Apache Flink介绍
Apache Flink是什么
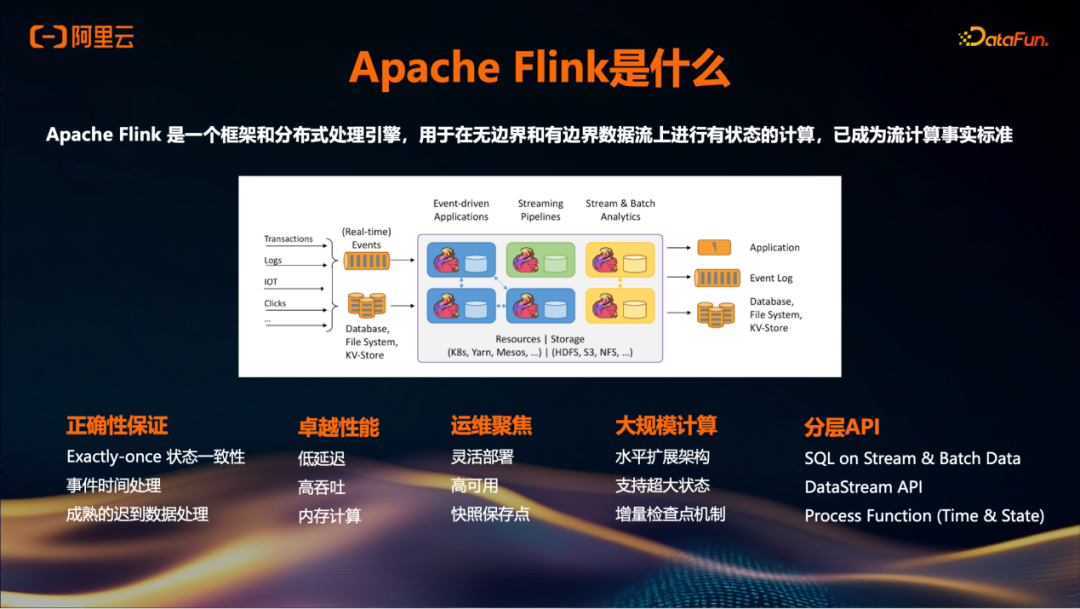
Apache Flink是一个流计算框架及分布式引擎。流计算是指将数据产生视为一条持续流动的数据流,数据源不断生成数据,通过流计算方式实现数据的持续消费、处理和分析。传统批处理模式则是在数据流中设定界限,将数据分成批次并在特定时间间隔(如T+1或T+1h)进行处理,这种方式存在延迟问题。
Flink在数据持续生成时,能够实现实时消费、处理和分析。此外,Flink支持流批一体处理,允许在同一个平台上执行流处理和批处理任务。目前,Flink社区拥有大约25K星标,在实时计算领域已成为一种事实标准。
在流处理领域存在诸多挑战,例如正确性保证。Flink提供Exactly-once语义以避免脏数据的生成,并支持基于事件时间的处理机制,能够有效处理迟到数据,既等待迟到数据同时推进数据流处理进度。Flink还提供了分层API,包括适合数据分析师使用的Flink SQL、适用于Python或Java工程师的Table API和DataStream API,以及更底层的Process Function供需要深入开发的用户使用。
Flink部署方案具备端到端低延迟和高吞吐量特性,并支持云环境下的灵活扩展与部署,以及跨可用区的高可用机制。
阿里云实时计算Flink版

