随着LangSmith Agent Builder进入正式发布阶段,AI框架领域的竞争焦点正从开源社区转向企业级市场。本文将深度解析这款拥有12.5万GitHub星标的热门框架,为不同背景的开发者提供从入门到落地的实战指南。
一、为什么选择LangChain:解决大模型应用的“最后一公里”
1.1 市场地位:全栈Agent开发的事实标准
截至最新统计,LangChain在GitHub上已收获超过12.5万颗星,成为全栈式智能体开发的事实标准。根据相关行业报告显示:
- 57%的企业 已经在生产环境中部署了AI Agent。
- 大公司(员工>1万人)采用率高达67%,显著高于小企业。
- 客户服务(26.5%)和数据分析(24.4%) 是最主要的应用场景。
这些数据揭示了一个明确趋势:企业需要的是能够快速验证、安全部署且持续优化的成熟工具链,而非仅仅是炫酷的技术演示。
技术洞察
LangChain通过Model Context Protocol(MCP)集成了Gmail、Google Docs、Slack等大量企业常用工具,支持的自定义工具集成超过8000个,形成了显著的生态护城河。
1.2 核心价值:Context Engineering让Agent“长期运行”
LangChain的核心突破在于 Context Engineering(上下文工程) 。这解决了早期Agent像“实习生”、每做一件事都需要重新交代背景的窘境。
现在的Agent更像“资深员工”,能够持续工作数小时,自主发现问题并解决。Context Engineering主要围绕四大策略展开:
- 写入(Write):将上下文保存在外部存储,而非全部塞进Prompt。
- 选择(Select):动态检索最相关的上下文片段,可节省高达90%的上下文窗口。
- 压缩(Compress):通过摘要、截断等技术,将海量Token压缩至可控范围。
- 隔离(Isolate):将系统提示、任务指令、领域知识与对话历史进行分离管理。
1.3 生态优势:8000+工具与MCP协议
LangChain通过MCP协议构建的强大生态是其关键优势。相比之下:
- LangChain:实际可用集成超过8000个。
- 其他竞品:虽然理论上支持同类协议,但实际可用集成数量有限。
这种深度且广泛的集成能力,使LangChain在企业级市场中占据了难以替代的位置。
二、快速上手:15分钟搭建RAG应用全流程
2.1 环境配置:一行命令搞定依赖
# 安装LangChain及相关依赖
pip install langchain langchain-openai langchain-community chromadb tiktoken
如果你使用的是国内环境,可以方便地替换为国产大模型:
# 使用百度文心一言
pip install langchain langchain-baidu-qianfan
# 使用阿里通义千问
pip install langchain langchain-alibaba
2.2 完整RAG应用代码(约100行Python)
"""
LangChain RAG应用示例:15分钟搭建智能问答系统
"""
import os
from typing import List, Dict, Any
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain.schema import Document
# 1. 配置API密钥(替换为你的实际密钥)
os.environ["OPENAI_API_KEY"] = "你的OpenAI API密钥"
# 或者使用国内大模型
# os.environ["QIANFAN_AK"] = "你的百度AK"
# os.environ["QIANFAN_SK"] = "你的百度SK"
class RAGApplication:
"""基于LangChain的RAG应用类"""
def __init__(self, model_name: str = "gpt-3.5-turbo"):
"""初始化RAG应用
Args:
model_name: 模型名称,支持gpt-3.5-turbo、gpt-4、qwen等
"""
self.model_name = model_name
self.vectorstore = None
self.qa_chain = None
# 初始化组件
self.embeddings = OpenAIEmbeddings()
self.llm = ChatOpenAI(
model_name=model_name,
temperature=0.7, # 控制创造性,0-1之间
max_tokens=1000
)
# 文本分割器
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每个块500字符
chunk_overlap=50, # 块间重叠50字符
separators=["\n\n", "\n", "。", "!", "?", ",", " ", ""]
)
def load_documents(self, file_path: str) -> List[Document]:
"""加载文档并分割
Args:
file_path: 文档路径
Returns:
分割后的文档列表
"""
print(f"正在加载文档: {file_path}")
# 使用TextLoader加载文档(支持.txt、.md等)
loader = TextLoader(file_path, encoding="utf-8")
documents = loader.load()
# 分割文档
splits = self.text_splitter.split_documents(documents)
print(f"文档分割完成,共{len(splits)}个块")
return splits
def create_vectorstore(self, documents: List[Document]) -> None:
"""创建向量存储
Args:
documents: 分割后的文档列表
"""
print("正在创建向量存储...")
