在并发编程的世界里,操作的顺序并非理所当然,而是需要开发者通过正确的同步机制去争取的。这句话,是我在排查一个棘手的跨平台Bug后才深刻体会到的。
当时,我们开发的防伪追溯系统在 x86 服务器上运行稳定,但迁移到 ARM 架构的边缘设备后,系统行为便变得不可预测。软件并未崩溃,日志也一切正常,但业务结果就是会出错,排查过程令人十分抓狂。
最终,问题根源锁定在了内存序的使用上。我们错误地认为,仅用 memory_order_acquire/release 同步两个独立的原子标志就足够了。然而,在弱内存模型的架构下,不同线程观察到的操作顺序,可能完全不同。
acquire-release 内存序能保证单个原子变量上的因果链,却无法强制多个变量在全局视角下保持一致顺序。 而 seq_cst(顺序一致性),正是 C++ 标准为我们提供的,用于建立全局一致顺序的最终手段。
一、acq_rel 的能力边界
acquire 和 release 内存序的核心作用是建立 happens-before 关系,但这一关系仅限于同一个原子对象上的操作链。

它的典型应用场景是发布-订阅模式:
std::atomic<bool> ready{false};
Data data;
// 生产者
data = compute();
ready.store(true, std::memory_order_release); // 保证data的写入在store前完成
// 消费者
if (ready.load(std::memory_order_acquire)) {
use(data); // 此时一定能看到完整的data
}
在这个例子中,ready 是唯一的同步点。release 操作保证 data = compute() 的写入在其之前完成,而 acquire 操作保证 use(data) 在其之后执行,二者配对形成了有效的同步。这完全在 acq_rel 的能力范围内。
但当场景涉及多个独立的原子变量时,acq_rel 的局限性就暴露无遗。
二、acq_rel 失效的经典反例:IRIW 问题
IRIW(Independent Reads of Independent Writes,独立写入的独立读取)问题是揭示弱内存模型复杂性的一个经典案例。

考虑以下代码:
std::atomic<int> x{0}, y{0};
// T1: x.store(1, std::memory_order_release);
// T2: y.store(1, std::memory_order_release);
// T3: r1 = x.load(memory_order_acquire); r2 = y.load(memory_order_acquire);
// T4: r3 = y.load(memory_order_acquire); r4 = x.load(memory_order_acquire);
直觉上,你可能认为不可能同时出现 T3 看到 (x=1, y=0) 而 T4 看到 (y=1, x=0) 的情况。因为 T1 和 T2 的写操作总该有一个全局顺序,所有线程理应看到一致的结果。
然而,在 C++ 的 acquire-release 内存模型下,这是完全合法的执行轨迹。原因在于 x 和 y 是两个独立的同步点。T3 观察 x 和 y 的顺序,与 T4 观察二者的顺序,允许完全不同。C++ 内存模型并不要求不同原子变量之间的操作顺序在所有线程间保持一致。
