在做后端开发的这些年,我发现一个特别有意思的现象:很多人愿意花大把时间去优化业务逻辑、折腾无锁队列、研究内存池,但一提到日志,普遍的态度就是随意选择一个库,调用API便告完成。
结果上线一压测才发现,P99延迟怎么也压不下去。用 perf 工具一分析,好家伙,CPU周期全都消耗在 LOG_INFO 这样的日志调用上了。
今天我们来聊聊 C++ 圈子里公认的日志库天花板 spdlog。它凭什么能做到极低的延迟开销?背后有哪些值得借鉴的工程思想?
常规日志库为什么慢?
当你在主线程调用一条日志时,如果直接写入磁盘,哪怕只是几毫秒的延迟,在高并发场景下也会被无限放大:线程阻塞、上下文切换、整体延迟飙升。
spdlog 的核心解法是 异步日志模型:将生产者(业务线程)和消费者(写入线程)解耦。
当你调用 logger->log(...) 时,spdlog 只是将格式化所需的数据打包,扔进一个预分配好的环形队列中,然后你的业务线程直接返回。整个过程仅需几个纳秒。
真正的磁盘写入操作,则交给后台的线程池异步处理。
队列满了怎么办?
当高并发洪峰来袭,后台线程的写入速度跟不上前端日志产生的速度时,队列可能会满。对此,spdlog 提供了几个务实的策略选项:
阻塞策略
等待队列有可用空间后再继续执行。这种策略保证了日志绝不丢失,但有可能拖慢业务线程的速度。
丢弃策略
直接丢弃最新的日志,或者覆盖最旧的日志。在服务可用性高于一切(例如在极端高负载下需要保证核心服务响应)的场景中,这种“弃车保帅”的思路反而更为合理。
没有标准答案,关键是根据业务场景做出取舍。
格式化层面的极致优化
将 I/O 操作移交给后台线程只是性能优化的第一步。字符串格式化 本身也是 CPU 消耗的大户。
使用过 snprintf 的开发者都知道,这个函数每次调用都需要重新解析格式符,且类型安全性欠佳。std::cout 在高频调用场景下的性能更是差强人意。
spdlog 在格式化层面主要做了两件事:
模式串预编译
大多数日志库每次打印日志时,都需要重新解析 %Y-%m-%d %H:%M:%S 这类时间格式字符串。而 spdlog 在调用 set_pattern() 设置格式时,就已经将模式字符串编译成了高效的内部执行结构。真正记录日志时,不再需要解析模式串。
内置 fmt 库
spdlog 的底层使用了著名的 {fmt} 库(C++20 的 std::format 即基于此)。fmt 库充分利用 constexpr 进行编译期类型推导,并内置了高度优化的整数与浮点数转字符串算法,使得整个格式化过程几乎实现了零拷贝。
清晰的分层架构设计
观察 spdlog 的架构,可以清晰地分为三层:Registry -> Logger -> Sink。
- Registry:全局管理器,负责维护所有 Logger 实例。
- Logger:暴露给业务代码的接口,负责处理日志级别过滤。
- Sink:具体的日志输出地,例如按天滚动的
daily_file_sink、按大小滚动的 rotating_file_sink、输出到控制台的 stdout_sink 等等。
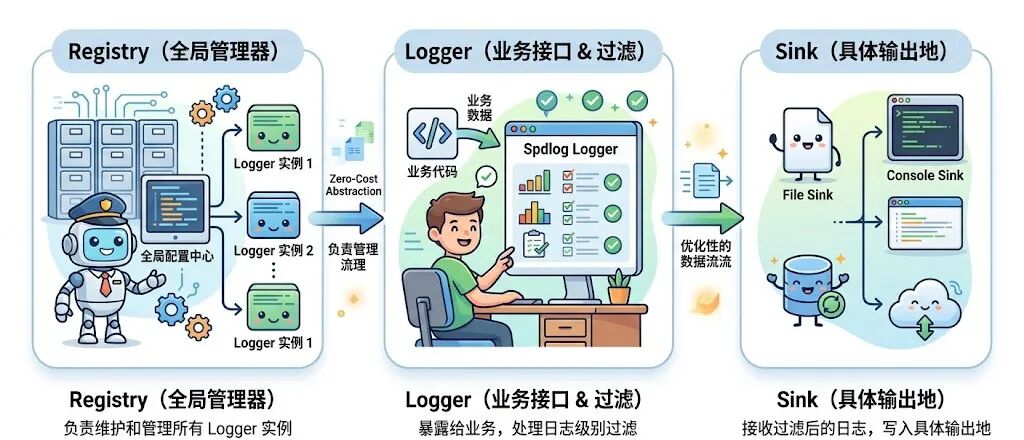
这种分层设计带来的好处显而易见:你可以在同一个 Logger 下挂载多个 Sink(例如同时写入文件和打印到控制台),而业务层的代码完全无需修改。
此外,spdlog 默认以纯头文件库的形式提供,大量使用了模板和 inline 函数。一方面,开发者省去了编译和链接依赖的麻烦;另一方面,当编译器开启 -O2 或 -O3 优化时,能够将这些封装函数直接在调用处内联展开,从而省去了传统库函数调用时创建栈帧的昂贵开销。
总结
spdlog 之所以能被广泛采用,并非依赖于任何花哨的技巧,而是源于其对计算机底层原理的深刻尊重:将阻塞操作剥离出关键热路径、将运行时的解析提前到编译期完成、并通过零成本抽象榨干 CPU 的每一分性能。
这种专注于核心瓶颈、务实而高效的 开源实战 设计思想,非常值得我们在构建自己的 技术文档 和系统时借鉴。对高性能 后端 & 架构 感兴趣的开发者,也可以多在 云栈社区 交流探讨相关话题。
 发表于 2026-4-19 04:40:09
|
查看: 137|
回复: 0
发表于 2026-4-19 04:40:09
|
查看: 137|
回复: 0
