在嵌入式通信开发中,协议解析是连接硬件与软件的关键环节。数据如何到达,决定了我们如何解析。本文将以一个简易的嵌入式自定义协议(ITLV协议)为例,深入探讨一次性解析(Batch Parsing)与流式解析(Stream Parsing)这两种核心方法的本质区别、典型应用场景以及具体的C语言实现。
我们将解答几个关键问题:如何处理粘包?如何应对断包?如何在有噪声的通信环境中稳定工作?首先,通过一个决策图来直观理解选择逻辑:
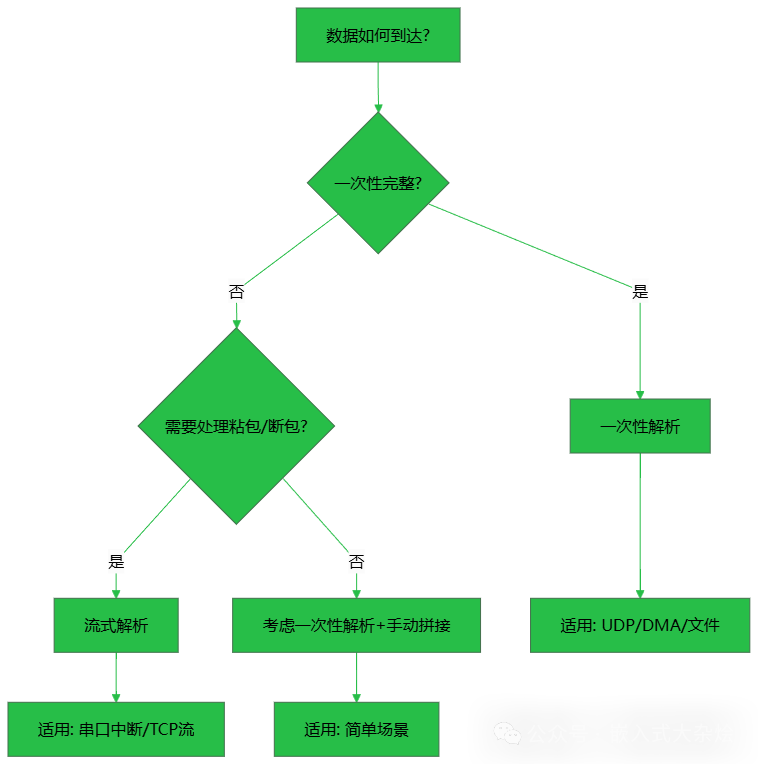
1. 问题的核心:数据如何到达?
假设我们需要解析一帧LED控制命令,数据内容如下(共9字节):
55 AA 01 08 02 01 01 A5 F4
这9个字节是如何抵达我们的程序缓冲区的?这直接决定了我们该采用哪种解析策略。
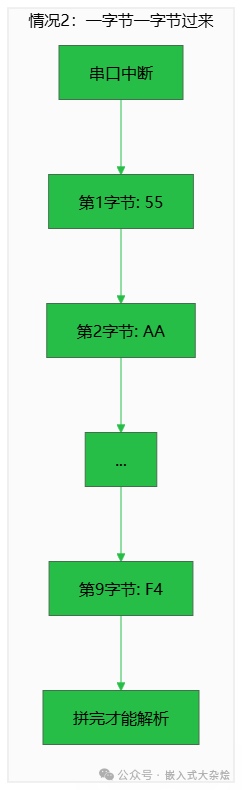
情况1:数据一次性完整到达。
这种情况下,数据包或文件读取操作通常能提供一个完整的数据帧,适合使用一次性解析方式。
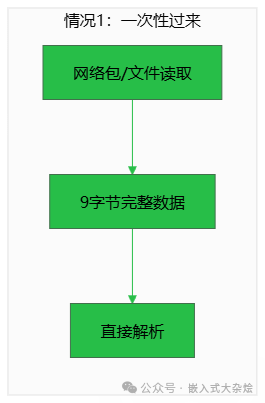
情况2:数据逐字节、分批到达。
在串口中断、低速TCP流等场景中,数据像流水一样逐个或小批量到达,必须使用流式解析方式。
2. 两种解析方式的核心区别
2.1 流式解析(Stream Parsing)
特点:
- 增量处理:每次只处理一个或少量字节。
- 状态机驱动:内部维护一个解析状态(如 IDLE → HEAD1 → HEAD2 → ID → ...)。
- 内部缓冲:拥有独立的接收缓冲区,用于暂存未完成的帧数据。
- 实时响应:数据到达即刻处理,无需等待完整帧。
实现示例(C语言状态机):
流式解析的核心是一个状态机函数,它接收单个字节并更新解析状态。这种基于状态机的解析是嵌入式C编程中的经典模式。
// 逐字节输入,状态机驱动
protocol_err_e protocol_parse_byte(protocol_parser_t *parser, uint8_t byte)
{
switch (parser->state)
{
case PARSE_STATE_IDLE:
if (byte == 0x55) // 寻找帧头第一个字节
{
parser->buffer[0] = byte;
parser->index = 1;
parser->state = PARSE_STATE_HEAD2;
}
// 其他字节直接丢弃,继续等待0x55
break;
case PARSE_STATE_HEAD2:
if (byte == 0xAA) // 确认帧头第二个字节
{
parser->buffer[parser->index++] = byte;
parser->state = PARSE_STATE_ID;
}
else
{
parser->state = PARSE_STATE_IDLE; // 包头错误,状态机复位
}
break;
// ... 其他状态(等待ID、长度、载荷、CRC等)...
