要抓住偷偷占用内存空间的“小偷”,首先得摸清它的作案场地——内存。对于程序而言,内存并非一个简单的硬件配件,而是一个即时存取的高效仓库,所有运行时的数据都需在此临时存放。若没有它,软件启动或许需要等待数十秒甚至数分钟。

深入内存仓库,你会发现两个核心区域:共享的Page Cache(页缓存)和专属的RSS(常驻内存集)。这两个区域的使用规则截然不同,也直接决定了内存泄漏的作案目标。
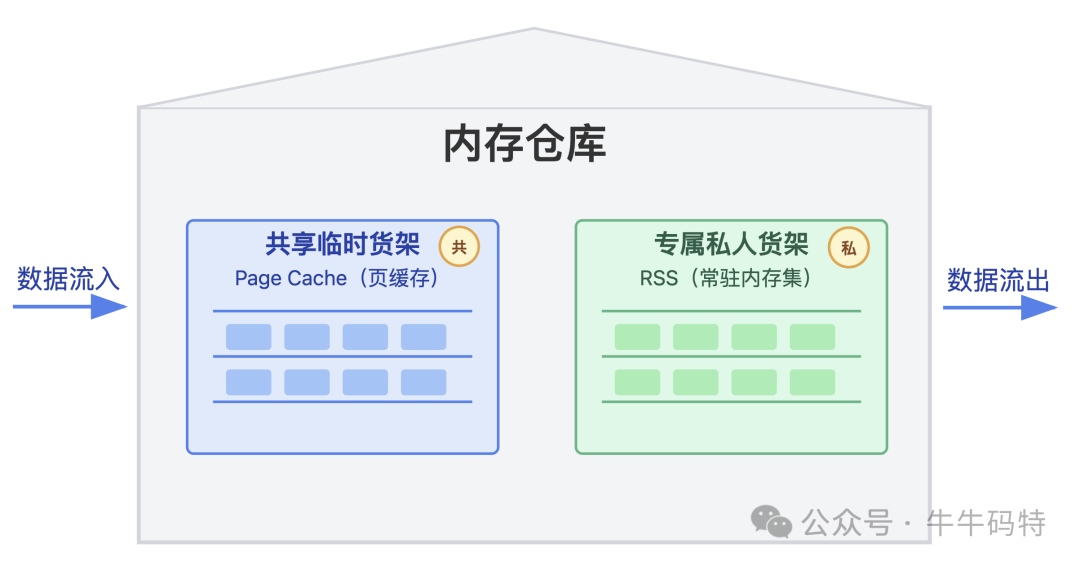
1. 共享临时货架:Page Cache
Page Cache 是系统的公共货架,专门存放各类“临时周转物料”,例如刚读取的日志文件或已关闭的文档缓存。这些数据驻留于此的核心目的,是让进程下次访问时无需再次访问缓慢的硬盘,直接从内存读取,从而大幅提升访问速度。
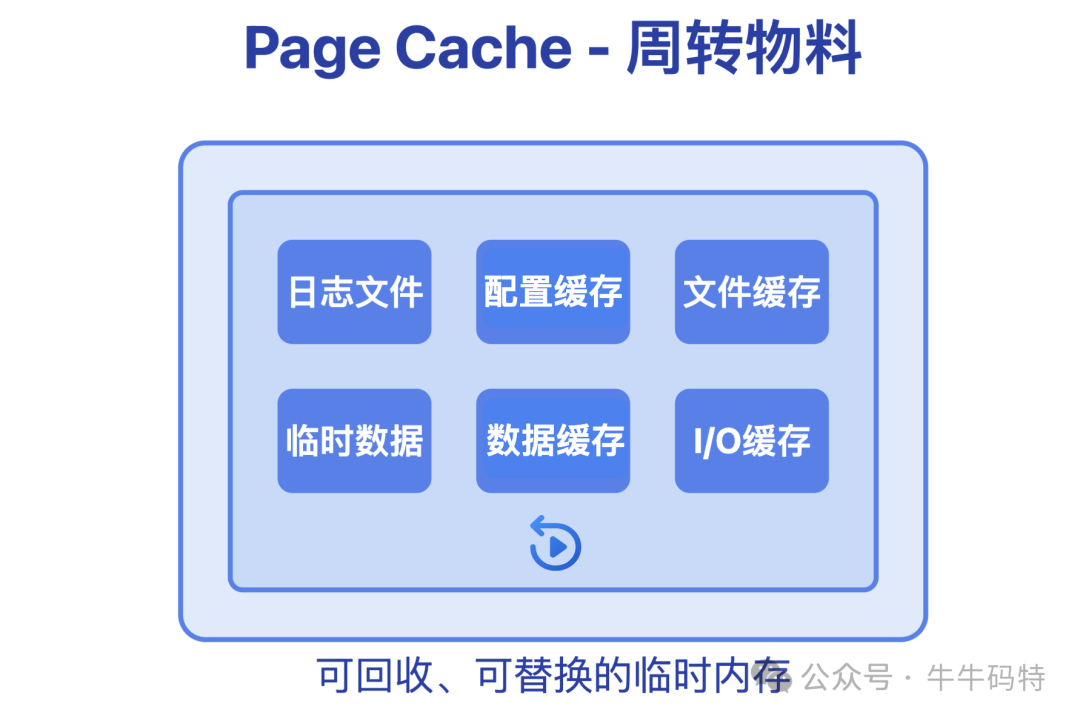
这个货架的关键特点是可回收、可替换。一旦系统察觉内存紧张,便会主动扮演“管理员”的角色,整理这个货架:将暂时用不上的数据移回硬盘或直接清理,为更急需的RSS空间或其他进程腾出位置。
