先说结论:经过一整天的捣鼓(其他啥事没干),Apache Flink on Kubernetes 终于被我跑起来了。
坦诚讲,这个过程对k8s的熟悉度要求不低。整个调通过程可谓煞费苦心,中间数次心态濒临崩溃。所以,如果你对 k8s 的熟悉程度跟我差不多,甚至还不如我的话,在决定尝试之前,最好想想清楚,它值不值得你付出这么多。
(PS:本文基于 k8s 集群已被成功部署完成之后的场景进行描述)
官网的踩坑起点
出师不利,一开始就被 Flink 官网的文档给误导了。我根据文档顺序,先找到的是“Kubernetes 设置”部分。

这部分内容描述的是以手动定义 Deployment 和 Service 的方式来部署 Flink session 集群。

对于新手来说,按照这个步骤操作大概率会失败,感觉像进了“黑店”。正确的入口,其实应该在“Native Kubernetes”这里。

这里的操作指引更为直接,主要是通过 Flink 自带的脚本与 Kubernetes 集群交互。

导航到这里,真正的挑战才刚刚开始。
网络插件的部署与配置
根据我目前与 Kubernetes 打交道的经验,网络插件是我们绕不开的一道“坎”。它负责集群节点间的网络通讯,一旦出问题,整个集群都可能瘫痪。
在部署 Flink 之前,集群各 Pod 运行正常。
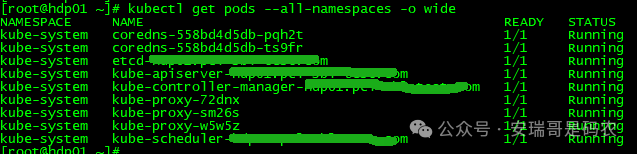
但当你启动一个 Flink Pod 之后,情况可能就不对了。
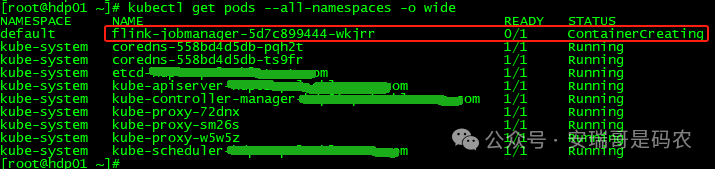
查看 Pod 事件,会发现类似这样的错误:
Warning FailedCreatePodSandBox 4m2s (x4 over 4m6s) kubelet (combined from similar events): Failed to create pod sandbox: rpc error: code = Unknown desc = failed to set up sandbox container "11fcf6f563466d75e69b390353cea4bba8b0918c587970843115841813bf1a65" network for pod "flink-jobmanager-6d6f7f8765-l4r7l": networkPlugin cni failed to set up pod "flink-jobmanager-6d6f7f8765-l4r7l_default" network: loadFlannelSubnetEnv failed: open /run/flannel/subnet.env: no such file or directory
这表明缺少一个叫 flannel 的网络插件。于是,我尝试安装它:
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
安装后,问题依旧,flannel 的 Pod 不断重启(CrashLoopBackOff)。

一番排查后,怀疑是配置文件中的 Pod IP 网段与集群初始化时设置的网段不一致。首先,需要确认集群的 Pod 网段:
# cat /etc/kubernetes/manifests/kube-controller-manager.yaml | grep cluster-cidr
- --cluster-cidr=10.244.0.0/16
然后,在下载的 kube-flannel.yml 文件中,找到 net-conf.json 部分,将其中的 Network 字段修改为与集群一致的网段(例如 10.244.0.0/16)。
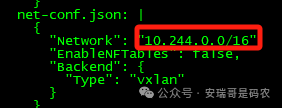
修改完毕后,重新应用配置文件,flannel 插件终于正常运行。

