假如你是一个致力于将AI引入传统行业的工程团队。现在,你有一个问题:训练一个能看懂复杂机械图纸、设备维护手册或金融研报图表的多模态助手。这个助手不仅要能专业陪聊,更要能精准地识别图纸上的零件标注,或者从密密麻麻的财报截图中提取关键数据。
首先,你需要选择一个合适的模型。
7B参数的小模型虽然跑得快,但「脑容量」太小,面对复杂的图文逻辑经常一本正经地胡说八道;而70B甚至更大的模型虽然聪明,但部署和推理成本直接劝退了客户。最后,你可能发现30B参数级的开源多模态模型(例如Qwen-VL-30B)是个不错的选择。
30B被称为大模型的黄金尺寸:它在理解能力上远超小模型,又比巨型模型轻量,是企业私有化部署的完美平衡点。
不过呢,你可能也会发现,「30B参数」也是一个极具欺骗性的数字。
在纯文本时代,一张前沿的消费级显卡或许还能勉强塞下30B的推理。但在多模态(Vision-Language)场景下,事情完全变了。当模型需要处理高分辨率图像时,视觉编码器会产生大量的视觉Token;而为了让模型真正懂行业Know-how,必须用数千张有标注图像进行LoRA微调。
这就意味着,除了模型本身的权重,我们还需要在显存里塞进梯度、优化器状态以及训练过程中的激活值。
原本以为只是「稍微大一点」的任务,瞬间撞上了硬件的天花板。
这些方案不太行
如果你的开发环境是顶级消费级旗舰,拥有24GB的超大显存,但在这次的任务面前,它显得如此无力。
当你尝试启动微调脚本时,终端里那行熟悉的红色报错如期而至:
RuntimeError: CUDA out of memory.
对于30B多模态模型的微调来说,24GB的显存就是不够。为了让程序跑起来,你可能会选择牺牲性能,比如:
- Batch Size降到1:哪怕训练速度慢到像蜗牛爬。
- 开启梯度检查点:这是一个典型的「时间换空间」策略,通过不缓存中间激活值而是在反向传播时重算,来节省显存。但这让训练时间直接翻倍。
- 极限量化:将模型量化到4-bit甚至更低。但这也会带来新的问题:对于精密图纸的识别,量化后的模型精度下降明显,连零件号都经常认错。
即使做了所有这些妥协,只要稍微喂进去一张分辨率高一点的图表,显存还是瞬间溢出,程序直接崩溃。那种「只差一点点就能跑通」的挫败感,最是折磨人。
「要不试试隔壁美术组那台Mac Studio?」你可能会这样想。那台机器拥有128GB统一内存(Unified Memory)。从硬件上看,这简直是完美的救星 —— 别说30B,就是70B也能塞得下。
但当你兴冲冲地把代码拷过去,才发现这是另一个深坑。
首先是环境配置的噩梦。开源社区的主流多模态模型(尤其是涉及底层CUDA优化的视觉算子)在苹果芯片上的适配往往慢半拍。你可能会花不少时间解决各种编译报错,好不容易跑通了推理,却发现训练速度受限于优化,效率远不及预期。
更致命的是「生态隔离」。在Mac上微调出的模型检查点,想要部署回公司的Linux服务器(基于NVIDIA GPU)上,需要进行繁琐的格式转换和精度对齐。这种开发环境与生产环境的割裂,对于追求快速迭代的工程团队来说,是不可接受的风险。
那么,你到底需要什么?
难道为了跑通这个30B模型,你真的要走漫长的合规流程去申请昂贵的A100云实例,时刻防范私密数据出域的风险?又或者,仅仅为了这一个开发项目,就专门配置一个高成本的工作站,甚至去采购一台必须安置在专业机房、且维护成本高昂的机架式服务器?