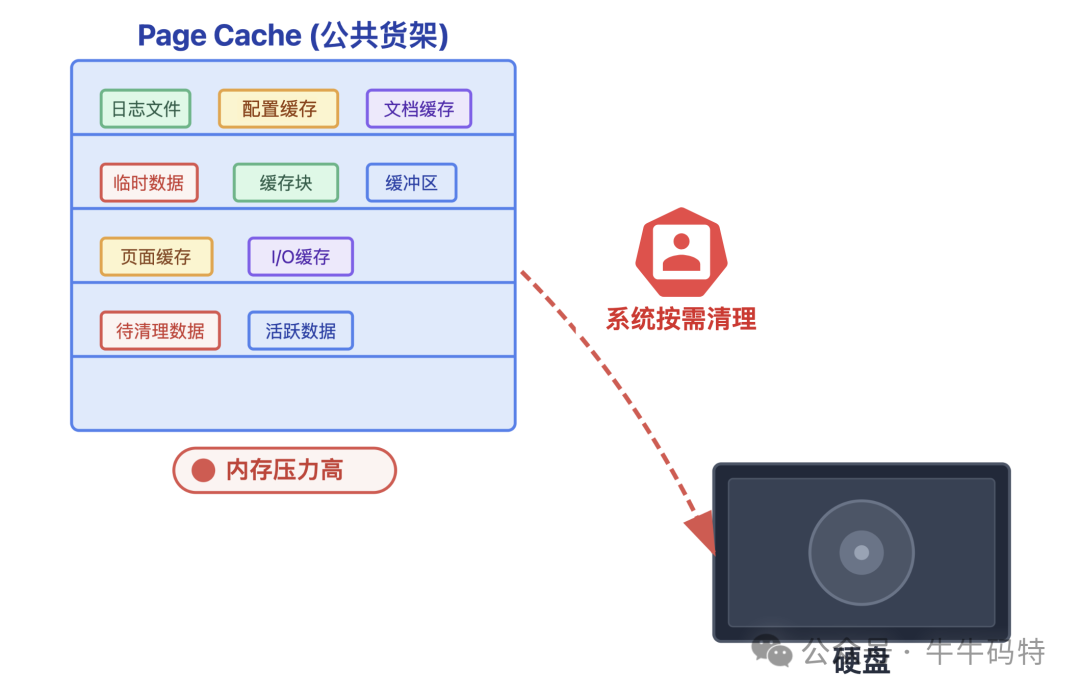
正因为这种动态清理机制,内存泄漏对这里毫无兴趣——在此处堆放无用数据,很可能刚放上就被系统回收,属于在“管理员眼皮底下作案”,风险极高。
RSS(Resident Set Size)是程序的专属私人货架,空间完全由单个程序支配。里面存放的是程序运行的“必需品”,例如正在执行的业务代码、处理中的中间数据以及核心依赖。
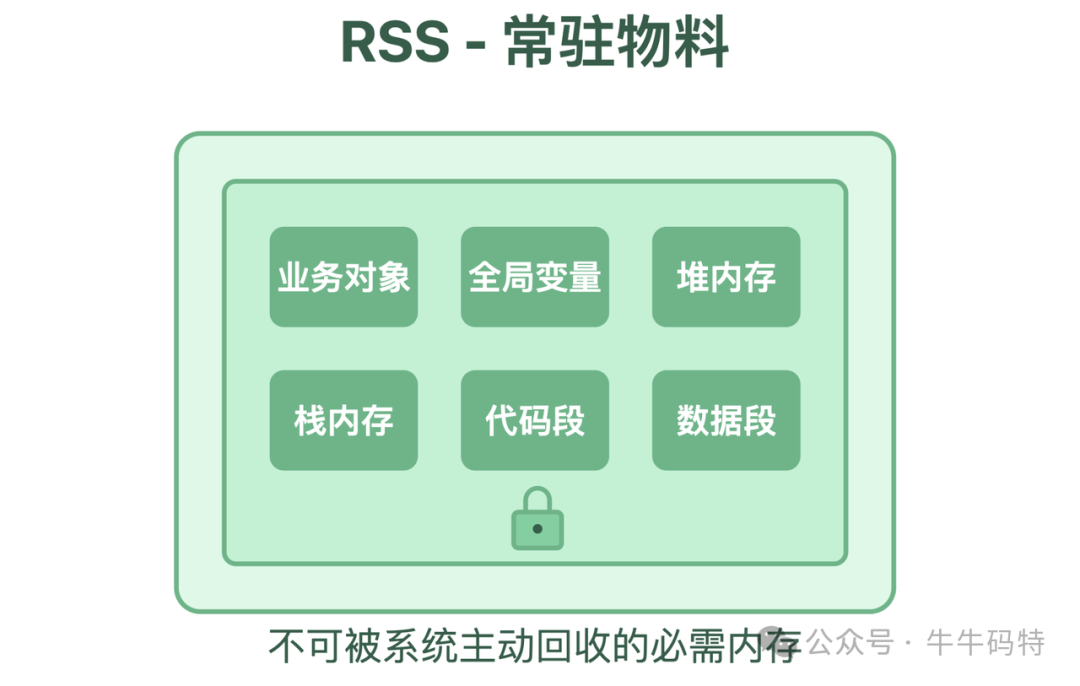
这里为何成为内存泄漏的“完美犯罪现场”?两个致命优势:
- 专属空间无监管:RSS是程序的私人领域,操作系统无权随意清理。只要将垃圾堆在这里,就不用担心被系统“扫地出门”。
- 空间占用稳定:程序默认RSS上的所有数据都是有用的,一旦占用就不会主动释放。这种“占住即拥有”的特性,让泄漏可以悄然发生,逐步侵蚀内存。
因此,内存泄漏的核心问题,几乎都出在RSS这个私人专属货架上。
内存泄漏的“四步作案”流程
内存泄漏导致程序卡顿并非一蹴而就,而是一个“小剂量、高频次”的渐进过程,其作案流程可清晰拆解为四步。
第一步:潜伏观察,摸清规律