在社区版的基础上,云上产品进一步提供了完整的托管平台以及企业级引擎增强。例如,近期逐步对外推出的Flash引擎是一种基于C++实现的原生向量化引擎,其性能表现显著优于开源版本:1个计算单元(CU)的Flash引擎约等效于4个CU的开源Flink引擎。此外,针对非向量化的场景,企业版引擎VVR也进行了优化,1个CU的VVR性能约等效于2个CU的开源Flink引擎。
除计算性能提升外,云上版本还在存储引擎方面进行了相关优化,并在引擎层面对算子实现了细粒度的增强。在平台托管层面,该方案有效解决基于开源自建所面临的运维挑战,具体包括服务资源调度、细粒度权限控制、Open API集成以及智能化的运维诊断能力。
为什么Agent时代需要实时流计算
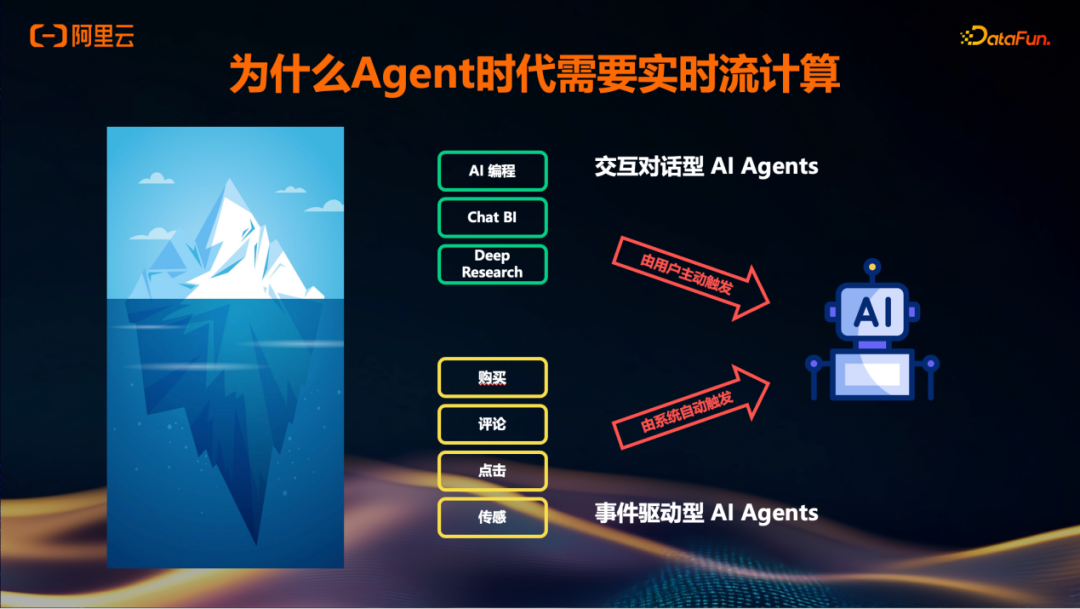
回到本次主题,即为何在Agent的语境下引入Flink。当前可以看到,许多Agent是基于交互对话式的模式,例如前两年较火的Chat BI、AI Coding、Deep Research,以及进一步如Manus将纯口述的模式转变为让Agent去执行具体的Action。在这些场景中,用户的交互会引发下层的事件。
类似于早期在大数据时代之前存在源源不断的机器自动生成的数据,在Agent场景的冰山之下,也存在大量基于事件触发的行为。除了上层用户交互所引起的下层事件外,autodriving及其他高度自动化的场景中,也会持续产生非用户触发的自动化事件。整体来看,在Agent的场景下,冰山之下有大量行为是以事件驱动的方式进行的。
Flink此前已提到是一个流处理框架,其特点正是对事件进行处理。因此,在Agent时代,尤其是在冰山之下事件驱动变得越来越重要的情况下,流计算能够帮助解决其中的一些问题。
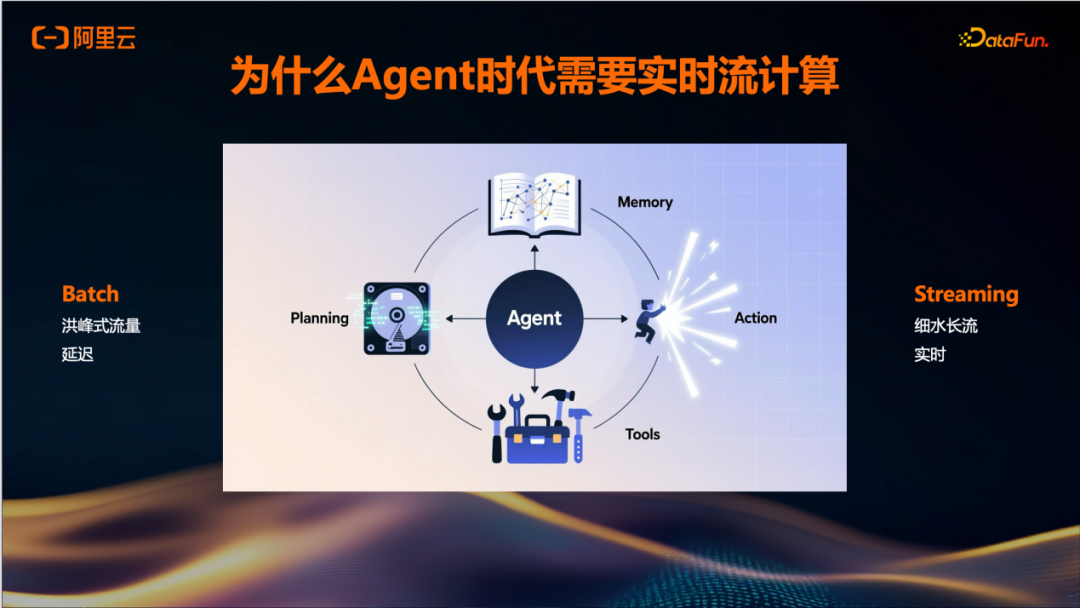
当前许多Agent采用的是批处理式的调用方式。这种方式在调用下游或上游工具时,若并发量较高,容易产生洪峰流量,进而引发模型服务的限流、频控等问题,导致无法达到预期效果。除了洪峰流量带来的与上下游服务之间的协调问题外,还存在端到端延迟较高的情况。
采用Streaming模式的一个优势在于其流量呈现细水长流的特征。相比纯洪峰式的调用,在业务高峰期(尤其是工作日的上下午时段),通过细水长流式的流量可以缓解洪峰调用所引发的问题。同时,由于采用Streaming模式,端到端的实时性也能够得到提升。
Apache Flink Agents介绍
如何助力Agent