# 使用Chroma作为向量数据库
self.vectorstore = Chroma.from_documents(
documents=documents,
embedding=self.embeddings,
persist_directory="./chroma_db" # 持久化目录
)
print("向量存储创建完成")
def create_qa_chain(self) -> None:
"""创建问答链"""
print("正在创建问答链...")
# 自定义提示词模板
prompt_template = """你是一个专业的AI助手,基于以下上下文回答问题。
上下文:
{context}
问题:{question}
请基于上下文提供准确、详细的回答。如果上下文不包含相关信息,请说明“根据现有信息无法回答”。
回答:"""
prompt = PromptTemplate(
template=prompt_template,
input_variables=["context", "question"]
)
# 创建RetrievalQA链
self.qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=self.vectorstore.as_retriever(
search_kwargs={"k": 3} # 返回最相关的3个文档
),
chain_type_kwargs={"prompt": prompt},
return_source_documents=True
)
print("问答链创建完成")
def ask_question(self, question: str) -> Dict[str, Any]:
"""回答问题
Args:
question: 用户问题
Returns:
包含回答和源文档的字典
"""
if not self.qa_chain:
raise ValueError("请先加载文档并创建问答链")
print(f"问题: {question}")
result = self.qa_chain.invoke({"query": question})
# 打印结果
print(f"\n回答: {result['result']}")
print("\n参考来源:")
for i, doc in enumerate(result['source_documents'], 1):
print(f"{i}. {doc.page_content[:100]}...")
return result
def run_demo(self) -> None:
"""运行完整演示"""
print("=" * 50)
print("LangChain RAG应用演示")
print("=" * 50)
# 步骤1:创建示例文档
sample_content = """LangChain是一个用于开发大语言模型应用的开源框架。
核心功能包括:
1. 与多种大模型集成(OpenAI、Anthropic、Google等)
2. 丰富的工具调用能力
3. 高效的向量检索(RAG)
4. 多Agent协作编排
LangChain的最新版本是1.0,引入了LCEL(LangChain Expression Language)作为生产级标准范式。
RAG(检索增强生成)是LangChain的核心应用场景,通过结合检索和生成技术,让大模型能够基于外部知识库回答用户问题。
Context Engineering是LangChain提出的关键技术概念,通过Write、Select、Compress、Isolate四大策略,让Agent能够长期运行。
"""
# 保存示例文档
with open("sample_doc.txt", "w", encoding="utf-8") as f:
f.write(sample_content)
# 步骤2:加载文档
documents = self.load_documents("sample_doc.txt")
# 步骤3:创建向量存储
self.create_vectorstore(documents)
# 步骤4:创建问答链
self.create_qa_chain()
# 步骤5:示例问答
questions = [
"LangChain是什么?",
"RAG技术的核心价值是什么?",
"什么是Context Engineering?"
]
for question in questions:
self.ask_question(question)
print("-" * 30)
# 运行演示
if __name__ == "__main__":
# 创建RAG应用实例
rag_app = RAGApplication(model_name="gpt-3.5-turbo")
# 运行完整演示
rag_app.run_demo()
2.3 代码解读:四大核心模块
- 文档加载与分割
- 使用
TextLoader 加载 .txt、.md 等格式文档。
RecursiveCharacterTextSplitter 按语义分割,保留上下文连贯性。
- 向量化与存储
OpenAIEmbeddings 将文本转换为向量。Chroma 作为轻量级向量数据库,支持持久化。
- 检索增强
as_retriever() 配置检索器,返回最相关的文档块。- 语义搜索替代传统关键词匹配,更好理解用户意图。
- 问答生成
RetrievalQA 链整合检索与生成。- 自定义提示词模板控制回答格式和质量。
2.4 运行效果展示
==================================================
LangChain RAG应用演示
==================================================
正在加载文档: sample_doc.txt
文档分割完成,共5个块
正在创建向量存储...