在程序启动初期,泄漏会先潜伏起来,观察程序的运行规律:任务处理周期、内存释放习惯、以及哪些冷门代码逻辑很少被检查。这些都是未来可以利用的漏洞。
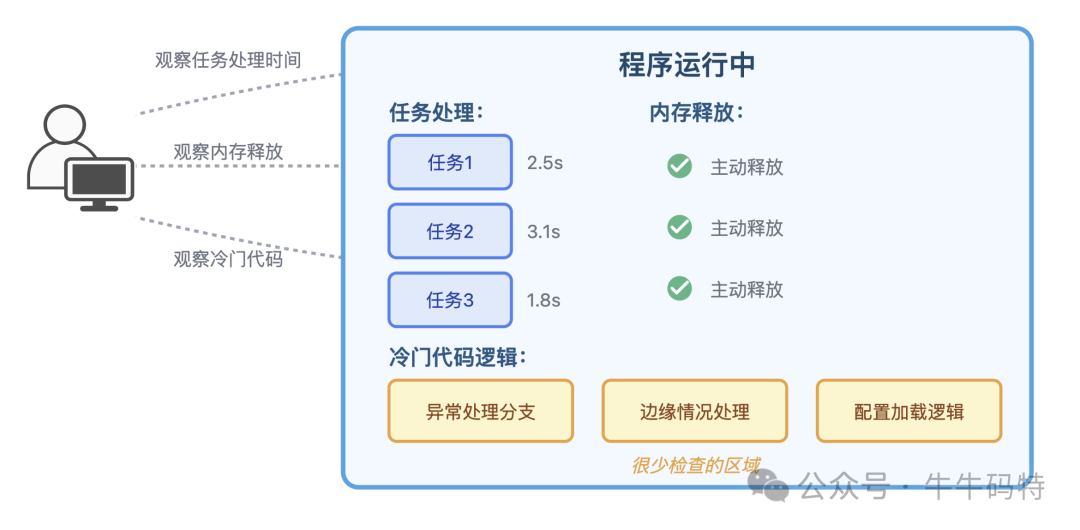
此阶段为程序初始化,系统分配初始RSS内存,内存占用稳定,宛如一条平直的线。
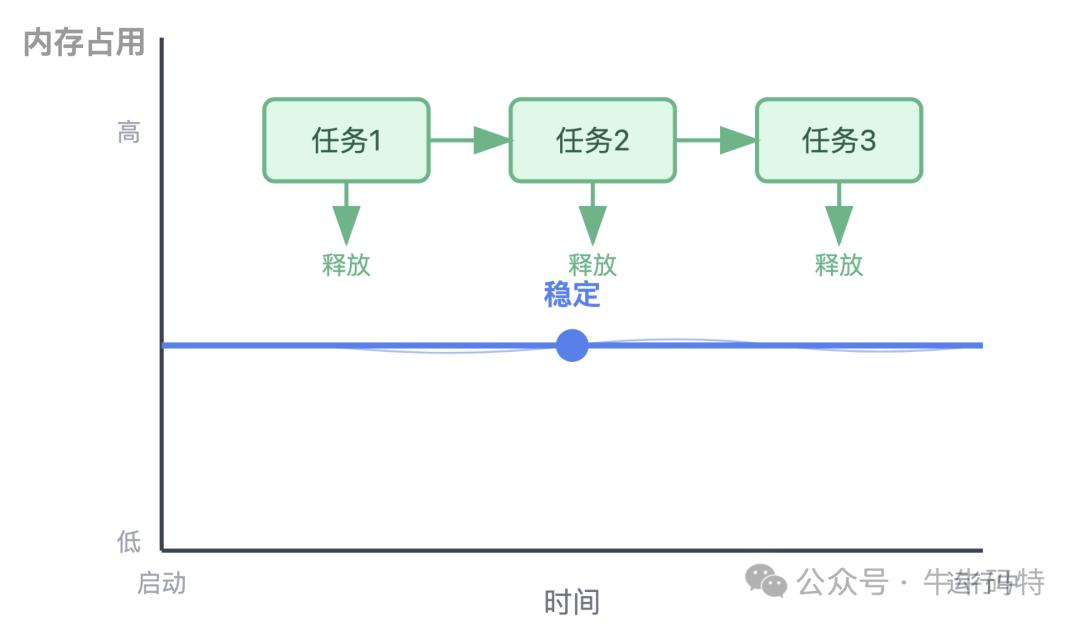
这只是暴风雨前的宁静,“小偷”正在暗中等待时机。
第二步:试探下手,囤积数据
当程序开始处理任务时,“小偷”开始试探。本应在使用后及时清理的临时数据(如处理完的订单缓存、计算中的中间结果),由于业务逻辑复杂或编码疏忽而未被释放。
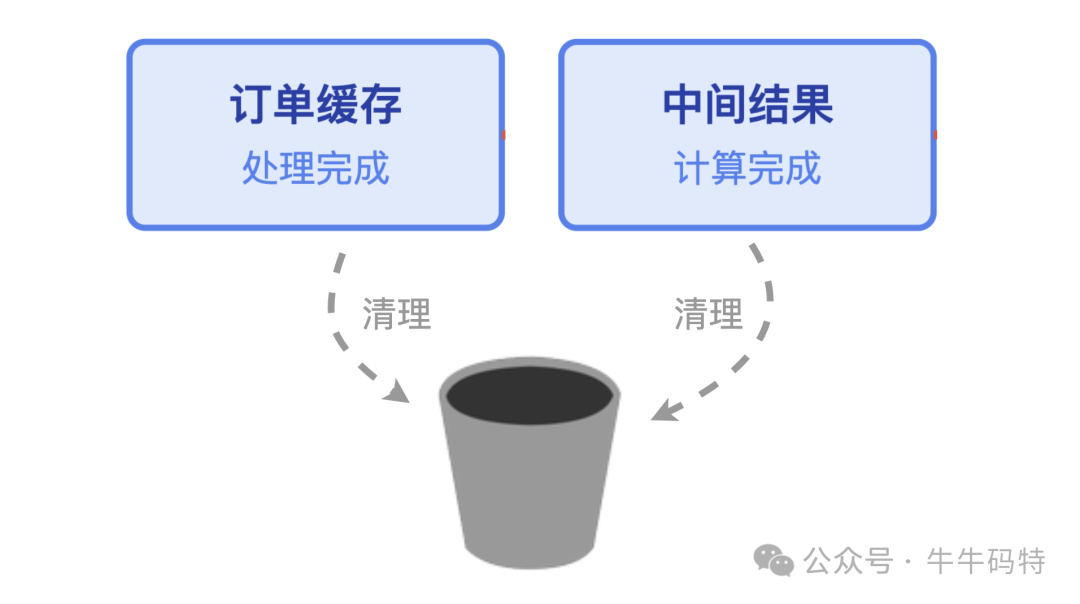
这个微小漏洞被“小偷”抓住,它将首批未被释放的无效对象留在了RSS空间里。
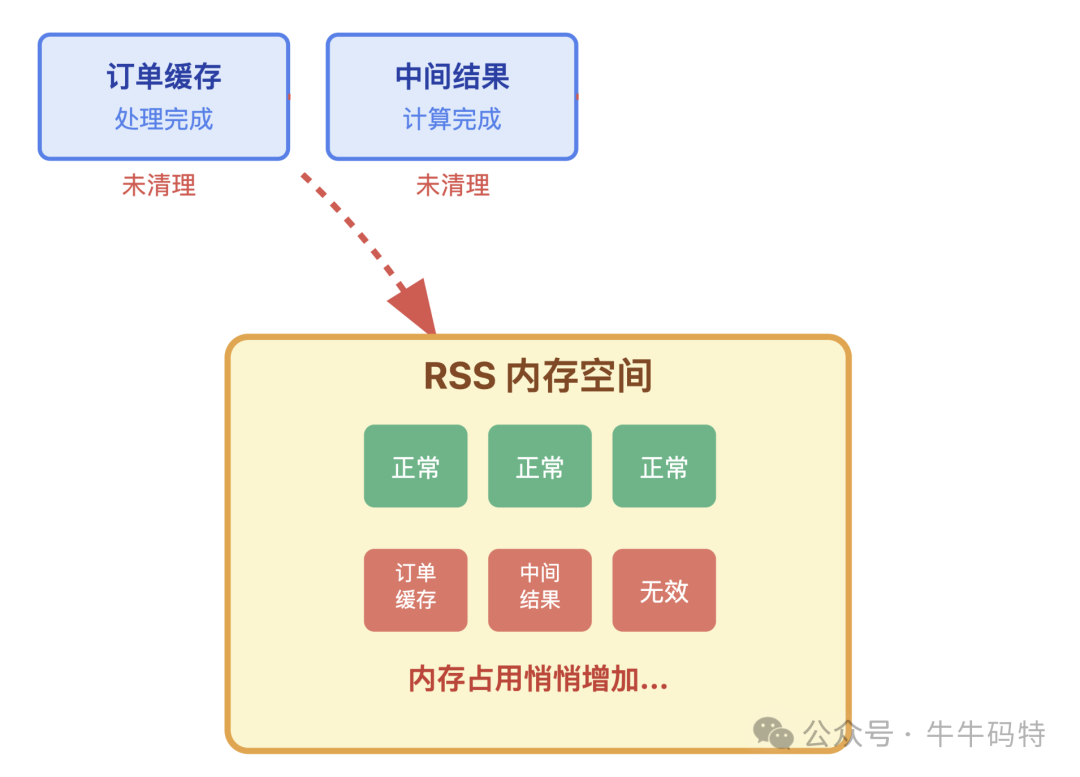
此时内存尚宽裕,小幅上涨不易察觉,你可能只觉得程序“有点迟钝”,并将其归咎于网络或后台程序过多。
第三步:疯狂囤积,内存告急
