大语言模型(LLM)智能体在执行需要跨越多轮对话的长期推理任务时,常常会遇到一个根本性的瓶颈:有限的上下文窗口。这使得对记忆进行高效管理变得至关重要。现有的主流方法通常将长期记忆(LTM)和短期记忆(STM)视为两个独立的组件,依赖启发式规则或额外的辅助控制器来进行管理。这种设计不仅限制了智能体的自适应能力,也难以实现端到端的全局优化。
传统架构的局限性在于,它们将LTM和STM处理为分离且松散耦合的模块。常见的有两种模式:一种是具备静态STM和基于触发器的LTM;另一种是具备静态STM和基于智能体的LTM。无论哪种模式,两个记忆系统都是被独立优化的,随后以一种临时的方式组合在一起,这导致了记忆构建过程的碎片化,并使得整体性能难以达到最优。
实现统一记忆管理主要面临三大挑战:
- 功能异构性的协调:LTM用于存储持久化知识,STM用于管理当前会话上下文,二者目的不同但必须互补协作。
- 训练范式的不匹配:现有的强化学习(RL)框架对这两种记忆类型采用了差异显著的训练策略。
- 实际部署的约束:许多系统依赖于额外的专家LLM来控制记忆,这显著增加了推理成本和训练复杂性。
为此,阿里巴巴集团与武汉大学的研究团队联合提出了Agentic Memory(AgeMem)。这是一个统一的记忆管理框架,旨在对LTM和STM进行联合优化管理。与先前将记忆视为外部组件的设计思路不同,AgeMem通过一套基于工具的统一接口,将两种记忆操作直接集成到智能体的决策循环中。团队还开发了一种配备逐步式GRPO机制的三阶段渐进式强化学习策略,以有效促进端到端的、统一记忆管理行为的学习。在多个模型与长期任务基准上的评估结果,充分验证了AgeMem在复杂智能体任务中的稳健性与卓越性能。

