无论是2026年伊始的AI应用入口争夺战,还是近期业内爆火的OpenClaw等项目,都清晰地预示着AI技术正加速进入广泛的生产落地阶段。行业的侧重点,正从过往的模型训练转向“训推并重与应用爆发”。如何利用现有技术成果实现快速开发和迭代,成为了新的关键。在这一背景下,开发者对高效、易用的AI开发设备的需求愈发迫切。
那么,AI时代的开发者究竟需要怎样的设备来提质增效?传统的PC在算力与显存上捉襟见肘,而庞大的服务器集群又过于昂贵和复杂。联想推出的ThinkStation PGX AI工作站(以下简称联想PGX工作站),正是瞄准了这一痛点,将强大的算力浓缩进仅1升的机箱,旨在成为开发者桌面上的“微型AI超算”。
这款工作站的核心,是一颗NVIDIA GB10 Grace Blackwell超级芯片,集成了20核ARM处理器与一个拥有6144个CUDA核心的Blackwell架构GPU。其在FP4精度下的峰值算力可达1 PFlops,而功耗不足240瓦。更关键的是,它集成了高达128GB的LPDDR5x统一内存,这极大地缓解了AI应用,尤其是大模型推理中常见的“显存焦虑”。
其小巧的体积(约15155.05厘米)使其能轻松融入办公室桌面、实验室工位乃至生产车间。无论是作为开发调试终端,还是部署在产线上执行视觉检测任务,联想PGX工作站都能凭借其稳定性和低噪音特性胜任。
原汁原味的软硬件生态
联想PGX工作站的外观设计简洁干练,正面为蜂窝格栅,背面接口齐全,包括两个200G QSFP网络接口、一个10GbE RJ-45网口、一个HDMI 2.1a接口以及四个USB-C 20G接口。
