
一、什么是 Skill?
1.1 定义
Skill(技能)是一个包含指令文档、参考资料和可执行脚本等资源的文件夹。AI 获取它之后,就能掌握一项原本不具备的特定工作能力。
举个例子,一个 pdf-editor 技能文件夹里,可能包含一份“如何处理 PDF”的操作指南、一个旋转 PDF 的 Python 脚本以及一份 API 参考文档。AI 无需再从外部寻找任何信息,这个文件夹里已经应有尽有。
这个概念并不局限于某个特定产品。无论是 OpenAI Codex、Claude 还是其他 AI Agent,Skill 的本质是相同的。你可以将其理解为 AI 的 能力插件 —— 插上它,AI 就多了一项专长;拔掉,AI 则恢复为通用助手。
1.2 最小形态
一个 Skill 最少只需要一个文件:

SKILL.md 的结构非常简单 —— 上半部分告诉 AI“什么时候使用我”,下半部分告诉 AI“具体如何操作”:
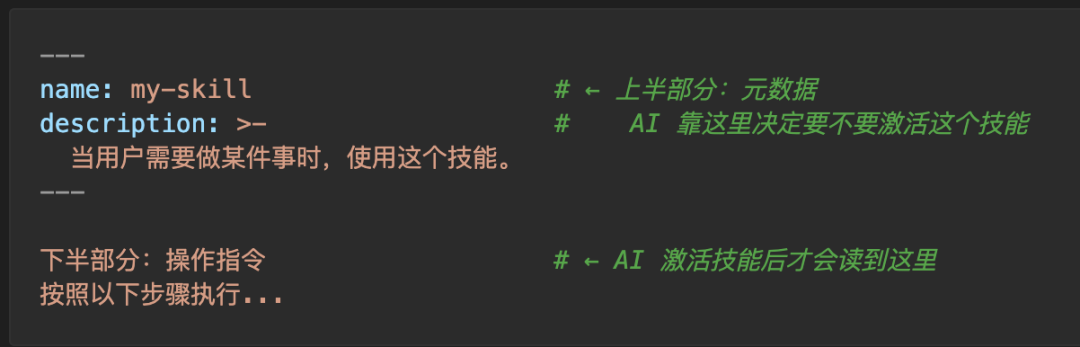
上半部分称为 frontmatter(两个 --- 之间的 YAML 区域),包含 name 和 description 两个必填字段。AI 在每次对话开始时,都会扫描所有已安装技能的 frontmatter,并根据 description 来判断“当前请求是否与该技能相关”——这是技能被触发的唯一入口。
下半部分称为 body(Markdown 正文),是技能被激活后才会加载的具体操作指令。如果技能未被触发,AI 永远不会读取这部分内容。
1.3 完整结构
当技能变得复杂时,仅靠一个 SKILL.md 文件就不够了。
例如,你需要创建一个“PDF 处理”技能:SKILL.md 中描述了处理流程,但旋转 PDF 的代码逻辑是确定且重复的。与其每次让 AI 重新编写(既耗时又可能出错),不如直接放入一个预先写好的 Python 脚本。再比如“前端项目生成器”技能:每次都需要一套 HTML/React 的样板文件,不如直接提供一个模板目录供 AI 复制和修改。
因此,一个完整的 Skill 目录可以包含以下内容:
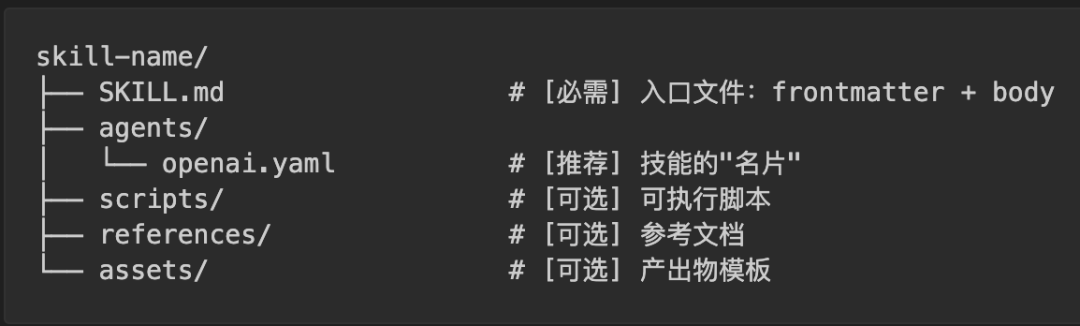
逐一说明:
SKILL.md — 唯一必需的文件,结构已在前文介绍。scripts/ — 存放预先写好的程序。AI 无需理解其代码逻辑,只需直接调用 Shell 执行即可。例如 scripts/rotate_pdf.py,AI 只需运行 python rotate_pdf.py input.pdf 90 就能旋转 PDF,无需每次重写旋转逻辑。这适用于那些 结果必须精确、不允许 AI 自由发挥 的操作。references/ — AI 在工作过程中可能需要查阅的参考资料。例如,一个“BigQuery 查询”技能,AI 需要知道公司有哪些数据表、每个表的字段结构。这些信息可以放在 references/schema.md 中,供 AI 在需要时读取。它与 scripts/ 的区别在于:references 是给 AI 阅读和理解 的,而 scripts 是给 AI 执行 的。assets/ — 不是给 AI “阅读”的,而是直接用于最终产出的文件。例如,一个“前端项目生成器”技能,可以在 assets/frontend-template/ 中存放一套 HTML/React 样板代码,AI 直接复制这套模板并在其上修改。再比如 assets/logo.png 是公司 logo,AI 在生成网页时可直接引用。AI 不需要“读懂”一张图片,只需知道它的位置以及何时放入产出物中。agents/openai.yaml — 技能的“名片”。许多 AI 产品会在用户界面上展示一个技能列表。这个 YAML 文件存储的正是列表中显示的名称、简介、图标等信息。它不影响 AI 的核心行为,主要是为了产品界面展示所用。
二、你是在给人写指令,还是在给 AI 写指令?