方法
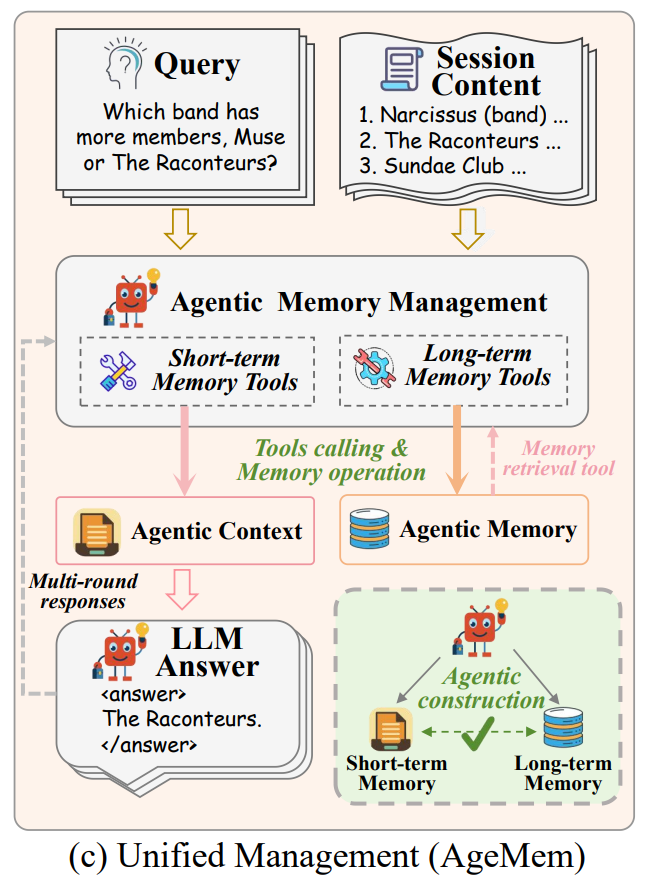
图1:AgeMem框架示意图
(1)统一记忆管理工具接口
如图2所示,AgeMem通过一套标准化的工具接口,将所有的记忆操作暴露给LLM智能体。智能体可以像调用普通函数一样,使用ADD、UPDATE、DELETE等工具来修改持久化的长期记忆(LTM),同时通过RETRIEVE、SUMMARY、FILTER等工具对短期记忆(STM)进行细粒度的控制。这种设计将复杂的记忆管理逻辑封装为智能体可理解和执行的动作,是实现统一控制的关键。

图2:AgeMem中用于操作长短期记忆的记忆管理工具定义示例
(2)三阶段渐进式RL策略
为了学习统一且稳定的记忆管理行为,研究团队设计了一个渐进式的三阶段训练策略。每个任务实例都会生成一个完整的轨迹:
- 阶段一(LTM构建):智能体在一个宽松的对话环境中接触大量上下文信息,学习识别并提取关键信息,将其存储到LTM中。
- 阶段二(含干扰的STM控制):短期上下文被重置,但LTM得以保留。智能体需要学习使用工具来过滤噪声、总结信息,从而高效管理有限的STM空间。
- 阶段三(集成推理与记忆协调):智能体接收正式的查询任务,此时它必须从LTM中检索相关知识、动态管理STM上下文,并最终生成准确的答案。
(3)逐步式GRPO优化机制
研究采用了逐步式GRPO(Group Relative Policy Optimization)的变体,以连接长周期任务的最终奖励与跨阶段的每一个记忆决策。该方法对每一组并行轨迹计算终端奖励,归一化优势后,将其广播给同轨迹的所有时间步。这使得最终的任务结果能够有效地监督每一个中间的记忆管理动作,实现了跨异构阶段的、长范围的信用分配。
