自 2023 年将 duckdb-rs 交由 DuckDB 官方维护后,我心里一直悬着一个未完成的课题:如果 DuckDB 在单机进程内已经足够强大,那么,如何将这份能力转化成一个更易接入、可部署、可观测的服务?
SwanLake 就是我为这个问题准备的答案。
它本质上是一个基于 Rust 的 Arrow Flight SQL 服务器,底层执行引擎是 DuckDB,并围绕 DuckLake 扩展了数据湖场景的能力。更精确地说,SwanLake 的核心技术栈组合是 DuckDB + DuckLake + Arrow Flight SQL。
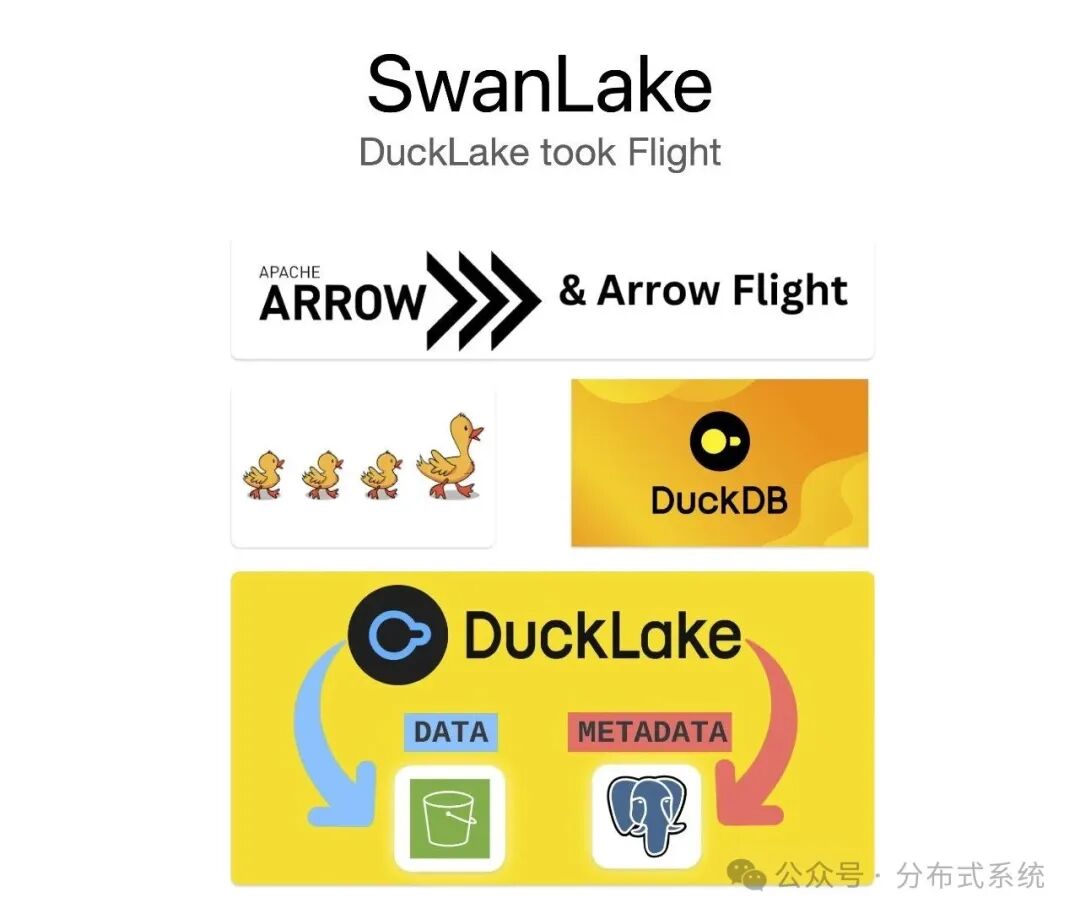
为什么是 SwanLake?
