“老板问:为什么数据团队10个人,报表还是慢、成本还越来越高?”
这往往不是团队能力问题,而是架构问题的集中体现。
2025年至2026年,我们看到无数中小企业陷入了“大数据内耗”的困境。以我们监控的实际数据为例,一个典型的Hadoop集群月均成本超过6万元,但其中80%的时间实际上处于空转状态。Hive查询一张表可能需要3分钟,业务方根本等不及。数据工程师一半的时间消耗在修复集群、核对数据和调整参数上。更令人头疼的是,如果想上实时分析,还得额外搭建 Flink + ClickHouse 等一整套组件,每月成本再增5万元……
最终的结果是:数据越堆越多,技术债务越来越重,但业务能感知到的价值却越来越低。
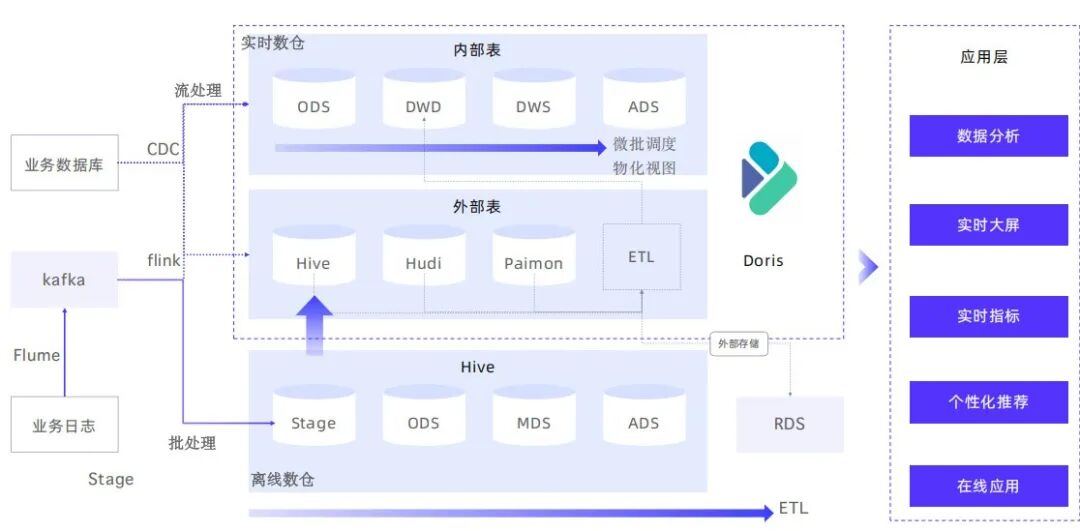
注:本文探讨的“停用Hadoop”,特指停用自建的 HDFS 存储 + YARN 资源调度集群,并非抛弃整个大数据生态。原有的 Hive SQL、Spark ETL 等数据处理逻辑仍然可以复用。
一个真实的转折点:年省87万的架构升级
某中型电商公司(年GMV约8亿元,日均订单50万以上)在2025年底进行了一次关键性的架构升级,他们的做法是:
- 停用整套 HDFS + YARN 集群
- 将数据迁移到 Apache Doris + 对象存储(OSS) 架构
- 保留原有的SQL开发习惯,核心ETL逻辑几乎无需改造
最终效果令人印象深刻:
- 典型交互式报表查询速度:从 2分30秒 提升至 1.8秒
- 月均成本:从 7.2万元 降低至 9800元
- 年节省成本:87万元以上
- 最直观的改善:数据工程师终于能在下班前轻松交付日报。
为什么 HDFS+YARN 不再适合大多数中小团队?