其优化目标函数为:
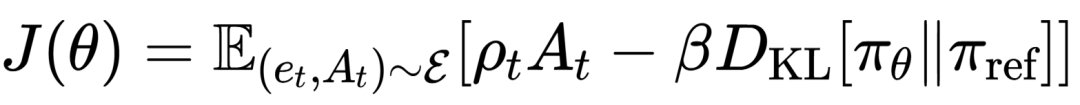
其中,ρ_t为新旧策略的概率比,D_KL为KL散度惩罚项,用于约束策略更新幅度,保证训练稳定性。
(4)复合奖励函数设计
总的轨迹级奖励R(τ)是一个复合函数,包含了任务完成奖励R_task、上下文管理奖励R_context和记忆管理奖励R_memory,并辅以违规惩罚项P_penalty:
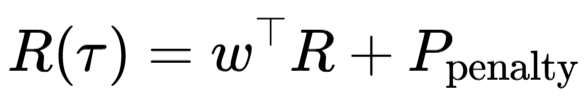
其中,权重向量w=[w_task, w_context, w_memory]^⊤,各奖励组件均被归一化到[0,1]区间。这种精心设计的奖励函数引导智能体不仅关注最终答案的正确性,也优化其在整个任务过程中的记忆管理行为。
评估
(1)多基准性能对比
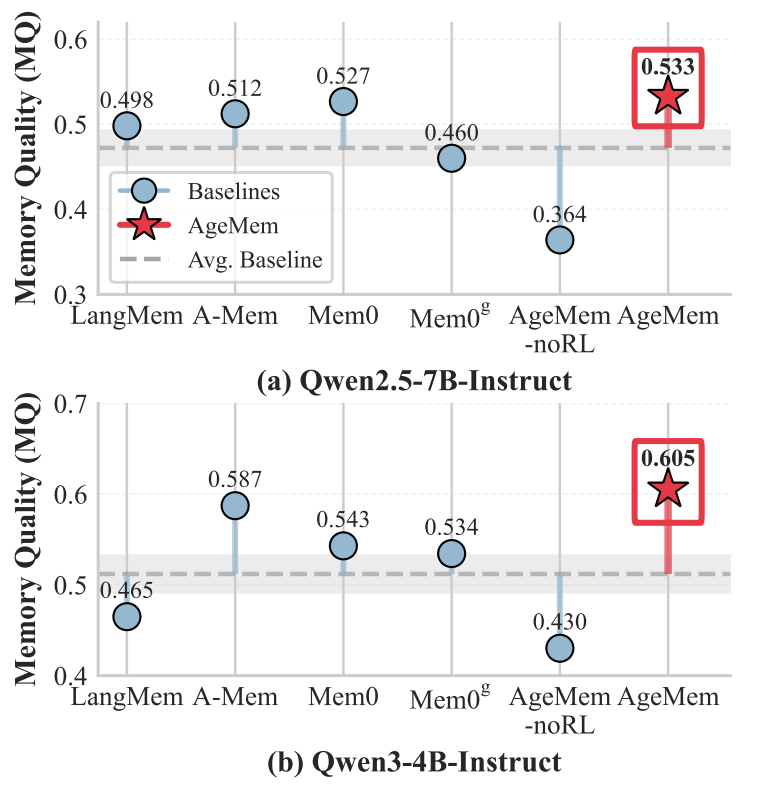
图3:在五个基准测试上的记忆质量(MQ)性能对比
在ALFWorld、SciWorld、PDDL、BabyAI和HotpotQA这五个具有挑战性的长期任务基准上,AgeMem在Qwen2.5-7B和Qwen3-4B模型上均取得了最高的平均性能,分别达到41.96% 和54.31% ,相对于无记忆管理的基线分别提升了49.59%和23.52%。与当前最佳基线Mem0和A-Mem相比,AgeMem平均分别提升了4.82和8.57个百分点。此外,强化学习训练本身带来了显著的增益,在两个模型上分别提升了8.53和8.72个百分点。