回到如何助力当前Agent时代的问题,首先介绍一个已开源的项目——Apache Flink Agents,这是一个用于构建事件驱动型智能体的开源框架。但其核心目的是将开发基于Streaming模式的Agent时常见的共性工作和底层逻辑进行封装,形成一个可供开发者直接使用的框架。
该框架的作用是支持构建事件驱动型的智能体,并可与Flink现有的Streaming Pipeline结合使用。例如,当源端有新数据产生(如MySQL库中的Binlog变更)或有新的消息事件通过Kafka传出时,即可基于这些事件触发处理逻辑。
具体开发流程分为三步:首先,使用Python通过 pip install flink-agents 安装该框架;其次,基于Flink的Table API或DataStream API进行开发;最后,将开发完成的作业提交至Flink集群运行。
Demo 演示
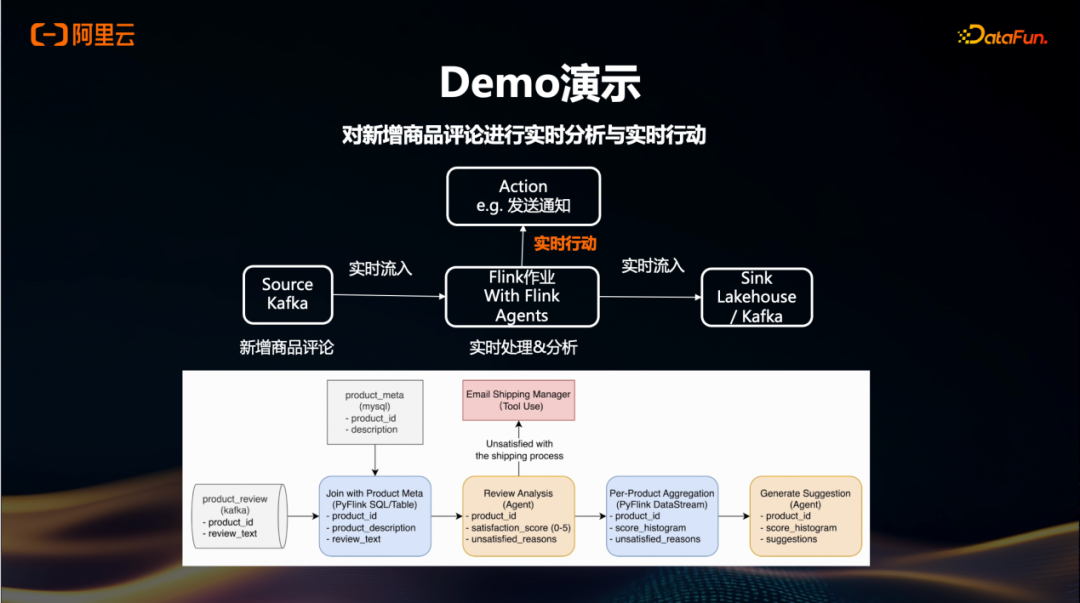
我们有一个演示场景,用于展示如何处理客户声音(VOC)中的新增商品评论。当前的处理方式多为批处理模式,更新频率通常为每小时、半小时或十几分钟一次,这不足以实现实时响应用户新增评论及其关联影响的需求。
在采用Agent模式后,当有新增商品或新增商品评论时,会向Kafka发送一条消息,这条消息随后流入Flink的一个作业中。通过引入Agent,这个Flink作业能够自动调用各种工具,例如发送通知和预警,甚至执行更深层次的动作。原始数据在Streaming处理过程中,会被导向Lakehouse或其它引擎,并继续流向下游系统。
具体案例中,新增的商品评论(包含Product ID及新的review)通过Table API的方式写入Flink作业。接下来,这些数据与商品的维表进行join操作,以获取更多关于商品的描述信息以及用户的评价内容。基于此,Agent可以用来计算满意度评分(如0到5分),对于不满意的评论,在没有Agent的情况下,可能需要很长时间才能识别并采取行动。而现在,一旦识别出不满意的评论,就可以立即调用相应的工具进行处理,比如如果是物流问题,则通知物流经理;如果是商品质量问题,则进一步通知相关部门。
此外,在完成基础的情感分析和问题分类之后,可以生成直方图并通过调用Agent来创建总结性的建议,提供给VOC客户作为整体反馈的一部分。这样不仅提高了处理效率,还增强了对实时事件的响应能力。
在演示中,首先在本地Python环境中运行应用。开发者可以方便地向Agent提供测试输入,并在本地执行整个流程,该过程完全在IDE中完成,无需依赖Flink。示例中提供了两条杂志的评论:第一条评论表示用户喜欢杂志中的故事;第二条评论指出收到的杂志已损坏。根据设定,第二条评论应触发向物流经理发送电子邮件的行为。运行结果显示,第一条评论获得较高的满意度评分,第二条评论则获得较低评分,并正确提取了问题原因,同时成功触发了邮件发送动作。检查邮件内容后确认行为符合预期。
随后,将该应用部署到Flink集群上运行,操作方式与其他PyFlink作业完全一致:使用 flink run 命令,指定Flink集群地址、作业入口文件及依赖项。同时启动另一个脚本用于消费并打印Kafka中的输出数据。实时结果随即显现,包含产品ID、满意度分数的直方图,以及针对每个产品的三条改进建议。切换至Flink Web UI界面可观察到,该Agent以多并发方式运行,并每隔数秒触发一次Checkpoint。
Flink Agents Architecture
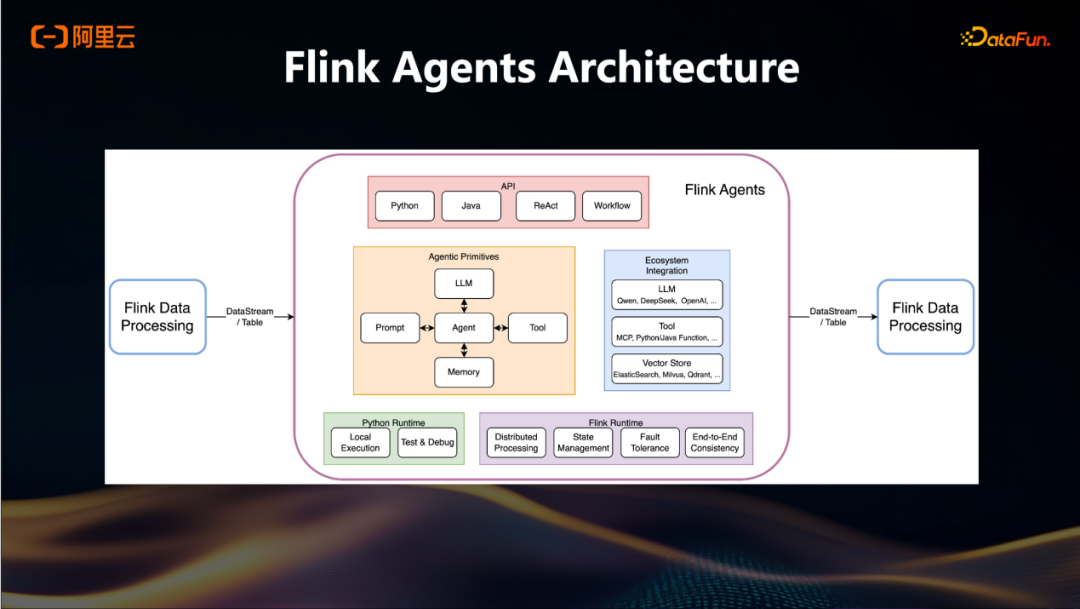
再进一步看Flink Agents架构,其整体输入和输出均基于Flink的Table API或DataStream API。在内部架构中,黄色区域包含多个核心模块:LLM相关的Chat模块、Tool调用模块、Prompt管理模块以及Memory模块。
在上层,由于Flink本身支持多种开发生态,Flink Agent提供了基于Python、Java的API,以支持不同语言背景的开发者进行开发。在Agent的运行模式方面,除了当前常见的Workflow模式外,还支持ReAct模式。当Agent完成调试并准备就绪后,开发者可以在Python本地环境中进行调试,随后将其提交至Flink集群运行。在整个数据处理过程中,一致性保障依赖于Flink自身的分布式处理能力、状态管理机制、容灾能力以及端到端的一致性保证。当Agent处理生成新数据后,仍通过DataStream或Table API的方式将结果写入下游系统。
Build a Workflow Agent
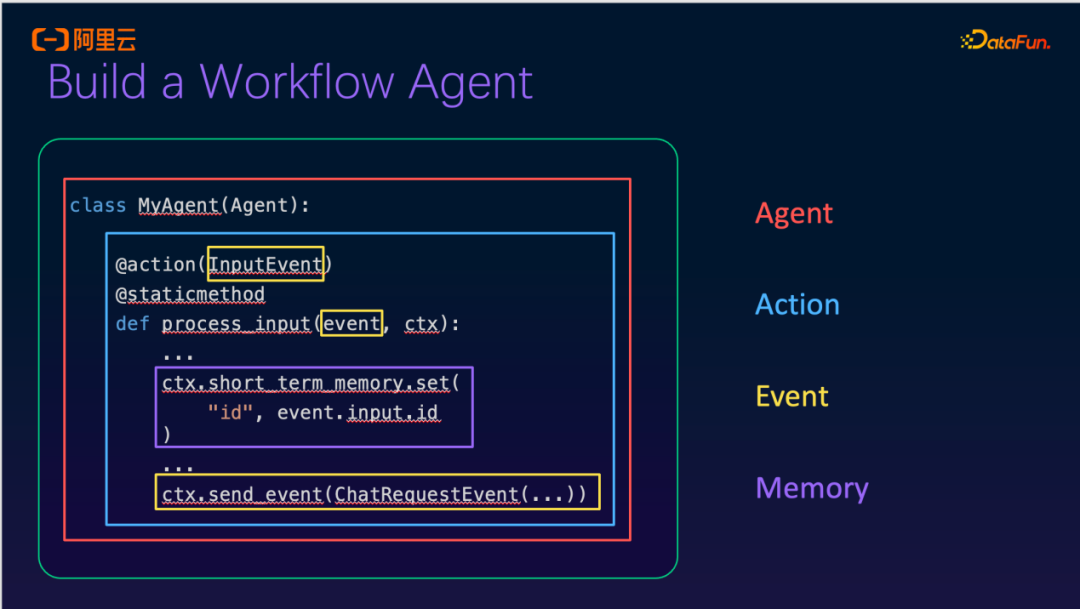
我们以构建一个简单的Workflow Agent为例,说明使用该Agent时通常需要完成的工作。首先,定义一个Agent类,例如命名为MyAgent。在该Agent类中,最重要的组成部分是两个模块:Action和Event。
其中,Event部分无需开发者像传统方式那样手动定义从Kafka到Flink的整条数据链路。相反,在接收到Table API或DataStream API输入后,框架内部会自动生成相应的Input Event。在Action执行完成后,可以生成一个新的Event,用于写入下游,从而触发下一个Agent或流程节点。
此外,当前框架已集成Memory模块,该模块基于Flink的状态管理(State Management)机制实现。在最新的0.2版本中,增加支持了感官、短期、长期记忆,长期记忆支持使用外部向量存储,如此可以支持更复杂的Agent行为和上下文保持能力。
Chat with a LLM

