导读
本文分享蚂蚁集团基于开源高性能计算库 Velox 构建流批一体向量化引擎 Flex 的技术实践,涵盖了其架构设计、核心功能开发、以及如何在保障正确性与提升易用性方面所做的探索,并展望了未来的工作方向。
01 向量化技术现状
1. 核心趋势:向量化技术发展现状
向量化技术的核心原理是利用 SIMD(单指令多数据流)指令集。简单来说,就是一条指令可以同时处理多条数据,相比于传统的单条指令处理单条数据,它能带来更高的计算并行度。
下图展示了不同计算模式的并行度对比。可以看到,无论是单线程还是多线程场景,使用向量化技术后,性能都能获得指数级的提升。
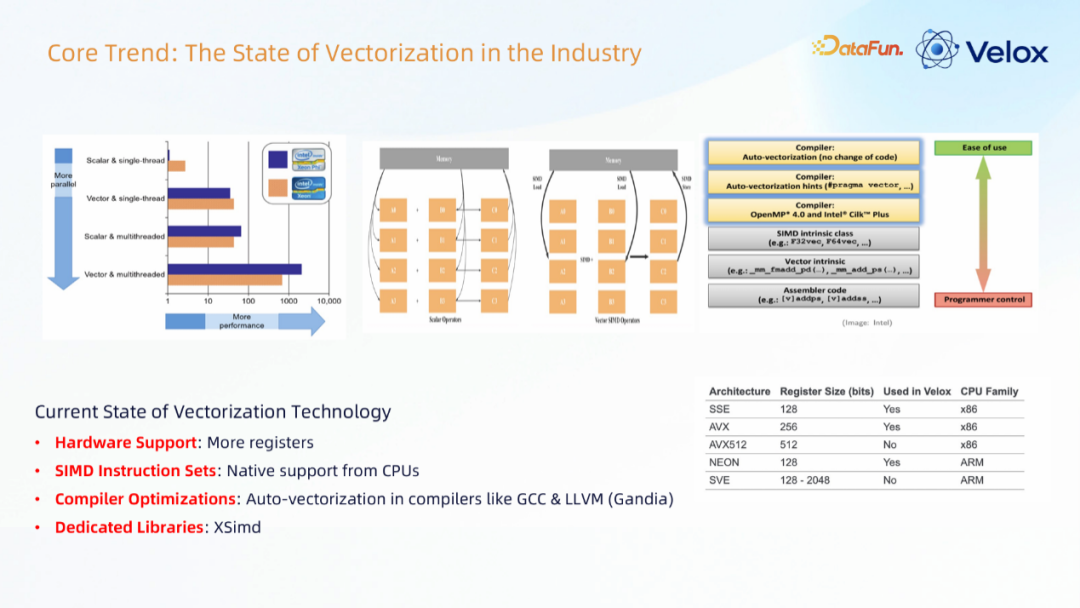
向量化技术发展现状
- 硬件支持:现代CPU提供了更多、更大的寄存器资源。
- SIMD指令集:CPU原生支持,如x86平台的SSE、AVX指令集,ARM平台的Neon指令集等。
- 编译器优化:GCC、LLVM等主流编译器已实现自动向量化功能,能自动识别并优化可向量化的代码。
- 专用库:如 xsimd 等跨平台的SIMD抽象库,方便开发者编写高性能可移植代码。
对于计算密集型应用,向量化技术能显著提升效率。如今,绝大多数处理器都支持SIMD,编译器层面的支持也日趋成熟,为向量化在大数据领域的应用铺平了道路。
2. 为何选择 Photon 引擎?
在大数据领域,向量化已经成为重要的性能优化方向。Databricks 的 Photon 引擎就是典型代表,它是一款完全基于 C++ 开发的闭源向量化引擎。根据公开信息,Photon 在 TPC-DS 1TB 基准测试中带来了额外2倍的性能提升,在实际业务负载中,客户观察到的平均性能提升可达3至8倍。
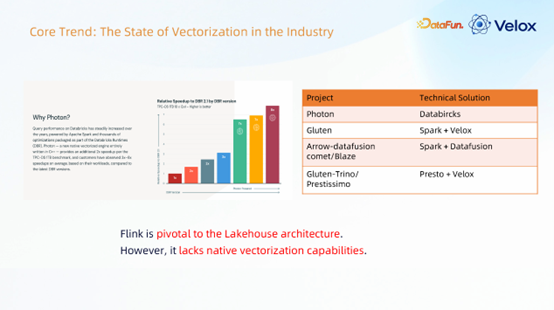
Photon的成功激发了业界的广泛关注,各大主流分布式计算引擎也纷纷向向量化方向发力。例如,英特尔开源的 Gluten 项目探索了 Spark + Velox 的方案;Comet/Blaze 项目尝试了 Spark + DataFusion(一个基于Rust的向量化库);还有基于 Presto + Velox 的实验方案。
然而,作为流批一体计算引擎的代表,Apache Flink 在原生向量化能力方面一直存在空白。这促使我们开始思考,能否为 Flink 也注入向量化的能力?
02 系统架构
1. Flex 框架:架构选型与设计理念
