最近在使用Google的NotebookLM时,我被它的一个功能深深吸引了——它能够基于你上传的文档,自动生成一段视频讲解,非常生动。可以把复杂的内容讲得清晰易懂、生动有趣。
今天我在听视频的时候,脑海中突然冒出一个想法:
这么好的内容,如果只能听一遍就过去了,太可惜了。能不能把它转成文字,再整理成一篇文章?
这个想法看似简单,但当我真正开始思考如何实现时,发现这背后涉及的技术决策远比想象中复杂。
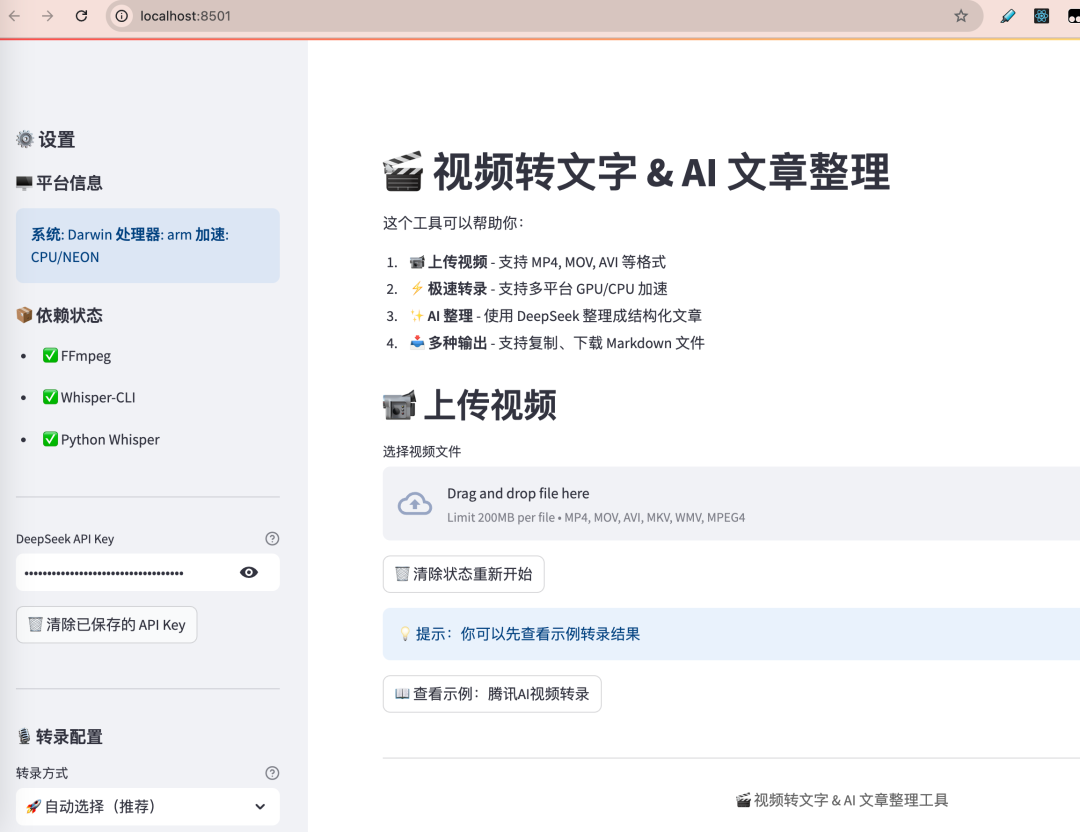
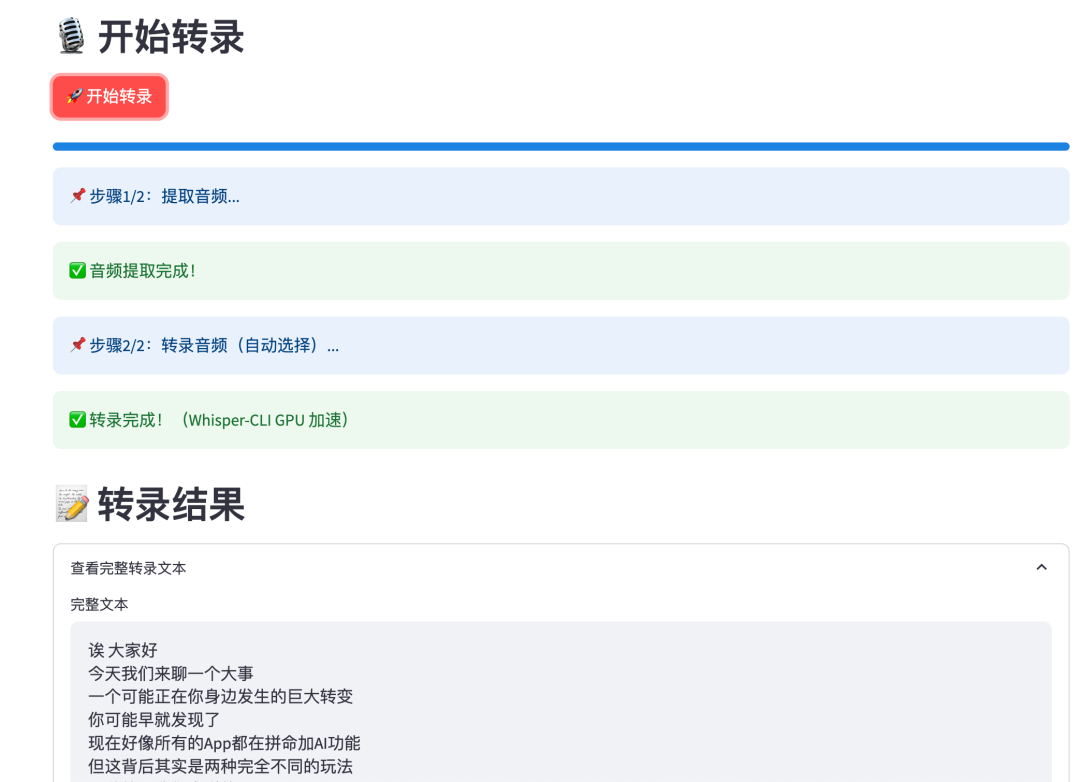
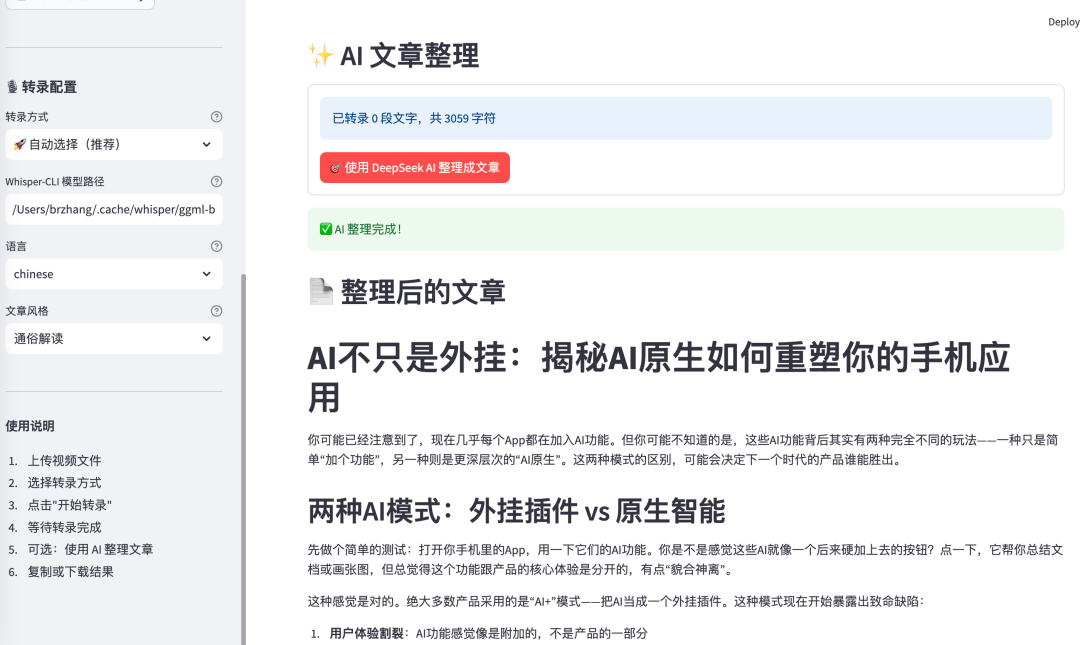
第一个问题:从哪里开始?