你需要这样一台机器:它要有Mac Studio那样海量的统一内存,让你不再为显存精打细算;它同时又必须流淌着纯正的NVIDIA血液,拥有原生的CUDA生态,让代码无缝迁移。
这个「既要又要」的幻想,直到一台1升体积的小盒子的出现,才变成了现实。
桌面上的一升解决方案
这个盒子就是联想 ThinkStation PGX。
如果你关注过英伟达之前的动作,可能会觉得眼熟。没错,联想ThinkStation PGX在核心配置上与NVIDIA DGX Spark完全一致。
准确地说,ThinkStation PGX正是英伟达DGX Spark的OEM量产版本。英伟达已将这一参考设计授权给了联想等厂商,由它们负责具体的工程化制造与差异化定制。
这台机器最直观的冲击力来自于它的尺寸:仅有 1升(1L)。它小到可以轻松塞进通勤背包,放在办公桌的一角几乎没有存在感。但就在这方寸之间,联想塞进了一颗基于NVIDIA Grace Blackwell架构的GB10超级芯片。

而对于被显存折磨得死去活来的开发者来说,它最性感参数是:128 GB 统一内存(Unified Memory)。
这不仅仅是数字的胜利,更是架构的胜利。ThinkStation PGX的统一内存架构允许CPU和GPU共享这128GB的海量空间,且可通过NVLink-C2C技术实现高速互联。这意味着,开发者终于可以在桌面上拥有接近甚至超越专业级计算卡(如H100 80GB)的显存容量。