在项目启动时,我们的目标很明确:不重复造轮子。业界已有像 Velox 这样经过验证的高性能开源向量化库,因此我们决定借鉴 Gluten 的思路,基于 Velox 为 Flink 构建向量化能力,并与 Gluten 社区保持了紧密的合作交流。
但挑战也随之而来。Velox 是面向批处理设计的,其计算模型无法处理流式计算中常见的“回撤”操作,两者语义存在冲突。同时,直接套用 Gluten 的 Substrait 执行计划模型不仅工作量大,还无法支持 Flink 核心的“有状态算子”。
2. 引擎选型最终方案
经过验证,我们正式立项了 Flex 项目,其核心公式为:
Flex = Flink + Velox
“Flex”取自“flexible”,寓意其设计目标为灵活、可插拔。
选型依据
- 可扩展性:提供一套高可扩展的向量化算子与函数库。
- 性能表现:采用经行业验证的高性能 C++ 库(Velox)。
- 社区与生态:依托 Velox 和 Flink 活跃的社区与持续壮大的生态系统。
3. 集成策略
我们对比了多种集成策略,主要考虑两个问题:
- 是否采用 Gluten 的 Substrait 执行计划模型?
- 如何实现对有状态算子的支持?
下图展示了我们的方案对比。Plan Option1 类似 Gluten 方案,需要插入行转列/列转行的算子,且不支持状态算子,工作量巨大。
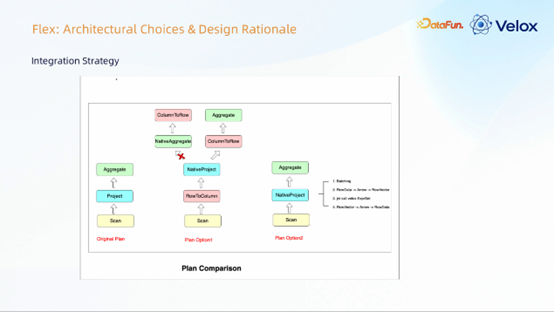
最终,我们选择了 Plan Option2。该方案将批处理、行列转换以及 Velox 的列式计算逻辑都封装到一个统一的算子内部,从而能够同时支持状态算子和非状态算子,大大简化了集成复杂度。
4. Flex:一款面向 Flink 的统一向量化引擎
Flex的整体架构分层清晰,主要包括以下模块:
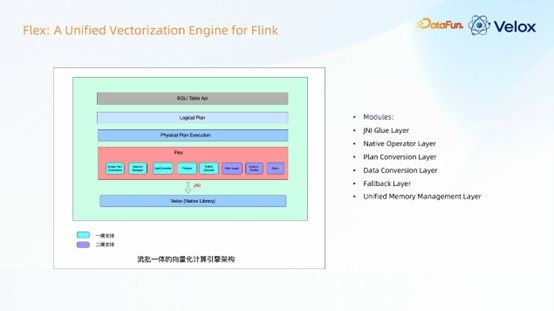
- JNI 适配层:负责 Java (Flink) 与 C++ (Velox) 之间的通信。
- 原生算子层:负责将 Flink 的执行计划转换为可由 Velox 执行的原生计划。
- 执行计划转换层:将 Flink 面向行的
RowData 转换为面向列的 ColumnRowData 数据结构。
- 数据转换层:处理行列数据格式之间的高效转换。
- 回退层:在算子或函数不支持原生执行时,自动回退到 Flink 原生的 Java 实现。
- 统一内存管理层:对 Native 侧的内存进行统一管理和生命周期控制。
03 Flex:核心功能开发与实现
我们围绕 Flex 在功能性、性能、正确性、易用性和稳定性方面开展了大量工作。
1. 性能优化与核心架构