我最初开发 duckdb-rs 时,目标是让 DuckDB 更自然地融入 Rust 生态。这个目标后来基本实现了,但新的问题也随之浮现:
- 许多团队并非纯 Rust 技术栈,客户端需要一种统一的接入方式。
- 业务中常见的不只是“本地查询”,更需要处理对象存储、元数据管理以及多服务协作。
- 线上系统必须具备可观测性,不能仅依赖日志进行故障排查。
因此,SwanLake 从立项之初就不是简单的“再封装一层 API”,而是致力于构建一个能够真正进入生产环境的分析服务入口。
系统架构浅析
SwanLake 的系统可以划分为五层来理解:
1. 接入层:Arrow Flight SQL(gRPC)
服务对外通过 Arrow Flight SQL 协议暴露接口,所有查询和更新请求均经此进入。该协议的核心价值在于跨语言兼容性与高吞吐,项目仓库中的 Rust、Go、Python 示例均围绕此层展开。
2. 会话层:Session Registry
swanlake-core 模块实现了连接级别的会话管理:
- 根据
peer_addr 或 peer_ip 生成或复用会话 ID。
- Prepared statement、事务以及临时对象都与会话生命周期绑定。
- 通过最大会话数和空闲超时等机制进行资源保护。
3. 执行层:DuckDB
执行层并未重复造轮子,而是将 DuckDB 封装为服务可用的执行引擎。每个会话持有独立的 DuckDB 连接,启动时会自动加载 ducklake、httpfs、aws、postgres 等扩展,并支持通过 SWANLAKE_DUCKLAKE_INIT_SQL 环境变量注入初始化 SQL。
4. 数据湖层:DuckLake
DuckLake 是系统中最关键的一层。没有它,DuckDB 更偏向于一个本地分析引擎;而有了 DuckLake,元数据和对象存储路径便得以统一组织。正是这一层,使得 SwanLake 能够将“基于 DuckDB 构建数据湖”的理念,落地为可部署的服务方案。
5. 运维层:Metrics + Status + 配置
运行时指标(延迟、慢查询、错误)、状态页(/ 及 /status.json)和环境变量配置(SWANLAKE_*)共同构成了系统的运维面。这一层的设计目标是确保系统上线后可观测、可调优、可回滚。
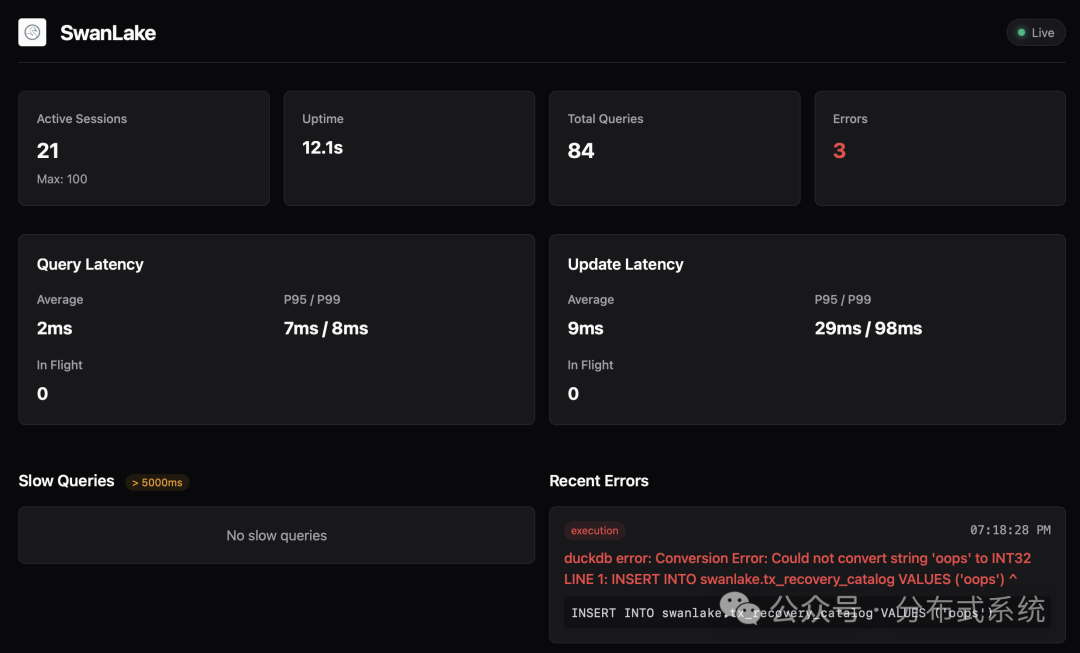
开箱即用的可观测性
SwanLake 内置了状态页(默认运行在 :4215 端口)和 status.json 端点,能够清晰展示:
- 当前活跃会话数、会话空闲时长等状态信息。
- 查询(Query)与更新(Update)操作的延迟统计(平均、P95、P99)。
- 正在发生的慢查询以及最近的错误详情。
开发这个页面并非单纯为了“界面美观”,而是因为它恰恰是我在排查线上问题时,最希望第一时间获取的信息集合。
如何看待当前的性能测试数据?