除了核心算力,在数据存储方面,联想贴心地提供了1TB和4TB两个存储版本。对于大部分只是想快速验证模型原型的开发者,1TB版本足矣;而对于需要本地存放海量训练数据(如医疗影像、自动驾驶点云或数万张高清图纸)的团队来说,4TB版本显然是更具安全感的选择。
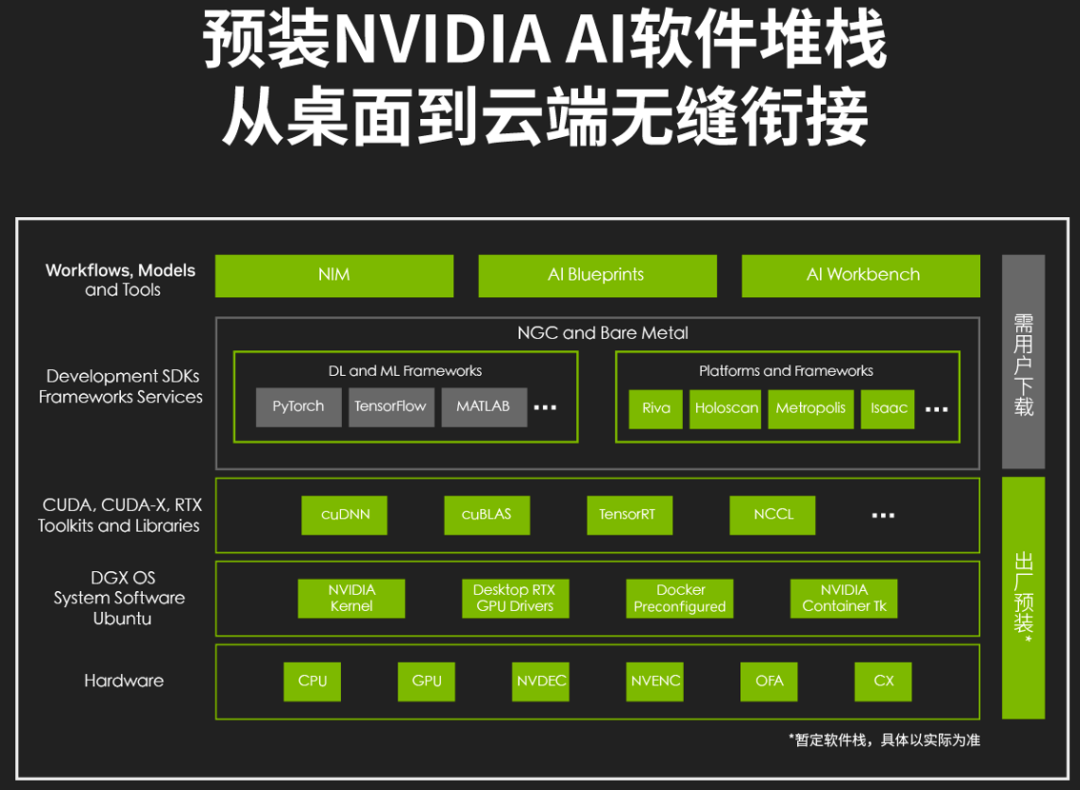
更关键的是,它是一台「原生」的AI机器。预装了 NVIDIA AI 软件栈,底层运行的是开发者熟悉的Linux系统,跑的是最纯正的CUDA环境。
接下来,就让我们亲手试一试这样显存巨大的性能小猛兽吧。
首先,掂一掂重量,着实非常小巧,甚至比Mac mini M1还小一些。同时,它的设计也非常精致,采用了标志性的蜂窝状散热设计,不仅看起来科技感十足,更是为了保证进风效率。

接下来,把ThinkStation PGX连上显示器,通电开机,先来看看基本信息。
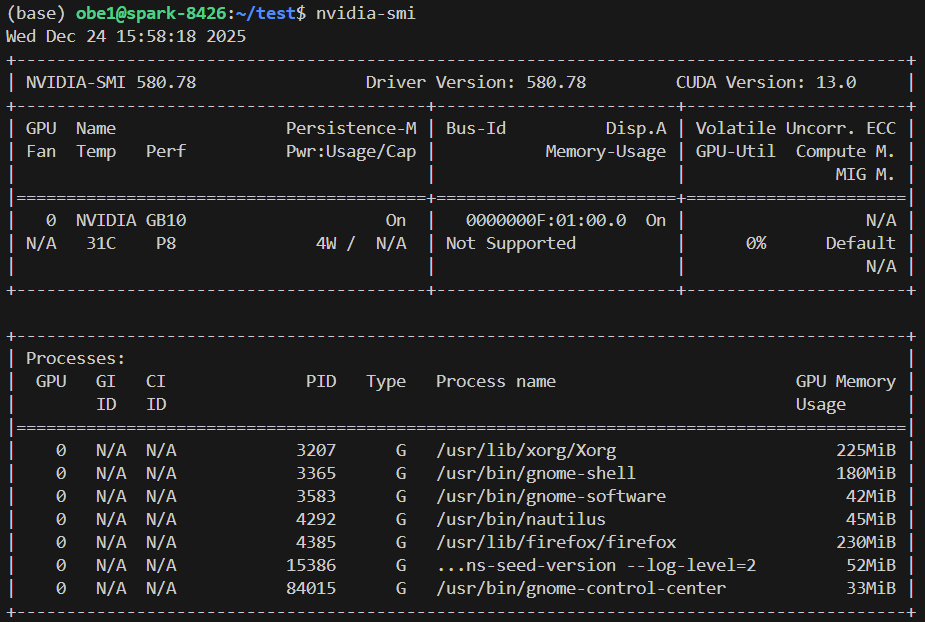
在终端输入nvidia-smi,可以看到显卡型号是NVIDIA GB10,CUDA版本为13.0。但这里有一个有趣的细节:在Memory-Usage一栏,它显示的是Not Supported。
为什么不支持?其实,这反而是最大的利好。
在传统的独立显卡(如RTX 4090)上,显存是独立的,所以会显示具体MiB数值。这里的「Not Supported」以及下面进程列表里能显示显存占用(如Firefox用了230MiB),直接证明了它是统一内存(Unified Memory)架构。