了解了 Skill 是什么,下一步就是编写它。但很多人首次写出的 Skill 都存在一个共性问题。
看一个例子。假设要创建一个“代码审查”技能,你可能会这样写:
---
name: code-review
description: 代码审查技能
---
# Code Review Skill
## 背景
本技能基于团队多年的代码审查经验总结而成,旨在提升代码质量和团队协作效率。
## 审查原则
- 保持专业、建设性的语气
- 关注代码质量而非个人风格
- 平衡严格性和灵活性
## 使用方式
当用户提交代码时,对代码进行全面审查,给出改进建议。注意保持友好和鼓励的态度。
## 版本记录
- v1.0: 初始版本
- v1.1: 增加了对 Python 的支持
如果这是一份面向人类团队成员的文档,它写得不错 —— 有背景、有原则、有使用方式,甚至还有版本记录。
但 Skill 的读者是 AI。从这个视角重新审视:
- “基于团队多年经验总结” — AI 不关心这个技能是如何诞生的,它只需要知道 现在该怎么做。
- “保持专业、建设性的语气” — 人类读者能大致理解这种感觉,但 AI 会把“专业”和“建设性”理解为无数种可能性的组合,导致每次输出都不稳定。
- “平衡严格性和灵活性” — 经验丰富的人类审查者知道何时该严格、何时该灵活,但 AI 没有这种直觉,这句话等于没有提供有效信息。
- “全面审查,给出改进建议” — 这是对人类审查者的期望,但 AI 需要的是具体步骤:先检查什么?再检查什么?哪些问题是必须指出的?哪些问题可以忽略?
- “版本记录” — 每次 AI 被唤醒都是一个全新的会话,v1.0 还是 v1.1 对它没有实际意义。
description 只写了“代码审查技能” — AI 完全依赖 description 来判断是否触发技能。“代码审查技能”这五个字过于模糊:用户说“帮我看看这段代码”要触发吗?“这个函数性能怎么样”要触发吗?
单独看每一条似乎都没问题,但它们都是在 给人写指令。问题的关键不在于写得不够多,而在于 写错了对象。
那么,正确的写法是什么样的?我们可以从一个现成的范本中找到答案——OpenAI Codex 的 skill-creator。它是一个“创建 Skill 的 Skill”,它自身的 SKILL.md 就是一份关于“如何给 AI 写指令”的 最佳实践指南。
三、skill-creator 的整体框架
打开 skill-creator 的 SKILL.md(约 370 行),在深入任何细节之前,我们先建立对它的整体认知。
skill-creator 要解决的核心问题只有一个:如何在有限的上下文窗口内,为 AI 提供最有效的指令?
围绕这个问题,它构建了一套完整的设计体系,可以从三个层次来理解。
第一层:根本约束 —— 简洁
AI 的上下文窗口是有限的,并且是共享的(系统提示、对话历史、所有已安装技能的元数据都占用其中)。你的技能占用的空间越多,留给其他用途的空间就越少。因此,skill-creator 的第一原则是:每一句话都值得它占用的 token。
第二层:两个核心设计维度
在“简洁”这一根本约束下,编写 Skill 时面临两个核心决策:
维度一:信息放在哪里?
并非所有信息都需要在对话开始时一次性全部加载。skill-creator 设计了一套三级分层架构,让不同的信息在不同的时机进入上下文:
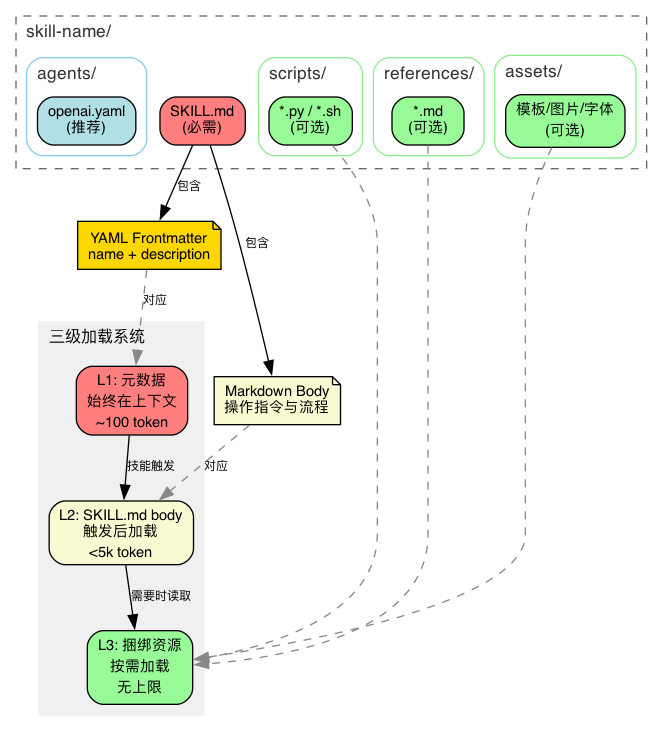
- L1(元数据):始终在上下文中,约 100 token。AI 依靠它来判断是否激活这个技能。
- L2(SKILL.md body):技能触发后才加载,控制在 5k token 以内。包含核心操作指令。
- L3(scripts/references/assets):按需使用,无上限。其中
scripts/ 是执行而不读入,零 token 成本。
这套架构解决了“如何用最少的 token 承载最多的有效信息”。
维度二:给 AI 多大自由度?