我手上有的是什么?一个视频文件(或音频文件)。我想要的是什么?一篇结构化的文章。
中间需要经过哪些步骤?我在纸上画了一个最简单的流程:
视频文件 → 音频文件 → 文字稿 → 结构化文章
看起来只有四步,但每一步都藏着技术选型的问题。让我一个一个来推敲。
第一步:我应该如何提取音频?
视频文件通常包含两个流:视频流和音频流。我只需要音频部分,所以第一步是把音频提取出来。
这里我面临第一个选择:用什么工具来提取音频?
方案对比
我能想到的方案有三个:
方案 A:使用Python库(如 moviepy)
from moviepy.editor import VideoFileClip
video = VideoFileClip("video.mp4")
video.audio.write_audiofile("audio.wav")
优点:
缺点:
- 依赖FFmpeg(moviepy底层还是调用FFmpeg)
- 多了一层封装,性能损失
- 错误处理不够灵活
方案 B:直接使用 FFmpeg
ffmpeg -i video.mp4 audio.wav
优点:
- 性能最优,直接调用底层工具
- 参数控制灵活
- 错误信息清晰
缺点:
方案 C:使用在线服务
优点:
缺点:
我反复思考了这三个方案。方案C首先被排除,因为处理视频这种大文件,本地处理更可靠。
那么A和B怎么选?
关键在于:moviepy本质上也是调用FFmpeg。既然最终都要依赖FFmpeg,为什么不直接用呢?多一层封装只会增加复杂度,而且出问题时更难调试。
但直接用FFmpeg有个问题:参数太多了。一个简单的 ffmpeg -i video.mp4 audio.wav 看起来简单,但实际上FFmpeg会用默认参数,这些默认参数不一定适合语音识别。
我需要搞清楚:语音识别需要什么样的音频格式?
深入音频格式
我查阅了Whisper的文档,发现它推荐的音频格式是:
- 采样率:16kHz(16000 Hz)
- 声道数:单声道(mono)
- 编码格式:PCM 16-bit
为什么是这些参数?让我一个个分析:
1. 为什么是 16kHz?
人类语音的频率范围主要在 85Hz - 8kHz 之间。根据奈奎斯特采样定理,采样率需要至少是最高频率的2倍,所以16kHz足够覆盖语音频率范围。
更高的采样率(如44.1kHz)会带来:
- ✅ 更好的音质(对音乐重要)
- ❌ 更大的文件
- ❌ 更长的处理时间
- ❌ 对语音识别没有明显提升
所以16kHz是一个平衡点。
2. 为什么是单声道?
立体声(stereo)有左右两个声道,但对于语音识别来说:
- 两个声道的内容通常是相同的(或差异很小)
- 单声道可以减少一半的数据量
- 语音识别模型通常是基于单声道训练的
所以转成单声道既能减少文件大小,又不会损失识别精度。
3. 为什么是 PCM 16-bit?