发现“藏垃圾无人管”后,“小偷”开始规模化作案。一旦程序进入高负载状态(如APP使用高峰、服务端处理大量请求),它便开启“疯狂囤货”模式。
无论是循环处理订单、接收用户请求还是生成报表,每次业务循环都会创建新对象。但由于漏洞存在,这些对象未被释放,在RSS中如滚雪球般越积越多。
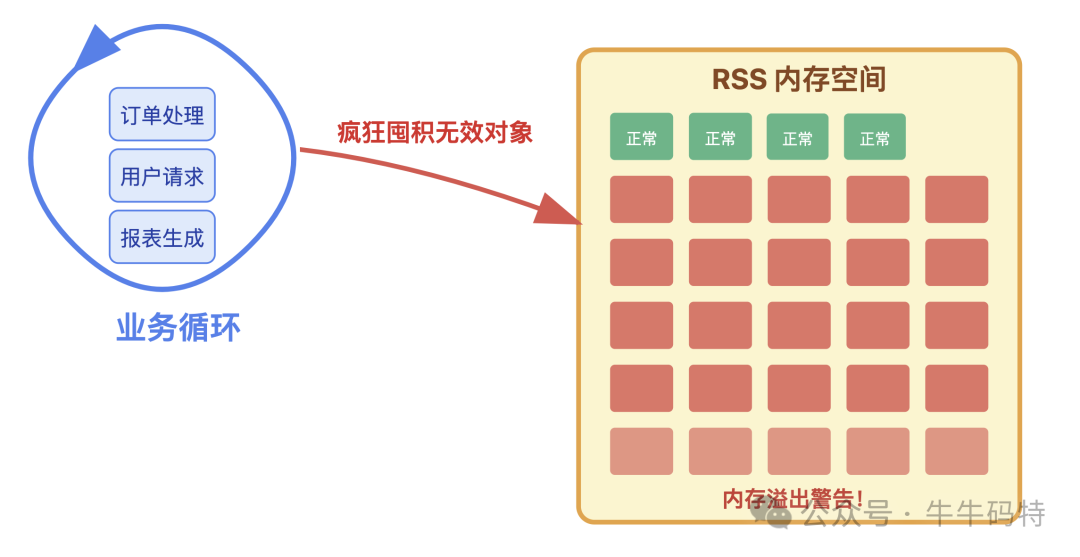
此时内存占用曲线呈“陡峭上升”趋势。程序卡顿加剧:页面加载需数秒,按钮响应“慢半拍”,服务端接口超时甚至报错。

操作系统会尝试清理Page Cache腾出空间,但这无济于事,因为被占满的是它无权插手的RSS专属空间。
第四步:空间耗尽,内存溢出(OOM)
当“囤货”行为持续,RSS空间被彻底偷光,系统迎来瘫痪时刻。为防止整个系统崩溃,操作系统会启动应急预案——OOM Killer(内存溢出杀手)机制。
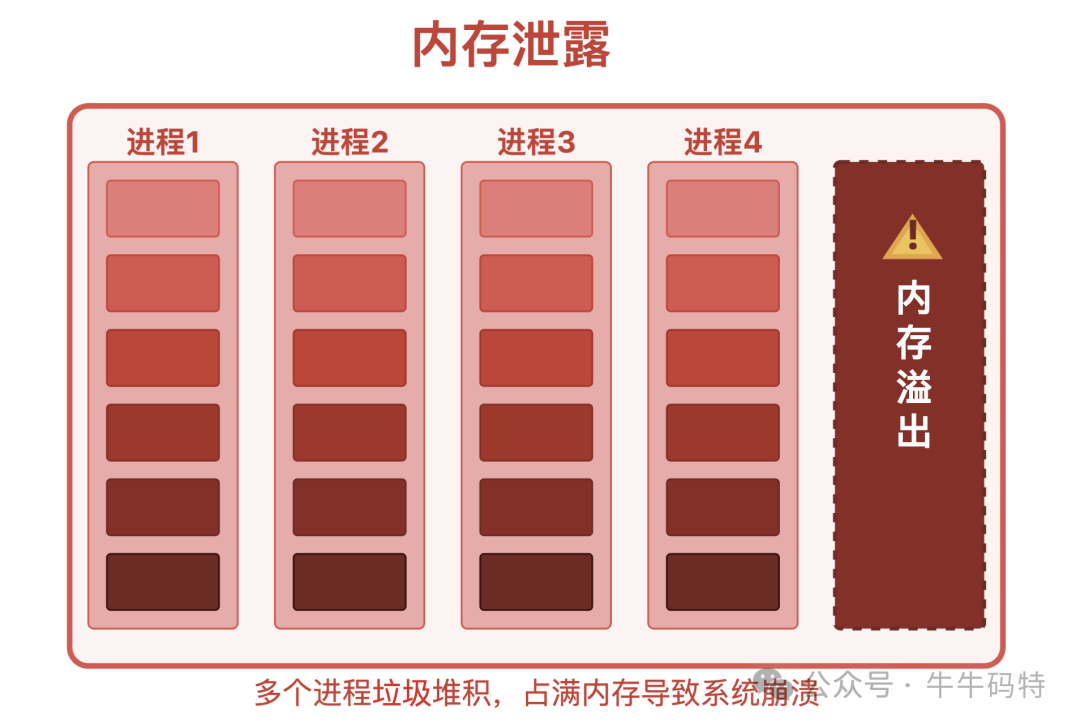
此机制会强制终止那个“占用空间最多的进程”,即有内存泄漏问题的程序。

外在表现为程序彻底失控:客户端APP闪退,服务端程序被“杀死”,并在系统日志中留下 Out of memory: Killed process 的记录。