并非所有任务都适合让 AI 自由发挥。
举个例子:让 AI 撰写一篇技术博客,十个人可能写出十种不同的风格 —— 你只需要给出方向,具体行文让 AI 自行决定。这属于高自由度任务。
但让 AI 生成一个 YAML 配置文件就完全不同了。比如 skill-creator 要生成的 openai.yaml,其中有一个 short_description 字段,要求长度为 25-64 个字符、首字母大写、不能包含引号。AI 若写成 65 个字符?不行,产品界面会截断。写成 24 个字符?不行,校验无法通过。忘了首字母大写?界面显示不一致。这种任务差一个字符就可能失败,你不能让 AI 自由发挥,必须用脚本来锁死格式。这就是低自由度任务,我们称之为“脆弱操作”:不是说它复杂,而是说它做对只有一种方式,做错却有一百种可能。
这个维度解决了“如何在 AI 的灵活性与输出结果的可靠性之间取得最佳平衡”。
第三层:落地流程
确立了原则和架构,skill-creator 最终提供了一个六步创建流程,将设计思想转化为可执行的操作步骤:
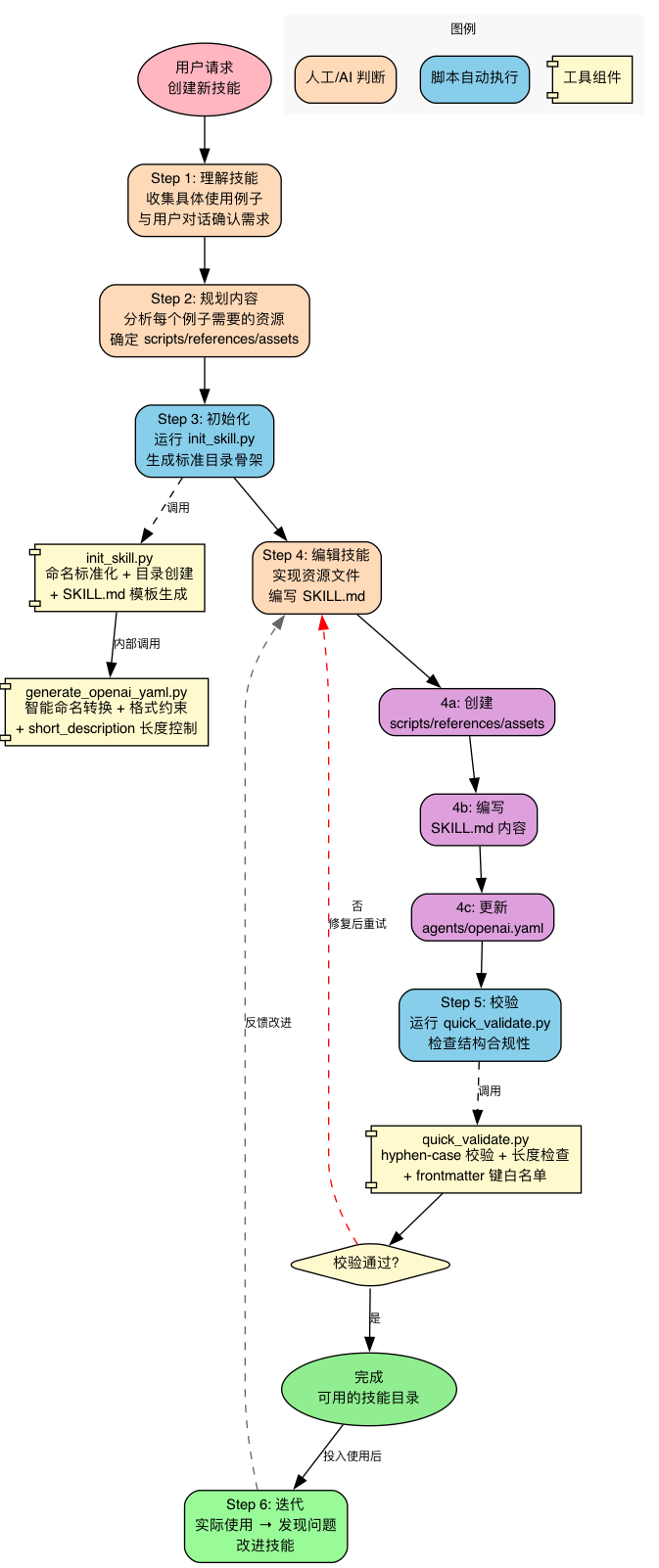
流程为:理解 → 规划 → 初始化 → 编辑 → 校验 → 迭代。其中,脚本代码贯穿整个流程,提供了确定性的保障:
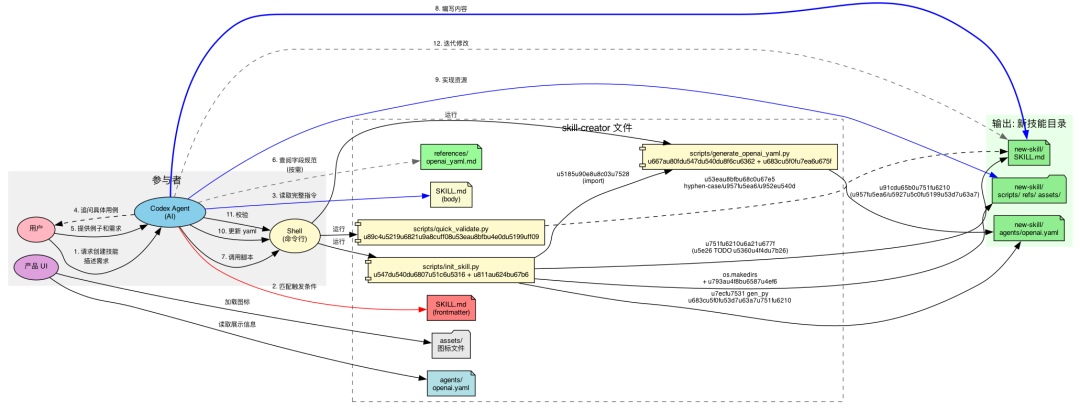
框架总览
三个层次的关系可以概括如下:

接下来,我们将在这个框架内逐一展开每个部分。
四、根本约束:简洁
框架位置:第一层
4.1 核心约束
AI 的上下文窗口就像一张共享的工作台——它同一时间能摊开的资料是有限的。这张工作台上已经放置了不少东西:系统自身的规则、用户之前的对话历史、所有已安装技能的简介。一旦你的技能被激活,它的内容也需要占用工作台的空间。空间就这么多,你占得越多,留给其他内容的空间就越少。
因此,skill-creator 将其列为第一条原则:
The context window is a public good. Skills share the context window with everything else Codex needs: system prompt, conversation history, other Skills‘ metadata, and the actual user request.
