在现代数据仓库体系中,DWD(明细数据层)和 DWS(汇总数据层)是承上启下的关键环节。DWD 层负责明细数据的清洗与标准化,而 DWS 层则聚焦于面向分析场景的轻度或高度聚合。二者之间的衔接质量,直接决定了下游 BI、报表、用户画像乃至 AI 模型的数据可用性与响应效率。
本文将系统拆解从 DWD 到 DWS 的完整建设路径,结合真实项目经验,提供可落地的避坑建议、典型场景案例及性能优化策略。
一、DWD 与 DWS 的核心定位
| 层级 |
定位 |
数据粒度 |
主要任务 |
| DWD |
明细数据层 |
原子事件级别(如一次点击、一笔订单) |
清洗、脱敏、维度退化、统一口径、保留原始业务语义 |
| DWS |
聚合服务层 |
分析主题级别(如用户日行为、店铺月GMV) |
轻度/高度聚合、宽表构建、指标预计算、支撑高频查询 |
关键认知:DWS 不是简单地对 DWD 做 GROUP BY,而是围绕“分析主题”进行有目的的建模。
二、从 DWD 到 DWS 的建设步骤(五步法)
步骤1:明确分析主题与指标体系
- 输入:业务需求文档、BI 报表清单、用户画像标签需求。
- 输出:DWS 主题域划分(如“用户行为”、“交易分析”、“商品运营”)。
- 关键动作:
- 梳理原子指标(如“支付金额”)、派生指标(如“7日复购率”)。
- 确定维度组合(如“按用户+日期+渠道”)。
示例:电商场景下,“用户日活宽表”需包含:用户ID、日期、首次/末次访问时间、页面浏览数、下单次数、支付金额等。
步骤2:设计 DWS 表结构(宽表 or 多事实表?)
- 推荐模式:以“一个主题一张宽表”为主(Kimball 宽表思想)。
- 字段构成:
- 维度字段(退化维度 + 关联维度)。
- 原子指标(来自 DWD)。
- 派生指标(可在 DWS 计算,也可留到 ADS 层)。
- 注意:避免过度宽表(字段 > 200),可考虑垂直拆分。
步骤3:ETL 逻辑开发(SQL / Spark / Flink)
- 原则:
- 仅依赖 DWD 层,不跨层引用 ODS 或 ADS。
- 使用分区字段(如
dt)控制增量更新。
- 保证幂等性(支持重跑)。
- 示例 SQL 片段(用户日行为聚合):
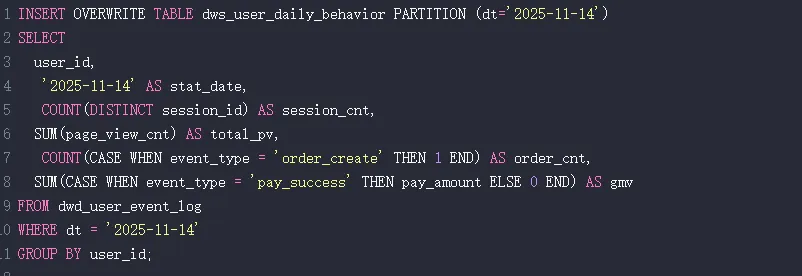
步骤4:数据质量校验
- 校验项:
- 主键唯一性(如
user_id + dt 是否重复)。
- 指标合理性(GMV 是否突增?)。
- 空值率监控(关键字段缺失率 < 0.1%)。
- 工具建议:Great Expectations、自研数据血缘与质量平台。
步骤5:建立血缘与元数据管理
- DWS 表必须标注:
- 来源 DWD 表。
- 每个字段的业务含义、计算逻辑。
- 更新频率(T+1 / 实时)。
- 价值:便于问题追溯、影响分析、成本治理。一个完善的 数据治理 体系是保障数仓健康运行的基础。
三、避坑指南:8 大高频陷阱
| 坑点 |
风险 |
解决方案 |
| 1. 直接在 DWS 做复杂业务逻辑 |
逻辑耦合、难以维护 |
复杂逻辑下沉至 DWD 或独立 UDF |
| 2. 忽略数据倾斜 |
Spark 任务 OOM、跑批超时 |
对高频 key(如超级用户)做 salting 或单独处理 |
| 3. 宽表无限膨胀 |
查询性能下降、存储成本飙升 |
按热度拆分(核心字段 vs 长尾字段) |
| 4. 指标口径不一致 |
同一指标在不同报表结果不同 |
建立指标字典,DWS 字段命名带版本(如 gmv_v2) |
| 5. 全量覆盖而非增量更新 |
资源浪费、无法支持历史修正 |