在Agent的主要框架中,除了Action和Event模块外,若需调用LLM,中间还包含一个“Chat with an LLM”模块。该模块的第一步是创建一个LLM Connection。这一过程跟以前创建数据库的长久连接有点相近。如果要使用多个模型,比如在model_setup中配置多个模型,或者使用多个不同的API Key去调用其他服务。
在后续使用时,只需指定前面创建的Connection,再指定模型、System Prompt、工具,以及一些模型相关的参数。

在结合前述Agent模块的Action时,可以将LLM嵌入其中。例如,在之前定义的一个Action为process_input,嵌入ChatResponseEvent后,所使用的model即为前面定义的“Chat with a LLM”模块,其返回结果就是一个ChatResponseEvent。该输出Event可作为下一个节点的输入Event,用于后续处理。
在模型支持方面,除了远程模型外,也支持本地部署的模型,例如Ollama这类本地模型的加载与管理注册。同时,还支持OpenAI兼容的模型、Anthropic以及阿里自研的通义系列模型。
Prompts
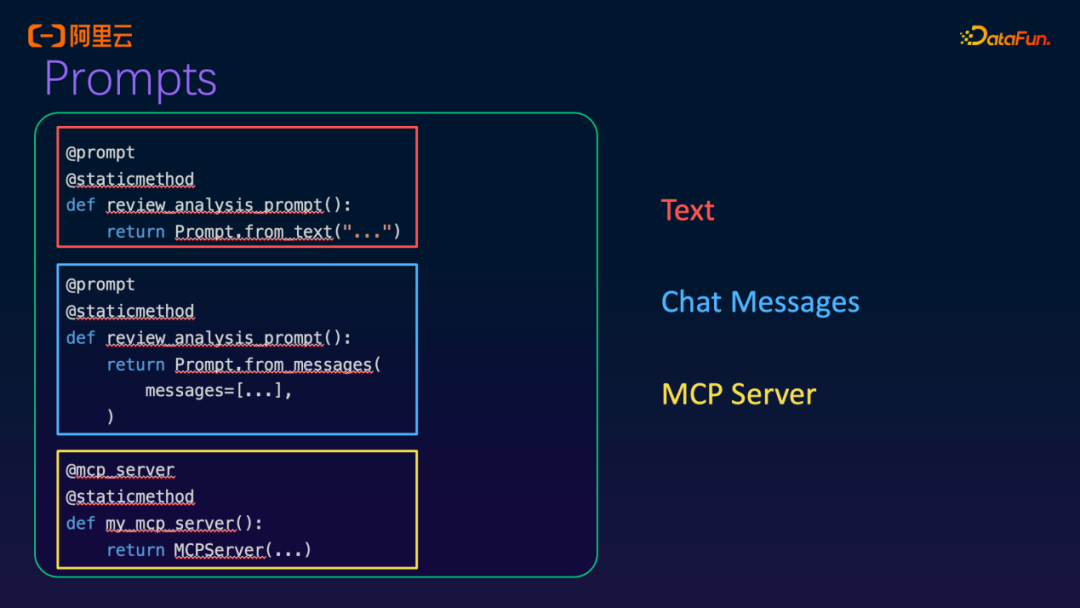
然后是我们的Prompts模块。目前定义Prompt的方式包括Text模式,以及通过Chat消息体(message)形式输入的模式。此外,也可以调用MCP的方式。