PCM(Pulse Code Modulation)是一种无损音频编码格式。相比MP3、AAC等有损压缩:
- ✅ 没有压缩损失
- ✅ 处理速度快(无需解码)
- ❌ 文件较大
但对于临时文件来说,文件大小不是问题,重要的是保证音质。
我的最终方案
基于以上分析,我确定了FFmpeg的完整命令:
ffmpeg -i video.mp4 \
-ar 16000 \ # 采样率 16kHz
-ac 1 \ # 单声道
-c:a pcm_s16le \ # PCM 16-bit 小端序
audio.wav
这个命令的每个参数都是经过推敲的,不是随便写的。
数据流程图
让我用图来表示音频提取的完整流程:
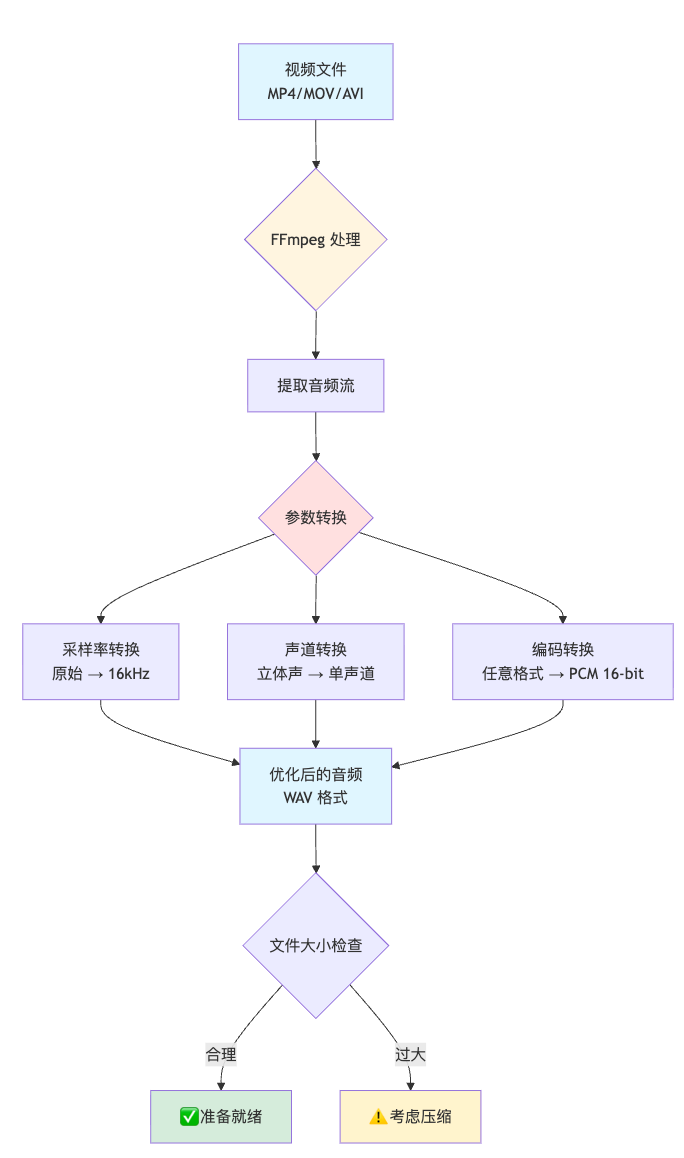
这个流程图清晰地展示了:
- 输入:各种格式的视频文件
- 处理:FFmpeg的三个关键转换步骤
- 输出:优化后的WAV音频文件
- 验证:文件大小检查
接下来,我应该如何进行语音识别?
有了音频文件后,下一步是把语音转成文字。这是整个流程中最核心、也是最复杂的一步。
我需要回答几个问题:
- 用什么模型? 开源还是商业API?
- 在哪里运行? 本地还是云端?
- 如何优化速度? CPU还是GPU?
方案对比
方案 A:使用商业API(如 Google Speech-to-Text、Azure Speech)
优点:
缺点:
- 💰 需要付费(按使用量计费)
- 🔒 隐私问题(音频上传到云端)
- 🌐 依赖网络(离线无法使用)
- ⏱️ 上传耗时(大文件传输慢)
方案 B:使用开源模型(Whisper)
优点:
- 🆓 完全免费
- 🔐 隐私安全(本地处理)
- 📡 离线可用
- 🎯 精度优秀(OpenAI训练)
缺点:
- 需要本地计算资源
- 首次需要下载模型
- 速度取决于硬件
这个选择看似简单,但我反复权衡了很久。
为什么不用商业API?
最初我确实考虑过用Google的API,毕竟NotebookLM本身就是Google的产品。但仔细一想,有几个问题:
- 成本问题:如果经常使用,费用会累积
- 隐私问题:NotebookLM的音频可能包含敏感信息
- 网络依赖:在没有网络的环境下无法使用
为什么选择 Whisper?
