一、什么是偏移量
当 Kafka 消费者每次调用 poll() 方法时,它获取到的都是生产者已写入但尚未被该消费者读取过的记录。为了追踪消息在分区中的消费进度,Kafka 引入了偏移量(Offset)的概念。简单来说,偏移量就是一个指向分区中特定消息位置的指针。
二、为什么需要偏移量
在理想情况下,如果一个消费者持续稳定运行,偏移量的作用并不凸显。然而,在实际的分布式环境中,消费者可能因故障崩溃,或者有新的消费者加入消费组,这时就会触发 “再均衡(Rebalance)”。
再均衡完成后,每个消费者可能会被分配到新的分区,而非之前正在处理的分区。为了确保消费任务能够从断点处无缝继续,而不是从头开始或遗漏数据,消费者必须知道每个分区上一次成功处理到的位置。这个位置信息,就是通过提交和读取偏移量来实现的。
三、如何提交偏移量
消费者通过向一个名为 __consumer_offset 的特殊主题发送消息来提交偏移量,这些消息中包含了各分区的偏移量信息。
提交偏移量的时机至关重要,不恰当的提交会导致两种典型问题:
- 重复消费:如果提交的偏移量小于客户端实际处理的最后一条消息的偏移量,那么处于这两个偏移量之间的消息将在消费者恢复后被再次处理。
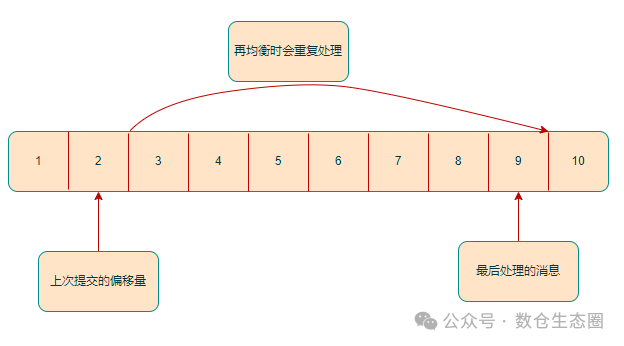
- 消息丢失:如果提交的偏移量大于客户端实际处理的最后一条消息的偏移量,那么处于这两个偏移量之间的消息将永远不会被处理,从而导致数据丢失。
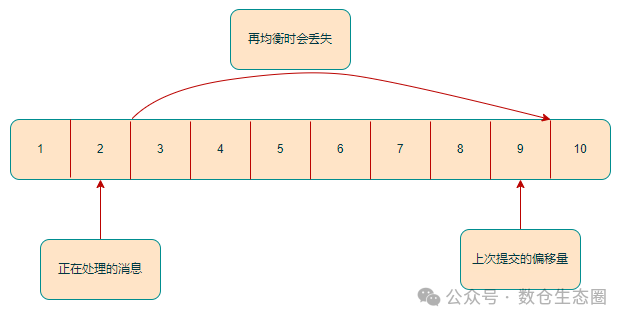
四、提交偏移量的方式
1. 自动提交
这是最简单的方式。只需将消费者配置 enable.auto.commit 设为 true,并通过 auto.commit.interval.ms 设置提交间隔(默认 5000 毫秒,即 5 秒)。消费者会在固定的时间间隔自动提交从 poll() 方法接收到的最大偏移量。
潜在问题:假设在自动提交完成后 2 秒发生了再均衡,那么在这 2 秒内已拉取但尚未提交的消息,在新消费者接管分区后会被重复消费。
2. 手动提交(程序控制)
将 enable.auto.commit 设为 false,由应用程序自主决定提交偏移量的时机。这提供了更强的控制力,避免因定时提交与消息处理进度不匹配带来的数据重复或丢失。
同步提交 (commitSync()):
这是最可靠的手动提交方式。只要没有发生不可恢复的错误,commitSync() 会阻塞当前线程直到偏移量提交成功。
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000L));
for (ConsumerRecord<String, String> record : records) {
System.out.println("key: " + record.key()+"-----分区:"+record.partition());
}
// 处理完一批消息后,同步提交偏移量
consumer.commitSync();
}
异步提交 (commitAsync()):
同步提交会阻塞应用,可能影响吞吐量。异步提交则不会等待服务器响应,允许在后台进行提交操作,并可通过回调函数获知提交结果。但请注意,它失败时不会自动重试。
consumer.commitAsync(new OffsetCommitCallback() {
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception e) {
if (e != null) {
// 记录提交失败日志,可根据业务逻辑决定是否重试
log.error("Commit failed for offsets {}", offsets, e);
}
}
});
混合提交策略:
一种常见的实践是:在常规消息处理循环中使用高效的 commitAsync(),而在消费者关闭前或处理特定逻辑时,使用可靠的 commitSync() 确保最终提交成功。
try{
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000L));
for (ConsumerRecord<String, String> record : records) {
System.out.println("key: " + record.key()+"-----分区:"+record.partition());
}
// 主循环中使用异步提交
consumer.commitAsync();
}
} catch(Exception e){
// 处理异常
} finally{
// 最终确保提交
try {
consumer.commitSync(); // 关闭前使用同步提交
} finally {
consumer.close();
}
}
3. 通过再均衡监听器提交
再均衡是提交偏移量的一个关键时间点。为了更精准地控制,我们可以实现 ConsumerRebalanceListener 接口,并将其传入 subscribe() 方法。该接口有两个核心方法:
-
public void onPartitionsRevoked(Collection<TopicPartition> partitions)
此方法在再均衡开始前、消费者停止读取消息后被调用。这是提交当前消费偏移量的理想时机,以确保接管分区的消费者能从正确位置开始消费。
-
public void onPartitionsAssigned(Collection<TopicPartition> partitions)
此方法在分区重新分配完成、消费者开始读取消息前被调用。通常在这里可以执行一些初始化操作,例如从自定义存储中读取偏移量。
下面是一个结合再均衡监听器、记录特定偏移量并灵活提交的 Java 消费者示例:
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props, new StringDeserializer(),
new StringDeserializer());
// 用于跟踪待提交的偏移量
Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();
class HandleRebalance implements ConsumerRebalanceListener {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
// 分区被回收前,同步提交当前累积的偏移量,确保不丢失
consumer.commitSync(currentOffsets);
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
// 分配到新分区后,可以在这里执行初始化,例如从数据库读取偏移量
}
}
// 订阅主题并传入再均衡监听器
consumer.subscribe(Collections.singletonList(topic), new HandleRebalance());
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000L));
for (ConsumerRecord<String, String> record : records) {
System.out.println("key: " + record.key() + "-----分区:" + record.partition());
// 在处理每条消息后,记录下一条待消费的偏移量 (offset + 1)
currentOffsets.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1, ""));
}
// 正常处理中,使用异步提交提高性能
consumer.commitAsync(currentOffsets, null);
}
} finally {
try {
// 最终退出时,使用同步提交确保成功
consumer.commitSync(currentOffsets);
} finally {
consumer.close();
}
}
理解并妥善管理 Kafka 消费者的偏移量提交,是构建可靠数据流处理应用的基础。选择适合业务场景的提交策略,能有效平衡数据一致性(不丢不重)与应用性能。希望本文的讲解能帮助你更好地驾驭 Kafka 的消费流程。更多关于分布式系统和消息队列的深度讨论,欢迎访问 云栈社区 与广大开发者交流。
 发表于 2026-1-16 00:00:20
|
查看: 136|
回复: 0
发表于 2026-1-16 00:00:20
|
查看: 136|
回复: 0