向量存储创建完成
正在创建问答链...
问答链创建完成
问题: LangChain是什么?
回答: LangChain是一个用于开发大语言模型应用的开源框架。它提供了与大模型集成、工具调用、向量检索(RAG)以及多Agent协作编排等核心功能。
参考来源:
1. LangChain是一个用于开发大语言模型应用的开源框架...
2. 核心功能包括:1. 与多种大模型集成(OpenAI、Anthropic、Google等)...
三、避坑指南:常见陷阱与最佳实践
3.1 陷阱一:上下文窗口爆炸
错误做法:将所有历史对话、工具调用结果、文档内容全部塞进Prompt。
# 错误示例:无限制积累上下文
conversation_history += f"用户: {user_input}\n助手: {assistant_response}\n"
prompt = f"{conversation_history}当前问题: {current_question}"
最佳实践:实施Context Compression策略。
from langchain.memory import ConversationSummaryBufferMemory
# 使用对话摘要记忆
memory = ConversationSummaryBufferMemory(
llm=llm,
max_token_limit=2000, # 限制记忆Token数量
return_messages=True
)
# 自动摘要历史对话,保留核心信息
memory.save_context({"input": user_input}, {"output": assistant_response})
3.2 陷阱二:向量检索质量低下
错误做法:单一检索策略,忽视元数据过滤。
# 错误示例:仅使用语义检索
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
最佳实践:混合检索 + 元数据过滤。
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
# 1. 元数据过滤
retriever = vectorstore.as_retriever(
search_kwargs={
"k": 5,
"filter": {"source": "official_docs"}, # 按来源过滤
"score_threshold": 0.7 # 相似度阈值
}
)
# 2. 上下文压缩:提取最相关片段
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=retriever
)
3.3 陷阱三:工具调用失控
错误做法:无限制工具调用权限。
# 错误示例:给Agent所有工具权限
tools = [search_tool, write_file_tool, execute_code_tool, send_email_tool]
agent = create_agent(llm=llm, tools=tools)
最佳实践:最小权限原则 + 人工审批中间件。
from langchain.agents import AgentExecutor, create_react_agent
from langchain.middleware import HumanApprovalMiddleware
# 1. 按需分配工具
basic_tools = [search_tool, read_file_tool] # 基础工具
