1. 项目概述
1.1 背景
TaskScheduler 是一个基于 C++20 实现的单机任务调度器,专注于管理和执行本地任务。它提供了完整的任务生命周期管理能力,涵盖任务提交、资源配额管理、进程执行、超时控制与状态跟踪。
1.1.1 单机调度器能用在哪些领域?
-
AI/机器学习训练与推理(最热门场景)
- 场景:一台服务器上有多个 GPU,需要同时运行多个训练或推理任务。
- 需求:
- 按 GPU 显存、计算单元分配任务
- 防止任务互相抢占资源(如一个任务占满显存导致其他 OOM)
- 支持优先级(高优模型优先调度)
- 例子:
- 字节的 ByteScheduler 在单机上调度多卡训练任务
- 华为 MindSpore 的本地执行引擎包含轻量调度模块
- 公司内部的模型 A/B 测试平台,需并发跑多个小模型
这类系统往往用 C++ 写调度器 + Python 做用户接口。
-
CI/CD 与自动化测试平台
- 场景:GitLab Runner、Jenkins Agent、内部构建系统。
- 需求:
- 并发执行多个构建/测试任务(如
make test、npm build)
- 限制每个任务的 CPU/内存,防止一个坏任务拖垮整台机器
- 任务队列管理、失败重试、超时控制
- 为什么不用 Docker?
- 启动开销大(冷启动 100ms+),而轻量调度器可做到 <10ms
- 某些安全环境禁止容器,只能用进程隔离
腾讯、阿里、美团都有自研的高性能 CI 执行引擎,底层就是单机调度器。
-
Serverless / FaaS(函数即服务)的本地运行时
- 场景:用户提交一个函数(如 Python lambda),平台在本地执行。
- 需求:
- 快速启动、资源隔离、超时 kill
- 高并发(单机每秒处理数百个短生命周期函数)
- 例子:
- 阿里云函数计算(FC)的 Worker 节点
- 华为云 FunctionGraph 的执行代理
- 技术栈:C++ 调度器 + gVisor/firecracker(可选) + 快照恢复
关键指标:冷启动延迟 < 50ms,这正是 C++ 单机调度器的优势。
-
边缘计算(Edge Computing)
- 场景:摄像头、IoT 网关、车载设备等资源受限设备。
- 需求:
- 低内存占用(<50MB)
- 无依赖(不能跑 K8s)
- 支持定时任务、事件触发任务
- 例子:
- 自动驾驶车上的感知模块调度
- 工厂 PLC 设备上的数据预处理任务
华为、百度 Apollo、大疆等公司在边缘端大量使用 C++ 调度框架。
-
游戏服务器(Game Server)
- 场景:一个物理机部署多个游戏房间(Room)实例。
- 需求:
- 每个房间独立进程,防止单点崩溃影响全局
- 动态扩缩容(玩家多就多开房间)
- 低延迟通信(调度器需快速响应负载变化)
腾讯天美、米哈游、网易雷火都有类似架构。
1.1.2 互联网大厂真的需要调度器吗?
答案是:非常需要! 但通常作为“基础设施组件”而非独立产品。
| 公司 |
应用场景 |
是否招人 |
| 华为 |
AI训练调度、昇腾芯片任务分发 |
✅ 大量 C++ 基础软件岗 |
| 阿里 |
函数计算 Worker、ODPS 本地执行器 |
✅ 云智能事业群常招 |
| 腾讯 |
游戏服务器调度、TEG 自动化测试平台 |
✅ TEG 后台开发(C++) |
| 字节 |
推荐模型训练、A/B 实验平台 |
✅ Infra 部门偏好系统人才 |
| 美团/快手 |
CI/CD 执行引擎、离线批处理 |
✅ 基础架构部有相关需求 |
招聘关键词搜索建议:
1.2 核心目标
- 任务调度:支持任务提交、排队、调度和执行的完整闭环
- 资源管理:基于 CPU 核数和内存上限进行准入控制
- 进程隔离:通过 fork/exec 执行任务,可选 cgroup v2 资源限制
- 可观测性:提供指标采集、HTTP 导出和 Prometheus 兼容格式
- 高可靠性:支持持久化恢复、超时终止、信号管理和 PSI 背压
1.3 技术特点
- 多线程模型:独立的调度、回收、PSI 监测和 Cron 触发线程
- 资源感知:预留/释放机制避免资源超卖
- 灵活配置:支持优先级调度、命令白/黑名单、工作目录限制
- 轻量级实现:核心代码约 600 行,依赖 SQLite 和 Linux 系统调用
2. 需求分析
2.1 功能性需求
2.1.1 任务提交与管理
- 支持通过
JobSpec 提交任务,包含命令、资源需求、超时和优先级
struct JobSpec {
std::string cmd; // 要执行的命令字符串
int cpu_cores{1}; // 需要的 CPU 核数
size_t memory_mb{256}; // 需要的内存 MB
int timeout_sec{0}; // 超时秒数,0 表示不限制
int priority{0}; // 优先级,数值越大优先级越高
};
- 队列长度限制:
max_queue_size 配置,超出则拒绝提交