Whisper是OpenAI开源的语音识别模型,它有几个突出的优点:
- 精度高:在多个基准测试中接近商业API的水平
- 多语言:支持99种语言,包括中英文混合
- 开源免费:MIT许可证,可以随意使用
- 社区活跃:有很多优化版本和工具
但Whisper也有一个大问题:速度慢。
深入性能问题
Whisper有多慢?我做了一个测试:
- 测试文件:9分钟的视频
- 硬件:MacBook Pro M1 Max
- 模型:base模型(142MB)
结果:
- Python Whisper(CPU):约3分钟
- Whisper-CLI(Metal GPU):约18秒
10倍的性能差距!
这让我意识到:选择什么实现方式,比选择什么模型更重要。
Whisper的两种实现
Whisper有两个主要实现:
1. OpenAI官方版本(Python)
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.wav")
- 实现语言:Python + PyTorch
- 优点:官方维护,功能完整
- 缺点:速度较慢,依赖庞大
2. whisper.cpp(C++移植版)
whisper-cli -m ggml-base.bin -f audio.wav
- 实现语言:C++
- 优点:速度快,资源占用低
- 缺点:需要单独安装
为什么 whisper.cpp 这么快?
我深入研究了一下,发现主要有三个原因:
- C++ vs Python:C++的执行效率本身就比Python高
- 量化优化:使用4-bit/5-bit量化,减少内存占用
- 硬件加速:
- macOS:Metal GPU加速
- Linux:CUDA GPU加速
- 其他:SIMD指令集优化(AVX2、NEON)
跨平台的挑战
但这里有个问题:不是所有平台都支持GPU加速。
我需要考虑三种情况:
- macOS M系列:Metal GPU加速 → 极快
- NVIDIA GPU:CUDA加速 → 很快
- 其他平台:CPU模式 → 较慢
如果我只支持whisper.cpp,那么在没有GPU的平台上,用户体验会很差。
怎么办?
我想到了一个方案:自适应选择。
检测平台
↓
是否有 whisper-cli?
↓ 是 ↓ 否
使用 whisper-cli 使用 Python Whisper
↓ ↓
检测 GPU CPU模式
↓ ↓
Metal/CUDA加速 兜底方案
这样可以保证:
- ✅ 在最优环境下获得最佳性能
- ✅ 在任何环境下都能正常工作
- ✅ 用户无需手动配置
数据流程图:语音识别
让我画一个完整的语音识别流程图:
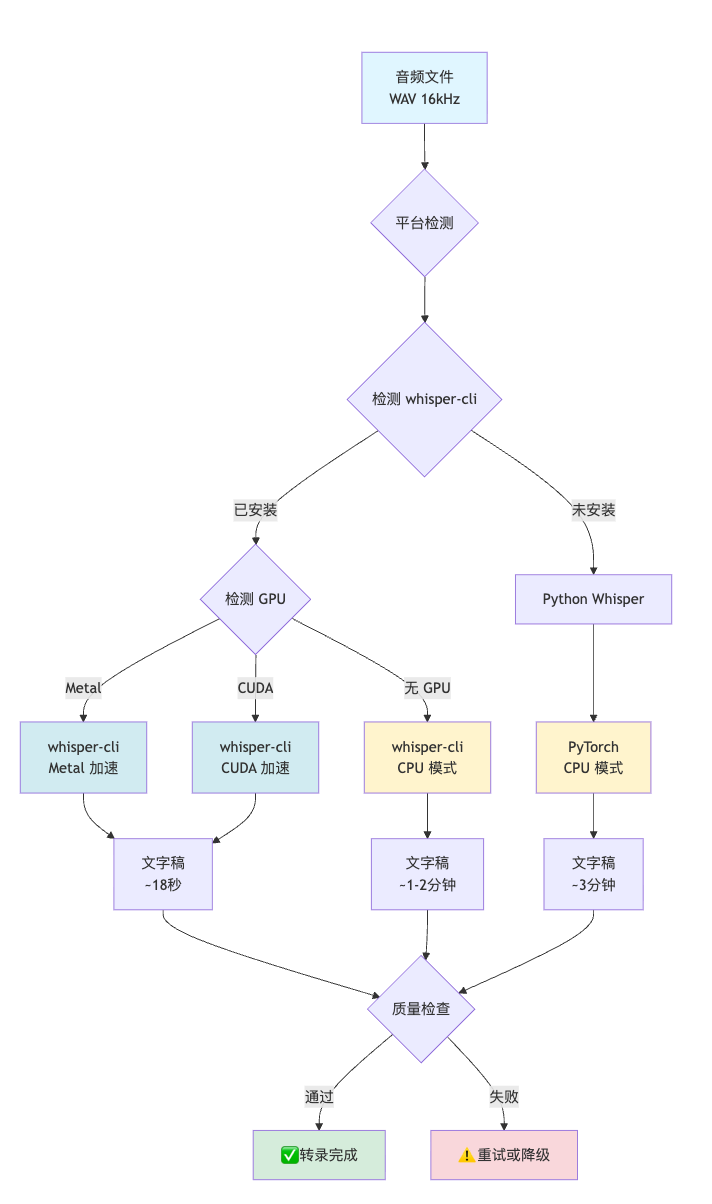
这个流程图展示了:
- 多路径选择:根据环境自动选择最优方案
- 性能分级:不同方案的速度差异
- 容错机制:失败后的重试逻辑
只剩下最后一步了,如何整理成文章?