advanced_tools = [write_file_tool, send_email_tool] # 高风险工具
# 2. 添加人工审批中间件
agent = create_react_agent(llm=llm, tools=basic_tools)
agent_executor = AgentExecutor(
agent=agent,
tools=basic_tools,
verbose=True,
# 高风险操作需要人工审批
middlewares=[HumanApprovalMiddleware(risk_threshold=0.8)]
)
3.4 陷阱四:忽视可观测性
错误做法:生产环境无监控,问题无法追溯。
# 错误示例:直接部署无监控
agent_executor.invoke({"input": user_query})
最佳实践:集成LangSmith全链路追踪。
import os
from langsmith import Client
from langchain.smith import RunEvalConfig, run_on_dataset
# 1. 配置LangSmith
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "你的LangSmith API密钥"
os.environ["LANGCHAIN_PROJECT"] = "生产环境监控"
# 2. 自动评估与监控
client = Client()
eval_config = RunEvalConfig(
evaluators=[
"qa", # 问答准确性
"context_relevancy", # 上下文相关性
"faithfulness" # 回答忠实度
]
)
# 3. 定期运行评估
run_on_dataset(
client=client,
dataset_name="生产问答测试集",
llm_or_chain_factory=agent_executor,
evaluation=eval_config
)
四、扩展思路:从单应用到企业级架构
4.1 LangGraph:复杂工作流编排
对于需要多步骤、有状态、循环执行的企业级任务,LangChain 提供了 LangGraph 框架。
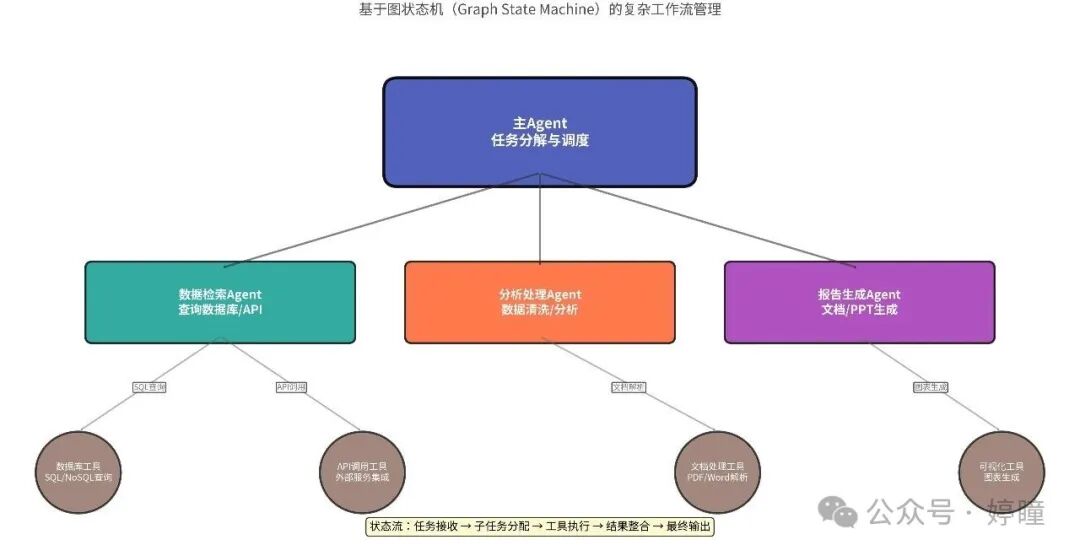
典型应用场景:
- 金融合规审查:文档解析 → 风险识别 → 人工审批 → 报告生成
- 客户服务升级:自动应答 → 复杂问题识别 → 专家转接 → 知识库更新
- 供应链优化:需求预测 → 库存分析 → 采购建议 → 执行监控
代码示例:多Agent协作系统核心结构
from langgraph.graph import StateGraph, END
from langgraph.checkpoint import MemorySaver
# 定义状态结构
from typing import TypedDict
import operator
class AgentState(TypedDict):
"""多Agent协作状态"""
task: str # 原始任务
plan: list # 分解后的子任务
results: dict # 各Agent执行结果
final_answer: str # 最终答案
# 创建Agent图
graph_builder = StateGraph(AgentState)