- 命令准入:支持白名单/黑名单校验
2.1.2 资源配额管理
struct ResourceQuota {
int total_cpu{4}; // 可用 CPU 总核数
size_t total_mem_mb{2048}; // 可用内存总量 MB
};
- CPU 和内存的预留/释放机制
- 启动前检查资源是否足够,不足则等待
- 任务结束后自动释放资源
2.1.3 任务生命周期
enum class JobStatus{
Pending, // 已提交但尚未调度
Running, // 正在运行
Succeeded, // 成功结束(exit 0)
Failed, // 失败结束(非零退出码)
Timeout, // 超时被终止
Cancelled // 被取消
};
- 完整状态转换:Pending → Running → Succeeded/Failed/Timeout
- 超时管理:两阶段终止(SIGTERM → 宽限期 → SIGKILL)
- 进程组管理:整组清理避免子进程泄漏
2.1.4 可观测性
- 指标采集:提交数、拒绝数、运行数、成功/失败/超时数、排队延迟
- HTTP 导出:Prometheus 兼容的
/metrics 端点
- 健康检查:
/health 端点返回 ok
2.2 非功能性需求
- 线程安全:所有共享状态通过互斥锁保护
- 资源可控:任务结束后正确释放资源,避免泄漏
- 优雅退出:
stop() 能够等待任务完成或按策略终止
- 日志完善:关键操作有日志记录,便于排障
2.3 可选特性
- cgroup v2 隔离:CPU 配额和内存限制
- PSI 背压监测:根据系统压力暂停新任务启动
- SQLite 持久化:支持重启后恢复未完成任务
- Cron 调度:支持定时触发任务(简化版 cron 表达式)
3. 架构设计
3.1 总体架构
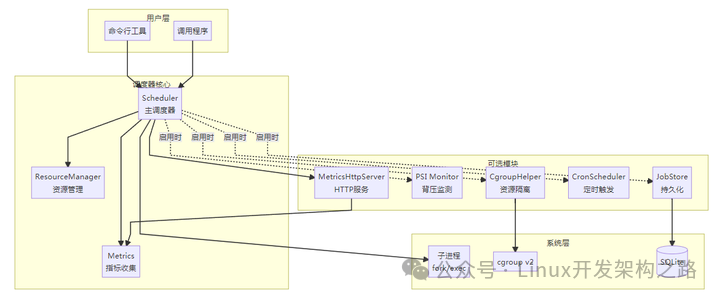
3.2 线程模型
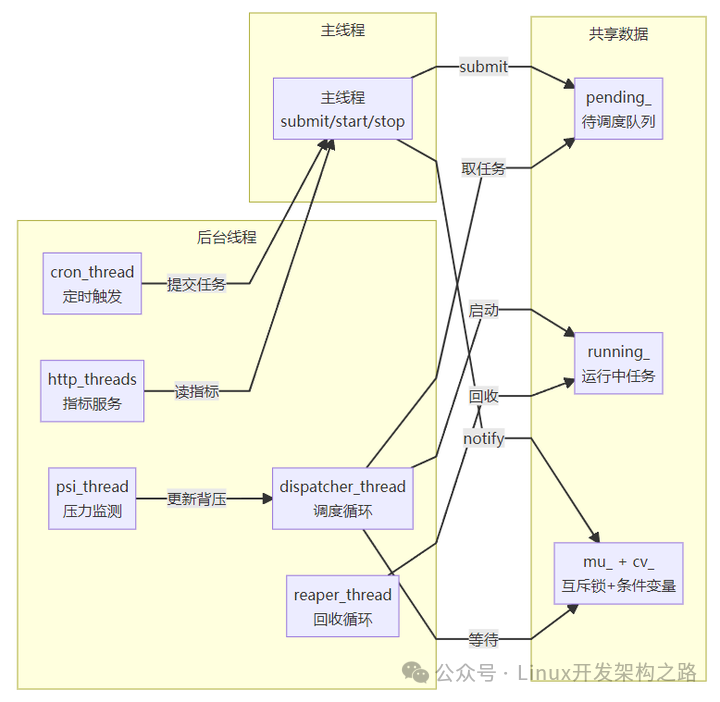
线程职责:
- 主线程:处理外部
submit() 调用,加锁操作 pending_ 队列
- dispatcher 线程:从
pending_ 取任务,检查资源,fork/exec 启动进程
- reaper 线程:周期性 waitpid 回收子进程,处理超时,释放资源
- psi 线程(可选):读取 cgroup pressure 文件,更新背压标志
- cron 线程(可选):检查模板到期时间,生成任务实例
- http 线程(可选):处理 HTTP 请求,返回指标或健康状态
3.3 数据流
提交路径:
submit() → 校验白/黑名单 → 检查队列上限 → pending_.push_back()
→ inc_submitted() → cv_.notify_all()
调度路径:
dispatcher_loop() → pick_next_job() → rm_.reserve()
→ launch_job() → fork/exec → running_[id] = job
回收路径:
reaper_loop() → waitpid(WNOHANG) → 更新 exit_code/status
→ rm_.release() → cleanup_cgroup() → running_.erase(id)
4. 核心模块设计
4.1 Scheduler(调度器)
职责:编排整个调度流程,管理任务生命周期
关键接口:
class Scheduler {
public:
explicit Scheduler(SchedulerOptions opts);
// 提交任务,返回 job id 或 -1
int submit(const JobSpec& spec);
// 启动后台线程
void start();
// 停止调度器并等待线程退出
void stop();
// 判断是否空闲(无待处理和运行中任务)
bool idle() const;
// 获取指标快照
Metrics::Snapshot metrics() const;
private:
void dispatcher_loop(); // 调度循环
void reaper_loop(); // 回收循环
void psi_loop(); // PSI 监测循环
void cron_loop(); // Cron 触发循环
bool launch_job(Job& job); // 启动任务进程
bool pick_next_job(Job& out); // 出队任务
void restore_from_store(); // 持久化恢复
};
关键数据结构:
private:
SchedulerOptions opts_; // 配置
ResourceManager rm_; // 资源管理器
std::vector<Job> pending_; // 待调度队列