如何揪出内存“小偷”的破绽?
内存泄漏会在进程和系统两个层面留下蛛丝马迹,通过监控工具即可精准定位。
进程层面的线索
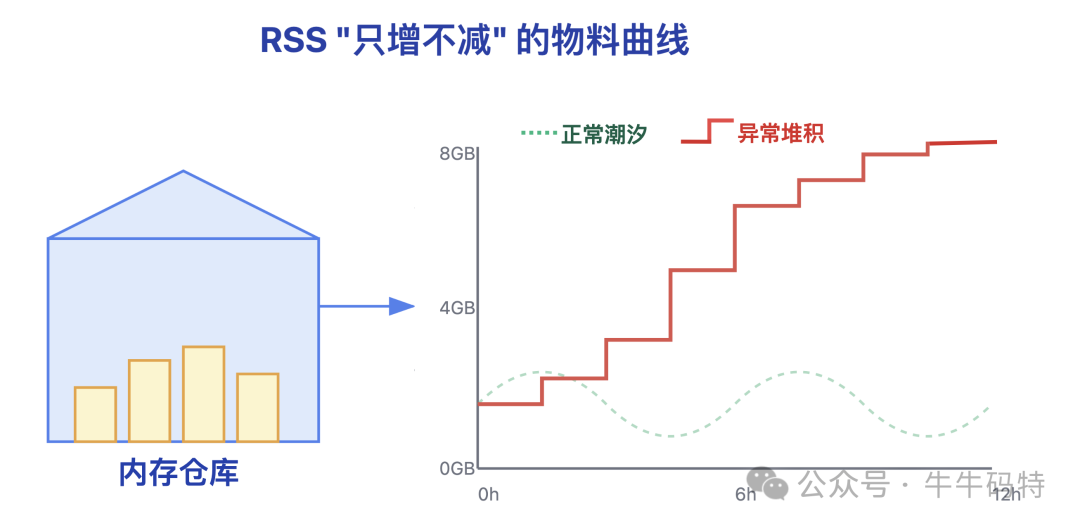
1. RSS内存“只增不减”
正常程序的内存占用如“潮汐”,有涨有落。存在泄漏的程序则如“爬山”,只上不下。使用 top (Linux) 或任务管理器 (Windows) 观察目标进程内存变化即可发现。
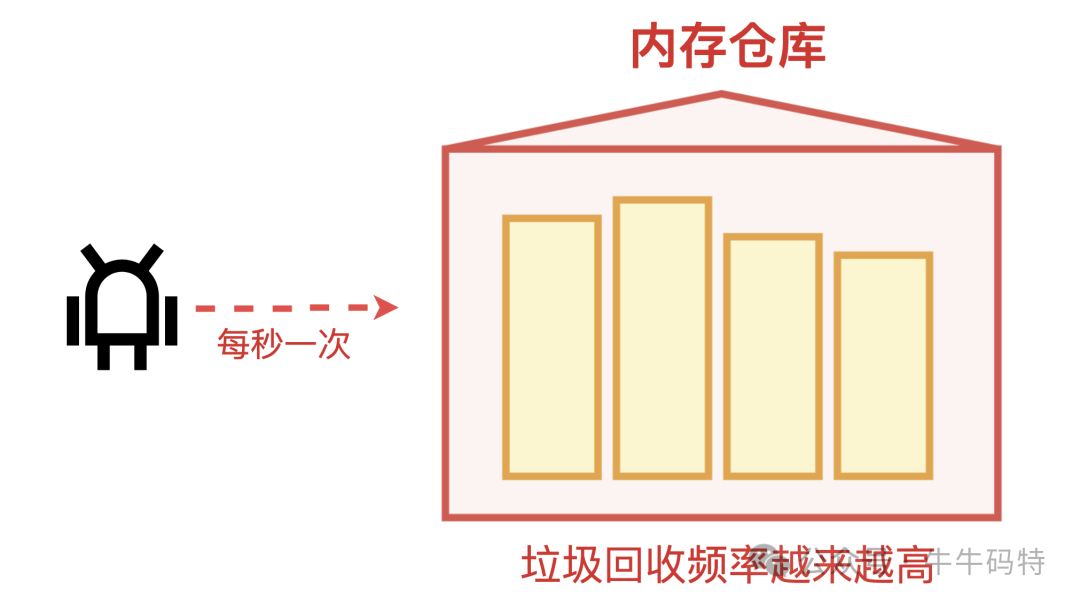
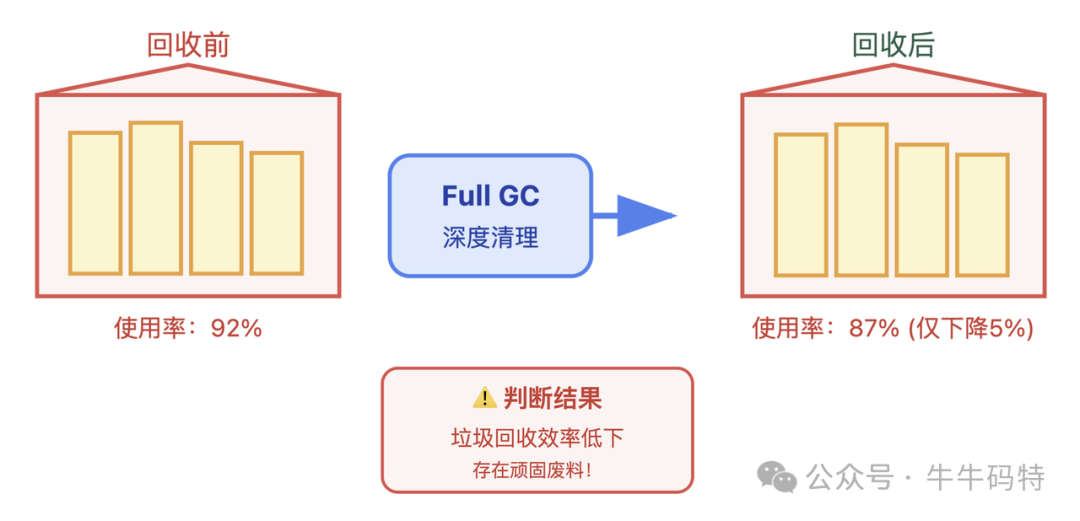
2. 垃圾回收(GC)“忙而无效”
对于Java、Python等带垃圾回收机制的语言,可观察GC日志。若发现Full GC(彻底清理)次数激增、耗时变长,但回收的内存却越来越少,说明大部分空间已被泄漏对象占据,GC无力回天。
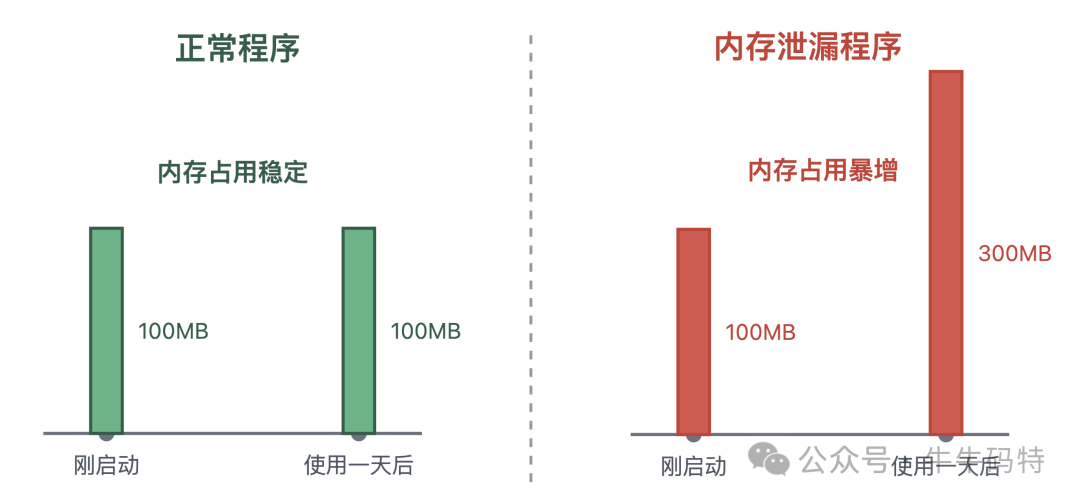
3. 内存与工作量不匹配
处理相同任务,内存占用应基本稳定。若程序运行一段时间后,处理同等工作量所需内存大幅增加(例如从100MB增至300MB),多出的部分很可能就是泄漏的垃圾。