case PARSE_STATE_CRC_HIGH:
parser->buffer[parser->index++] = byte;
// CRC校验
if (crc_ok)
{
parser->state = PARSE_STATE_IDLE;
return PROTO_OK; // 一帧解析完成!
}
else
{
parser->state = PARSE_STATE_IDLE;
return PROTO_ERR_CRC_MISMATCH;
}
}
return PROTO_ERR_IN_PROGRESS; // 帧未接收完整,继续等待
}
// 从解析器中获取已解析完成的帧数据
protocol_err_e protocol_parser_get_frame(const protocol_parser_t *parser, protocol_data_t *data)
{
if (parser == NULL || data == NULL)
{
return PROTO_ERR_NULL_PTR;
}
const uint8_t *buf = parser->buffer;
data->id = buf[2]; /* ID位置 */
data->type = buf[3]; /* Type位置 */
data->length = buf[4]; /* Length位置 */
/* 复制payload数据 */
if (data->length > 0)
{
memcpy(data->payload, &buf[PROTOCOL_HEADER_SIZE], data->length);
}
return PROTO_OK;
}
典型使用场景(串口中断服务例程):
void USART1_IRQHandler(void)
{
if (USART1->SR & USART_SR_RXNE)
{
uint8_t byte = USART1->DR;
if (!ring_is_full(&g_rx_ring))
{
ring_push(&g_rx_ring, byte); // 存入环形缓冲区
}
}
}
void protocol_task(void)
{
while (!ring_is_empty(&g_rx_ring))
{
uint8_t byte = ring_pop(&g_rx_ring);
protocol_err_e ret = protocol_parse_byte(&g_parser, byte);
if (ret == PROTO_OK)
{
// 一帧完成,提取并处理
protocol_data_t data;
protocol_parser_get_frame(&g_parser, &data);
process_frame(&data); // 业务处理
}
else if (ret != PROTO_ERR_IN_PROGRESS)
{
// 异常处理:解析出错(CRC错误等),状态机已自动复位
}
}
}
2.2 批量解析(Batch Parsing)
特点:
- 一次性处理:前提是调用者已经提供了完整的一帧数据。
- 无状态:函数本身不维护任何解析状态,每次调用都是独立的。
- 外部缓冲:依赖调用者管理数据缓冲区,确保数据完整性。
- 简单直接:逻辑清晰,易于理解和调试。
实现示例:
// 一次性解包完整帧
protocol_err_e protocol_unpack(const uint8_t *buf, size_t len, protocol_data_t *data)
{
// 1. 检查包头
if (buf[0] != PROTOCOL_HEAD_BYTE1 || buf[1] != PROTOCOL_HEAD_BYTE2)
{
return PROTO_ERR_INVALID_HEAD;
}
// 2. 验证长度字段是否与缓冲区长度匹配
uint8_t payload_len = buf[PROTOCOL_LENGTH_INDEX];
// 3. CRC校验
uint16_t calc_crc = crc16_x25(buf, crc_offset);
// 4. 提取数据
data->id = buf[2];
memcpy(data->payload, &buf[PROTOCOL_HEADER_SIZE], data->length);
return PROTO_OK;
}
典型使用场景:
// 假设从某处已读取到完整帧
uint8_t rx_buf[] = {0x55, 0xAA, 0x01, 0x08, 0x02, 0x01, 0x01, 0xA5, 0xF4};
protocol_data_t data;
protocol_err_e ret = protocol_unpack(rx_buf, sizeof(rx_buf), &data);
if (ret == PROTO_OK)
{
printf("解析成功: ID=0x%02X\n", data.id);
}
3. 实战场景对比
3.1 典型场景处理能力
3.1.1 处理粘包
什么是粘包? 多个数据帧粘连在一起到达接收端。

接收到的数据: 55 AA 01 08 02 01 01 A5 F4 55 AA 02 08 08 02 02 00 FE A3
- 一次性解析:只能解析第一帧(前9字节),处理剩余数据需要手动计算偏移量,循环调用解析函数。
- 流式解析:自动处理!状态机在完成一帧解析并返回
PROTO_OK后,自动复位到IDLE状态,继续处理后续字节,无缝分离粘连的帧。
void demo_sticky_packets(void)
{
printf("\n流式解析粘包处理\n");
// 两帧数据粘在一起
uint8_t sticky[] = {
0x55, 0xAA, 0x01, 0x08, 0x02, 0x01, 0x01, 0xA5, 0xF4, // 帧1
0x55, 0xAA, 0x01, 0x08, 0x02, 0x02, 0x00, 0x44, 0xCF // 帧2
};
protocol_parser_t parser;
protocol_parser_init(&parser);
int frame_count = 0;
for (size_t i = 0; i < sizeof(sticky); i++)
{
if (protocol_parse_byte(&parser, sticky[i]) == PROTO_OK)
{
frame_count++;
protocol_data_t data;
protocol_parser_get_frame(&parser, &data);
uint8_t *payload = data.payload;
printf("帧%d: ID=0x%02X, LED%d=%s\n",
frame_count, data.id,
payload[0], payload[1] ? "ON" : "OFF");
}
}
}
3.1.2 处理断包
什么是断包? 一个完整的数据帧被分割成多个小包,分批到达。
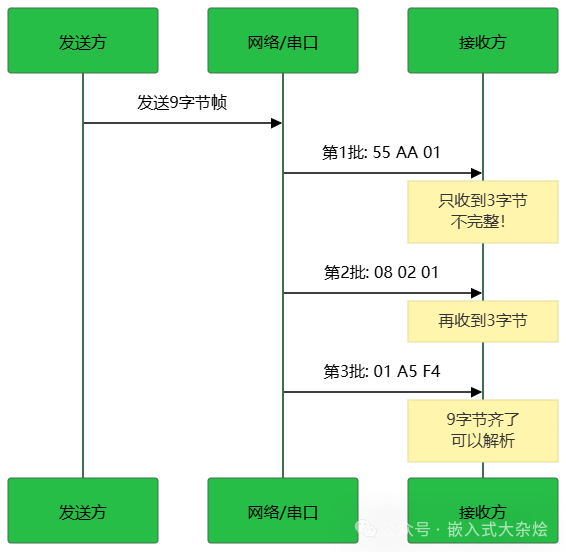
- 一次性解析:在前两批数据到达时,因为数据不完整,解析函数无法工作,需要应用程序自己拼接和管理缓冲区。
- 流式解析:天然支持!状态机内部维护了当前解析状态和已接收的字节,即使数据分十次到达,也能正确拼接出完整帧。
void demo_break_packets(void)
{
printf("\n流式解析断包处理\n");
// 模拟断包场景
uint8_t part1[] = {0x55, 0xAA, 0x01}; // 第1批
uint8_t part2[] = {0x08, 0x02, 0x01}; // 第2批
uint8_t part3[] = {0x01, 0xA5, 0xF4}; // 第3批
protocol_parser_t parser;
protocol_parser_init(&parser);
// 喂入第1批
for (int i = 0; i < 3; i++) {
protocol_parse_byte(&parser, part1[i]);
}
printf("第1批后状态: %d\n", parser.state); // 输出状态码,例如 4 (WAIT_TYPE)
// 喂入第2批
for (int i = 0; i < 3; i++) {
protocol_parse_byte(&parser, part2[i]);
}
printf("第2批后状态: %d\n", parser.state); // 输出状态码,例如 7 (WAIT_CRC_L)
// 喂入第3批
for (int i = 0; i < 3; i++) {
protocol_err_e ret = protocol_parse_byte(&parser, part3[i]);