既然工作台空间有限,那么在编写 Skill 时如何判断一段内容是否应该放入?skill-creator 给出了一个前提假设:AI 本身已经非常聪明,你只需要补充它不知道的信息。
Default assumption: Codex is already very smart. Only add context Codex doesn't already have.
基于这个假设,在撰写每段内容之前,问自己两个问题:
- “AI 是不是已经知道这个了?” —— 例如“Python 的 for 循环怎么写”,AI 当然知道,无需赘述。
- “这段内容值得占用工作台上的宝贵空间吗?” —— 一段 200 字的解释,能否用一个 10 行的代码示例来替代?
实操推论:用简洁的示例代替冗长的解释。一个好的代码示例胜过三段文字描述。
4.2 什么不该放进 Skill?
Skill-creator 明确列出了禁止清单:
A skill should only contain essential files that directly support its functionality. Do NOT create extraneous documentation or auxiliary files.
不该包含的文件:
README.mdINSTALLATION_GUIDE.mdQUICK_REFERENCE.mdCHANGELOG.md

原因很简单:Skill 的读者是 AI,不是人类开发者。AI 不需要安装指南、更新日志、快速参考这类“人类辅助文档”。每一个多余的文件都是干扰信息的噪音。
4.3 写约束时,“不做什么”比“做什么”更精确
“简洁”不仅是“少写”,更是“写对”。来看一个例子。
当 skill-creator 创建 laotou-thought-style(一种写作风格技能)时,它没有写:
请用温暖、克制、有洞察力的语气写作。
这种正面描述看似清晰,但对 AI 而言,“温暖”的程度、“克制”与“有洞察力”之间的平衡——全是模糊地带。
它实际的做法是编写了一份反模式清单(references/anti-patterns.md):
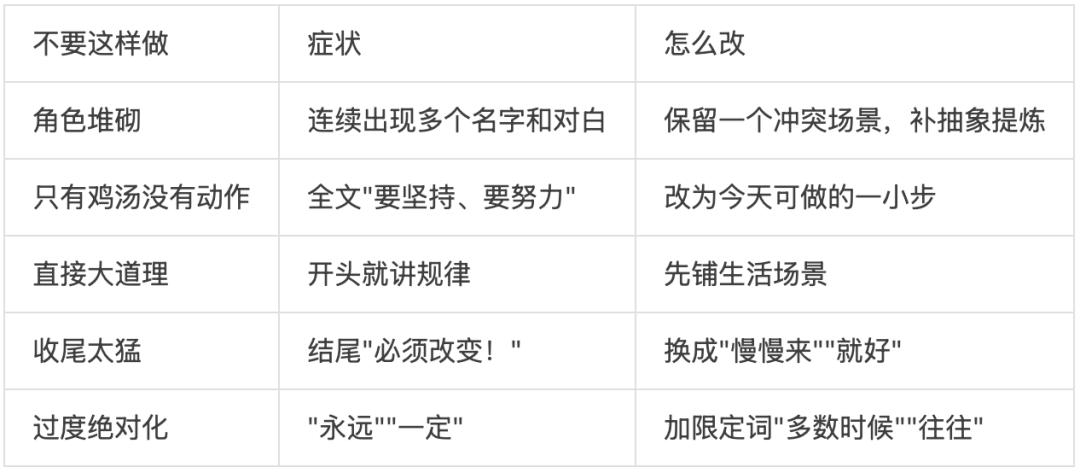
每一条都是具体的、可检测的、有明确修正方案的。
背后的原理是:
- “做什么” → 描述一个无限大的可行域 → AI 在其中随机游走。
- “不做什么” → 在可行域上划定清晰的边界 → AI 的行为空间被精准收窄到你期望的范围。
skill-creator 自身也遵循了这一原则——它的 SKILL.md 用了大量篇幅说明“什么不该写”(What to Not Include in a Skill),而非泛泛地谈论“如何写好内容”。
当你写完 SKILL.md 后,可以做一次“反转测试”:将每一条正面指导,尝试改写成“不要做 X”的形式。如果可以,改写后的指令通常会更加精确。
4.4 统一使用祈使语气
Skill-creator 要求 SKILL.md 的正文统一使用祈使语气或不定式(Always use imperative/infinitive form)。这不是美学偏好,而是为了减少歧义——祈使句天生就是指令。
五、设计维度一:信息放在哪里?
框架位置:第二层 — 维度一
5.1 三级渐进式加载
Skill-creator 原文对三个层级的定义:
- Metadata (name + description) - Always in context (~100 words)
- SKILL.md body - When skill triggers (<5k words)
- Bundled resources - As needed by Codex (Unlimited because scripts can be executed without reading into context window)
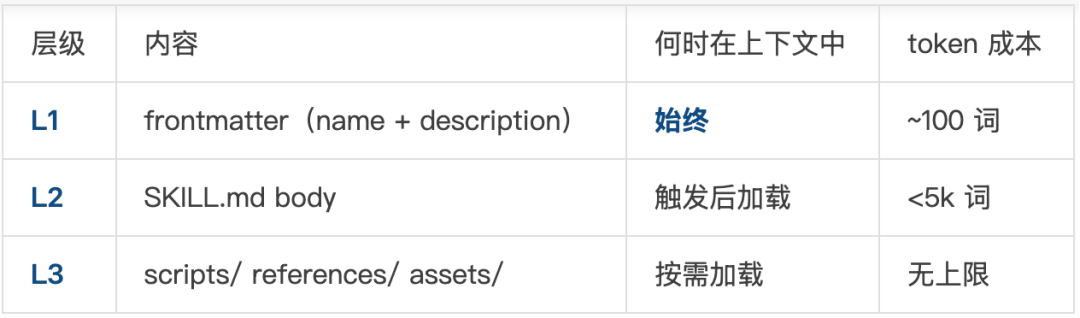
这本质上是一套信息熵管理系统:
- L1 是过滤器 —— 从几十个已安装技能中筛选出当前最相关的一个。
description 若不精确,会导致误触发或漏触发。
- L2 是操作手册 —— 技能触发后,告诉 AI 具体如何行动。内容过长会导致 AI 的注意力被稀释。Body 部分建议控制在 500 行以内。
- L3 是工具箱 —— 仅在需要时打开使用。其中
scripts/ 效率最高——执行而不读入,零 token 成本。
5.2 Frontmatter:触发机制的全部来源
Frontmatter 只有两个必需字段:name 和 description。但 description 的写法至关重要:
This is the primary triggering mechanism for your skill, and helps Codex understand when to use the skill.