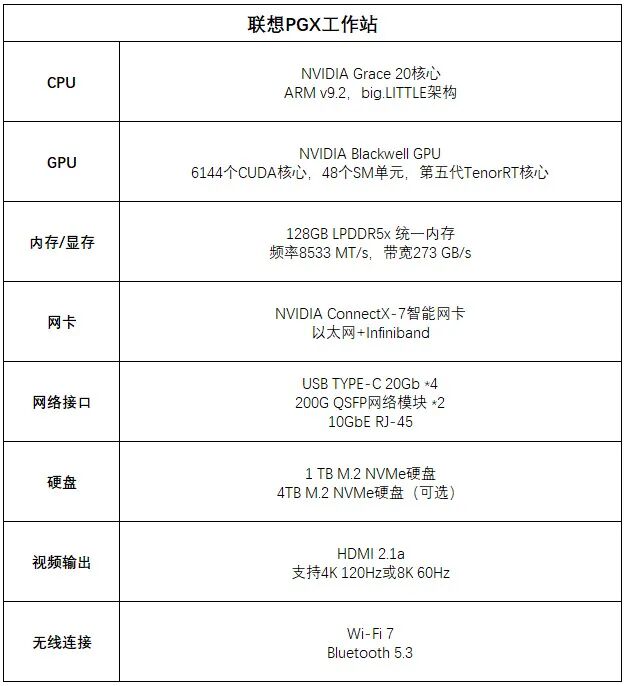
硬件配置对性能至关重要:
软件层面是其“开箱即用”体验的保障。它预装了基于Ubuntu 24.04 LTS的NVIDIA DGX OS系统及完整的CUDA工具生态,大幅降低了环境配置的复杂度。

实战性能测试:从语言模型到视频生成
我们将通过Ollama、ComfyUI等工具,测试联想PGX工作站在不同AI任务下的表现。
1. 大语言模型推理 (Ollama)
我们使用Ollama部署不同规模的模型,以“200字简述企业为什么需要AI”为提示词进行测试。
-
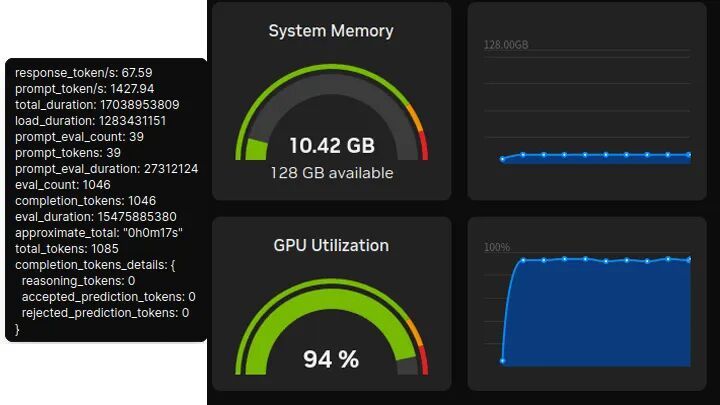
Qwen3:4b
性能:67.59 token/s,首token延迟:27.3ms。
统一内存占用:10.42GB(显存约3.2GB)。
-
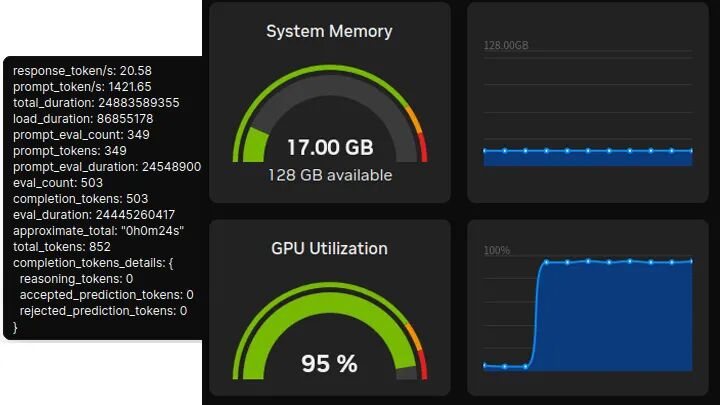
Qwen3:14b
性能:20.58 token/s,首token延迟:245.5ms。
统一内存占用:17GB(显存约9.4GB)。
-
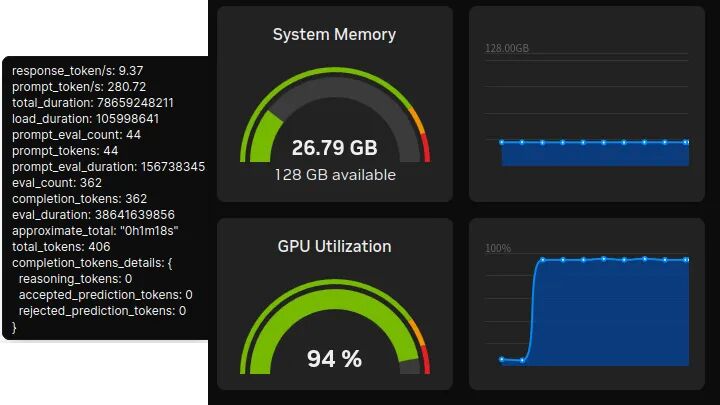
DeepSeek-r1:32B
性能:9.55 token/s,首token延迟:156.7ms。
统一内存占用:26.79GB(显存约20GB)。
-
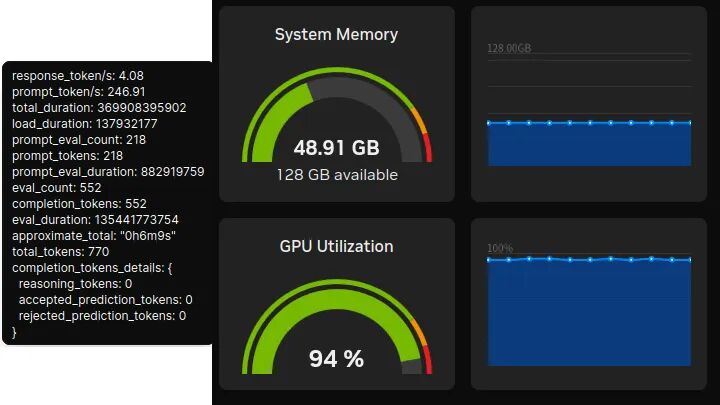
DeepSeek-r1:70B
性能:4.08 token/s,首token延迟:882.9ms。
统一内存占用:48.91GB(显存约41.7GB)。