std::unordered_map<int, Job> running_; // 运行中任务表
mutable std::mutex mu_; // 互斥锁
std::condition_variable cv_; // 条件变量
std::atomic<bool> shutting_down_{false}; // 关闭标志
std::atomic<bool> psi_backpressure_{false};// 背压标志
Metrics metrics_; // 指标收集器
std::unique_ptr<JobStore> store_; // 持久化存储
std::unique_ptr<CronScheduler> cron_sched_; // Cron 调度器
std::unique_ptr<MetricsHttpServer> metrics_server_; // HTTP 服务
4.2 ResourceManager(资源管理器)
职责:管理 CPU 和内存配额,提供预留/释放接口
实现要点:
class ResourceManager {
public:
explicit ResourceManager(ResourceQuota quota);
// 尝试预留资源,成功返回 true
bool reserve(int cpu, size_t mem_mb);
// 释放资源(必须与 reserve 配对调用)
void release(int cpu, size_t mem_mb);
// 查询当前使用情况
std::pair<int, size_t> used() const;
private:
ResourceQuota quota_;
int used_cpu_{0};
size_t used_mem_mb_{0};
mutable std::mutex mu_;
};
核心逻辑(src/resource_manager.cpp):
bool ResourceManager::reserve(int cpu, size_t mem_mb){
std::lock_guard lk(mu_);
// 不做部分分配:要么全部满足要么拒绝
if (used_cpu_ + cpu > quota_.total_cpu ||
used_mem_mb_ + mem_mb > quota_.total_mem_mb) {
return false;
}
used_cpu_ += cpu;
used_mem_mb_ += mem_mb;
return true;
}
4.3 Metrics(指标收集器)
职责:提供原子计数器,生成快照和 Prometheus 文本
指标项:
| 指标名 |
类型 |
说明 |
| submitted_ |
counter |
累计提交任务数 |
| rejected_ |
counter |
因队列满/策略拒绝的次数 |
| running_ |
gauge |
当前运行中任务数 |
| succeeded_ |
counter |
成功完成任务数 |
| failed_ |
counter |
失败任务数 |
| timeout_ |
counter |
超时被终止任务数 |
| launchfailed |
counter |
启动失败次数 |
| pressureblocked |
counter |
因背压暂停的累计次数 |
| pressureactive |
gauge |
背压是否激活(1/0) |
| queue_wait_mstotal |
counter |
队列等待时长总和(毫秒) |
| queue_waitcount |
counter |
统计样本数 |
| queue_wait_msmax |
gauge |
最大等待时长(毫秒) |
Prometheus 导出示例:
# TYPE tasks_total counter
tasks_total{status="submitted"} 100
tasks_total{status="rejected"} 5
tasks_total{status="succeeded"} 80
tasks_total{status="failed"} 10
tasks_total{status="timeout"} 5
# TYPE tasks_running_current gauge
tasks_running_current 3
# TYPE tasks_pending_current gauge
tasks_pending_current 5
4.4 CgroupHelper(cgroup 辅助)
职责:创建、绑定和清理任务专属 cgroup
接口:
// 创建任务 cgroup 并设置 CPU/内存限制
std::string create_cgroup_for_job(int job_id, int cpu_cores,
size_t mem_mb, const CgroupConfig& cfg);
// 将 pid 加入 cgroup
