据的初始化。
驱动放置:将你的 MySQL 驱动 Jar 包(例如 mysql-connector-j-8.0.33.jar)放入 streampark/lib 目录下。
启动服务:
bin/startup.sh
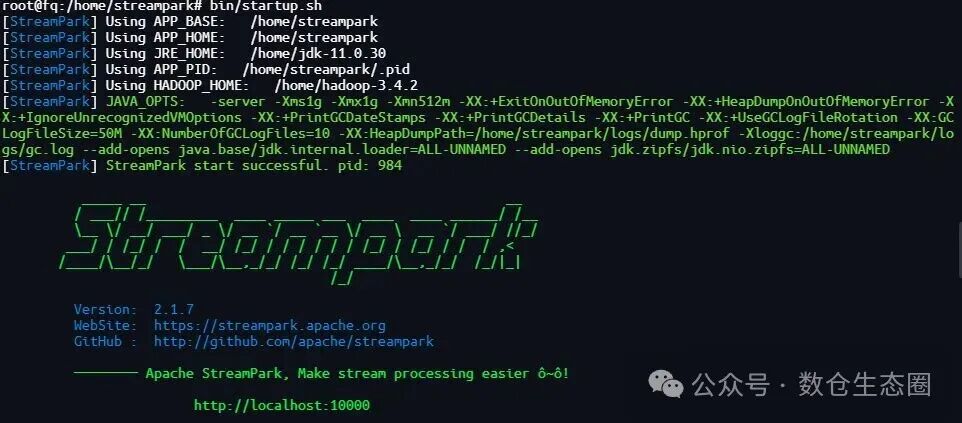
启动后,可通过 logs/streampark.out 文件查看运行日志。
访问管理平台
在浏览器中访问 http://your-server-ip:10000。
默认登录账号为 admin,密码为 streampark。
基础配置
成功登录后,需要进行两项关键的基础配置,以便 StreamPark 能够管理你的 Flink 环境。
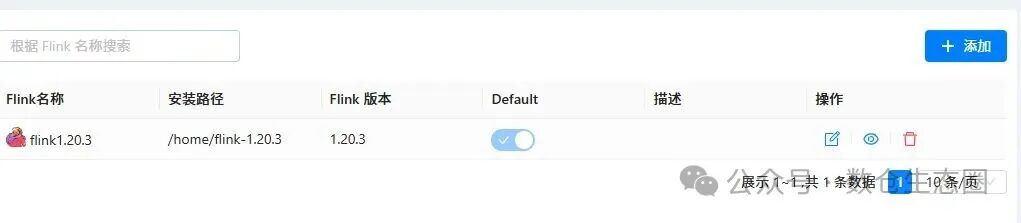
1. 设置 Flink 版本
在此处添加你已安装的 Flink 目录,StreamPark 会识别其版本。
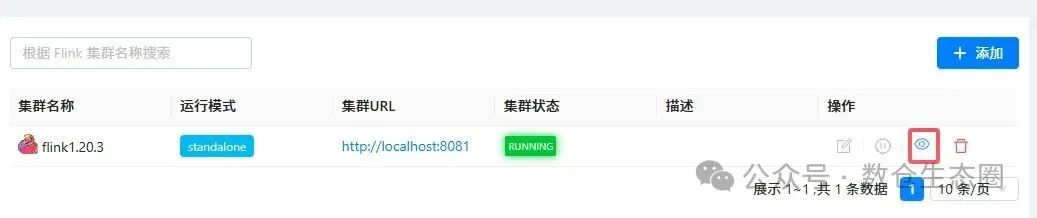
2. 设置 Flink 集群
添加一个 Flink 集群,运行模式选择 standalone,并填写其 Web UI 地址(例如 http://localhost:8081)。配置成功后,点击“眼睛”图标可直接跳转至原生的 Flink Web UI 界面。
创建并运行你的第一个 Flink SQL 作业
现在,让我们创建一个简单的 Flink SQL 作业来体验整个流程。
- 进入作业开发:在平台中找到作业开发或类似功能入口,点击“添加”按钮。
- 填写作业配置:
- 作业类型:选择
Flink SQL。
- 运行模式:选择
standalone。
