说起 TanStack,可能很多开发者会觉得陌生,甚至会想:这又是一个新框架?新概念?我还没学明白 React / Vue,又来一个?
事实上,如果从 GitHub 的数据来看,TanStack 已然是一个知名度相当高的开源组织。
并且,很多开发者可能早已用过 TanStack 的产品而不自知。因为你可能叫它 React Query 或者 Vue Query。

一、从 React Query 说起
我们不妨先回顾一下早期的 React Query。
那么,React Query 究竟是用来解决什么问题的?不妨思考一下我们日常开发中的这些场景:
- 在
useEffect 中编写异步请求。
- 手动维护
loading、error、data 等状态。
- 切换页面后再返回,数据被重新请求。
- 列表页与详情页数据不一致。
- 某个操作完成后,不清楚是否需要主动刷新数据。
这些问题都指向了一个核心命题:来自后端服务器的数据状态,真的应该由前端手动管理和维护吗?
React Query 给出的答案是:不应该。服务器状态应被视为一种独立的、需要被专门缓存和管理的资源。
基于这一理念,React Query 为我们做了几件至关重要的事情:
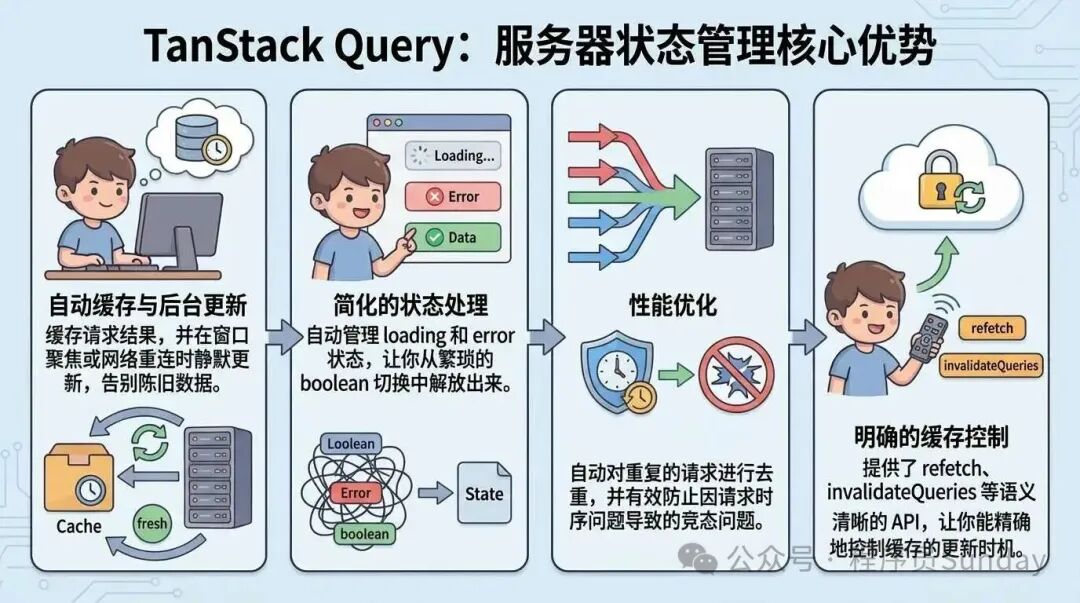
- 自动缓存与后台更新:缓存请求结果,并在窗口聚焦或网络重连时静默更新,有效避免数据过时。
- 简化的状态处理:自动管理
loading 和 error 状态,将开发者从繁琐的布尔值切换中解放出来。
- 性能优化:自动对重复请求进行去重,并有效防止因请求时序导致的竞态问题。
- 明确的缓存控制:提供
refetch、invalidateQueries 等语义清晰的 API,让你可以精确控制缓存的更新时机。
因此,React Query 的真正价值并不仅仅是“少写几个 useEffect”。它所做的,是在前端领域首次将 「服务端状态」 从 UI 状态中清晰地剥离出来,并为它构建了一套完整、可预测的管理模型。
二、React Query 的局限性与真实挑战
读到此处,你或许会觉得 React Query 已经相当不错。然而,一旦将其应用于真实复杂的业务项目,一些局限性便会浮现。这也是 TanStack Query 诞生的背景。
React Query 主要存在以下几个问题:
1. 本质仍是「React 专用方案」
这意味着 Vue 或 Solid 等其他框架的开发者无法直接使用。这导致了一个现实困境:你的“数据建模经验”无法跨技术栈复用。
2. 解决了“请求”,但未解决“系统复杂度”
在真实的业务场景中,异步请求很少是孤立的。例如:列表请求与筛选条件联动、路由参数与数据请求的依赖、表格分页与复杂的缓存策略等。
React Query 擅长管理「请求结果」,但它无法管理整个由多个状态联动构成的“系统”。
3. 能力越强,架构问题越凸显
这是一个微妙的点。当你深度使用 React Query 时,越容易意识到:真正复杂的不只是发送请求,而是“数据与数据之间的关系”。
这些关系本质上涉及路由、表格结构、分页、筛选、虚拟滚动等多个维度之间的联动。React Query 解决了数据获取与缓存,但它本身无法承载这些多维度的复合复杂度。
三、TanStack 的破局之道:构建前端状态建模层
TanStack 的出现,正是为了系统性地解决上述问题。它做了一件至关重要的事:将“框架无关的核心状态逻辑”彻底抽离。
TanStack 的本质不是“升级版 React Query”,而是一个 「前端复杂状态建模层」。它主要完成了三件大事:
1. 核心逻辑与 UI 框架解耦
它提供了大量的适配器,可以与任何主流前端框架结合使用。