bool attach_pid_to_cgroup(pid_t pid, const std::string& cg_path);
// 清理 cgroup 目录
void cleanup_cgroup(const std::string& cg_path);
实现细节(src/cgroup_helper.cpp):
- 在
cfg.base_path 下创建 job_<id> 子目录
- 写入
cpu.max:<quota_us> <period_us>,例如 100000 100000 表示 1 核
- 写入
memory.max:字节数,例如 268435456 表示 256MB
- 写入
cgroup.procs:将 pid 加入该 cgroup
4.5 JobStore(持久化存储)
职责:通过 SQLite 持久化任务状态,支持重启恢复
数据模型:
CREATE TABLE jobs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
cmd TEXT NOT NULL,
cpu_cores INTEGER,
memory_mb INTEGER,
timeout_sec INTEGER,
priority INTEGER,
status TEXT, -- queued/running/succeeded/failed/timeout/launch_failed
submit_ms INTEGER,
start_ms INTEGER,
end_ms INTEGER,
exit_code INTEGER
);
关键接口:
class JobStore {
public:
bool init(const std::string& path);
// 插入任务
int insert_job(const JobSpec& spec, PersistStatus status,
int64_t submit_ms, ...);
// 更新状态
void update_status(int id, PersistStatus status, ...);
// 加载未完成任务
std::vector<PersistedJob> load_unfinished();
};
恢复策略(Scheduler::restore_from_store()):
void Scheduler::restore_from_store() {
if (!store_) return;
auto jobs = store_->load_unfinished();
for (auto& pj : jobs) {
Job job;
job.id = next_id_++;
job.spec = pj.spec;
job.status = JobStatus::Pending;
job.enqueue_time = std::chrono::steady_clock::now();
pending_.push_back(job);
}
cv_.notify_all();
}
4.6 CronScheduler(定时触发)
职责:管理 cron 模板,定时生成任务实例
当前实现:
- 支持简化表达式:
@every <sec>s,例如 @every 60s 每 60 秒触发一次
- 完整 5 字段 cron(分 时 日 月 周)接口已定义但简化实现
核心逻辑:
void CronScheduler::tick(SubmitCallback submit_cb){
auto now = std::chrono::system_clock::now();
for (auto tpl : templates_) {
if (!tpl.enabled) continue;
if (now >= tpl.next_run) {
submit_cb(tpl.spec); // 提交任务实例
tpl.next_run = tpl.cron.next_run(now); // 计算下次触发时间
}
}
}
4.7 MetricsHttpServer(HTTP 指标服务)
职责:提供轻量级 HTTP 服务,导出指标和健康检查
路由:
GET /metrics:返回 Prometheus 文本格式指标GET /health:返回 ok
并发模型:
- 监听线程:
accept() 接收连接
- 工作线程池:处理请求,生成响应
- 连接队列:有限长度,避免内存膨胀
实现细节(src/metrics_http_server.cpp):
class MetricsHttpServer {
public:
using MetricsHandler = std::function<std::string()>;
bool start(int port, MetricsHandler handler);
void stop();
private:
void accept_loop();
void worker_loop();
// ...