是的,PGX的GPU没有自己封闭的小显存墙,而是直接访问系统的大内存池。
接下来我们将通过一个真实的微调场景来检验这台机器的能力。
实战:用FoodieQA数据集微调Qwen3-VL-30B
首先,我们选择的模型是完整版的Qwen3-VL-30B-A3B-Instruct。
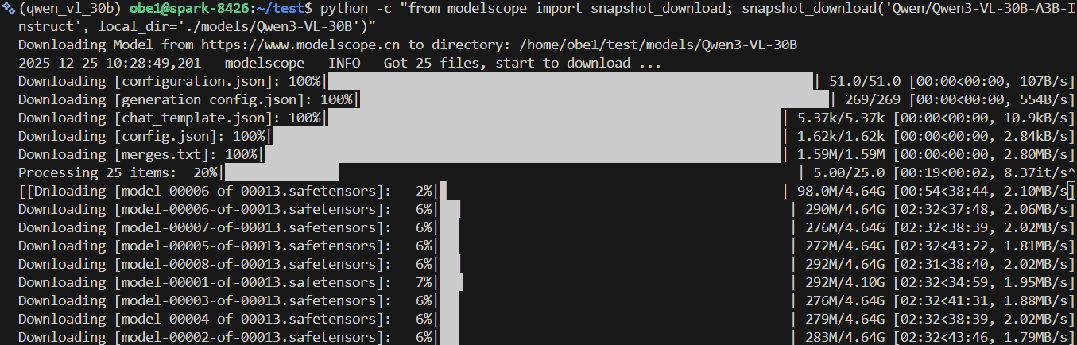
糟糕的网速下等待1个多小时,下载完成。而为了微调模型,我们还需要一个数据集,这里我们选择是的lyan62发布的FoodieQA数据集。据介绍,FoodieQA是一个用于细粒度理解中国饮食文化的多模态数据集,其中包含多图像、单图像视觉问答(VQA)以及关于中国地方美食的文本问答问题。该数据集基于350种独特美食条目对应的389张独特美食图像构建而成。它要求模型不仅能看图,还要懂中国味。
接下来,我们先是自己尝试了编写微调脚本,但效果并不佳。于是我们决定直接让AI全程接管,来一次vibe fine-tuning(氛围微调)!
给PGX装上Claude Code,并配置好MiniMax-M2.1。然后下达一小段指令:
你是一位出色的AI模型微调专家,你现在需要在一台拥有128GB统一内存的联想ThinkStation PGX上微调一个30B大小的MoE模型。在这里,models/Qwen3-VL-30B文件夹中是已下载的Qwen3-VL-30B-A3B-Instruct模型,FoodieQA文件夹中是lyan62/FoodieQA数据集。请使用FoodieQA数据集完成对Qwen3-VL-30B-A3B-Instruct模型的进一步微调。
