当AI应用开发从简单的单模型演示,扩展到包含多个处理步骤(例如,后处理、背景移除、转录、检索重排等)的复杂工作流时,调试就成了一场噩梦。你不得不反复运行代码、打印中间结果,甚至注释掉大段逻辑来定位问题。数据在多个环节间流转,一旦出错,往往难以快速确定根源。
Daggr 正是为解决这类可视化调试难题而生的一个开源 Python 库。它的核心理念很明确:用代码定义工作流,用可视化图审视系统状态。它并非要取代 Python 编程或强行推广拖拽式编辑器,而是填补了代码开发与视觉调试之间的空白。
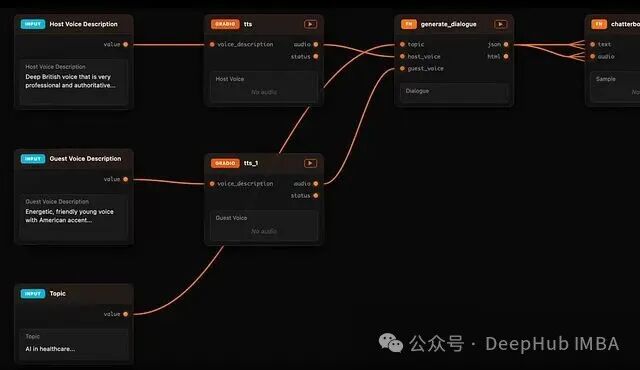
Daggr 概述
Daggr 是一个用于构建 AI 工作流的 Python 库。你使用标准 Python 语法来定义工作流,无需学习额外的 DSL 或编写 YAML 配置。其核心功能在于,能够从你的代码实时生成一个可交互的可视化画布。
这个画布是一个有向图,精确反映了代码的执行状态。每个计算步骤都对应一个节点,节点之间的数据流向清晰可见。你可以点击查看任意中间输出,单独重跑某个节点,或回溯整个执行历史。一个关键的设计哲学是:可视化层仅作为观察和调试工具,源代码始终是唯一的事实来源。这让它从根本上区别于那些以拖拽编辑为核心的传统编排工具。
上手体验
安装非常简单:
pip install daggr
接下来,创建一个 Python 文件,例如 app.py:
import random
import gradio as gr
from daggr import GradioNode, Graph
glm_image = GradioNode(
"hf-applications/Z-Image-Turbo",
api_name="/generate_image",
inputs={
"prompt": gr.Textbox(
label="Prompt",
value="A cheetah in the grassy savanna.",
lines=3,
),
"height": 1024,
"width": 1024,
"seed": random.random,
},
outputs={
"image": gr.Image(
label="Image"
),
},
)
background_remover = GradioNode(
"hf-applications/background-removal",
api_name="/image",
inputs={
"image": glm_image.image,
},
postprocess=lambda _, final: final,
outputs={
"image": gr.Image(label="Final Image"),
},
)
graph = Graph(
name="Transparent Background Image Generator", nodes=[glm_image, background_remover]
)
graph.launch()
运行它:
daggr app.py
这时,你看到的不是一个传统的、黑盒的 Gradio 演示界面,而是一张清晰的可视化画布:两个节点(图像生成、背景移除)通过边连接在一起。你可以调整输入参数,检查每个节点的输出结果。更重要的是,你可以单独重跑图像生成节点或背景移除节点,也可以在历史结果之间切换,观察下游节点如何响应不同的上游输入。整个调试过程无需插入 print 语句,也无需人工记忆状态是如何一步步变化的。
与 Gradio 的核心差异
Gradio 在构建单步模型演示方面非常出色。但当工作流涉及多个步骤时,调试难度会指数级上升。比如,当你修改了一个 prompt,下游某处结果异常,你很难快速确定:是哪个环节没有重新执行?它使用的到底是哪一组输入参数?
Daggr 直接瞄准了这个问题。在它的画布里,每次节点运行都会被记录,每个输出都可以追溯其源头,每条连接都通过视觉样式标记了数据的“新鲜度”。当上游的值发生变化时,Daggr 会通过颜色变化清晰地告诉你;下游节点如果还没重新执行,其状态也一目了然。
从模型上看,Daggr 将工作流抽象为一个有向无环图(DAG)。每个节点代表一次计算,可以是 Gradio Space API 调用、Hugging Face 模型推理,或者一个普通的 Python 函数。节点通过输入和输出端口定义接口,数据就在这些端口之间的连接上流动。
节点类型详解
1. GradioNode:封装现有 Gradio 应用
GradioNode 用于调用已有的 Gradio 应用,无论是托管在 Hugging Face Spaces 上的远程应用,还是本地运行的服务。
from daggr import GradioNode
import gradio as gr
image_gen = GradioNode(
space_or_url="black-forest-labs/FLUX.1-schnell",
api_name="/infer",
inputs={
"prompt": gr.Textbox(label="Prompt"),
"seed": 42,
"width": 1024,
"height": 1024,
},
outputs={
"image": gr.Image(label="Generated Image"),
},
)
对于熟悉 Hugging Face Spaces “Use via API” 功能的开发者,这个接口定义方式会非常亲切。由于 GradioNode 调用的是外部服务,它默认采用并发执行模式。
2. FnNode:封装自定义 Python 函数
当你的工作流需要自定义逻辑(如数据解析、过滤、组合)而不仅是模型调用时,FnNode 就派上用场了。
from daggr import FnNode
import gradio as gr
def summarize(text: str, max_words: int = 100) -> str:
words = text.split()[:max_words]
return " ".join(words) + "..."