};
5. 关键流程设计
5.1 任务提交流程
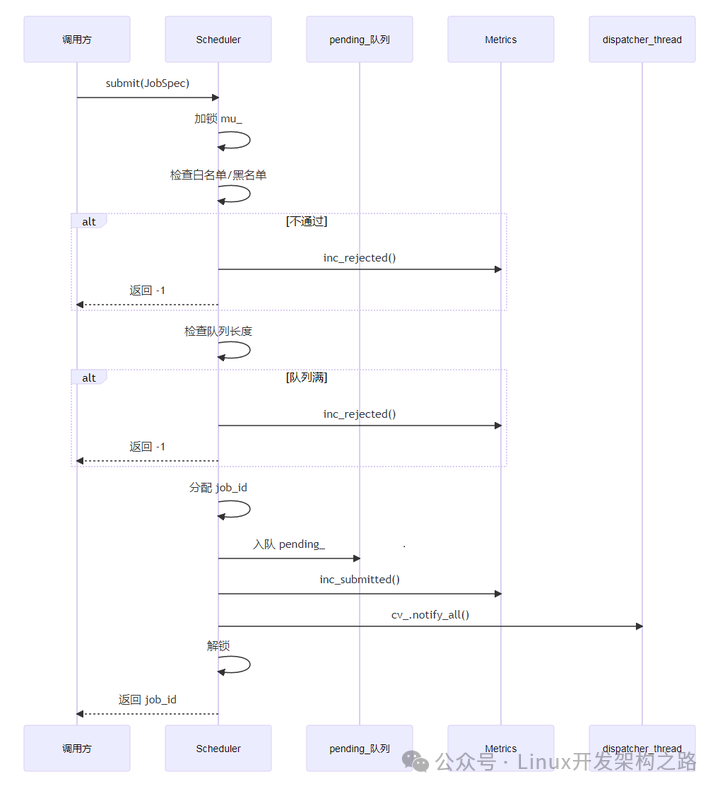
5.2 调度启动流程
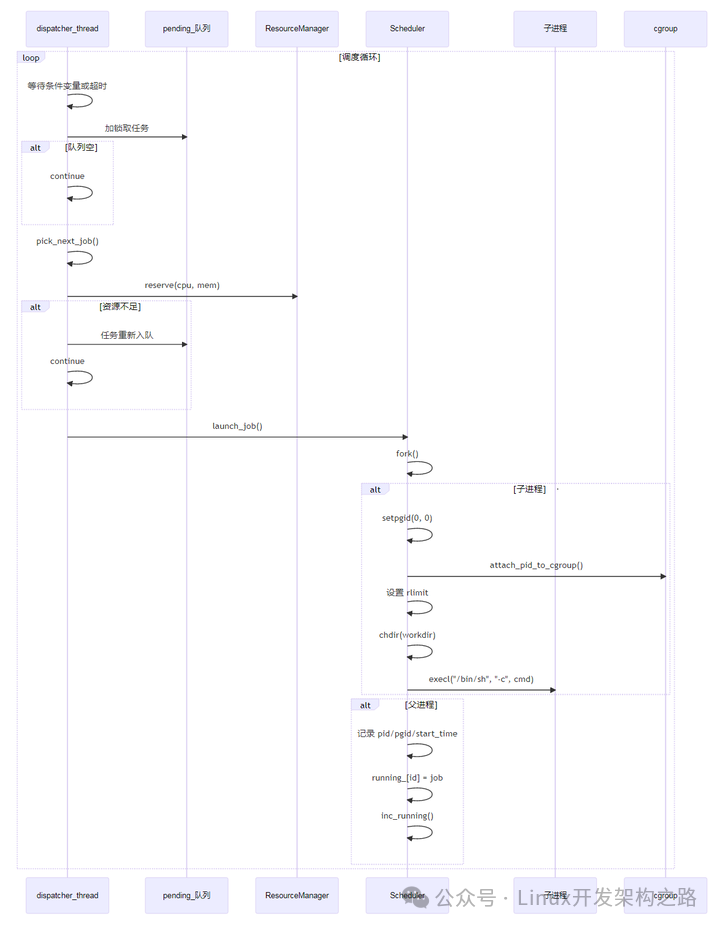
关键代码(Scheduler::launch_job()):
bool Scheduler::launch_job(Job& job) {
// 创建 cgroup
std::string cg_path;
if (opts_.cgroup.enabled) {
cg_path = create_cgroup_for_job(job.id, job.spec.cpu_cores,
job.spec.memory_mb, opts_.cgroup);
}
pid_t pid = fork();
if (pid == 0) {
// 子进程
setpgid(0, 0); // 建立独立进程组
if (!cg_path.empty()) {
attach_pid_to_cgroup(getpid(), cg_path);
}
// 设置 rlimit
if (opts_.rlimit_nofile >= 0) {
struct rlimit rl;
rl.rlim_cur = rl.rlim_max = opts_.rlimit_nofile;
setrlimit(RLIMIT_NOFILE, &rl);
}
if (opts_.disable_core_dump) {
struct rlimit rl;
rl.rlim_cur = rl.rlim_max = 0;
setrlimit(RLIMIT_CORE, &rl);
}
// 切换工作目录
if (!opts_.workdir.empty()) {
chdir(opts_.workdir.c_str());
}
// 执行命令
execl("/bin/sh", "sh", "-c", job.spec.cmd.c_str(), nullptr);
_exit(127);
}
// 父进程
job.pid = pid;
job.pgid = pid;
job.start_time = std::chrono::steady_clock::now();
job.status = JobStatus::Running;
return true;
}
5.3 回收超时流程
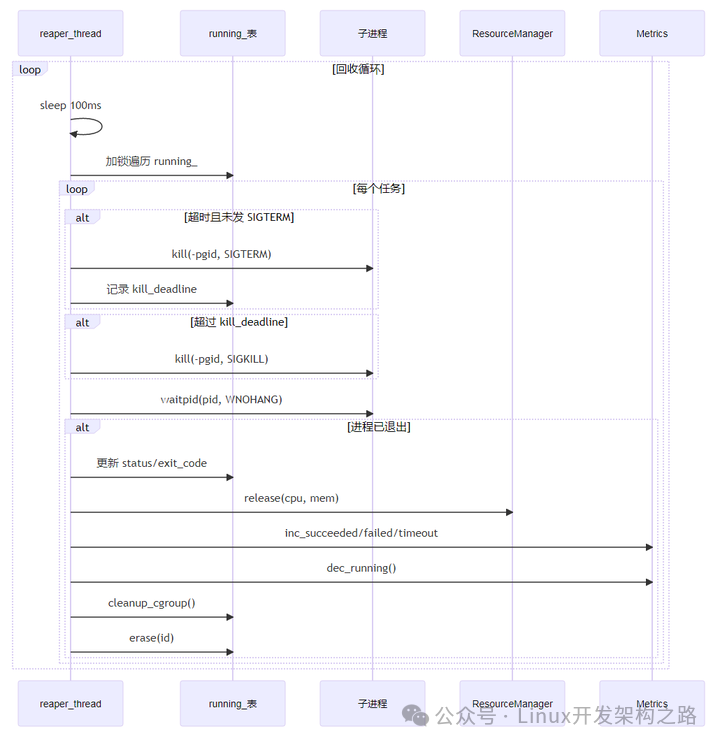
关键代码(Scheduler::reaper_loop()):
void Scheduler::reaper_loop() {
while (!shutting_down_.load()) {
std::this_thread::sleep_for(std::chrono::milliseconds(100));
std::lock_guard lk(mu_);
auto now = std::chrono::steady_clock::now();
for (auto it = running_.begin(); it != running_.end(); ) {
Job& job = it->second;
// 检查超时
if (job.spec.timeout_sec > 0) {
auto elapsed = std::chrono::duration_cast<std::chrono::seconds>(
now - job.start_time).count();
if (elapsed >= job.spec.timeout_sec) {
if (!job.sigterm_sent) {