- Flink 版本:选择你上一步配置好的版本。
- Flink 集群:选择你上一步配置好的集群。
- Flink SQL:在编辑框中填入你的 SQL 脚本。
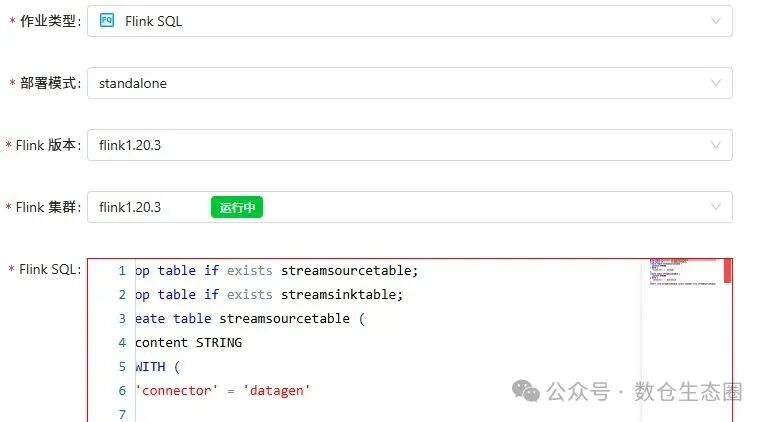
这里是一个简单的示例脚本,它创建了一个数据生成源表和一个黑阱接收表,并将数据从源表插入到接收表:
drop table if exists streamsourcetable;
drop table if exists streamsinktable;
create table streamsourcetable (
content STRING
) WITH (
‘connector’ = ‘datagen‘
);
create table streamsinktable (
content STRING
) WITH (
‘connector’ = ‘blackhole‘
);
insert into streamsinktable select content from streamsourcetable;
-
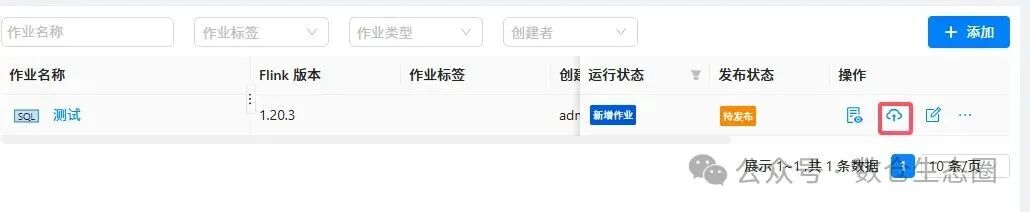
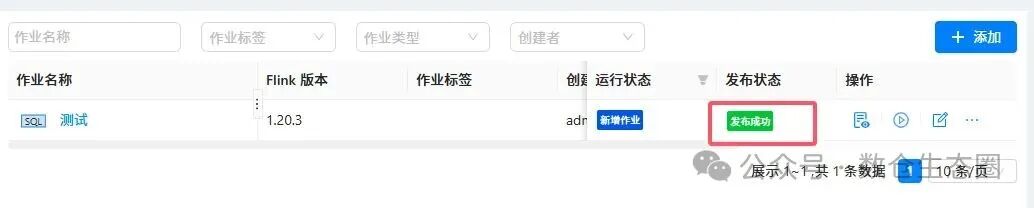
发布作业:配置完成后,点击“发布”按钮。系统会校验配置并将作业提交保存。
-
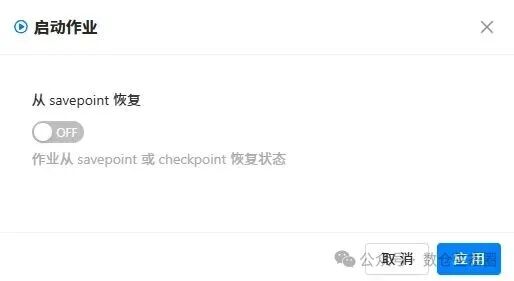
启动作业:发布成功后,在作业列表中找到该作业,点击“启动”按钮。首次启动时,会询问是否从 Savepoint 恢复,选择 OFF 即可。

-