(2)记忆质量评估
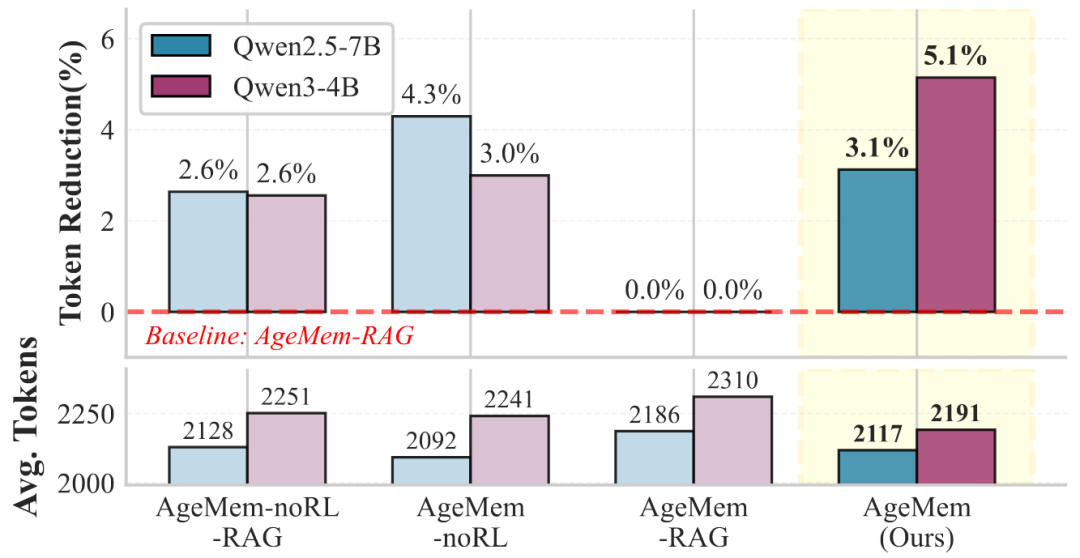
图4:HotpotQA上不同方法的记忆质量(MQ)分数
AgeMem在两个模型骨干上均取得了最高的记忆质量(MQ分数分别为0.533和0.605)。这一结果表明,统一的记忆管理框架不仅提升了任务解决性能,更重要的是促进了智能体存储更高质量、更可复用的知识。
(3)STM管理有效性
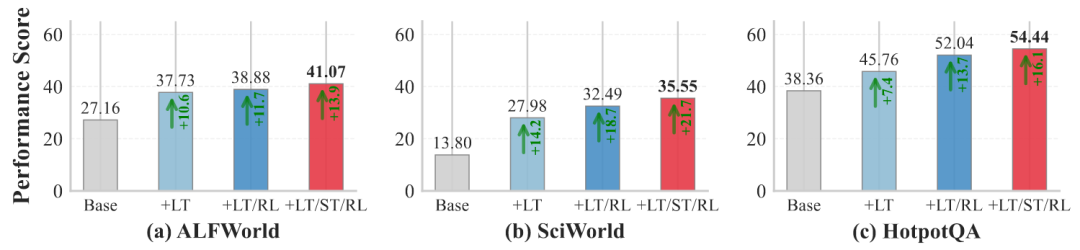
图5:不同STM配置下的性能得分消融研究
AgeMem成功减少了提示token的使用量。在Qwen2.5-7B上,其平均使用2117个token,相比没有STM工具管理的版本(2186个token)减少了3.1%;在Qwen3-4B上,则从2310个token降至2191个token,降幅达到5.1%。这证明了其STM管理工具在压缩和提炼上下文信息方面的效率。
(4)工具使用分析
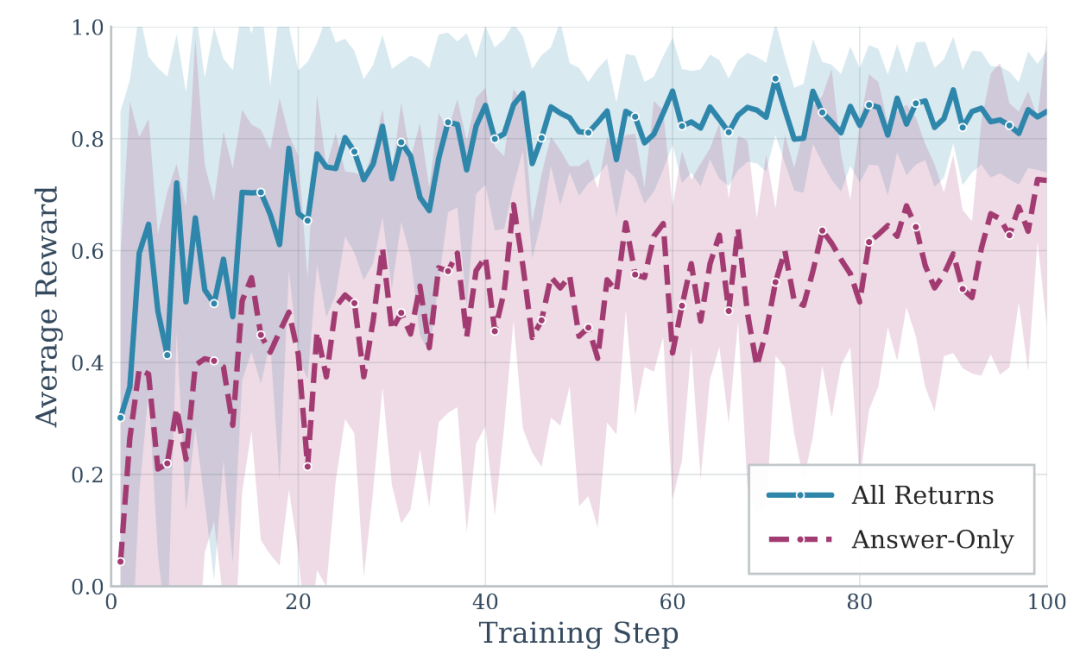
图6:训练过程中“全奖励”与“仅答案奖励”策略的平均奖励对比
RL训练显著增加了对长期记忆工具的使用。例如,ADD操作在Qwen2.5-7B模型上从平均每回合0.92次增加到1.64次,UPDATE操作从近乎为零增加到0.13次。同时,短期记忆工具的使用也更加均衡和主动,FILTER工具的调用次数从0.02次显著增加至0.31次。这表明智能体通过训练学会了更积极地维护和利用记忆。