在Tools调用方面,有一种比较传统的方式是Function Call。具体而言,原先定义的一些Python函数或Java函数可以直接作为Tools进行注册和调用。例如,前面提到的发送邮件等操作,如果已有对应的函数实现,就可以直接在此处作为工具使用。对于更复杂的场景,进一步调用MCP也是支持的。
Flink Integration

整体上,完成一个Agent模块的搭建后,在整个Flink的Streaming Pipeline中,它可以被视为一个比Join或Order等操作更复杂的Operator。当嵌入到Flink中时,其输入来自DataStream中的相关数据,输出则是Agent处理完成后生成的结果,并可将该结果写入下一个Table API进行输出,从而与Flink自身的Streaming Data Pipeline实现集成。
典型场景1:实时直播分析
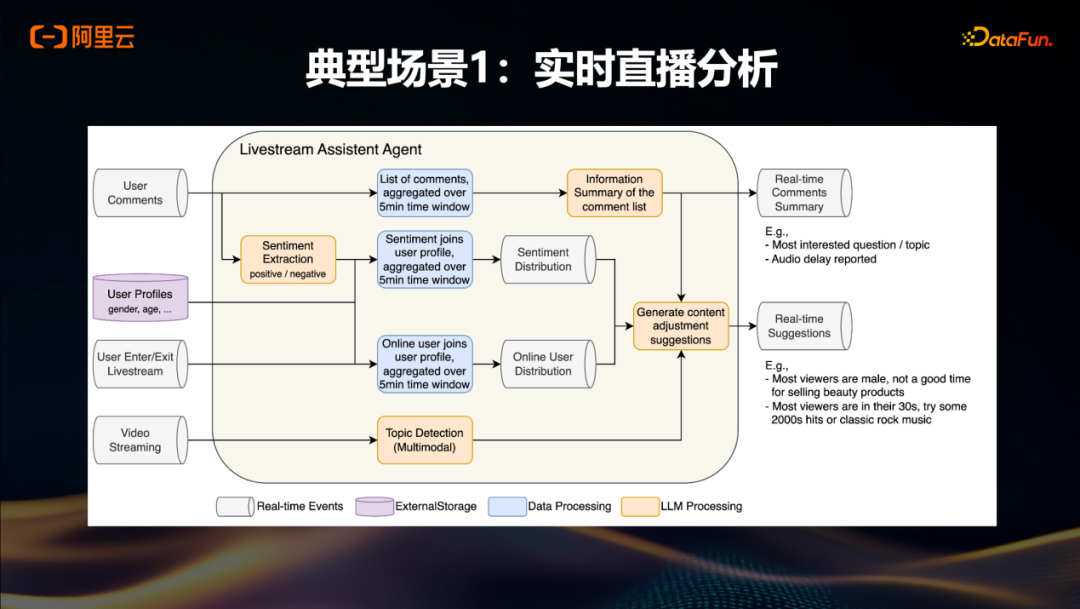
在介绍完前面的简单Demo以及Flink Agent本身的架构和主要模块之后,我们再来看一个面向直播场景的应用案例。直播领域常面临“好的主播不常有”的问题,即大量主播的能力有限,若仅依赖主播个人能力,直播效果会大打折扣。如果数据系统能够向业务侧提供实时输入,就有机会端到端地提升整体直播效果,从而更好地助力业务价值。
以该场景为例,在直播过程中,用户评论数据(如弹幕)是实时产生的。结合用户画像(user profile)数据,可以按一分钟或五分钟的粒度进行情感分析和评论分类。进一步融合用户进出直播间等多维度数据,进行综合分析,最终生成整体的直播建议,并实时反馈给前端主播,使其能根据当前用户反馈及时采取相应行动。
在没有这种模式之前,可能仅能基于弹幕调用某个函数做简单处理,但难以将此类处理与Lakehouse集成,也无法实现真正的实时闭环。而借助Flink Agent的流式处理能力,上述端到端的实时分析与反馈成为可能。
典型场景2:智能运维
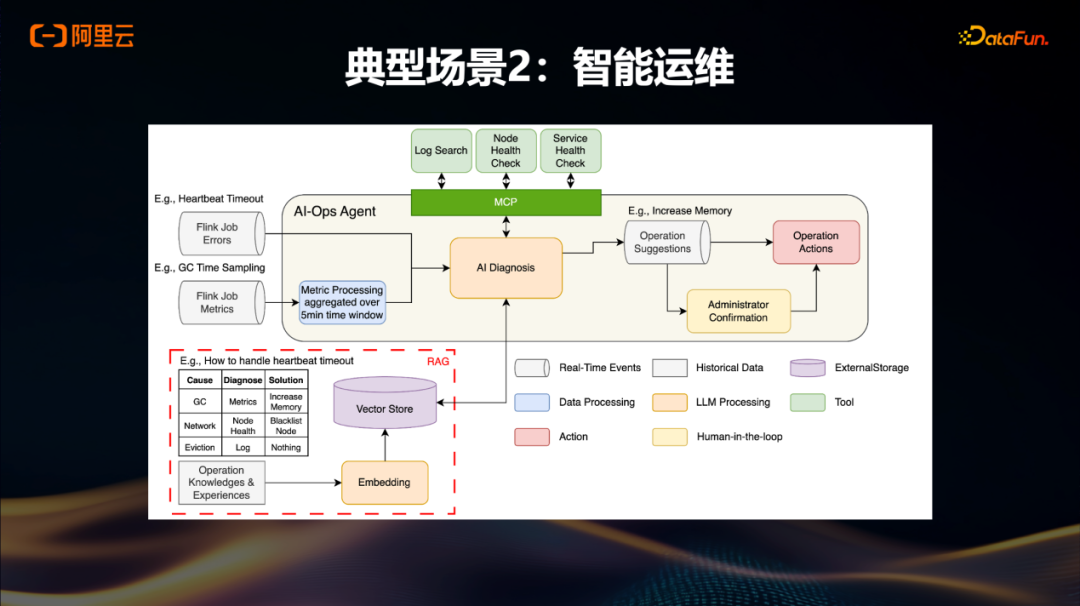
还有一个场景是智能运维,运维本身是一个长期存在的难题,即使在云上,云厂商也需要投入大量精力处理。此前,线上已经提供了Flink运维Adviser助手,但该助手通常仅提供运维建议,具体的执行操作仍需用户手动完成。
最近,我们正在基于Flink Agent框架开发新的Agent模式,将作业的异常信息与外部系统结合,例如调用节点健康检查接口,并关联原先存储在库中的数据,生成建议。在此基础上,用户确认后可实时执行相应Action。随着不断推进和验证这些Action的有效性,在部分场景下,甚至可以省去管理员的人工确认环节,实现自动化运维闭环。
Flink Agents和其他Agent开发框架的区别