如今的 TanStack Query:
- 核心状态逻辑完全框架无关。
React / Vue / Solid 等仅作为“适配器”层。- 服务端状态的建模方式实现了统一。
这意味着,你学习的是“数据系统思维”,而不仅仅是某个特定框架的 API。
2. 从“孤立能力”到“系统能力”
让我们看看 TanStack 提供的完整工具箱:

于是,我们看到了:
- TanStack Query → 专注于服务端状态管理。
- TanStack Table → 专注于表格状态与交互逻辑。
- TanStack Router → 专注于路由状态与数据加载。
- TanStack Virtual → 专注于大数据集的虚拟化渲染。
它们有一个共同的核心理念:不提供具体的 UI 组件,只提供确定性的、可预测的状态模型与 API。 这种系统性整合,是 React Query 单体库难以企及的。
3. 以“数据状态”为中心重构前端架构
在 TanStack 的理念体系中:
- 路由不仅仅是页面切换,更是数据加载与状态的前置条件。
- 表格不是一个 UI 组件,而是一套可排序、可筛选、可分页的数据状态机。
- 请求不是副作用,而是声明式的数据依赖与同步过程。
它们全都是:可预测、可组合、可推导的数据状态单元。 这也解释了为什么 TanStack Router 能与 Query 深度集成,而不仅仅是完成“页面跳转”。
四、为何说 TanStack 定义了新的协作模式?
它试图让 React、Vue 等框架回归其最擅长的领域。
1. 让 UI 库回归本职
还记得 React 和 Vue 的本质是什么吗?

借用 Vue.js 官方文档的定义:它们本质上是 UI 库。最核心的职责是:高效地将状态(State)渲染为用户界面(UI)。
但在 TanStack 这类方案普及之前,我们常常让它们承担了过多职责:手动管理异步数据、处理缓存、解决竞态条件……这导致组件代码臃肿,UI 逻辑与业务逻辑高度耦合。
TanStack 的出现,正是为了让 React 和 Vue 回归其渲染引擎的本职。
2. 提供跨框架的“通用语言”
React 和 Vue 生态之间存在一定的隔阂,许多优秀的解决方案无法直接互通。
而 TanStack 提供了一套 “通用语言”。无论你的团队使用 React、Vue 还是 Svelte,都可以基于 TanStack 的核心思想(如 Query 的缓存策略、Table 的状态设计)来构建应用。你在一个框架下学到的状态建模经验,在其他框架下依然适用。
这意味着开发者的经验更具普适性,团队的知识资产可以沉淀,技术栈选型的风险也随之降低。这无疑推动了整个 开源 前端生态的融合与进步。
3. 描绘“现代前端应用”的理想架构
TanStack 全家桶实际上向我们展示了一个理想的现代前端应用架构蓝图:
- 状态层(State Layer):由
TanStack(Query, Router, Table, Form…)负责。它完全独立于 UI,承载所有业务逻辑、数据管理、状态联动与副作用处理。
- 视图层(View Layer):由
React / Vue 等 UI 框架负责。它是一个纯粹的“渲染引擎”,职责单一:将状态层输出的状态高效、响应式地映射到 DOM。
这种清晰的关注点分离,使得应用更易于理解、测试和维护。它代表了前端工程化从“以视图为中心”向“以数据状态为中心”演进的重要趋势。关于这一架构模式的更多讨论与实践,欢迎在 云栈社区 与广大开发者一起交流。
 发表于 2026-1-17 00:36:34
|
查看: 159|
回复: 0
发表于 2026-1-17 00:36:34
|
查看: 159|
回复: 0