Skill-creator 自身的 description 是这样写的:
description: Guide for creating effective skills. This skill should be used when users want to create a new skill (or update an existing skill) that extends Codex's capabilities with specialized knowledge, workflows, or tool integrations.
它不仅说明了“做什么”(创建有效的技能),还明确了“什么时候用”(当用户想要创建或更新一个扩展 Codex 能力的技能时)。
关键规则:
- 把所有“何时使用此技能”的信息都放在
description 里,千万不要放在 body 里。因为 body 是触发后才加载的,到那时 AI 已经决定使用该技能,“何时使用”的信息为时已晚。
- 不要在 frontmatter 中放置
name 和 description 以外的字段(license、allowed-tools、metadata 这三个例外)。
一个好的 description 示例(docx 技能):

5.3 四种捆绑资源的本质区别
理解这四种资源的区别,是掌握整个 Skill 系统的关键。
Scripts(scripts/)
用于需要确定性、高可靠性或需要反复重写的任务的可执行代码(Python/Bash 等)。
- 何时需要:同样的代码每次都要重新写,或者需要确定性的可靠输出。
- 举例:
scripts/rotate_pdf.py 用于 PDF 旋转任务。
- 核心优势:token 效率高、输出确定、可以执行而不读入上下文窗口。
- 注意:脚本有时仍需要被 Codex 读取,例如用于打补丁或环境适配。
References(references/)
在需要时加载到上下文中,辅助 Codex 思考过程的文档和参考材料。
- 何时需要:Codex 在工作时需要参考的详细文档。
- 举例:
references/finance.md(财务数据表结构)、references/api_docs.md(API 规范)、references/policies.md(公司政策)。
- 用途:数据库 schema、API 文档、领域知识、公司政策、详细工作流指南。
- 核心优势:保持
SKILL.md 精炼,只在 Codex 判断需要时才加载。
- 最佳实践:如果文件很大(>10k 词),在
SKILL.md 中包含 grep 搜索模式以便快速定位。
- 避免重复:信息应该只存在于
SKILL.md 或 references 文件中,不能两边都有。详细信息优先放入 references,SKILL.md 只保留核心流程指令和必要的工作流指引。
Assets(assets/)
不是用来加载到上下文中的文件,而是直接用在 Codex 产出物中的资源。
- 何时需要:技能需要在最终输出中使用的文件。
- 举例:
assets/logo.png(品牌素材)、assets/slides.pptx(PPT 模板)、assets/frontend-template/(HTML/React 样板)、assets/font.ttf(字体)。
- 用途:模板、图片、图标、样板代码、字体、示例文档——这些会被复制或修改。
- 核心优势:将输出资源与操作文档分离,Codex 可以使用它们而无需将其内容读入上下文。
Agents 元数据(agents/openai.yaml)(推荐)
面向用户界面的元数据,不是给 AI 读的,而是给产品前端读取并展示的:
- 包含
display_name、short_description、default_prompt 等字段。
- 应通过
generate_openai_yaml.py 脚本确定性生成,而不是手动编写。
- 更新
SKILL.md 后,需检查 agents/openai.yaml 是否仍与之匹配,若已过期则需重新生成。
- 详细字段定义请参考
references/openai_yaml.md。
5.4 渐进式披露的三种实战模式
Skill-creator 提供了三种将内容拆分到 references 的具体模式:
Pattern 1:高层指南 + 参考文件
# PDF Processing
## Quick start
Extract text with pdfplumber:
[code example]
## Advanced features
- **Form filling**: See [FORMS.md](FORMS.md) for complete guide
- **API reference**: See [REFERENCE.md](REFERENCE.md) for all methods
- **Examples**: See [EXAMPLES.md](EXAMPLES.md) for common patterns
Codex 只在需要时才加载 FORMS.md、REFERENCE.md 或 EXAMPLES.md。
Pattern 2:按领域组织
适用于多领域/多场景的技能,按领域拆分可以避免加载无关内容:
bigquery-skill/
├── SKILL.md (overview and navigation)
└── reference/
├── finance.md (revenue, billing metrics)
├── sales.md (opportunities, pipeline)
├── product.md (API usage, features)
└── marketing.md (campaigns, attribution)
当用户询问销售指标时,Codex 只会读取 sales.md。
这同样适用于多框架/多供应商场景:
cloud-deploy/
├── SKILL.md (workflow + provider selection)
└── references/
├── aws.md (AWS deployment patterns)
├── gcp.md (GCP deployment patterns)
└── azure.md (Azure deployment patterns)
Pattern 3:条件性细节
基础功能直接在 SKILL.md 中展示,高级功能则通过链接按需访问:
# DOCX Processing
## Creating documents
Use docx-js for new documents. See [DOCX-JS.md](DOCX-JS.md).
## Editing documents
For simple edits, modify the XML directly.