if (ret == PROTO_OK) // 接收到最后一个字节时触发
{
printf("帧解析完成!\n");
protocol_data_t data;
protocol_parser_get_frame(&parser, &data);
uint8_t *payload = data.payload;
printf("ID=0x%02X, LED%d=%s\n",
data.id, payload[0], payload[1] ? "ON" : "OFF");
}
}
}
3.1.3 噪声过滤
真实通信环境(尤其是串口)可能存在干扰,产生噪声数据。

- 一次性解析:如果缓冲区开头是噪声(非帧头),解析会直接失败,需要调用者预先清理缓冲区。
- 流式解析:自动过滤!状态机在
IDLE状态时,只认帧头第一个字节0x55,其他任何字节都会被静默丢弃,直到正确的同步序列出现。
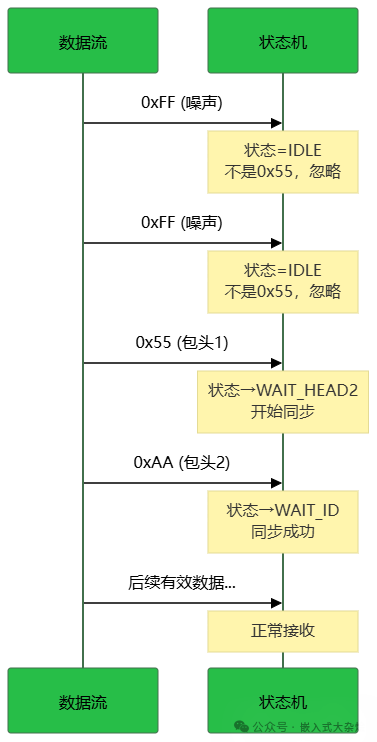
void demo_noise_filter(void)
{
printf("\n流式解析过滤噪声\n");
// 有效帧前面有噪声的数据
uint8_t noisy[] = {
0xFF, 0xFF, // 噪声
0x55, 0xAA, 0x01, 0x08, 0x02, 0x01, 0x01, 0xA5, 0xF4 // 有效帧
};
protocol_parser_t parser;
protocol_parser_init(&parser);
for (size_t i = 0; i < sizeof(noisy); i++)
{
protocol_err_e ret = protocol_parse_byte(&parser, noisy[i]);
if (ret == PROTO_OK)
{
protocol_data_t data;
protocol_parser_get_frame(&parser, &data);
uint8_t *payload = data.payload;
printf("解析结果: ID=0x%02X(噪声被自动过滤), LED%d=%s\n",
data.id, payload[0], payload[1] ? "ON" : "OFF");
}
else if (ret != PROTO_ERR_IN_PROGRESS)
{
printf("Parse error: %s\n", protocol_err_str(ret));
break;
}
}
}
3.2 流式解析的典型适用场景
3.2.1 串口通信(最典型)
如前文USART1_IRQHandler和protocol_task示例所示,其优势在于:
- 中断触发,即时响应。
- 无需等待完整帧,减少延迟。
- 自动处理粘包、断包问题。
3.2.2 低速网络通信(TCP流式传输)
TCP是面向流的协议,数据可能被拆分成多个报文段到达。流式解析能很好地适应这种特性。
// TCP接收回调(数据分批到达)
void tcp_recv_callback(uint8_t *data, size_t len)
{
for (size_t i = 0; i < len; i++)
{
protocol_err_e ret = protocol_parse_byte(&g_parser, data[i]);
if (ret == PROTO_OK)
{
// 处理完整帧
process_frame();
}
}
}
3.2.3 嵌入式实时系统(RTOS任务)
在任务中循环检查并处理到达的字节。
void protocol_task(void)
{
while (1)
{
if (uart_has_data())
{
uint8_t byte = uart_get_byte();
protocol_parse_byte(&parser, byte);
}
os_delay(1); // 短暂让出CPU
}
}
3.3 批量解析的典型适用场景
3.3.1 高速网络通信(UDP/以太网)
UDP是面向数据报的协议,每次recv调用理论上获取一个完整的应用层报文。
// UDP接收(每次接收理论上是一个完整报文)
void udp_recv_callback(uint8_t *buf, size_t len)
{
protocol_data_t data;
