近年来,随着ChatGPT、DeepSeek等大模型的火爆,AI技术已经渗透到工作和生活的方方面面。而在资源受限的嵌入式领域,端侧AI也逐渐成为新的发展方向。你是否想过,在内存仅有几KB的单片机上也能运行AI模型?今天,我们就来深入探讨一个极为轻量级的嵌入式机器学习推理框架——uTensor。
关于 uTensor 模型
uTensor 是一个基于 TensorFlow 构建的、极其轻量级的机器学习推理框架,并针对 Arm 处理器进行了优化。它本质上由一个运行时库和一个负责模型转换的离线工具组成。
项目地址如下:
https://github.com/uTensor/uTensor
该仓库包含了核心运行时、算子库、内存管理器、调度器等示例实现。其最引人注目的特点在于,核心运行时的体积被压缩到了惊人的 2KB!

uTensor 是如何做到如此极致的轻量化呢?其秘诀在于独特的模型转换与内存管理机制。它能够将训练好的 TensorFlow 模型直接转换为 .cpp 和 .hpp 源代码,从而在编译阶段就消除冗余的库依赖。同时,框架采用了预分配内存区域的方式,彻底杜绝了运行时内存泄漏的风险。实际测试表明,其核心运行时加上基础算子的总代码量仅约2KB,这几乎只是一张普通图片大小的千分之一,为在单片机上部署 人工智能 应用提供了可能。
uTensor 工作原理
uTensor 的整体工作流程可以概括为下图所示:
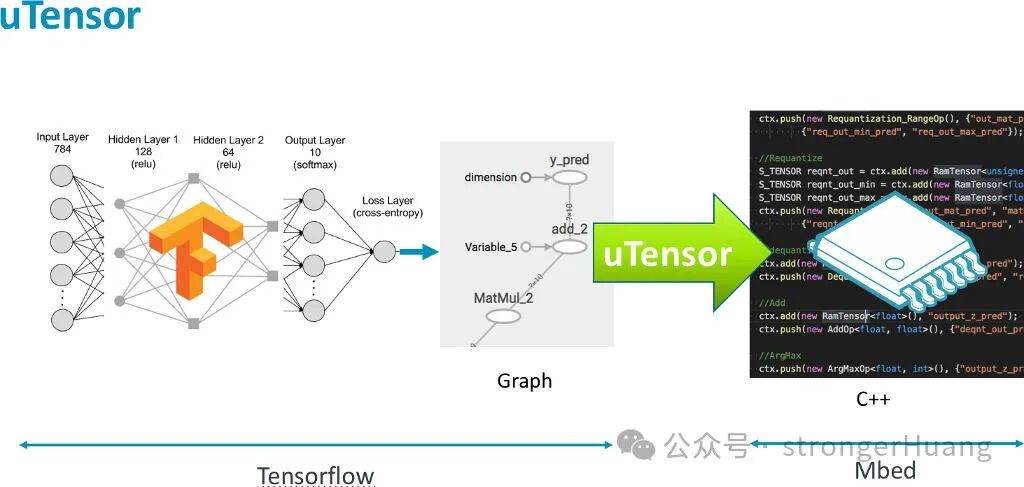
开发者首先在 TensorFlow 中完成模型的构建与训练。随后,uTensor 的转换工具会读取该模型,并生成对应的 .cpp 和 .hpp 源文件。这些文件包含了模型推理所需的全部 C++ 代码。最后,你只需将这些生成的源文件复制到你的嵌入式项目中进行编译,即可完成集成,过程相当简洁。
uTensor 的运行时主要由两个核心组件构成:
- uTensor Core:包含了满足 uTensor 运行时契约所需的基本数据结构、接口和类型定义。
- uTensor 库:一系列基于 uTensor Core 构建的默认实现(如默认的内存管理器、算子等)。
这种设计允许构建系统分别编译这两个部分,使得开发者能够轻松地扩展或覆盖基于 uTensor Core 的实现,例如定制自己的内存管理器、张量类型、运算符或错误处理程序。
错误处理示例:
SimpleErrorHandler errH(50); // 维护一个最多50个事件的历史记录
Context::get_default_context()->set_ErrorHandler(&errH);
...
// 一系列内存分配操作
...
// 检查分配器内部是否发生了重新平衡操作
bool has_rebalanced = std::find(errH.begin(), errH.end(), localCircularArenaAllocatorRebalancingEvent()) != errH.end();
Tensor 读写接口示例:
uint8_t myBuffer[4] = { 0xde, 0xad, 0xbe, 0xef };
Tensor mTensor = new BufferTensor({2,2}, u8, myBuffer); // 定义一个2x2的uint8_t张量
uint8_t a1 = mTensor(0,0); // 隐式转换此索引引用的内存为uint8_t
printf("0x%hhx\n", a1); // 输出 0xde
uint16_t a2 = mTensor(0,0); // 隐式转换此索引引用的内存为uint16_t
printf("0x%hx\n", a2); // 输出 0xdead
uint32_t a3 = mTensor(0,0); // 隐式转换此索引引用的内存为uint32_t
printf("0x%x\n", a3); // 输出 0xdeadbeef
// 你也可以使用显式类型转换进行读写,行为类似
mTensor(0,0) = static_cast<uint8_t>(0xFF);
printf("0xhhx\n", static_cast<uint8_t>(mTensor(0,0)));
出于性能考量,uTensor 的各种张量读写接口更接近于底层缓冲区操作,而非完全类型化的成熟 C++ 对象。不过其高级 API 设计得颇具 Python 风格,直观易用。实际的读写行为取决于用户如何解释和转换这个缓冲区。
uTensor 构建、运行和测试
官方为 uTensor 提供了多种构建、运行和测试的方式,方便开发者在不同环境中集成。
在本地进行构建和测试:
git clone git@github.com:uTensor/uTensor.git
cd uTensor/
git checkout proposal/rearch
git submodule init
git submodule update
mkdir build
cd build/
cmake -DPACKAGE_TESTS=ON -DCMAKE_BUILD_TYPE=Debug ..
make
make test
在 Arm Mbed OS 上构建和运行:
mbed new my_project
cd my_project
mbed import https://github.com/uTensor/uTensor.git
# 创建主文件
# 运行 uTensor-cli 工作流并将生成的模型目录复制到这里
mbed compile # 正常编译
在 Arm 系统(如Cortex-M)上构建和运行:
mkdir build && cd build
cmake -DCMAKE_BUILD_TYPE=Debug -DCMAKE_TOOLCHAIN_FILE=../extern/CMSIS_5/CMSIS/DSP/gcc.cmake ..
# 或者,使用CMSIS-DSP库进行内核优化
cmake -DARM_PROJECT=1 -DCMAKE_BUILD_TYPE=Debug -DCMAKE_TOOLCHAIN_FILE=../extern/CMSIS_5/CMSIS/DSP/gcc.cmake ..
以上方法为开发者提供了基础的集成思路和参考。实际应用中,具体的实现细节还需要结合项目需求和 uTensor 框架的特性进行进一步优化和调整。对于希望在资源极端受限的嵌入式设备上探索 AI 可能性的开发者来说,uTensor 无疑是一个值得深入研究的 开源实战 项目。更多关于嵌入式开发与前沿技术的讨论,欢迎在 云栈社区 交流分享。
 发表于 2026-1-17 04:34:34
|
查看: 198|
回复: 0
发表于 2026-1-17 04:34:34
|
查看: 198|
回复: 0