# 定义节点函数(规划、执行、监督)并添加节点...
# 设置边与条件路由...
# 编译图
memory = MemorySaver()
graph = graph_builder.compile(checkpointer=memory)
# 执行任务
initial_state = {"task": "分析本季度财报并生成PPT摘要"}
result = graph.invoke(initial_state)
print(f"最终答案: {result['final_answer']}")
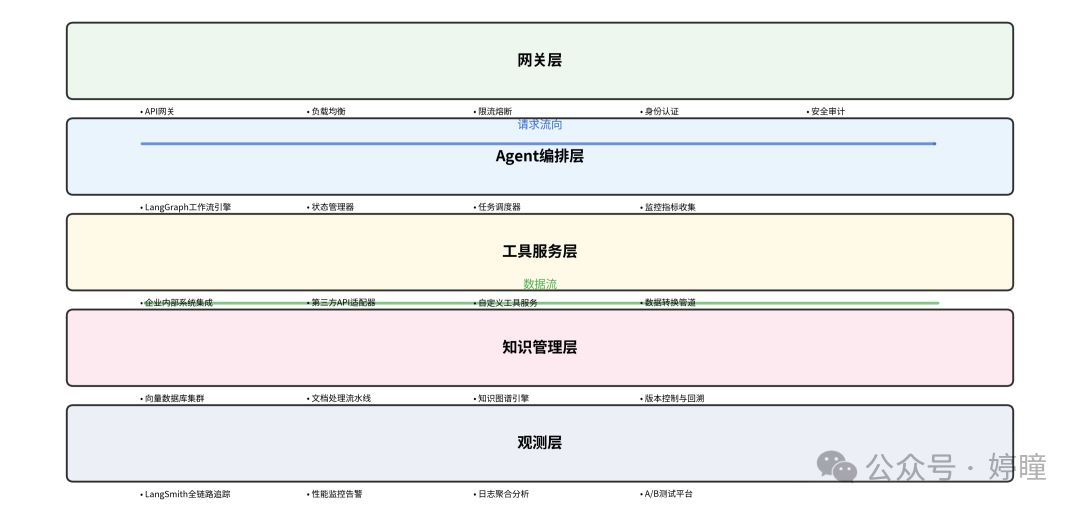
4.2 企业级部署架构
对于大型企业,建议采用分层的可扩展架构。
核心组件说明:
- 网关层:请求路由、限流、鉴权
- Agent编排层:LangGraph工作流管理、状态持久化
- 工具服务层:企业系统集成(CRM、ERP、数据库)
- 知识管理层:向量数据库、文档处理流水线
- 观测层:LangSmith监控、日志聚合、性能分析
高可用配置示例(Kubernetes):
apiVersion: apps/v1
kind: Deployment
metadata:
name: langchain-agent
spec:
replicas: 3 # 多副本保证高可用
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
template:
spec:
containers:
- name: agent
image: langchain-agent:latest
resources:
limits:
memory: "2Gi"
cpu: "1"
env:
- name: LANGCHAIN_TRACING_V2
value: "true"
- name: REDIS_HOST
value: "redis-cluster"
readinessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
五、总结与行动指南
5.1 核心价值回顾
- 降本增效:让企业级Agent开发从“季度级”缩短到“天级”。
- 生态优势:8000+工具集成,MCP协议支持,形成完整生态。
- 生产就绪:提供全链路追踪、中间件机制、标准化ReAct循环。
- 持续演进:Context Engineering、LangGraph等创新持续提升Agent能力。
5.2 立即开始的三个步骤
环境搭建(5分钟):
pip install langchain langchain-openai
第一个Agent(10分钟):
from langchain.agents import create_react_agent
from langchain.tools import Tool
# 定义简单工具
def search_tool(query: str) -> str:
return f"搜索结果: {query}"
# 创建Agent
tools = [Tool(name="Search", func=search_tool, description="搜索工具")]
agent = create_react_agent(llm=llm, tools=tools)
生产部署(30分钟):
- 集成LangSmith监控
- 添加错误处理中间件
- 配置自动伸缩策略
5.3 常见问题解答
Q:LangChain学习曲线陡峭吗?
A:对于简单应用,1-2天即可上手;复杂应用需要1-2周系统学习。建议从官方Quickstart开始。
Q:需要多少预算?
A:开源版本免费;企业级功能(如LangSmith)有订阅计划。相比从零自研,能显著降低成本和风险。
Q:适合哪些行业?
A:金融、医疗、教育、电商、制造等任何涉及知识处理与自动化流程的行业都有成功案例。
Q:未来会被替代吗?
A:作为当前的事实标准,LangChain的生态和社区壁垒已经形成。其架构设计也便于集成新的技术趋势。
通过本文的解析,我们可以看到,LangChain 真正降低了大模型应用开发的门槛。无论是想快速验证创意的创业者,还是希望提升技术栈的 Python 开发者,都可以借助这套框架将自己的想法转化为可运行的智能应用。如果你对这类 开源实战 项目或企业级AI部署有更多兴趣,欢迎在技术社区深入交流。
 发表于 2026-2-7 15:26:09
|
查看: 336|
回复: 0
发表于 2026-2-7 15:26:09
|
查看: 336|
回复: 0