- 执行计划层优化:提供丰富的优化规则集。例如,将包含 SIMD 函数表达式的 Calc 算子翻译成 NativeCalc,以提升表达式计算性能。
- 原生算子:支持 SLS、ODPS、Paimon 等原生连接器,使数据能以列式格式(如 Arrow)直接流转,避免额外的行列转换开销。
- 高效数据表示:采用基于 Arrow 的
ColumnRowData 数据结构,实现高性能的列式处理流水线。
- 丰富的 SIMD 函数库:对大量 Flink 内置函数使用 SIMD 指令集进行了重写,目前支持超过 15 个字符串函数以及大量数学函数。
2. Projection Reorder 投影重排
在实际应用中,我们发现一些SQL查询引用了大量字段,但实际参与计算的字段很少,数据转换开销成为瓶颈。

我们没有采用社区中让 UDF 也以 Native 方式运行的复杂方案,而是巧妙地将 Calc 算子拆分为两个。这样,含有 SIMD 函数的表达式部分被剥离出来,由 NativeCalc 高效执行,而包含 UDF 的部分则按原逻辑处理,完美绕过了性能瓶颈。
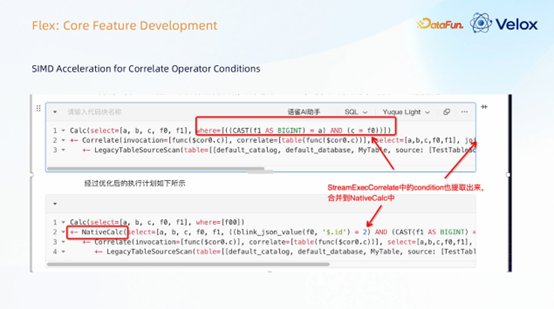
3. 针对关联算子条件的 SIMD 加速
我们同样对 Correlate(关联)算子进行了加速。在流计算中,Correlate 通常用于实现流表 JOIN,其条件判断部分若包含 SIMD 函数,则可以拆分出来进行加速。
4. 针对流-流连接条件的 SIMD 加速优化
这个思路可以扩展到双流 JOIN。如果 JOIN 的 ON 或 WHERE 条件中包含 SIMD 函数,同样可以将其拆分为独立的 NativeCalc 进行加速。

5. 支持原生 Paimon 源/汇/DIM 及规则资源注入
Paimon 数据湖是我们实现性能突破的关键场景。Paimon 内部使用 Parquet 存储格式,并提供了 Arrow 格式的数据接口。我们打通了 Flink RowData 到 Paimon Arrow 结构的直接转换链路,避免了中间格式转换,显著提升了性能。
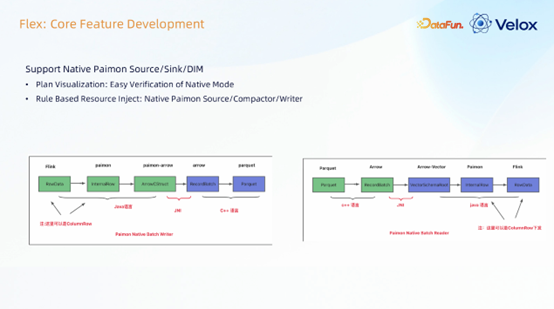
大规模上线会遇到各种稳定性问题。为了确保用户作业的稳定,我们基于规则为使用了 Native 算子的作业自动注入额外的资源。
执行计划可视化:为了方便用户和开发者直观地识别哪些算子在以 Native 模式运行,我们在算子名称前统一加上了“Native”前缀。