使用 MERGE INTO(Hive 3+ / Iceberg)或 CDC 方案 |
| 6. 忽视冷热分离 |
存储成本高 |
热数据存 SSD,冷数据转低频存储(如 OSS) |
| 7. 未考虑实时场景 |
无法支持分钟级看板 |
构建 Lambda 架构:批流双写 DWS |
| 8. 缺乏权限与生命周期管理 |
数据泄露、僵尸表堆积 |
设置自动归档策略(如 180 天未访问自动冻结) |
四、实战案例:某电商平台“用户交易宽表”建设
背景
业务方需要一张表支撑“用户生命周期价值(LTV)”分析,要求包含:
- 用户基础属性(性别、注册渠道)。
- 每日交易行为(订单数、退款率)。
- 优惠券使用情况。
- 复购间隔。
DWD 准备
dwd_user_info:用户主数据(每日快照)。dwd_trade_order:订单事实表(含状态变更)。dwd_coupon_use:优惠券使用日志。
DWS 设计
表名:dws_user_trade_daily
| 字段 |
来源 |
说明 |
user_id |
dwd_user_info |
主键 |
dt |
分区字段 |
日期 |
reg_channel |
dwd_user_info |
退化维度 |
order_cnt |
dwd_trade_order |
当日成功订单数 |
refund_rate |
dwd_trade_order |
退款订单 / 总订单 |
coupon_used_cnt |
dwd_coupon_use |
使用优惠券次数 |
days_since_last_order |
计算字段 |
基于历史订单计算 |
优化亮点
- 复用中间表:先构建
dws_user_order_agg 再 join 用户属性,避免大表笛卡尔积。
- 预计算 LTV 分段:增加字段
ltv_level(高/中/低),减少下游计算压力。
- 支持回溯:通过拉链表记录用户属性变更,确保历史数据一致性。
五、性能与成本优化策略
1. 存储优化
- 列式存储:Parquet/ORC + Z-Order 排序(按
user_id, dt)。
- 压缩算法:Snappy(平衡 CPU 与压缩比)。
- 分区策略:
dt 分区 + 分桶(user_id 分 100 桶)。
2. 计算优化
- 向量化执行:Spark 启用 vectorized reader。
- 谓词下推:确保 WHERE 条件能下推到 DWD 层。
- 物化视图(可选):对高频查询模式预建 MV(如 Doris / ClickHouse)。
3. 成本治理
- 生命周期管理:DWS 表保留 365 天,超期自动归档。
- 资源隔离:DWS 任务调度优先级低于 ADS,避免抢占 BI 资源。有效的 资源与配置管理 是控制成本的关键。
- 用量监控:按团队统计 DWS 表存储/计算消耗,推动“谁使用谁负责”。
六、结语:DWS 是艺术,更是工程
DWD 到 DWS 的过程,本质上是从业务原始数据到分析语言的翻译。优秀的 DWS 层应具备三个特征:
- 一致性:指标口径统一,避免“同名不同义”。
- 高效性:90% 的常规查询可在 3 秒内返回。
- 可扩展性:新增指标不影响现有结构。
记住:不要为了建模而建模,要为业务价值而建模。每一张 DWS 表背后,都应该有一个清晰的“被谁用、解决什么问题”的答案。
本文探讨了大数据领域经典的数仓分层建模实践,更多关于数据科学、云计算与人工智能的深度讨论,欢迎访问 云栈社区 进行交流与学习。 |  发表于 2026-1-12 23:32:16
|
查看: 220|
回复: 0
发表于 2026-1-12 23:32:16
|
查看: 220|
回复: 0