系统层面的异常信号
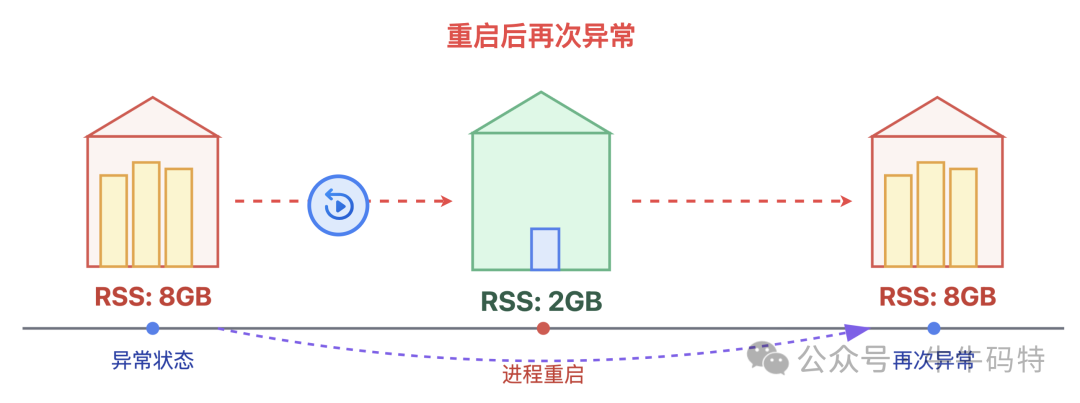
1. 可用内存“重启恢复,运行复涨”
观察系统可用内存(Linux free,Windows资源监视器)。若关闭问题程序后内存回升,重启该程序后内存又持续攀升,说明泄漏逻辑仍在。
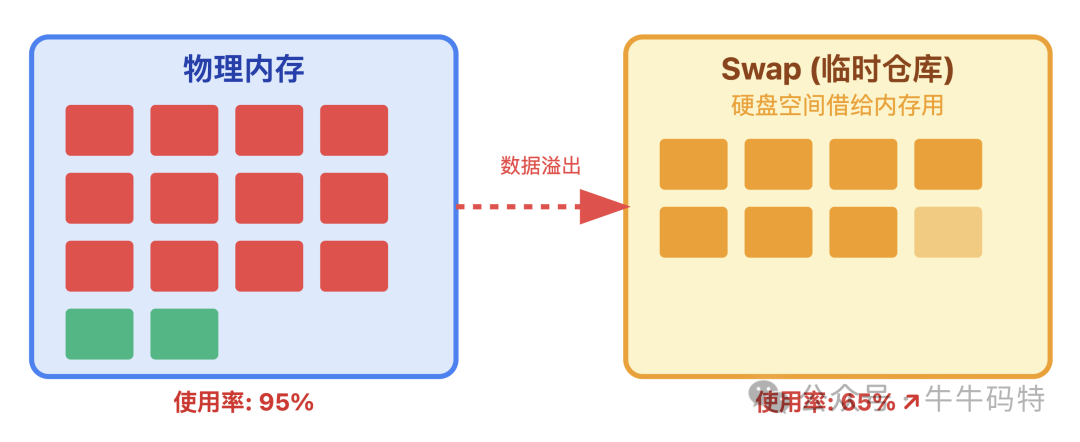
2. Swap使用率异常飙升
当物理内存不足时,系统会使用硬盘空间作为“临时仓库”,即Swap。硬盘速度远慢于内存,一旦Swap使用率持续超过50%并上涨,程序会明显卡顿,硬盘灯常亮。
3. 系统日志出现OOM记录
这是最终警告。使用命令 dmesg | grep -i oom 查看日志,若发现 Out of memory: Killed process [PID],表明程序已因内存泄漏被系统终止。

内存“防盗”实战手册
发现泄漏后,应按照“紧急修复 -> 日常巡检 -> 源头设防”的逻辑应对。
第一招:紧急修复,抢回空间
当程序已卡顿或崩溃时,首要目标是紧急止损。