**For tracked changes**: See [REDLINING.md](REDLINING.md)
**For OOXML details**: See [OOXML.md](OOXML.md)
5.5 两条重要的避坑指南
- 避免深层嵌套引用 — 所有 reference 文件都应该从
SKILL.md 直接链接,不要形成 A → B → C 式的多层嵌套。
- 长文件加目录 — 超过 100 行的 reference 文件,建议在顶部添加目录(TOC),方便 Codex 快速预览文件全貌。
5.6 常见的层错位错误
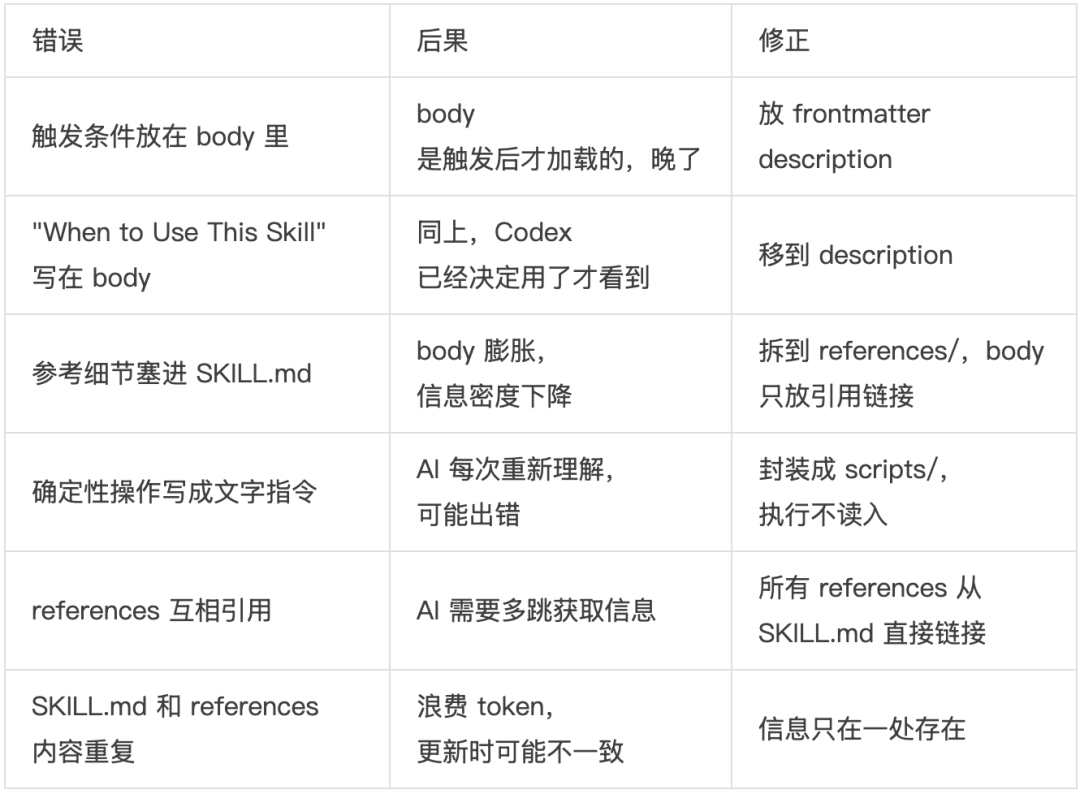
六、设计维度二:给 AI 多大自由度?
框架位置:第二层 — 维度二
明确了信息该放在哪里、该如何约束之后,下一个核心问题是:AI 做什么,脚本做什么?
AI 非常擅长理解语义、生成文本、进行创造性工作。但它不擅长精确的格式控制、长度约束、命名规范——这些都属于“脆弱操作”。
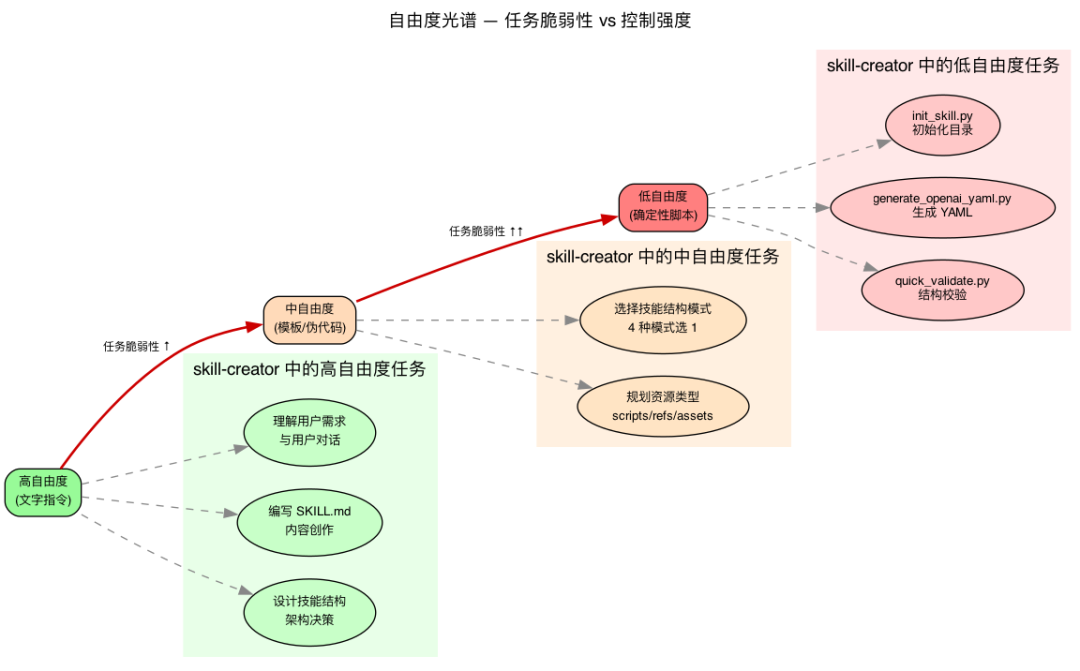
6.1 三个自由度档位
Skill-creator 用一个自由度光谱来处理任务特性的不均匀性(已在第三章展示):
Think of Codex as exploring a path: a narrow bridge with cliffs needs specific guardrails (low freedom), while an open field allows many routes (high freedom).