(5)消融研究
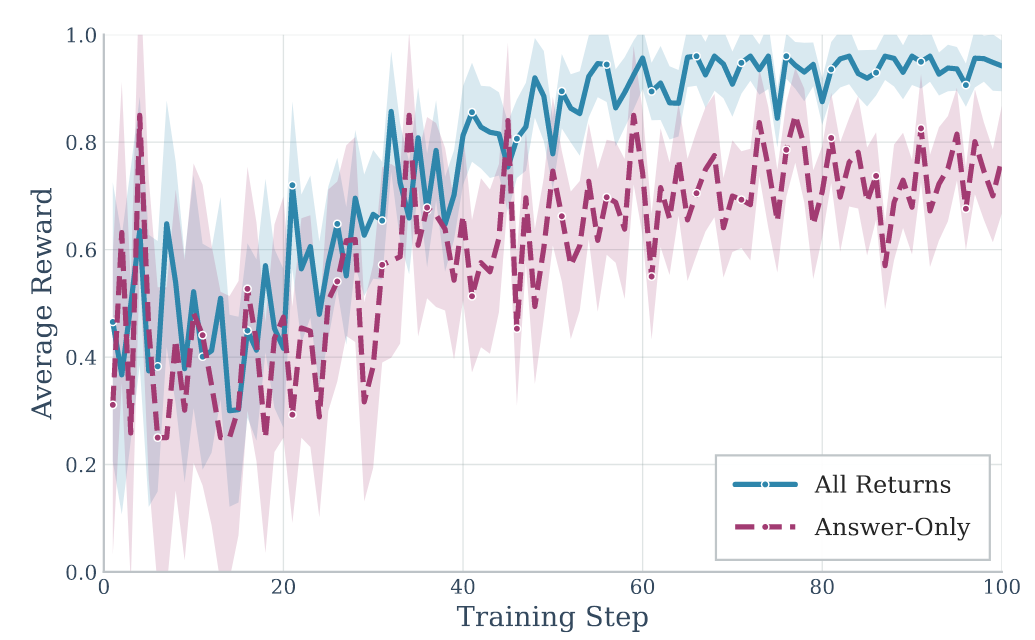
图7:HotpotQA上不同方法的工具使用统计
对各组件的消融研究清晰展示了每个部分的价值:添加LTM管理(+LT)较基线带来了10.6%–14.2%的性能增益;在此基础上加入RL训练(+LT/RL)后,在HotpotQA上性能进一步提升了6.3%;而完整的AgeMem系统(+LT/ST/RL)在所有基准上都取得了最佳结果,整体性能提升了13.9%–21.7%。
(6)奖励函数设计验证
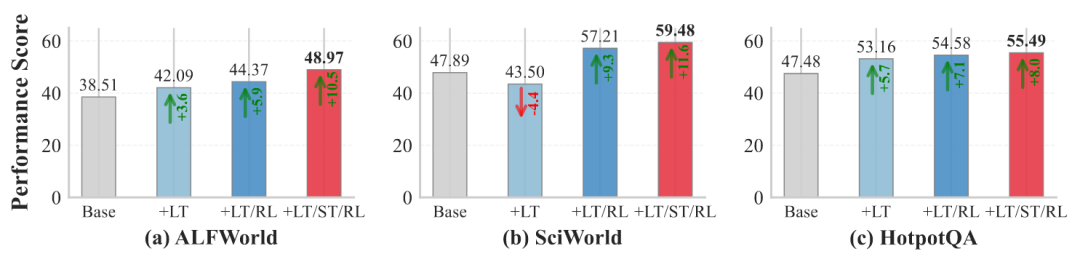
图8:更广泛环境下的组件消融研究
团队设计的复合奖励函数策略(All-Returns)比仅使用最终任务奖励的策略(Answer-Only)收敛速度更快,且最终达到的性能更高。全奖励策略在保持更高LLM评判分数(0.544 vs 0.509)的同时,记忆质量也获得了显著提升(0.533 vs 0.479),验证了其奖励函数设计的有效性。
总结:Agentic Memory (AgeMem) 通过创新的统一工具接口和三阶段渐进式强化学习策略,为大语言模型智能体的记忆管理问题提供了一个强大而高效的解决方案。其在多项基准测试中展现出的优越性能,标志着人工智能体在长期、复杂任务处理能力上迈出了重要一步。对这项前沿技术更深入的解读与代码实践,欢迎关注 云栈社区 获取更多资讯。
 发表于 2026-1-16 02:18:13
|
查看: 297|
回复: 0
发表于 2026-1-16 02:18:13
|
查看: 297|
回复: 0