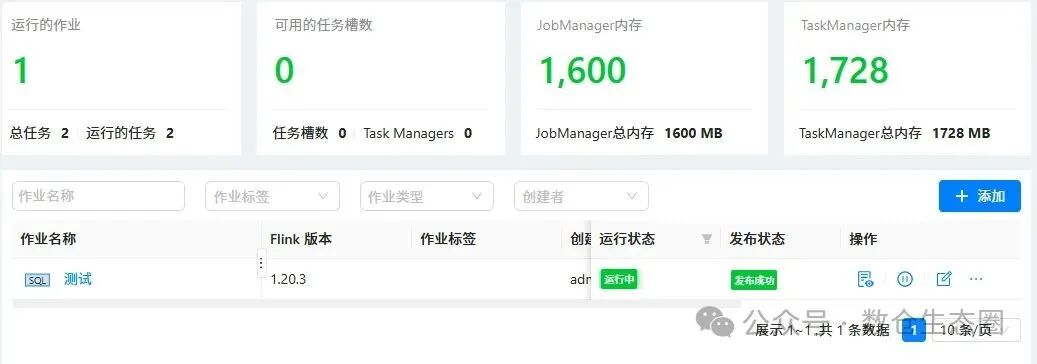
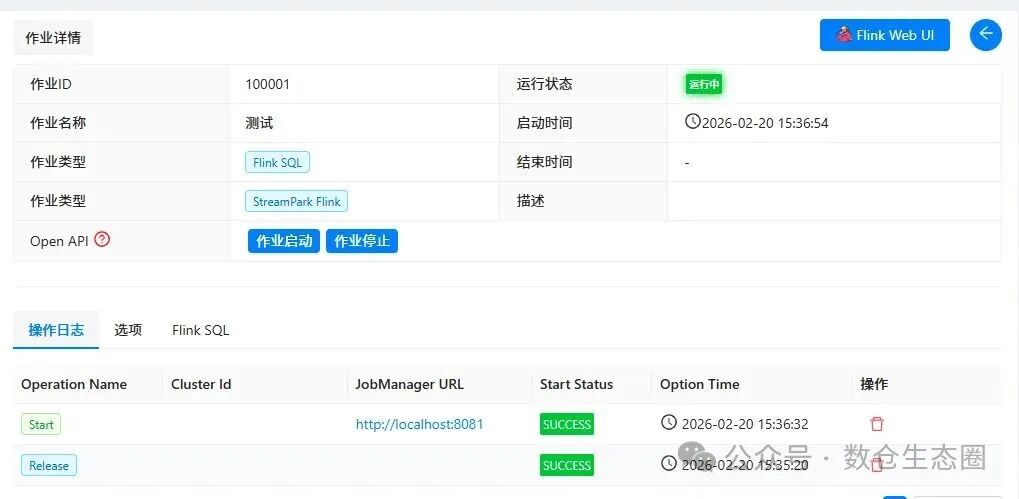
查看运行状态:作业启动后,状态会变为“运行中”。你可以在 StreamPark 的仪表盘和作业详情页中直观地看到任务槽、内存使用等关键指标。
作业下线与清理
当需要停止或移除作业时,StreamPark 也提供了便捷的操作。
-
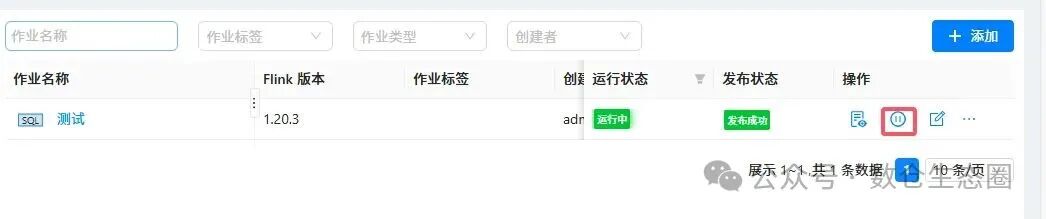
停止作业:在运行中的作业操作栏,点击“停止”按钮。你可以根据需求选择停止时是否触发 Savepoint,以便后续从断点恢复。
-
删除作业:作业停止后,方可执行删除操作,这将彻底清理平台内的作业记录。
总结:StreamPark 如何重塑流处理开发
通过以上实践,我们可以看到 Apache StreamPark 与 Apache Flink 的结合,远不止是工具的叠加。它将 Flink 强大的实时计算能力封装在一个高度可视化、标准化的操作平台之下。
核心价值在于,它统一并简化了从开发、测试到部署、监控、运维的全链路,极大降低了 大数据 流处理任务的管理复杂度。开发者无需再记忆繁琐的命令行参数,运维者也能在一个界面掌控所有作业的健康状态。
对于希望快速构建和稳定管理实时数据流水线的团队而言,StreamPark 提供了一个高效的“驾驶舱”。如果你也在探索如何让流处理变得更简单,不妨在 云栈社区 与更多同行交流实践经验,共同解决开发中遇到的挑战。
 发表于 2026-2-25 06:26:42
|
查看: 259|
回复: 0
发表于 2026-2-25 06:26:42
|
查看: 259|
回复: 0