- 高自由度(文字指令):当多种方法都可行,决策高度依赖上下文时,使用启发式文字进行引导。
- 中自由度(伪代码/带参数的脚本):存在最佳实践,但也允许一定程度的变通,配置参数会影响具体行为。
- 低自由度(具体脚本,少量参数):操作脆弱易出错,一致性至关重要,必须遵循特定的操作序列。
核心逻辑:
任务越脆弱(容易出错) → 自由度越低 → 用脚本锁死
任务越灵活(多种方案都对) → 自由度越高 → 用文字引导
6.2 skill-creator 自身的自由度分配
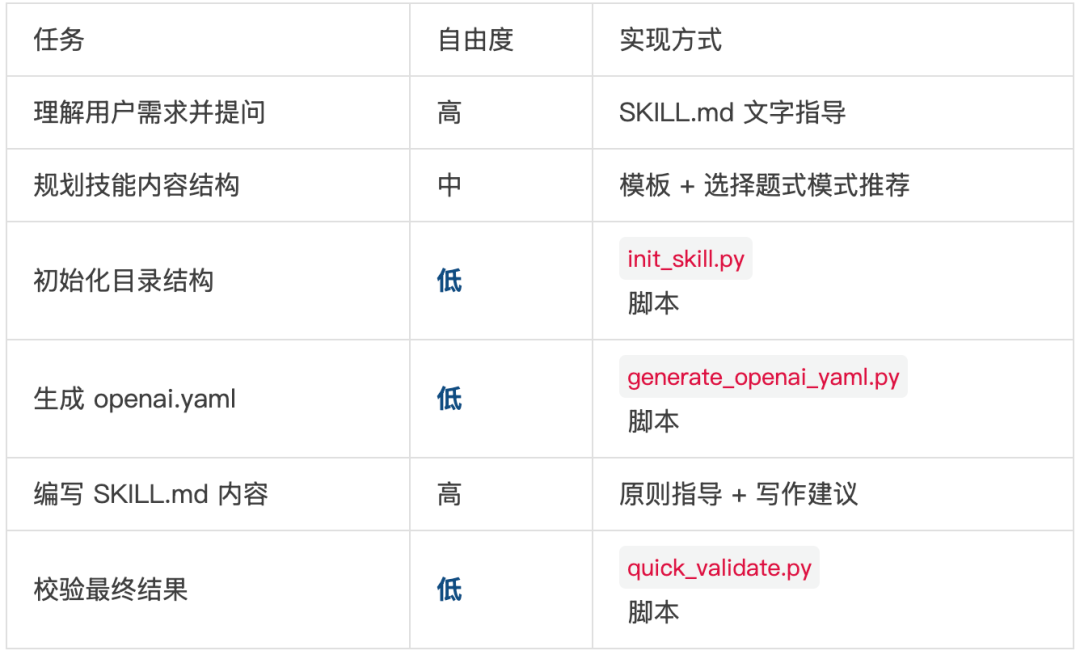
6.3 两个方向的错误
错误 1:给脆弱任务太多自由度
# 错误示例
请生成一个 openai.yaml 文件,包含 display_name 和 short_description。
# 后果:short_description 可能超过 64 字符限制,大小写可能不一致
Skill-creator 的做法:使用 generate_openai_yaml.py 脚本锁死格式。AI 只提供参数值,脚本负责保证最终输出完全合规。
错误 2:给创造性任务太多约束
# 错误示例
第一段必须以“昨天”开头,第二段必须包含“本质上”,最后一段以“慢慢来”结尾。
# 后果:生成的文本像填词游戏,生硬不自然
Skill-creator 的做法:给出结构比例指导(例如,场景描述 ≤30%,原理分析占 30-40%),但不锁定具体的用词,保留 AI 的创造性空间。
6.4 判断标准
决策时问自己两个问题:
- 做错了后果有多严重? — 后果越严重 → 自由度越低。
- 有多少种“正确”的做法? — 正确做法越多 → 自由度越高。
6.5 低自由度的实现:skill-creator 的三个脚本
理解了自由度光谱,就能明白为何 skill-creator 配备了三个核心脚本——它们正是“低自由度”原则的具体实现。
init_skill.py(输入保障,398 行)
初始化新技能目录的脚手架工具,类似于 create-react-app 之于 React 项目。
scripts/init_skill.py <skill-name> --path <output-directory> \
[--resources scripts,references,assets] [--examples] \
[--interface key=value]
generate_openai_yaml.py(格式保障,226 行)
专门负责生成和更新 agents/openai.yaml 文件。
quick_validate.py(输出保障,102 行)
技能创建完成后的“质量检查”工具。
scripts/quick_validate.py <path/to/skill-folder>
- 校验内容:
SKILL.md 文件是否存在。- YAML frontmatter 格式是否合法。
name:是否为 hyphen-case,长度 ≤ 64 字符,无连续或首尾连字符。description:是否存在,不包含尖括号,长度 ≤ 1024 字符。- frontmatter 中只允许出现
name, description, license, allowed-tools, metadata 这 5 个键。
6.6 质量保障链
这三个脚本形成了一条前后衔接的工作流链,将高自由度的创造性步骤“夹”在中间,确保了输入和输出的确定性:
init_skill.py(输入保障)
命名标准化 + 目录结构创建 + 模板生成
→ 确保起点正确
↓
AI 创造性编写(高自由度)
→ SKILL.md 内容、references、自定义 scripts
↓
quick_validate.py(输出保障)
frontmatter 格式 + 命名规范 + 长度约束校验
→ 确保终点合规
脚本是 “执行而不读入” 的——这意味着它们具有零 token 成本。你可以将任意复杂的确定性逻辑封装进脚本,而不必担心它会占用宝贵的上下文空间。这正是 skill-creator 将命名转换、长度约束、格式校验这些琐碎但脆弱的操作全部交给脚本代码的原因。
6.7 什么该封装成脚本?