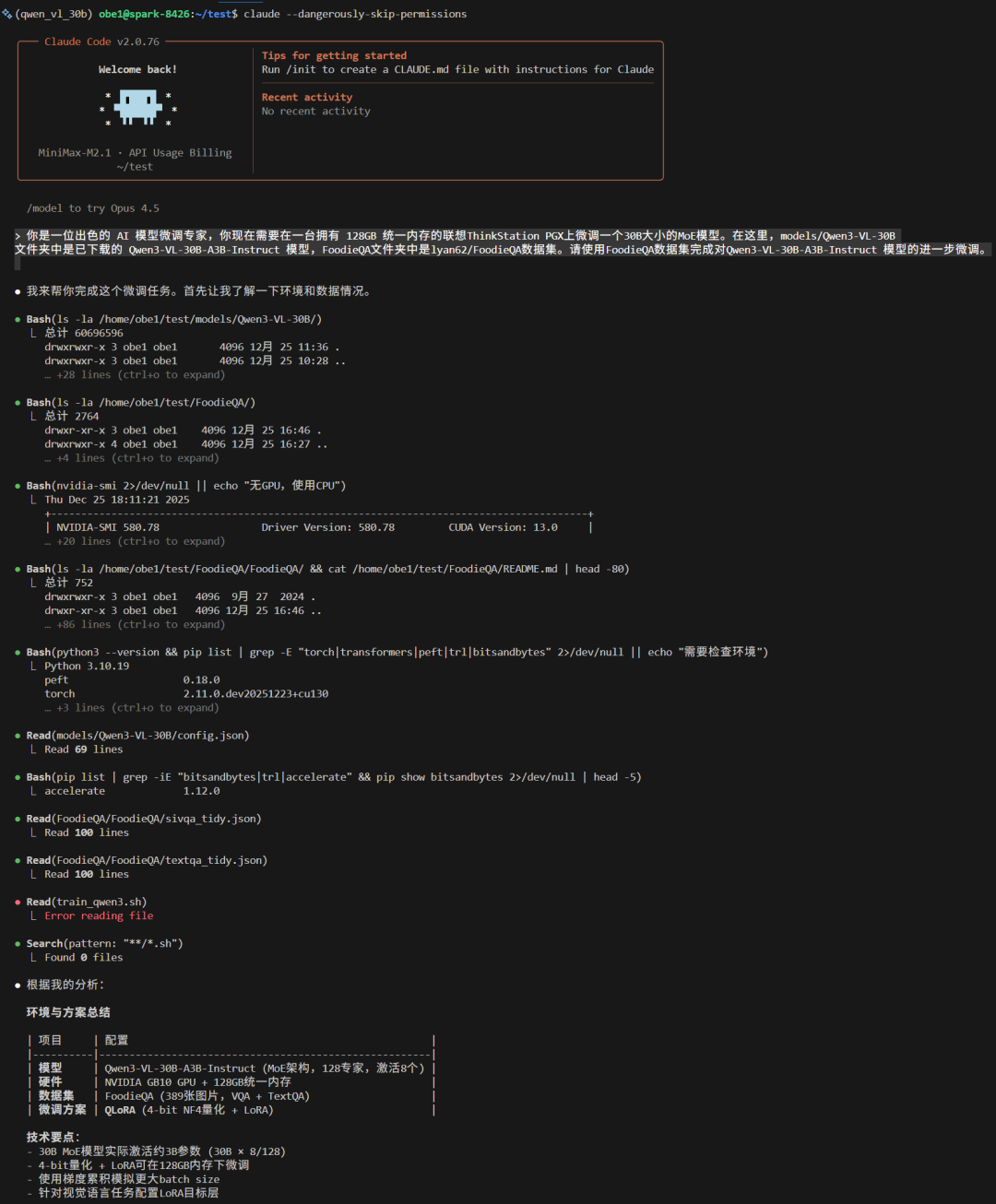
接下来就是等待。两三个小时后,训练方案终于确定下来。以下是训练稳定后nvtop监视画面。
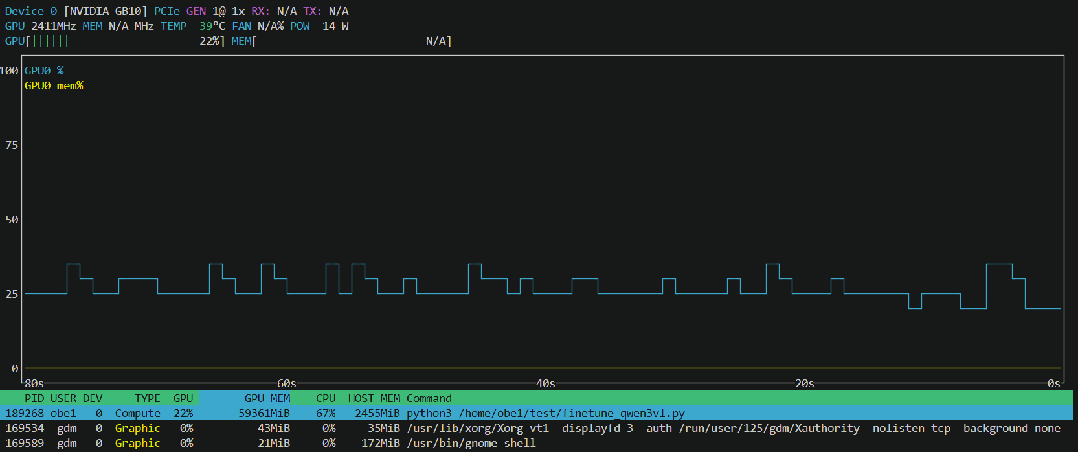
可以看到,对于该任务,GPU使用率大体在23%左右,显存(统一内存)的占用接近60GB。
要知道,这60GB的显存占用,如果是消费级显卡早就炸了三次了,但在ThinkStation PGX上,显存条只吃了一半,它甚至游刃有余。更令人印象深刻的是温控。得益于出色的散热设计,在开了暖气的房间里,ThinkStation PGX的GPU最高温度也仅达到了40℃。
一夜之后,微调完成。在验证集上的损失从4.03成功降到了1.06,下降了74%。

来一张我们自己拍摄的食物照片来简单试试。

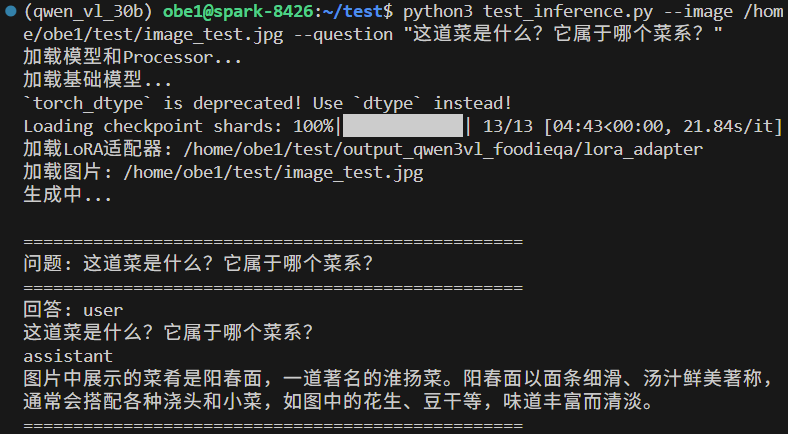
结果大体正确,这个微调过的Qwen3-VL-30B-A3B-Instruct正确识别了中间的阳春面,并正确地指出了其属于淮扬菜,不过它也忽略了旁边的蟹黄(确实有点难以辨认)。
整体体验下来,联想ThinkStation PGX展现出了几个让开发者无法拒绝的优势:
- 从容加载:128GB内存意味着我们可以不需要任何量化,甚至可以直接加载FP16/BF16精度的原始模型。
- 大胆训练:可以直接开启较大的Batch Size,不用担心OOM,训练效率成倍提升。
- 英伟达原生体验:基于Linux+CUDA,可以直接clone官方的微调代码库,配置好环境,一行命令
bash finetune.sh直接开跑,没有适配的痛苦。
结论很明显:联想ThinkStation PGX是目前桌面上唯一能让30B多模态模型「跑得舒服」的设备。
事实上,微调模型绝非PGX的唯一用途。打开想象力,我们能发现很多适合它的大显存AI场景,比如:
- 算法工程师的本地沙盒:用于金融或医疗等数据敏感行业。工程师可以在本地完整加载70B+模型验证想法,无需申请云端资源,数据绝不出域。
- 野外科研的离线算力站:对于珍稀动物监测或地质勘探,野外往往没有高速网络。PGX可塞进背包,离线处理海量红外监控影像。
- 长视频生成的无限画布:视频生成模型对显存需求随时间线性增长。PGX的大内存能支持生成更长时间的连贯视频素材。
- 具身智能的数字孪生:在桌面运行高保真的Isaac Sim仿真环境,训练完成后直接部署到架构同源的Jetson模块,零迁移成本。
- 数字艺术家的私有风格库:长期累积创作者自己的Style Checkpoint,本地运行风格迁移,不用担心独家画风泄露。
为什么选择联想ThinkStation PGX?
既然核心芯片和架构与英伟达的参考设计(DGX Spark)一致,为什么我们更推荐联想的PGX?