-
Qwen3:30b-A3B (MoE模型)
性能:74.08 token/s,首token延迟:136.07ms。
统一内存占用:24.67GB(显存约18.2GB)。
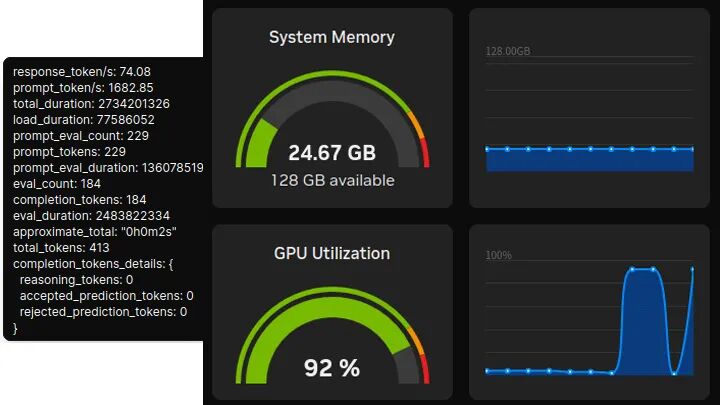
小结:得益于128GB统一内存,从4B到70B的模型均未出现“爆显存”现象。预装的CUDA环境使得通过Ollama部署模型异常顺畅,系统监控显示GPU利用率可轻松维持在95%左右。
2. 文生图与文生视频 (ComfyUI)
-
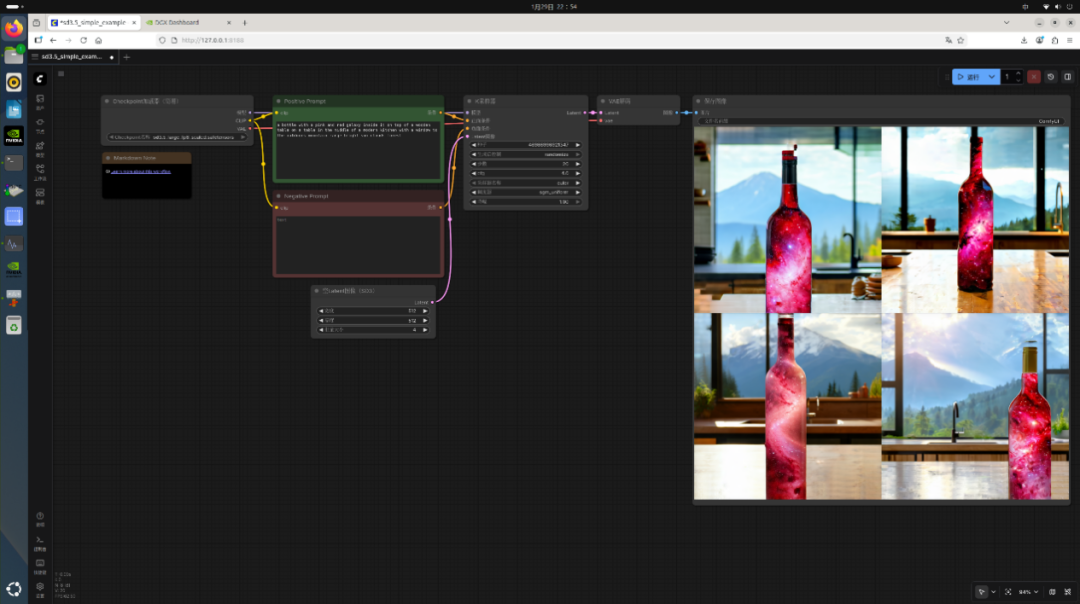
Stable Diffusion 3.5 文生图
使用FP8量化的SD3.5_large模型(约8B参数)。
正向prompt:a bottle with a pink and red galaxy inside it on top of a wooden table...
生成4张512x512图片总耗时:30.58秒。
统一内存占用:24.15GB(显存约14.55GB)。
-
Wan 2.2 文生视频
使用Wan2.2 14B FP8模型,生成5秒640x480分辨率视频。
生成总耗时:3分49秒。
统一内存占用:72.64GB(显存约53.8GB)。
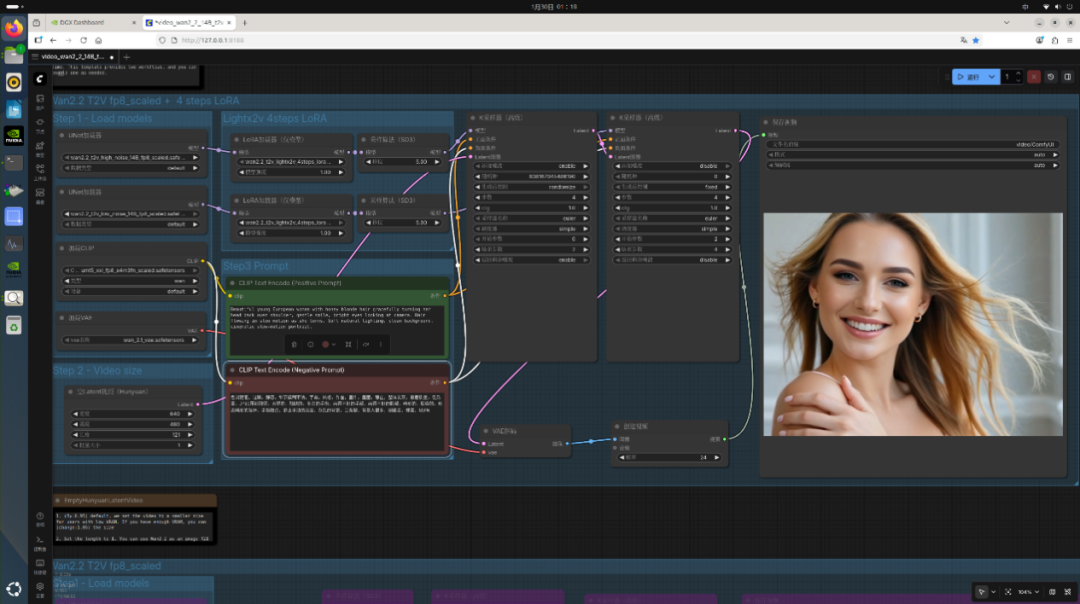
小结:文生图任务对PGX工作站游刃有余。即使是显存需求较高的14B文生视频模型,其内存占用也未超过总容量的60%,这在以往需要大型工作站才能实现。
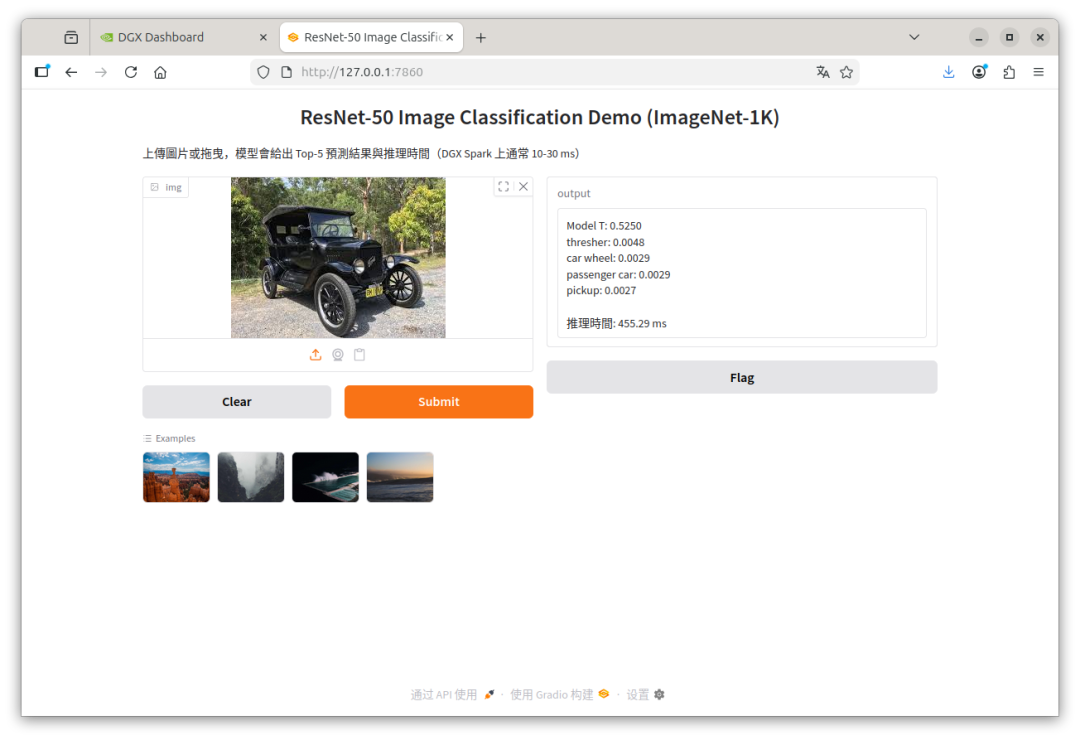