我们通过一个简单的对比表格来直观感受:
| 维度 |
传统 Hadoop (HDFS+YARN) |
新架构 (Apache Doris + OSS) |
| 存储成本 |
默认三副本,存储成本实际×3 |
OSS采用纠删码,冗余度约1.2倍 |
| 计算弹性 |
存算一体,机器需常开以保服务 |
存算分离,按需查询,秒级弹性响应 |
| 运维复杂度 |
需要专职Hadoop工程师维护 |
架构扁平,云托管可大幅降低基础设施负担 |
| 实时能力 |
需额外搭建 Flink + Kafka 等流处理栈 |
Doris原生支持实时数据写入与更新 |
| BI工具兼容 |
通常需要中间层进行协议转换 |
可直接对接 Tableau、QuickBI 等主流BI工具 |
核心洞察:Hadoop 最初是为“超大规模、稳定吞吐”的场景设计的,并非为追求“敏捷、低成本”的中小团队业务而设计。当然,在PB级、高吞吐的批处理场景,它依然是可靠的选择。(注:HDFS 自 3.0 起支持纠删码,冷数据存储成本可降至约1.5倍,但这会带来额外的管理和运维开销。)
新架构如何搭建?(极简三步法)
这次平滑迁移的关键,在于利用了 Apache Doris 2.0+ 版本成熟的 Multi-Catalog 功能。这套方案在2026年已经非常稳定。
步骤1:将历史数据迁移至对象存储 (如OSS/S3)
将HDFS上的历史数据一次性迁移到云上对象存储,作为数据湖基底。

步骤2:部署 Apache Doris(社区版免费)
- 3台中等配置的机器(如16核64G内存)即可支撑日均十亿行级别的查询压力。
- 在Doris中开启 HMS (Hive Metastore) External Catalog,使其能够直接读取OSS上以Parquet/ORC格式存储的数据表。建议为热查询开启本地缓存以加速。
步骤3:实现统一查询入口
利用Doris的联邦查询能力,业务方无需感知数据物理位置,一条SQL即可同时查询实时数据和历史冷数据。
-- 一条SQL同时查询实时表与存储在OSS的历史表
SELECT dt, SUM(gmv)
FROM (
SELECT dt, gmv FROM doris_db.realtime_orders -- 实时数据表
UNION ALL
SELECT dt, gmv FROM hive_catalog.oss_db.orders_historical -- OSS上的历史外部表
) t
GROUP BY dt;

至此,业务查询实现无感切换,SQL几乎无需改动。
避坑指南:来自一线的血泪经验
- 不要尝试全量一次性迁移:建议采用“先冷后热”的策略,优先迁移超过30天的冷数据,热数据再通过双写或逐步切换的方式平滑迁移。
- OSS权限管理使用RAM Role:避免在配置文件中直接使用AK/SK,采用云平台提供的RAM角色进行授权,安全性更高。
- 为Doris开启本地缓存:可以为Doris BE节点配置SSD作为缓存层,避免频繁读取OSS对象存储带来的查询延迟波动。
- 保留HMS元数据服务:这样能最大程度兼容现有的 Airflow、DolphinScheduler 等任务调度系统,减少运维改造工作量。
展望:2026年大数据架构的新范式
- 存算分离成为标配:以 OSS/S3 作为统一的数据湖,以 Doris/StarRocks 等高性能分析型数据库作为数据仓库,构建“湖仓一体”架构。
- Serverless 化降低门槛:主流云厂商已推出“按查询付费”的Doris服务,真正做到 0运维、0闲置成本,进一步降低了中小团队的使用门槛。
- AI增强优化体验:自动索引推荐、智能物化视图(Apache Doris 2.1已集成)等功能,让系统越用越快。
- 中小团队的技术红利:这意味着,用更低的成本和更精简的团队,也能获得接近大厂水平的交互式数据分析体验。
这套思路,其实也呼应了2026年所倡导的“新质生产力”内核——通过数智化、绿色化和架构轻量化来驱动业务高质量发展,摒弃过去那种盲目堆砌资源、效率低下的“添油战术”。
结语:技术的价值在于解放生产力
文章开头的那个案例,省下的远不止87万元的真金白银,更是团队每天数小时被无效运维、漫长等待所消耗的宝贵生产力。
2026年,大数据技术不应该成为业务发展的负担,而应成为撬动增长的杠杆。选对架构,用对工具,即使是小团队,也能释放出巨大的数据价值。关于数据仓库架构的更多实践与思考,欢迎在 云栈社区 与广大开发者们继续交流。 |  发表于 2026-2-9 11:50:03
|
查看: 249|
回复: 0
发表于 2026-2-9 11:50:03
|
查看: 249|
回复: 0