现在我有了一份完整的文字稿,但它只是一段连续的文本,没有结构、没有重点。
我需要把它整理成一篇结构化的文章。这个选择其实不难。既然我已经用了AI来做语音识别,为什么不用AI来整理文章呢?
但关键问题是:用哪个AI?
我考虑了几个选项:
- GPT-5:质量好,但国内访问不便,且贵
- Gemini 3:质量好,但国内访问不便,且小贵
- Claude 4:质量好,但国内访问不便,且死贵
- DeepSeek:国产,便宜,中文理解好
为什么选择 DeepSeek?
直接说就是便宜,而且,对于整理文章这个任务,DeepSeek的质量完全够用。
Prompt 设计
选定了模型,下一步是设计prompt。这是整个流程中最需要“手艺”的部分。
一个好的prompt需要包含:
- 角色定位:告诉AI它是谁
- 任务描述:要做什么
- 输入格式:输入是什么样的
- 输出要求:输出应该是什么样的
- 风格指定:用什么风格写作
我设计了三种风格的prompt:
system_prompt = """你是一个科普作家。
你的任务是将专业内容转化为通俗易懂的文章。
要求:
1. 用简单的语言解释复杂概念
2. 多用比喻和例子
3. 避免过多专业术语
4. 保持轻松的语气
5. 适合非专业读者阅读
"""
这个项目让我学到的地方
整个项目完全开源免费,可以直接使用。这个过程让我学到了很多:
1. 系统设计的重要性
一开始我只想“把视频转成文字”,但真正动手后发现,这涉及:
- 音频处理
- 平台检测
- 性能优化
- API调用
- 错误处理
- 用户界面
每一个环节都需要仔细设计。
2. 性能优化的价值
从3分钟优化到18秒,这不仅仅是数字的变化,而是:
- 用户愿意等待 vs 用户直接放弃
- 可以实时使用 vs 只能批量处理
- 良好体验 vs 勉强可用
性能优化直接决定了产品的可用性。
3. 成本控制的必要性
从GPT-5切换到DeepSeek,成本降低200倍,这意味着:
- 可以免费提供服务 vs 必须收费
- 可以大量使用 vs 必须限制使用
- 可持续发展 vs 难以为继
成本控制决定了产品的商业模式。
写在最后
从一个简单的想法——“把NotebookLM的音频转成文字”,到一个完整的工具,这个过程充满了技术决策和权衡。
每一个决策背后,都是对问题的深入思考:
- 为什么这样做?
- 有没有更好的方案?
- 代价是什么?
- 值得吗?
这就是工程的魅力:在约束条件下,找到最优解。
希望这篇文章能给你一些启发。如果你也有类似的想法,不妨动手试试。技术的乐趣,就在于把想法变成现实。欢迎在云栈社区交流你的想法和开发心得。
项目地址:GitHub - transcribe_video
相关资源:
 发表于 2026-2-7 10:39:05
|
查看: 253|
回复: 0
发表于 2026-2-7 10:39:05
|
查看: 253|
回复: 0