// 发送 SIGTERM
kill(-job.pgid, SIGTERM);
job.sigterm_sent = true;
job.kill_deadline = now +
std::chrono::seconds(opts_.kill_grace_sec);
} else if (now >= *job.kill_deadline) {
// 发送 SIGKILL
kill(-job.pgid, SIGKILL);
}
}
}
// 尝试回收
int status;
pid_t ret = waitpid(job.pid, &status, WNOHANG);
if (ret > 0) {
// 进程已退出
job.exit_code = status;
job.end_time = now;
if (job.sigterm_sent) {
job.status = JobStatus::Timeout;
metrics_.inc_timeout();
} else if (WIFEXITED(status) && WEXITSTATUS(status) == 0) {
job.status = JobStatus::Succeeded;
metrics_.inc_succeeded();
} else {
job.status = JobStatus::Failed;
metrics_.inc_failed();
}
// 释放资源
rm_.release(job.spec.cpu_cores, job.spec.memory_mb);
metrics_.dec_running();
// 清理 cgroup
if (opts_.cgroup.enabled) {
std::string cg_path = opts_.cgroup.base_path +
"/job_" + std::to_string(job.id);
cleanup_cgroup(cg_path);
}
it = running_.erase(it);
} else {
++it;
}
}
}
}
5.4 PSI 背压流程
目标:根据系统压力暂停新任务启动,避免雪崩
实现原理:
psi_thread 周期性读取 /sys/fs/cgroup/scheduler/memory.pressure 和 cpu.pressure- 解析
avg10 值(10 秒平均压力)
- 与阈值比较(如 50.0),超过则设置
psi_backpressure_ = true
dispatcher_loop 检查背压标志,若为 true 则跳过本轮调度
关键代码:
void Scheduler::psi_loop(){
const double threshold = 50.0; // 背压阈值
while (!shutting_down_.load()) {
std::this_thread::sleep_for(std::chrono::seconds(1));
// 读取 memory.pressure
std::string mem_pressure_file = opts_.cgroup.base_path + "/memory.pressure";
std::ifstream ifs(mem_pressure_file);
// 格式:some avg10=12.34 avg60=... total=...
double avg10 = parse_psi_avg10(ifs);
bool pressure = (avg10 > threshold);
if (pressure != psi_backpressure_.load()) {