summarizer = FnNode(
fn=summarize,
inputs={
"text": gr.Textbox(label="Text to Summarize", lines=5),
"max_words": gr.Slider(minimum=10, maximum=500, value=100),
},
outputs={
"summary": gr.Textbox(label="Summary"),
},
)
Daggr 会自动检查函数签名,按参数名匹配输入,并按返回值顺序映射到输出端口。值得注意的是,FnNode 默认采用串行执行。这是因为本地 Python 代码可能涉及文件 I/O、GPU 资源、全局状态或非线程安全的库,Daggr 选择了更保守的默认行为。当然,你也可以显式启用并发:
node=FnNode(my_func, concurrent=True)
3. InferenceNode:云端模型推理
InferenceNode 让你能直接通过 Hugging Face 的推理服务调用模型,无需下载权重或配置本地环境。
from daggr import InferenceNode
import gradio as gr
llm = InferenceNode(
model="meta-llama/Llama-3.1-8B-Instruct",
inputs={
"prompt": gr.Textbox(label="Prompt", lines=3),
},
outputs={
"response": gr.Textbox(label="Response"),
},
)
它默认并发执行,并会自动处理 Hugging Face token 的传递,支持 ZeroGPU 计费追踪、私有 Space 访问等。
核心特性解析
全链路溯源(Provenance)
这是 Daggr 的杀手锏。每次节点执行,Daggr 都会保存输出结果以及产生这个结果的精确输入参数。你可以像浏览版本历史一样查看某个节点的所有历史结果。当你选择某个历史记录时,Daggr 不仅会恢复当前节点的输入状态,整个下游依赖链的状态都会同步恢复。
这意味着你可以自由探索不同的参数变体,而不会丢失上下文。例如,先生成三张图,对其中的两张进行背景移除,然后你可以轻松切回查看第一张图,整个工作流图会自动对齐到对应的历史状态。这不仅仅是便利,它改变了一种开发范式。
状态可视化
Daggr 使用边的颜色来传递数据状态信息:
- 橙色边:表示数据是最新的。
- 灰色边:表示数据已过期。
一旦上游输入发生改变,所有依赖这条输入的边都会变成灰色,清晰地告诉你哪些节点需要重新执行。
Scatter 与 Gather 模式
有些工作流需要处理列表数据:生成多个项目,分别处理,最后再合并。Daggr 通过 .each 和 .all() 语法优雅地支持这种模式:
script = FnNode(fn=generate_script, inputs={...}, outputs={"lines": gr.JSON()})
tts = FnNode(
fn=text_to_speech,
inputs={
"text": script.lines.each["text"],
"speaker": script.lines.each["speaker"],
},
outputs={"audio": gr.Audio()},
)
final = FnNode(
fn=combine_audio,
inputs={"audio_files": tts.audio.all()},
outputs={"audio": gr.Audio()},
)
语法是标准的 Python,逻辑清晰,同时 Daggr 能够理解其背后的数据分发与聚合语义。
Choice 节点
当你想在多个备选方案(比如不同的图像生成器、不同的 TTS 服务)之间快速切换,同时保持下游逻辑不变时,Choice 节点非常有用。
host_voice=GradioNode(...) | GradioNode(...)
UI 中会出现一个选择器,下游连接保持不变,你的选择结果会在当前 sheet 中持久化。这非常适合做对比实验。
Sheets:多状态工作区
Daggr 引入了 sheets 的概念,你可以把它理解为一个独立的工作区。每个 sheet 拥有自己独立的输入参数、缓存结果和画布布局,但共享同一个工作流定义。这就像你在 notebook 里复制多个 cell 做不同实验,但管理起来更加规范。
API 与一键部署
你的 Daggr 工作流会自动暴露 REST API,你可以通过以下方式查询接口模式:
curl http://localhost:7860/api/schema
部署也同样简单:
daggr deploy my_app.py
Daggr 会自动提取工作流图,创建 Hugging Face Space,生成所需元数据并完成部署。
总结:Daggr 的定位
对于单一模型的快速演示,Gradio 依然是最佳选择;对于追求极致可视化、节点式编排的场景(如 Stable Diffusion 工作流),ComfyUI 可能更合适;对于企业级、生产环境下的复杂任务调度,Airflow 或 Prefect 是更成熟的选择。
那么,Daggr 的价值在哪里?它精准地定位在中间地带:当你的 AI 工作流 复杂度已经超越了单步演示,需要可视化工具来理解和调试,但又尚未复杂到需要引入完整的编排系统时;当你仍处于快速探索、调整参数、迭代原型的阶段时——这正是 Daggr 最能发挥其威力的场景。它将代码的严谨与可视化的直观结合,为 AI 应用开发者提供了一个强大的“调试望远镜”。
欢迎在 云栈社区 分享你在使用 Daggr 或构建复杂 AI 工作流时的心得与问题。
 发表于 2026-2-7 15:58:01
|
查看: 265|
回复: 0
发表于 2026-2-7 15:58:01
|
查看: 265|
回复: 0