在开发Flink Agent项目时,我们注意到现有的框架如langraph, pathway等也在做类似的事情。这些框架已经培养了用户的使用习惯,因此我们在开发Flink Agent时,尽量遵循这些已有的框架给用户带来的习惯和期望。
Flink Agent与其他Agent框架的主要区别在于它依赖于Flink本身的特性。例如,Flink提供的低延迟实时处理能力,使其能够无缝衔接到现有的数据Pipeline中。通过简单地添加一个Operator,并利用Flink的Table API和DataStream API作为source和sink,Flink Agent可以轻松集成。此外,Flink多年积累的数据一致性保障(如Exactly-once语义)确保业务数据的准确性。基于Flink的大规模扩展性和灵活的扩缩容能力,Flink Agent也能够满足不同规模的需求。

该项目已于2025年10月上线发布,目前是完全开源的。用户可以在GitHub上查看源码,并在官方网站上找到更详细的架构介绍和快速入门指南。特别的是,我们也在官方文档中提供了一些模板,用户可以根据这些模板快速上手,搭建自己的应用。这使得用户不仅能快速理解如何使用Flink Agent,还能迅速将其集成到自己的项目中。
我们计划在二月初发布0.2版本,除了此前提到的Workflow、ReAct等模式外,该版本还将引入一些新的用户场景(user story),欢迎大家关注。
阿里云实时计算Flink AI Function介绍

除了前述推出的Agent框架用于帮助上层用户更便捷地创建Agent之外,回到本次主题——面向Agent的数据工程系统,在该系统中,传统TP、AP场景下的SQL或Python开发也可以直接调用相关的AI Function。同时,在SQL流作业或PyFlink作业中,也支持实时调用LLM进行实时推理。
基于LLM的实时推理

简单来说,当前的LLM实时调用不仅面向阿里云自身的业务(如百炼、PAI等),也支持通过create model注册兼容OpenAI接口协议的大模型服务。在此类模型服务之上,支持Embedding和Chat Completion等模型类型。基于此,可以将RAG流程中的embedding、检索等环节实现更彻底的实时化。同时,也可利用Chat Completion模型的特性,进行各类实时分析。
除通用分析能力外,还提供一些垂直领域的专用功能,例如分类、情感分析等垂类Function,以帮助用户在具体场景中更高效地使用。
AI Functions

目前,我们的开源版和企业版引擎在SQL和Table API中均支持 CREATE MODEL 模式。使用方式类似于以往创建数据库的操作:用户需定义模型的输入和输出。在配置时,可在 provider 字段中指定服务提供方,例如OpenAI或百炼,并填写对应的endpoint和API Key。由于模型服务商通常提供多个模型,用户还需明确指定具体使用的模型,例如GPT-5.2或通义千问Flash等。
在创建模型时,还可直接配置System Prompt,以及设置top-k、top-n、temperature等参数。左侧示例展示了在SQL中的使用方式,右侧则与SQL中的调用方式相近,但应用于Table API,从而支持基于Python和Java的开发。

在完成第一步通过 CREATE MODEL 建立与LLM的连接之后,当前开源版和企业版引擎均支持通用型的 ML_PREDICT 推理功能。以左侧SQL示例为例,用户需指定原始表、第一步中注册的模型,以及在description中声明使用原表中的哪些列作为输入进行通用推理。
在左下角的案例中,若要对用户评论进行情感分析,可将包含user comment的列作为输入。如果该模型已在System Prompt中预设了相关指令,则在调用 ML_PREDICT 函数时无需重复指定Prompt内容。
右侧展示了Table API中的等效用法,同样支持此类通用推理。

此外,开源版和企业版也均支持基于向量的检索功能。用户可指定向量库中的向量表(Vector Table)和待检索的当前表(search table),并通过Table API或SQL发起向量检索操作。