psi_backpressure_.store(pressure);
metrics_.set_pressure_active(pressure);
Logger::instance().log(Logger::Level::Info,
pressure ? "PSI backpressure activated" : "PSI backpressure cleared");
}
}
}
6. 配置与接口
6.1 配置选项
struct SchedulerOptions {
ResourceQuota quota; // 资源配额
CgroupConfig cgroup; // cgroup 配置
int max_queue_size{1000}; // 最大队列长度
int kill_grace_sec{2}; // SIGTERM 宽限期
bool enable_priority{false}; // 是否启用优先级调度
bool enable_psi_monitor{false}; // 是否启用 PSI 背压监测
std::vector<std::string> cmd_whitelist; // 命令白名单
std::vector<std::string> cmd_blacklist; // 命令黑名单
std::string workdir; // 工作目录
int metrics_http_port{-1}; // HTTP 指标端口
int rlimit_nofile{-1}; // 文件句柄限制
bool disable_core_dump{true}; // 禁用 core dump
bool enable_persistence{false}; // 启用持久化
std::string db_path{"state/tasks.db"}; // 持久化路径
bool enable_cron{false}; // 启用 cron
int cron_tick_ms{1000}; // cron 检查间隔
};
6.2 命令行接口
./scheduler \
--cmd "echo hello" \ # 任务命令
--cpu 1 \ # CPU 核数
--mem 256 \ # 内存 MB
--timeout 5 \ # 超时秒数
--priority 10 \ # 优先级
--total-cpu 4 \ # 总 CPU
--total-mem 2048 \ # 总内存
--cgroup \ # 启用 cgroup
--enable-priority \ # 启用优先级
--metrics-port 8080 \ # HTTP 端口
--whitelist ls,echo \ # 白名单
--blacklist rm,shutdown \ # 黑名单
--workdir /tmp # 工作目录
6.3 HTTP 接口
健康检查:
$ curl http://localhost:8080/health
ok
指标导出:
$ curl http://localhost:8080/metrics
# TYPE tasks_total counter
tasks_total{status="submitted"} 100
tasks_total{status="rejected"} 5
tasks_total{status="succeeded"} 80
...
如果你对这类系统级开发与架构设计感兴趣,或者想深入讨论操作系统的底层原理如 fork/exec,欢迎到 云栈社区 与更多开发者交流。
 发表于 2026-1-17 05:36:16
|
查看: 142|
回复: 0
发表于 2026-1-17 05:36:16
|
查看: 142|
回复: 0