- 重启程序:最直接有效的方法,能彻底清空RSS空间。重启前建议使用
jmap (Java) 或 tracemalloc (Python) 等工具导出内存快照,为后续分析保留证据。
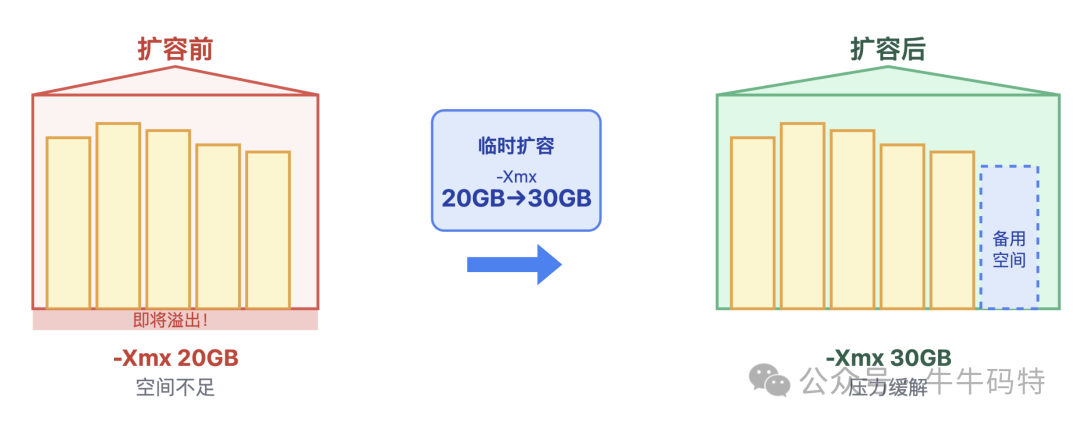
- 临时扩容:若重启影响业务,可临时增加进程内存上限。例如,将Java启动参数
-Xmx 从20G调整为30G。但这仅是缓兵之计,必须尽快根治。

第二招:日常巡检,守住阵地
建立监控防线,防患于未然。
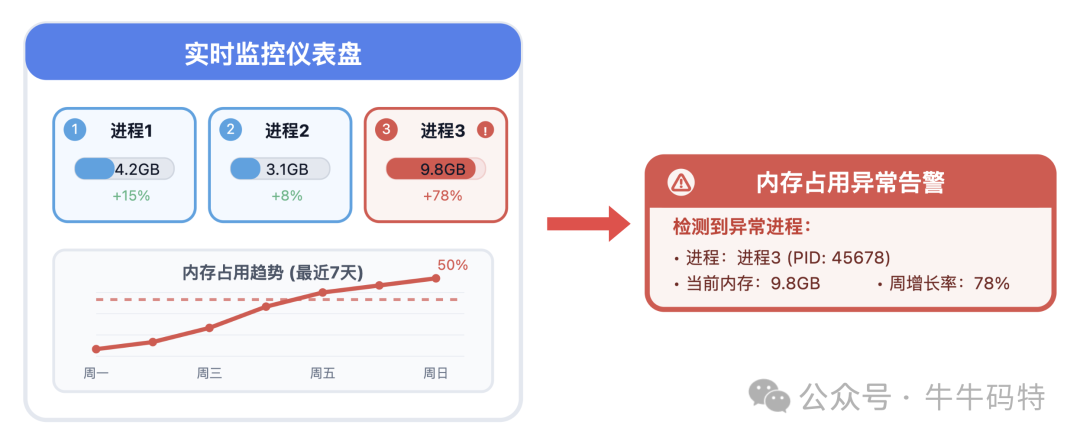
- 趋势监控:使用Prometheus等工具持续监控进程RSS指标,设置报警规则(如周增长率超50%)。一旦内存异常爬升,立即报警。
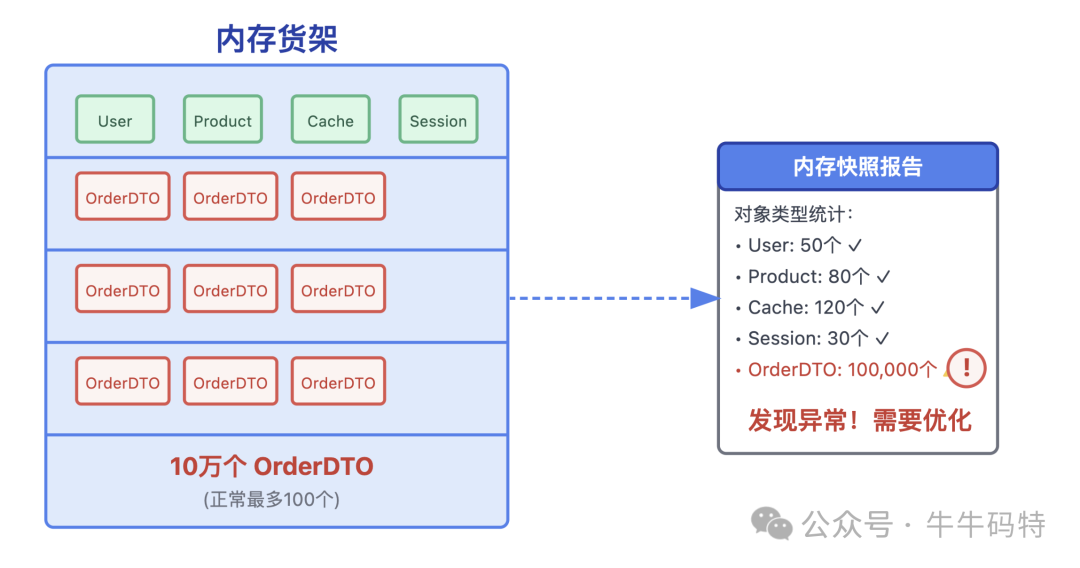
- 定期快照分析:定期导出内存快照,分析对象实例数量。若发现某类对象(如OrderDTO)数量远超正常值(例如10万个对比正常100个),则存在泄漏风险,需提前优化。
第三招:源头设防,杜绝漏洞
最根本的解决之道是从编码和架构层面预防。