在 x86 架构上,由于其硬件内存模型接近于顺序一致,这种现象极少发生,容易让开发者产生误判。但在 ARM 或 POWER 这类弱内存模型架构上,存储缓冲区和缓存一致性协议允许这种分歧真实存在。这正是我们之前在跨平台多线程代码中踩坑的原因。
三、seq_cst 的核心价值
memory_order_seq_cst 在 acq_rel 的基础上,提供了更强的保证:所有 seq_cst 操作(无论涉及多少个不同的原子变量)必须能被排入一条所有线程都认可的单一全局总序,并且该总序与每个原子变量自身的修改顺序保持一致。
将上述 IRIW 示例中的内存序全部改为 seq_cst:
// T1: x.store(1, std::memory_order_seq_cst);
// T2: y.store(1, std::memory_order_seq_cst);
// T3: r1 = x.load(memory_order_seq_cst); r2 = y.load(memory_order_seq_cst);
// T4: r3 = y.load(memory_order_seq_cst); r4 = x.load(memory_order_seq_cst);
现在,C++ 内存模型将禁止矛盾轨迹的出现。如果 T1 的 store 在全局总序中排在 T2 之前,那么所有后续的 seq_cst load 操作都会看到这个顺序。T3 和 T4 不可能再对 x 和 y 的写入顺序产生分歧。这就是 seq_cst 提供的核心价值——全局顺序的一致性保证,它关乎的是程序的正确性,而非单纯的性能。
四、必须使用 seq_cst 的场景
1、经典无锁算法
许多经典的无锁算法,如 Peterson 算法,其正确性依赖于顺序一致的假设。在弱内存模型下,仅使用 acq_rel 可能导致活锁或互斥失败。
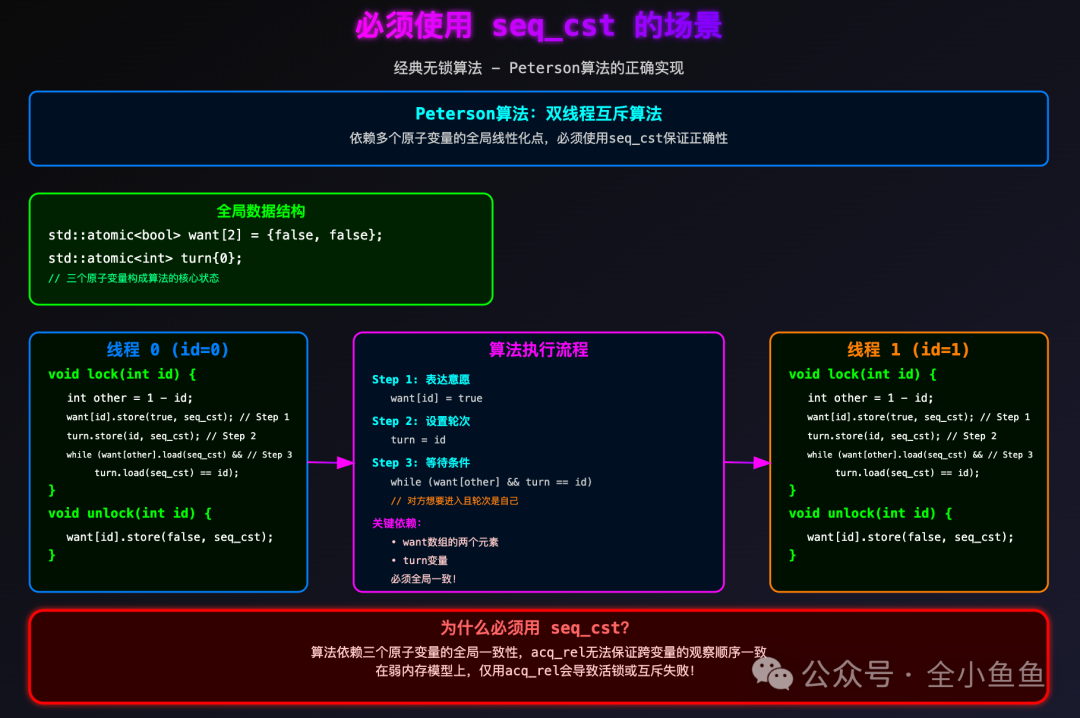
Peterson 算法的正确实现必须使用 seq_cst:
std::atomic<bool> want[2] = {false, false};
std::atomic<int> turn{0};
void lock(int id) {
int other = 1 - id;
want[id].store(true, std::memory_order_seq_cst); // Step 1
turn.store(id, std::memory_order_seq_cst); // Step 2
while (want[other].load(std::memory_order_seq_cst) && // Step 3
turn.load(std::memory_order_seq_cst) == id);
}
void unlock(int id) {
want[id].store(false, std::memory_order_seq_cst);
}
这个例子清晰地表明,当算法逻辑依赖于多个原子操作变量的全局线性化点时,seq_cst 是最直接可靠的保障,否则在不同架构下可能出现难以复现的并发错误。
2、分布式一致性协议的本地并发部分
例如,在实现 Raft 一致性算法时,日志的 term 和 index 通常需要被原子地更新和读取。如果使用两个独立的原子变量来表示,而某个 Follower 线程需要同时读取二者以判断日志是否最新,那么就必须保证它们的更新顺序在所有观察者线程眼中是一致的。否则,可能出现观察到新 term 但旧 index 的非法中间状态,破坏协议的正确性。
五、如何判断是否需要 seq_cst?