3. 图像识别 (ResNet50)
使用标准ResNet50模型进行图像识别,成功识别出车辆为福特T型,耗时仅455ms。此时统一内存占用约7.5GB,显存占用仅400MB左右。
4. 功耗、温度与噪音
在22℃、30分贝底噪的室内环境测试:
- 待机状态:整机功耗约40W,顶部温度26.4℃,人耳位噪音与环境底噪无异。
- 满载状态:整机功耗约190W,顶部温度29.1℃,人耳位噪音仅36.5分贝。
总结:桌面上的AI开发利器
经过多维度测试,联想ThinkStation PGX工作站展现了其作为“桌面微型AI超算”的强悍实力。20核Grace处理器与Blackwell GPU的组合性能出色,128GB统一内存让开发者可以更自由地选择模型,而无需频繁进行显存换算与模型切换。
其近乎无声的运行表现(满载仅36.5分贝)尤其令人印象深刻,非常适合需要安静环境的办公室与实验室。预装的全套CUDA生态则实现了真正的开箱即用,省去了大量环境配置与调试时间,这对于追求效率的开发者而言价值巨大。
综合来看,联想PGX工作站凭借其小巧的体积、强悍的算力、充足的内存、极致的静音和开箱即用的体验,为AI开发者、科研人员及教育用户提供了一个高效、可靠且易于部署的本地算力解决方案。对于希望快速拥抱AI时代,为团队配备敏捷开发工具的组织而言,它是一个值得认真考虑的选择。想要了解更多关于AI硬件、开发技巧与行业动态,欢迎访问云栈社区与大家交流讨论。 |  发表于 2026-2-28 06:07:41
|
查看: 317|
回复: 0
发表于 2026-2-28 06:07:41
|
查看: 317|
回复: 0