在开源引擎的基础上,企业版引擎还支持前述提到的实时RAG能力。其中前半部分涉及Embedding:在 CREATE MODEL 阶段,endpoint中任务类型除了用于推理的chat/completion,也支持指定为embedding。随后,通过 AI_EMBED 函数对输入文本进行实时向量化。接着,利用 VICTOR_SEARCH 这一聚合函数(或使用社区版已支持的向量检索函数),对生成的向量执行实时向量检索。
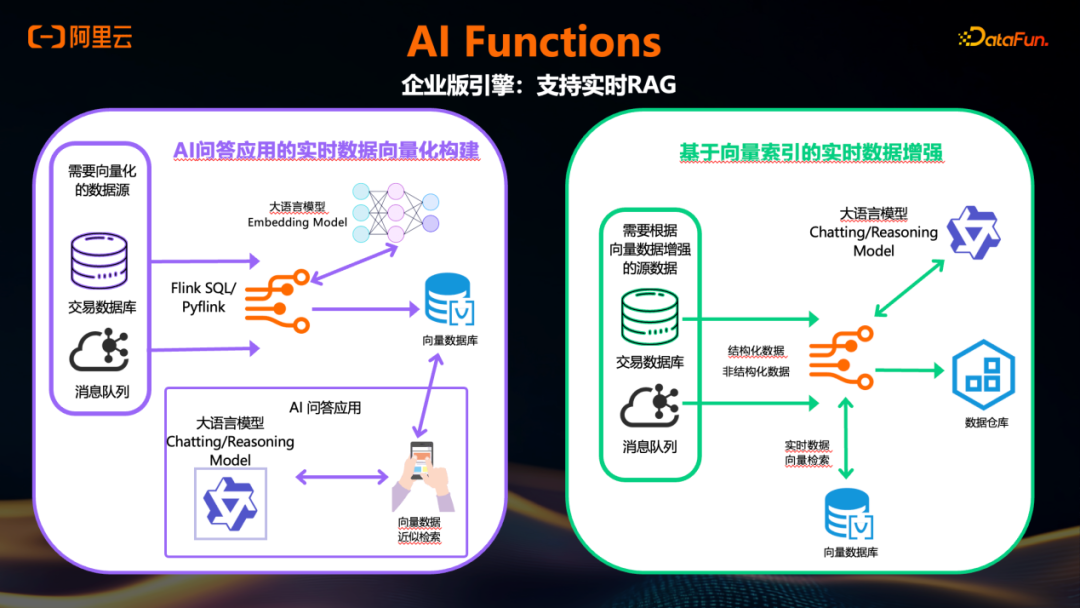
以该场景为例,左侧展示了前述Embedding部分的处理流程:当交易库中的数据(例如来自MySQL或Kafka)以字符串形式进入Flink作业时,可在作业中指定调用Embedding模型,通过 AI_EMBED 函数将这些字符串实时转换为向量,并直接写入下游的向量库。
在检索阶段,同样支持实时调用Chat模式的LLM,并结合向量库与OSS、Lakehouse等存储引擎,进行实时的聚合分析。

在企业版引擎中,除了提供通用型的 ML_PREDICT 能力外,还针对多个垂直场景进行了优化。使用通用型模型的一个主要问题是用户需要在Prompt上投入大量精力。为此,在垂类场景下,我们将经过持续优化和调整的System Prompt固化到后台,并以此为基础向用户提供面向特定场景的AI Function。
例如,目前已支持实时翻译、基于已有打标体系的分类以及情感分析等垂类AI Function,使用户无需自行设计复杂的Prompt即可直接调用这些能力。

此外,还支持基于信息的提取和智能总结等垂类AI Function。

目前我们还在扩展对非结构化数据的AI Function支持。此前的场景主要基于结构化表中的字符串字段,而现在正逐步引入对图片等非结构化数据的处理能力。
以图片为例,在典型业务流程中,用户上传图片后,经过前序链路最终写入OSS。过去的做法是等待大量图片累积在OSS(或S3等对象存储)中后,再通过批处理引擎调用AI Function进行推理。而现在,我们可以基于新增的增量图片文件——一旦上传至对象存储即触发事件通知——将该事件发送至Flink,由Flink实时调用相应的AI Function进行处理,并将图像分类或信息提取的结果写入下游的Lakehouse系统。
对于语音和视频数据,相关能力也在逐步建设中。需要注意的是,由于音视频文件体积较大,直接通过OSS传输可能存在延迟。因此,我们正在探索除HTTP以外的其他协议(例如WebSocket方式),以更高效地支持实时音视频模型的处理。该功能将分阶段发布。
AI Function客户案例:某车企客户之声实时市场舆情分析

有一个头部车企的客户案例,其痛点与前述电商领域的客户之声(VOC)场景类似,主要集中在处理效率、吞吐能力以及成本方面。原先的方案在LLM模型应用上存在多元数据整合困难和实时性不足的问题。
该车企的用户反馈来源多样,包括其垂类社区、自有APP以及外部网站的评论。这些数据以事件形式推送至Kafka,再由Flink消费,并在Flink作业中实时调用百炼模型服务,对数据进行实时推理。推理结果随后写入下游系统,包括车主APP、公关团队及相关业务模块。
整体落地效果显示,该方案在吞吐量、成本控制和推理精确度等方面均超出客户预期,目前该方案正在逐步扩大应用规模。
如何进一步提升端到端AI实时性?