启动 Flink Session 集群的挑战
网络问题解决后,以为可以一帆风顺了?事情远没有这么简单。如果完全照搬官网的命令,成功几率渺茫。这其中主要遇到两个大坑。
镜像版本与拉取问题
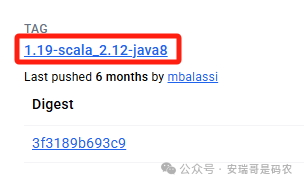
我使用的 Flink 版本是 1.19,因此希望 Session 集群也使用对应的镜像。但官网的启动命令默认可能拉取 latest 标签,这并非明智之选。官网确实有关于镜像别名的说明,但实际操作中并不直观。
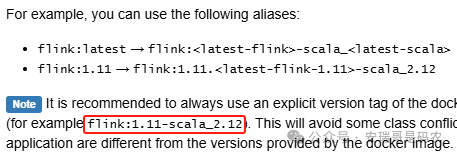
正确的做法是去 Docker Hub 上找到明确且匹配的镜像标签。例如,我找到的是 apache/flink:1.19-scala_2.12-java8。
然而,由于网络原因,直接从官方仓库拉取镜像可能非常缓慢甚至失败。我的解决方案是:使用一台境外云服务器拉取镜像,然后再导入到本地 k8s 集群的所有节点上。
Flink Web UI 的访问问题
指定了正确的镜像后,启动 Session 集群:
bin/kubernetes-session.sh \
-Dkubernetes.cluster-id=my-first-flink-cluster \
-Dkubernetes.container.image=apache/flink:1.19-scala_2.12-java8
启动成功后会输出一个 Web UI 地址,例如 http://192.168.1.173:30793。但直接访问这个地址(IP 是 Master 节点)可能会失败,因为服务实际可能运行在某个 Worker 节点(如 192.168.1.175)上。
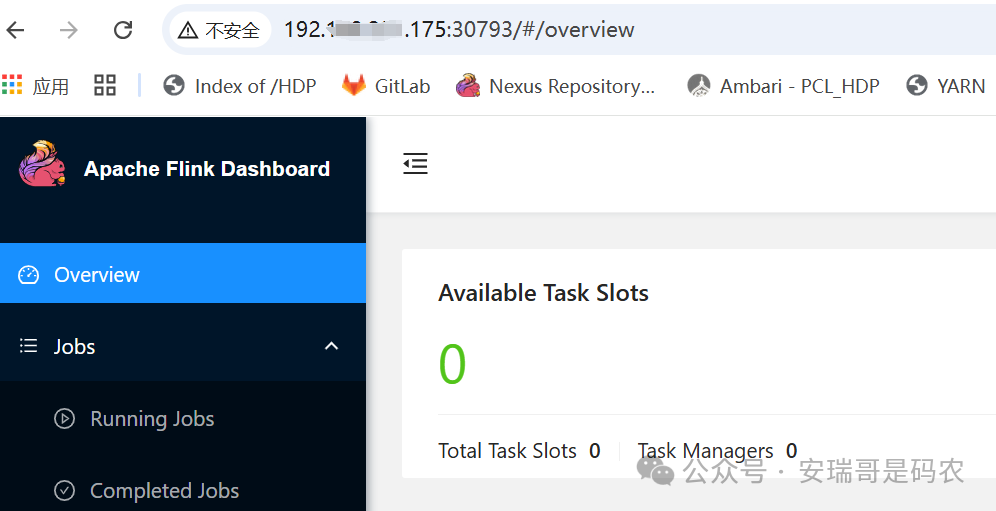
这引出了一个更严重的问题:后续提交任务时,Flink 客户端默认会尝试连接启动日志中给出的那个地址(Master 节点 IP),如果无法连通,任务提交就会卡住或失败。
我的调试过程一度陷入僵局,甚至因为一些激进的操作(如修改节点网络配置)导致整个 k8s 集群崩溃了两次,不得不推倒重来。这段经历虽然痛苦,但也让我对 Kubernetes 的底层机制有了更深刻的理解。
权限配置:最后的临门一脚
在集群“重生”后,我再次启动 Flink Session,并增加了一个关键参数,将服务端口类型设置为 NodePort,以便外部访问:
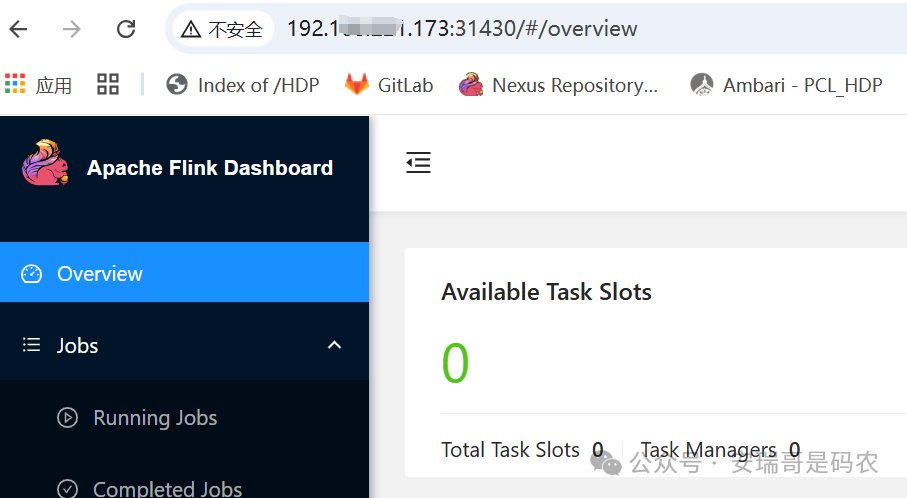
2026-01-16 14:29:10,803 INFO org.apache.flink.kubernetes.KubernetesClusterDescriptor [] - Create flink session cluster my-first-flink-cluster successfully, JobManager Web Interface: http://192.xxx.xxx.173:31430
这次,无论是 Master 节点 IP 还是 Worker 节点 IP,都能成功访问 Web UI 了。
但是,当我兴冲冲地提交一个示例任务时,任务状态却一直卡在 RUNNING,实际上没有真正的 TaskManager 被创建,几分钟后便超时失败。