答案在于两个词:工程与服务。
驯服240W功耗的蜂窝美学
GB10是一颗性能强悍的超级芯片,但其满载功耗高达170W,整机功耗更达到240W。在一个1升的极小空间内压制这种热量,如果设计不当,很容易导致积热降频,甚至变成桌面烫手宝。
联想没有简单照搬公版设计,而是沿用了ThinkStation家族标志性的「蜂窝状」散热设计。这种源自空气动力学的设计理念(灵感源于阿斯顿・马丁的进气格栅),最大化了机箱前后的进出风效率。
实测表明,相比于初期公版参考设计可能存在的积热问题,PGX表现得更加「冷静」。对于需要连续跑几天几夜微调任务的开发者来说,这种基于顶级工作站大厂的工程稳定性,意味着你不用半夜起来担心训练因过热而中断。
数据保险
对于购买PGX的企业和科研用户来说,最值钱的往往不是机器本身,而是硬盘里的数据:那些私有的行业数据集、微调后的模型权重、以及核心算法代码。

作为中国市场份额第一的专业工作站品牌,联想给PGX配备了中国区独享的顶格服务:
- 3年上门保修:相比于海淘水货或部分竞品可能仅提供的1年质保,这是面向生产力用户更合理、也更负责任的保障方案。
- 硬盘数据恢复服务:这是最打动企业用户的痛点。万一硬盘发生物理损坏,联想提供专业的数据恢复服务。对于科研实验室等数据至关重要的机构来说,这项服务的价值远超机器价格本身。
- 售后技术支持:联想工作站在全国拥有超过1万名认证工程师,2300多个专业服务站,能保证7x24小时在线支持。
升级空间:双机NVLink
如果你觉得128GB依然不够用,PGX还预留了升级空间。
借助内置的NVIDIA ConnectX-7网络技术,你可以将两台ThinkStation PGX通过高速互联。在NVLink的加持下,两台机器瞬间化身为一个拥有 256 GB 统一内存 的超级怪兽。

这时,你的桌面算力上限将被进一步打破:你甚至可以尝试挑战上千亿参数量级别的超大模型推理。从1升小盒子到双机并行,这给了开发者极大的灵活性。
算力普及的「最后一公里」
回顾这几天的体验,联想ThinkStation PGX给我们留下的最深印象,并不是某个具体的跑分数字,而是它带来的「确定性」。
在过去,想要在本地搞定30B级别以上的多模态模型微调,总是充满了不确定性:显存会不会爆?量化会不会掉点?算子能不能跑通?
而ThinkStation PGX用128GB的海量统一内存和原生的CUDA生态,把这些不确定性变成了一条平滑的直线。它填补了消费级显卡(显存太小)和工业级服务器(动静太大)之间那个巨大的真空地带。
至于大家都关心的价格,在拥有128GB统一内存和原生CUDA生态的前提下,ThinkStation PGX 1TB版本售价为31999元,4TB版本售价为36999元。这仅仅相当于一块高端专业显卡的价格,却可以换来一台完整的、开箱即用的桌面AI超算。
如果要我以一个技术编辑的身份给一个购买建议,我的答案是:对于深陷显存焦虑的专业开发者而言,联想ThinkStation PGX不仅值得买,甚至可能是目前4万元以内唯一的最优解。
不妨算一笔账:在市面上,要获得同等规模(128GB)的显存容量,你通常需要购买昂贵的专业级计算卡,或者租用按小时计费且数据需上传云端的A100实例。而ThinkStation PGX以不到3.7万元的顶配价格,提供了一个拥有海量统一内存、原生CUDA生态且数据完全私有的桌面级方案。
如果你只是偶尔跑跑7B小模型,它或许略显奢侈;但对于那些受够了环境配置错误的算法工程师、对数据安全有极高要求的科研团队,以及希望快速验证idea的初创公司来说,PGX买到的不仅仅是硬件,更是「不折腾」的权利:让你不必再为显存溢出修改代码,也不必再为跨平台移植浪费时间。这种 让开发者回归创造力 本身的价值,远超机器售价本身。
这或许才是AI基础设施普及过程中,最动人的「最后一公里」。
 发表于 2026-1-14 00:40:29
|
查看: 203|
回复: 0
发表于 2026-1-14 00:40:29
|
查看: 203|
回复: 0