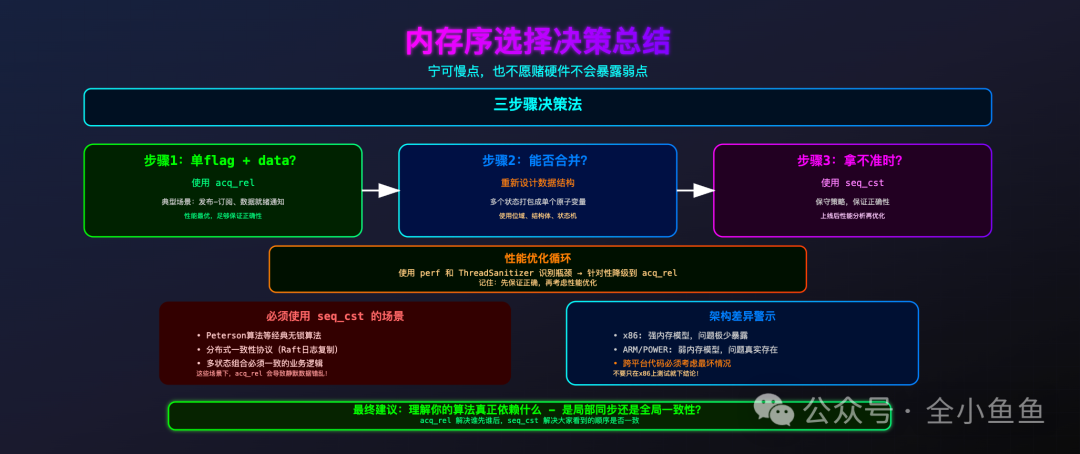
面对复杂的并发编程场景,可以采用一个三步决策流程来判断内存序的选择。
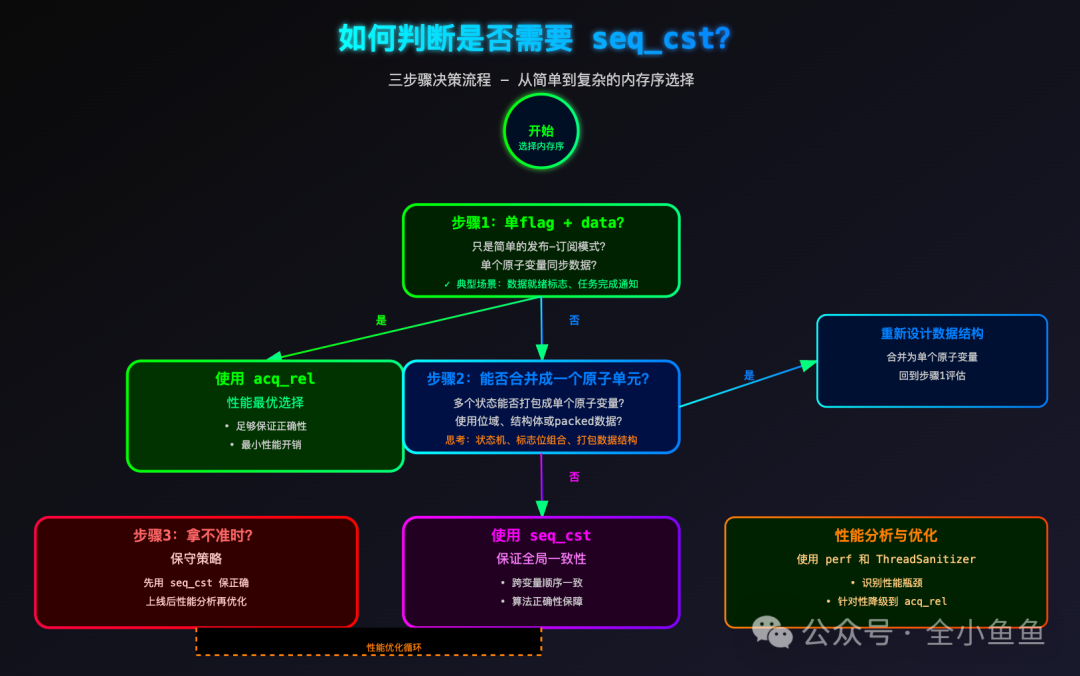
- 检查是否为单 Flag + Data 模式:如果只是简单的发布-订阅,单个原子变量同步一块数据,那么
acq_rel 完全足够,且性能最优。这是 C++ 并发编程中最常见和推荐的模式。
- 评估能否合并状态:当涉及多个必须保持一致的状态时,首先考虑能否将它们合并成一个原子单元(例如使用位域、结构体或
std::atomic<T> 其中 T 为自定义类型)。如果能够合并,问题就回到了步骤1。如果无法合并,或者合并后逻辑过于复杂,那么就应该使用 seq_cst 来保证全局一致性。
- 保守策略与事后优化:当无法确定时,一个稳妥的策略是先用
seq_cst 保证正确性。程序上线后,再利用 perf、ThreadSanitizer 等工具进行性能剖析,识别出真正的瓶颈点,再有针对性、有依据地将部分 seq_cst 操作降级为 acq_rel。
简单来说,acq_rel 解决的是“局部谁先谁后”的同步问题,而 seq_cst 解决的是“全局顺序是否一致”的共识问题。选择哪一个,根本在于分析你的算法逻辑到底依赖于何种保证。
在并发编程中,有时候“宁可慢一点,也不愿去赌硬件或编译器优化是否会暴露内存模型的弱点”。正确性永远应该排在性能之前。
希望本文对 C++ 内存序的探讨,能帮助你在实际开发中做出更清晰的选择。欢迎在云栈社区的 C/C++ 板块与更多开发者交流并发编程的经验与心得。
 发表于 2026-1-16 02:13:34
|
查看: 210|
回复: 0
发表于 2026-1-16 02:13:34
|
查看: 210|
回复: 0