// UDP保证报文边界,通常可直接解包
protocol_err_e ret = protocol_unpack(buf, len, &data);
if (ret == PROTO_OK)
{
handle_data(&data);
}
}
优势:
- 一次性处理,函数调用开销小,效率高。
- 逻辑简单,易于调试。
- 利用UDP的数据报特性。
3.3.2 文件/存储读取
从文件或Flash中读取配置数据时,通常可以一次性读取整个结构。
void read_config_from_file(void)
{
FILE *fp = fopen("config.bin", "rb");
if (fp == NULL) return;
uint8_t frame_buf[PROTOCOL_MAX_LEN];
// 从文件读取完整帧
size_t read_len = fread(frame_buf, 1, sizeof(frame_buf), fp);
fclose(fp);
protocol_data_t config;
if (protocol_unpack(frame_buf, read_len, &config) == PROTO_OK)
{
apply_config(&config);
}
}
3.3.3 单次请求-响应交互
在某些简单的主从通信中,一次收发即完成交互。
void recv_cmd(void)
{
uint8_t rx_buf[256];
size_t rx_len;
protocol_data_t response;
// 接收完整响应
rx_len = recv(rx_buf, sizeof(rx_buf));
// 一次性解包
protocol_unpack(rx_buf, rx_len, &response);
}
4. 总结与选型指南
详细对比
| 维度 |
流式解析 |
批量解析 |
| 适用场景 |
串口、低速TCP流、实时环境 |
文件、高速网络(UDP)、单次交互 |
| 数据要求 |
可处理不完整、分批的数据 |
必须提供完整数据帧 |
| 状态保持 |
需要内部状态机 |
无状态 |
| 内存占用 |
需要固定大小的内部缓冲区 |
依赖外部缓冲区,无额外占用 |
| 粘包处理 |
自动分离粘连帧 |
需上层手动处理偏移 |
| 断包处理 |
跨多次接收无缝拼接 |
无法处理,需外部拼接 |
| 实时性 |
极佳,字节级响应 |
一般,需等待完整帧 |
| CPU开销 |
较高(每字节一次函数调用/状态判断) |
较低(一次调用处理整帧) |
| 实现复杂度 |
高(需设计健壮的状态机) |
低(顺序检查即可) |
| 错误恢复 |
强(状态机可自动重新同步) |
弱(失败后需调用者清除缓冲区) |
选型核心要点:
- 数据“一次到齐” → 优先选择一次性解析。简单高效,例如处理UDP报文、读取文件。
- 数据“滴滴答答” → 必须选择流式解析。这是应对串口、TCP流等场景的唯一健壮方式,能妥善处理粘包、断包和噪声。
两种方式本身没有绝对的优劣之分,关键在于匹配你的数据到达方式。在复杂的嵌入式网络通信中,理解数据流的本质是做出正确技术选型的第一步。
常见问题解答(Q&A)
Q1: 流式解析状态机遇到“帧头假象”怎么办?
即payload数据中恰好包含 0x55 0xAA 序列,状态机会不会误判为新帧开始?
A1: 设计良好的状态机不会。在成功接收到包头 (0x55 0xAA) 后,状态机会根据后续的Length字段确定该帧的总长度。在按长度收完该帧的所有数据(包括CRC)之前,状态机不会返回到IDLE状态去寻找新的帧头。即使因极端干扰导致状态机复位并在payload中错误同步,最终的CRC校验也会失败,状态机自动复位,从而保证最终解析的正确性。
增强建议:如果协议对可靠性要求极高,可以考虑对payload进行转义编码(Byte Stuffing),例如将payload中的0x55转换为0x7D 0x55,在解析端再还原,从而彻底杜绝假帧头问题。
希望这篇关于嵌入式协议解析方式的深入对比能对你的项目开发有所帮助。在实践中根据数据的实际“到来”方式选择合适的解析策略,是构建稳定可靠通信系统的基石。更多嵌入式开发实战技巧与系统设计思想,欢迎在云栈社区交流探讨。
 发表于 2026-1-14 00:45:08
|
查看: 167|
回复: 0
发表于 2026-1-14 00:45:08
|
查看: 167|
回复: 0