问题出在哪里?又是一轮排查后,我将目光投向了 Kubernetes 的 RBAC 权限。可能是默认的 serviceaccount 权限不足,无法在集群中创建 TaskManager 的 Pod。
于是,我进行了以下权限配置操作:
# 创建独立的namespace
kubectl create ns flink
# 创建serviceaccount
kubectl create serviceaccount flink-account -n flink
# 为serviceaccount绑定clusterrole
kubectl create clusterrolebinding flink-role-binding-flink --clusterrole=edit --serviceaccount=flink:flink-account
现在,完整的、能够成功运行的 Flink Session 启动命令如下:
bin/kubernetes-session.sh \
-Dkubernetes.cluster-id=my-first-flink-cluster \
-Dkubernetes.container.image=apache/flink:1.19-scala_2.12-java8 \
-Dkubernetes.namespace=flink \
-Dkubernetes.jobmanager.service-account=flink-account \
-Dkubernetes.rest-service.exposed.type=NodePort
使用此命令启动集群后,再次提交任务。这一次,一切都顺畅了:
- TaskManager 的 Pod 被成功创建并运行。

- 任务在 Web UI 中清晰可见,并从
RUNNING 状态最终变为 FINISHED。

至此,我的 Flink on Kubernetes 运行环境才算是真正调试完成。
总结与思考
回顾整个过程,上面记录的只是所遇困难的冰山一角。我想说的是,在 Kubernetes 上运行 Flink 在技术上是完全可行的,但其中的复杂性和可能遇到的“坑”需要你有充分的心理和技术准备。
你需要面对网络插件配置、镜像拉取、服务暴露、权限控制等一系列在传统部署中较少触及的 运维 层面问题。任何一个环节出错,都可能导致整个流程失败,且排查难度较大。
在我看来,Flink on k8s 更适合两类人:
- 对 Kubernetes 有较深理解,能驾驭其各种复杂问题的高手。
- 拥有极强耐心和折腾精神,不惧推倒重来的探索者。
你属于哪一种呢?如果你也在探索云原生技术栈,欢迎来 云栈社区 分享你的故事或寻找解决方案。
 发表于 2026-1-17 00:45:30
|
查看: 180|
回复: 0
发表于 2026-1-17 00:45:30
|
查看: 180|
回复: 0