- 即用即清:对文件流、网络连接等资源,必须确保使用后及时关闭。采用
try-with-resources (Java) 或 with 语句 (Python) 实现自动管理。
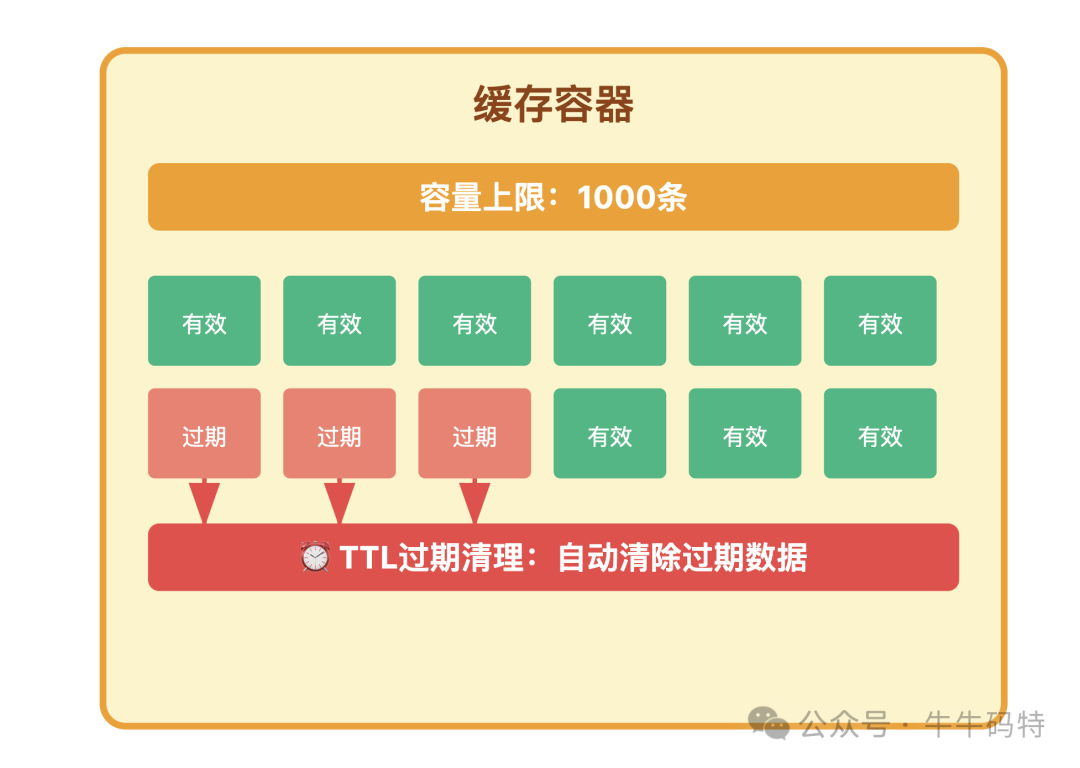
- 缓存管控:为缓存容器(如Redis、本地缓存)设置容量上限和TTL(过期时间),防止无效数据无限堆积。
- 依赖审计:定期升级第三方库至已修复内存管理问题的版本,并移除项目未使用的依赖,减少外部引入的风险。

总结
内存泄漏这个“隐形小偷”并不可怕,它总会留下“只涨不跌”的内存曲线、“忙而无效”的GC日志、“越用越少”的可用空间等破绽。本质上,它利用了程序在操作系统内存管理机制下的漏洞和我们的疏忽。
根治之道在于像管理仓库一样管理内存:及时清理无用数据,合理规划缓存与资源,并建立持续的监控体系。如此,方能确保你的应用始终保持在高效、清爽的运行状态。
如果你对系统底层原理、性能优化等话题有更多兴趣,欢迎在云栈社区交流探讨。
 发表于 2026-3-3 11:21:11
|
查看: 162|
回复: 0
发表于 2026-3-3 11:21:11
|
查看: 162|
回复: 0