在前述讲述中,熟悉模型调用的观众可能会提出一个疑问:当在Flink中实时调用远程模型(例如基于HTTP协议)时,必然引入额外的网络和推理耗时。对于某些Flink作业场景——例如普通的ETL处理——端到端延迟要求非常严格;而对于另一些场景,如复杂事件处理(CEP)或更深层次的分析,虽然对延迟的容忍度稍高,但仍存在对模型调用耗时的担忧。
针对这一问题,我们提供了两种解决方案:一种是 Flink + Fluss 的组合,另一种是使用本地部署的小模型。
Apache Fluss是什么
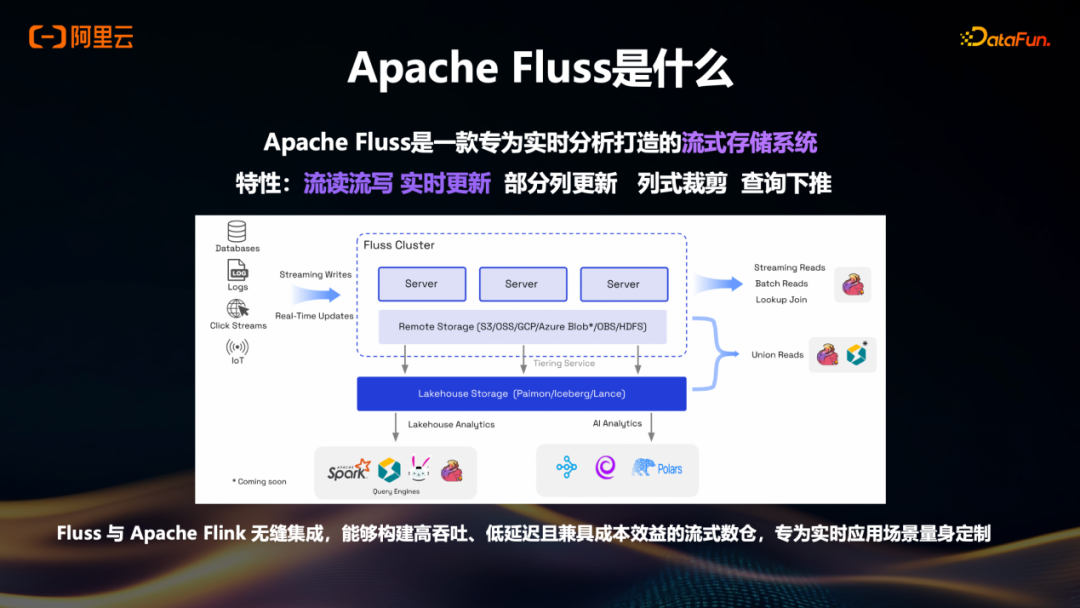
在前面提到的许多案例中,源端数据通常通过Kafka写入Flink。由于Kafka作为消息队列被广泛使用,很多人逐渐认为Kafka与Flink是天然匹配的组合。然而,Kafka本身并非为流处理场景原生设计,因此在流式处理中会遇到诸如Partial Update等细节问题。
针对这一情况,我们团队近两年推出了新项目Apache Fluss。简单理解,Fluss是一个专为流场景设计的流存储系统。当数据从源端产生后,可直接写入Fluss;Flink计算层在需要读取数据时,也直接从Fluss中查询。借助Fluss支持的流读流写、实时更新、部分列更新、列式裁剪、查询下推等特性,能够显著提升端到端的实时性。
例如,在一个典型链路中,数据从Kafka经Flink处理后写入Doris,且Flink中需执行复杂分析而非简单处理,原有端到端延迟约为五分钟。而采用Fluss替代Kafka后,整体端到端延迟得到极大改善。
AI Function + Fluss: 直播评论实时智能情感分析
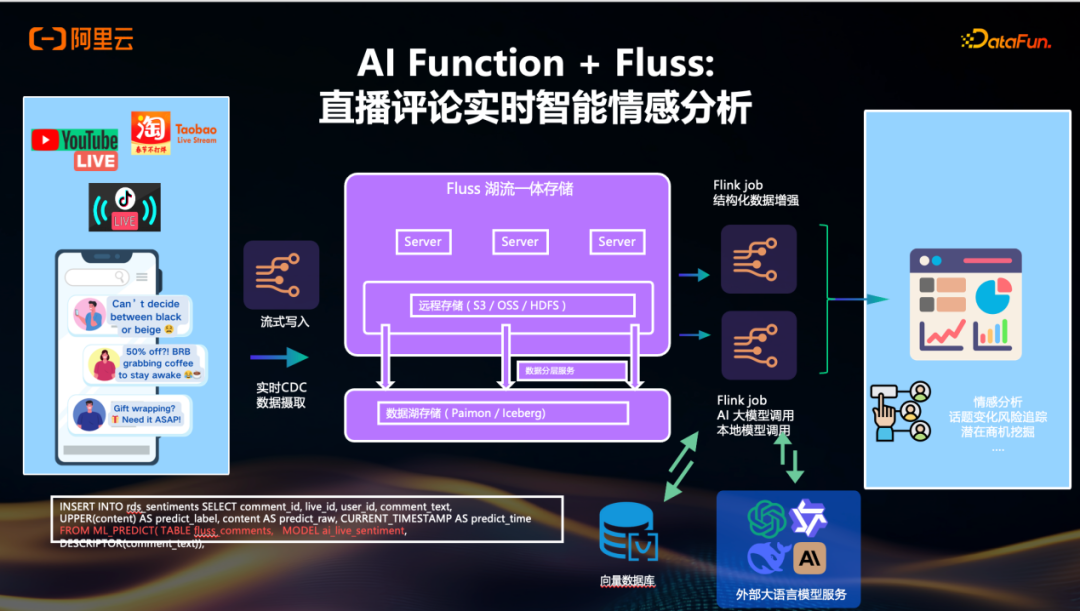
结合Fluss和刚刚提到的本地model的内置,比如今天反复讲到用户评论这种场景,数据流式写入到Fluss之后,Flink里面去调用一些外部的model和内置的model进行相关分析,实时生成情感分析和话题风险的相关分析,提升端到端的流式推理的实时性。
结语

本次分享,首先回顾了Apache Flink的能力,随后介绍了构建事件驱动型智能体的开源框架Flink Agents,最后给大家介绍了Flink中内置的调用大模型进行实时向量化及实时推理的AI Function。欢迎大家开通阿里云上Serverless Flink版本进行免费试用。https://free.aliyun.com/?productCode=sc

希望这篇在DataFun峰会上的技术分享,能帮助各位开发者和技术决策者更好地理解如何利用Flink构建实时、高效的事件驱动型AI系统。想获取更多关于大数据、人工智能和流计算等前沿技术的实战经验和社区讨论,欢迎访问云栈社区。
 发表于 2026-2-8 02:34:33
|
查看: 196|
回复: 0
发表于 2026-2-8 02:34:33
|
查看: 196|
回复: 0