项目仓库中的 BENCHMARK.md(数据截至 2026-02-21)包含了一组 TPCH(SF=0.1)的测试结果:在此轮测试中,postgres_local_file 配置的性能表现优于 postgres_s3。
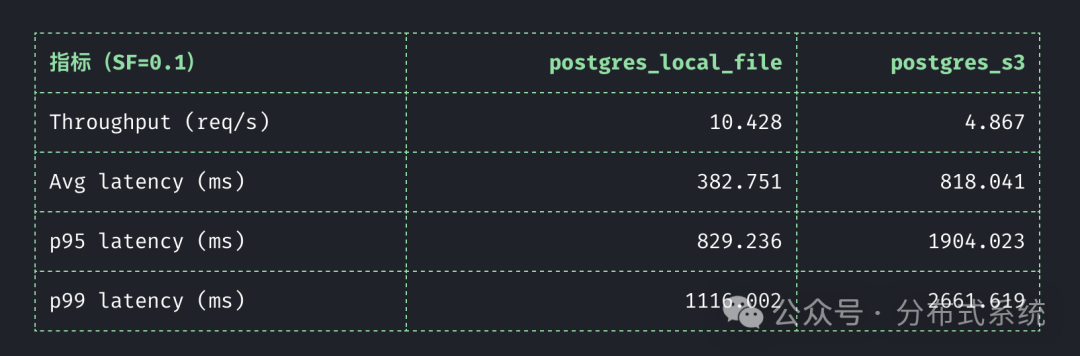
这个结果在预期之内:对象存储链路确实会引入更高的网络延迟与不确定性。
这里有一个非常重要的实践建议:如果后端使用的是 S3 或其他远程对象存储,建议默认启用 cache_httpfs 选项。否则,查询延迟(尤其是尾部延迟 P99)将会非常不稳定。这一优化策略已被整合进项目的基准测试流程中,具体配置可查看 .github/workflows/performance.yml 文件:
postgres_s3 测试默认设置 BENCHBASE_ENABLE_CACHE_HTTPFS=true。postgres_local_file 测试默认设置 BENCHBASE_ENABLE_CACHE_HTTPFS=false。- 也可以通过 workflow 的输入参数显式覆盖该配置。
但我不想简单地将结论归结为“本地存储一定优于远程存储”。更准确的实践认知应该是:
- 需要根据实际工作负载进行数据分层(热数据、本地缓存、远端对象存储)。
- 需要反复运行基准测试以观察性能方差,而非仅凭单次结果决定架构。
- 需要将性能指标转化为持续可见的监控数据,而非一次性报告。
从 duckdb-rs 到 SwanLake 的思考
如果说 duckdb-rs 解决了“如何让开发者在 Rust 中优雅地使用 DuckDB”的问题,那么 SwanLake 试图解决的是另一个层面的问题:如何将 DuckDB 转变为一个团队可共享、可部署、可运维的数据服务。
对我而言,这两个项目是同一条技术演进路线上的不同阶段,而非彼此孤立的尝试。它们共同体现了从单机工具到可扩展服务的工程化探索。
后续迭代方向
SwanLake 仍在持续演进中,接下来我会重点关注以下几个方面:
- 继续完善生产环境下的稳定性验证与压力测试数据。
- 进一步优化面向对象存储场景的性能表现与可预测性。
- 统一客户端与服务端的使用体验,降低不同技术栈的接入门槛。
如果你曾是 duckdb-rs 的用户,我非常欢迎你尝试 SwanLake,无论是提交 Issue、PR,或是直接分享你在使用中遇到的任何问题。更多技术细节与实时动态,也欢迎在 云栈社区 的 数据库/中间件/技术栈 等板块进行交流探讨。
参考链接
 发表于 2026-2-27 03:48:51
|
查看: 384|
回复: 0
发表于 2026-2-27 03:48:51
|
查看: 384|
回复: 0