每次执行结果必须一样 → 脚本
涉及精确格式/长度约束 → 脚本
涉及命名规范转换 → 脚本
需要校验规则匹配 → 脚本
同样的代码每次都要重新写 → 脚本
需要理解上下文 → 文字指令
有多种合理做法 → 文字指令
需要创造性判断 → 文字指令
脚本的核心定义是“执行”。虽然有时仍需要被 Codex 读取(例如用于打补丁或环境适配),但在大多数情况下,它们都是“执行而不读入”的。
七、落地:六步创建流程
框架位置:第三层
有了前面的设计原则和架构,skill-creator 最终提供了一个六步创建流程(已在第三章展示),将理论转化为可执行的操作。
7.0 命名规范
在开始之前,先确立命名规则:
- 只使用小写字母、数字和连字符(hyphen);将用户提供的名称标准化为 hyphen-case(例如 “Plan Mode” →
plan-mode)。
- 名称长度 ≤ 64 字符。
- 优先使用简短、以动词开头的短语来描述动作。
- 必要时使用工具名作为命名空间(例如
gh-address-comments、linear-address-issue)。
- 技能文件夹的名称必须与技能名(
name 字段)完全一致。
7.1 Step 1:理解技能——用具体例子建立共识
Skip this step only when the skill's usage patterns are already clearly understood.
要创建一个有效的技能,必须首先清晰理解具体的使用场景和例子。这些理解可以来自用户直接提供的案例,也可以是生成后经用户确认的例子。
以构建 image-editor 技能为例,可以向用户提问:
- “
image-editor 技能应该支持什么功能?编辑、旋转,还有其他吗?”
- “能给一些使用这个技能的具体例子吗?”
- “我能想到用户会说‘去掉这张照片的红眼’或‘旋转这张图片’。还有其他典型的使用方式吗?”
- “用户会说哪些话(触发词)来启动这个技能?”
注意:不要一次性提出所有问题。先从最重要的问题开始,然后根据回答进行跟进。
完成标志:对技能应该支持的核心功能和使用场景有了清晰、一致的认识。
7.2 Step 2:规划可复用的技能内容
针对 Step 1 中收集的每个具体例子,进行两个层面的分析:
- 如果从零开始完成这件事,需要哪些信息、步骤或资源?
- 其中哪些部分会被反复、高频地使用?
将被反复使用的部分 → 封装成 scripts/、references/ 或 assets/。
Skill-creator 提供了三个典型分析案例:
- 案例 1:
pdf-editor 技能(用户请求“帮我旋转这个 PDF”)
- 分析:旋转 PDF 的代码逻辑每次都是相同的。
- → 封装为
scripts/rotate_pdf.py
- 案例 2:
frontend-webapp-builder 技能(用户请求“帮我做一个 todo app”)
- 分析:创建前端 Web 应用每次都需要基础的 HTML/React 样板代码。
- → 封装为
assets/hello-world/ 模板目录
- 案例 3:
big-query 技能(用户请求“今天有多少用户登录了?”)
- 分析:查询 BigQuery 每次都需要重新发现数据表的 schema 和关联关系。
- → 封装为
references/schema.md
完成标志:获得了一份要包含的所有可复用资源清单(scripts、references、assets)。
7.3 Step 3:初始化技能
When creating a new skill from scratch, always run the init_skill.py script.
这里用的是 “always”(总是)——不是建议,是必须。原因在于:
- 脚本生成的目录结构能 100% 符合规范。
- 模板中的 TODO 占位符能有效提醒你不遗漏任何必需字段。
agents/openai.yaml 的格式约束(字段长度、引号规则等)手动编写极易出错。
这是低自由度原则的直接应用:初始化是一个典型的脆弱操作,必须用脚本来消除所有可能的出错点。
初始化完成后:
- 根据规划定制
SKILL.md,并按需添加资源文件。
- 如果使用了
--examples 参数,记得替换或删除生成的占位符示例文件。
7.4 Step 4:编辑技能
这是最核心的创造性步骤,分为两个阶段:
阶段一:先实现可复用资源
从 Step 2 规划的资源清单开始,着手实现 scripts/、references/、assets/ 目录下的具体文件。
- 注意:这一步可能需要用户提供输入(例如,
brand-guidelines 技能需要用户提供品牌素材)。
- 新增的脚本必须通过实际运行来测试,确保没有 bug 且输出符合预期。
- 如果有很多类似的脚本,测试其中代表性的几个即可建立信心。
- 如果初始化时用了
--examples,请删除不需要的占位符文件。只创建真正必需的资源目录。
阶段二:更新 SKILL.md
7.5 Step 5:校验技能
scripts/quick_validate.py <path/to/skill-folder>
运行此脚本,校验 YAML frontmatter 格式、必需字段是否存在以及命名规则是否符合规范。如果校验不通过,根据提示修复问题后重新运行。
7.6 Step 6:迭代
After testing the skill, users may request improvements. Often this happens right after using the skill, with fresh context of how the skill performed.
一个优秀的技能很少是一次性写成的。迭代工作流通常如下:
- 在真实任务中使用该技能。
- 观察并发现技能在哪些地方表现吃力或效率低下。
- 分析是
SKILL.md 的指令问题,还是某个捆绑资源需要更新。
- 实施变更,并重新测试。
例如,skill-creator 创建的 laotou-thought-style 技能,在第一次生成后,就根据实际使用反馈,迭代更新了 openai.yaml 中的 short_description 和 default_prompt,使其从泛泛的描述变为更精确、可操作的具体指令。
八、总结
回到最初的核心问题:如何写出好的 Skill?
回顾整个 skill-creator 的设计框架:

首先,必须明确 Skill 是给 AI 写指令,而不是给人。基于此,Skill 设计的本质可以归结为一句话:用最少的 token,在正确的层级,给 AI 最精准的约束,从而让它在设定的边界内充分发挥其能力。
skill-creator 通过“简洁”的根本约束、三级分层的信息架构、基于自由度光谱的任务分配,以及标准化的六步流程,为我们提供了一套经过实践检验的、可落地的 Skill 设计范式。遵循这套范式,你就能更高效地为 AI Agent 打造出真正强大、可靠的能力插件。
更多关于AI开发与工程实践的深度讨论,欢迎访问 云栈社区。
 发表于 2026-2-23 03:55:06
|
查看: 573|
回复: 0
发表于 2026-2-23 03:55:06
|
查看: 573|
回复: 0