6. 细粒度可配置回退机制

由于 Velox 和 Flink 在某些函数的具体行为上可能存在语义差异,我们设计了一套精细的回退控制机制:
- 黑名单机制:支持基于函数签名的细粒度黑名单,精准控制哪些函数或类型不进行向量化。
- 智能卸载:仅当表达式完全由已支持的 SIMD 函数构成时,才将其转换为 NativeCalc。
- 自动回退:对 TIMESTAMP、DECIMAL 等复杂 SQL 类型,提供自动回退保障。
7. 可配置函数映射
- 支持 SQL 函数的自定义映射。例如,将 Flink 的某个函数名映射到 Velox 中语义相同的另一个函数,避免重复开发。
- 在 Flex 中提供原生实现,并配备优先级覆盖机制,使得问题修复和迭代更快捷(编译时间从数小时缩短到几分钟)。
04 Flex:正确性与数据完整性保障
正确性是金融级应用的底线。Flink(Java)和 Velox(C++)是两套独立的引擎,如何保证数以百计的函数语义完全一致?我们不能仅靠假设,必须建立自动化的验证体系。为此,我们开发了函数级和作业级两套验证系统。
1. 自动化函数级验证

- 无缝复用:直接复用 Flink 自身丰富的单元测试用例。
- 双栈执行:同时在 Flink 的旧栈(Legacy)、新栈(New)以及 Flex(Velox)上执行测试。
- 逐比特比对:自动比对三者的输出结果,任何细微差异都会被捕获。
关键发现与影响
- 发现了 Flink 原生 Java 函数中存在的 4 处 正确性问题。
- 发现了大量 Flink 与 Velox 在函数行为上的语义不一致问题。
这套工具不仅帮助我们校准了 Velox 的实现,甚至反过来帮助完善了 Flink 引擎自身。
2. 端到端自动化对比框架 Minos
函数级正确不代表组合起来就正确。因此,我们开发了作业级的自动化比对框架 Minos。

它能将用户的一个 SQL 作业,自动改写成两个并行作业(一个走原生Java路径,一个走Flex向量化路径),并将两者的计算结果写入存储。系统会定时对两个结果进行全量比对,生成详细的核对报告,确保万无一失后才敢大规模应用。
05 Flex 框架:提升易用性与开发者体验
为了让用户和开发者能顺畅地使用 Flex,我们做了大量“看不见”的工作。
1. 自动化兼容性分析器

- 静态分析作业的执行计划,在用户迁移前就能判断其作业是否能以原生模式运行,大幅缩短接入周期。
- 通过扫描线上真实作业,提前发现大量暂不支持的函数,为后续开发提供明确优先级。
2. 基于 JMH 的端到端性能验证框架
- 用于量化验证向量化带来的实际性能收益,并精准定位任何可能出现的性能回退。

从上图的性能测试数据可以看到,像 position、locate、instr 这类字符串查找函数,在使用 SIMD 优化后,性能提升了十倍以上。
3. 向量化监控面板
为所有向量化作业提供实时洞察与核心指标监控,让运行状态一目了然。
06 应用情况与运行成效
目前,Flex 已经在蚂蚁集团内部实现了大规模落地,并取得了显著的成效。

- 规模:已支持 6800+ 个线上作业。
- 集成:已在内部 Flink 1.18.1.2 版本中默认启用。
- 资源:累计节省超过 3万+ 个 CPU 核心。
- 性能:Paimon 表端到端 TPS 提升 50%;在曝光、点击、访问等蚂蚁最高流量的数据管道中,TPS 提升达到 59%。
- 场景:已广泛应用于广告投放、碰一碰、闪购、灵光平台、资金调度、大规模安全防护等核心业务场景。
07 未来工作方向与重点

- 支持全链路向量化:突破当前仅支持部分算子的限制,让数据在更多算子间以列式格式高效流转,避免不必要的行列转换开销。
- 高效低开销的数据转换:优化当前的 Arrow 中转链路,探索从 Flink
RowData 直接转换为 Velox RowVector 的更高效方式。
- 支持更多状态算子:探索对窗口聚合等有状态算子进行向量化加速的可能性。
- 支持更多架构:扩展对 ARM、GPU 等异构计算架构的支持。
- 支持完整 SQL 类型:完善对复杂 Row、Array、Map 等数据类型的原生支持。
- 扩展 SIMD 函数库:持续增加更多的数学函数和其他类型的 SIMD 函数实现。
如果你对数据库/中间件的底层性能优化技术感兴趣,欢迎来云栈社区交流探讨。
 发表于 2026-3-3 08:18:26
|
查看: 268|
回复: 0
发表于 2026-3-3 08:18:26
|
查看: 268|
回复: 0
