如果把计算机比作一座24小时不停工的智能工厂,CPU(中央处理器)就是工厂里至关重要的生产车间。这个车间里有多条“生产线”(核心)协同作业,无论是打开文档、播放视频还是运行程序,所有任务都需要在这里被处理,才能将需求转化为你能在屏幕上看到的结果。
当然,生产车间的高效运转离不开一位经验丰富的调度员——CPU调度器(CPU Scheduler)。正是它负责在所有任务间动态分配宝贵的生产线资源。倘若没有它的合理安排,系统很快就会陷入订单堆积、生产线空转,甚至完全瘫痪的混乱局面。因此,深入理解CPU调度与优化,是保障系统稳定性的关键。在云栈社区,你可以找到更多关于系统底层原理的深度讨论。本文将一步步拆解CPU算力“告急”的全过程,并提供从定位到解决的实战指南。
第一站:算力告急——CPU“忙到宕机”全过程
在一个普通的上午,当你同时打开浏览器、IDE、视频会议软件和后台下载工具时,电脑可能很快变得卡顿——鼠标指针变成转圈的“风火轮”,键盘输入延迟,音乐开始断断续续。这通常不是硬件故障,而是CPU这个“生产车间”的使用率飙升到100%的“超负荷预警”。
本质上,这是一场“算力资源争夺战”。每个运行中的程序都是一个亟待处理的“订单”,而CPU调度器就是工厂里的调度员。当所有订单一股脑涌来,井然有序的生产流程瞬间被打乱。像键盘输入这样的“加急订单”,和后台下载工具校验这类“常规订单”挤在一起争抢CPU资源,最终导致“工厂生产瘫痪”。
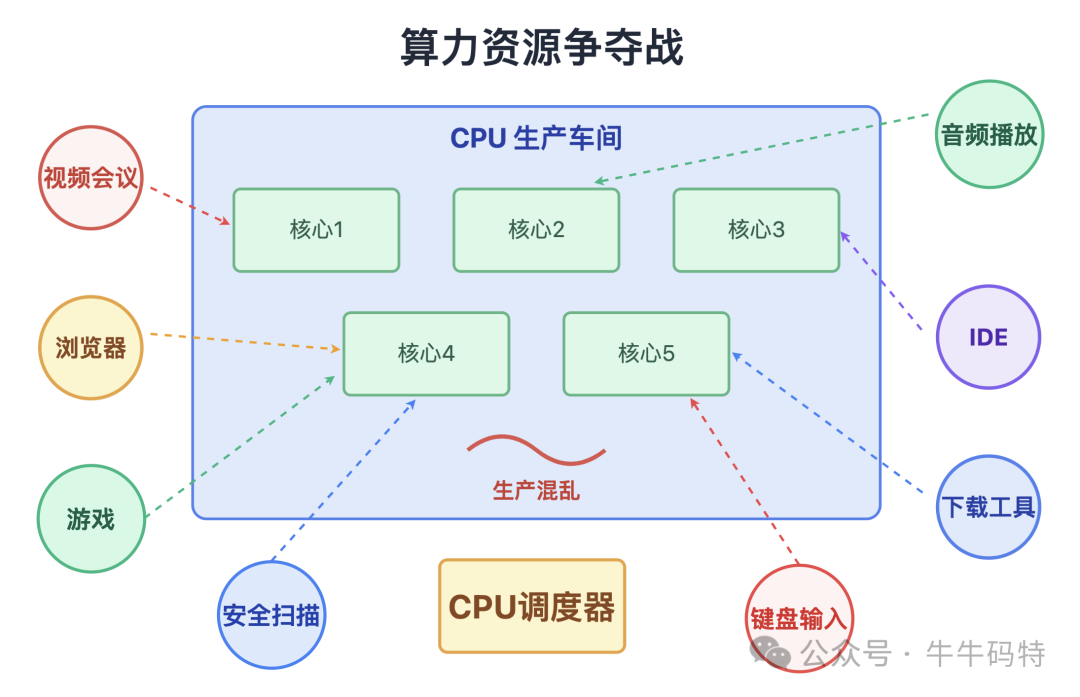
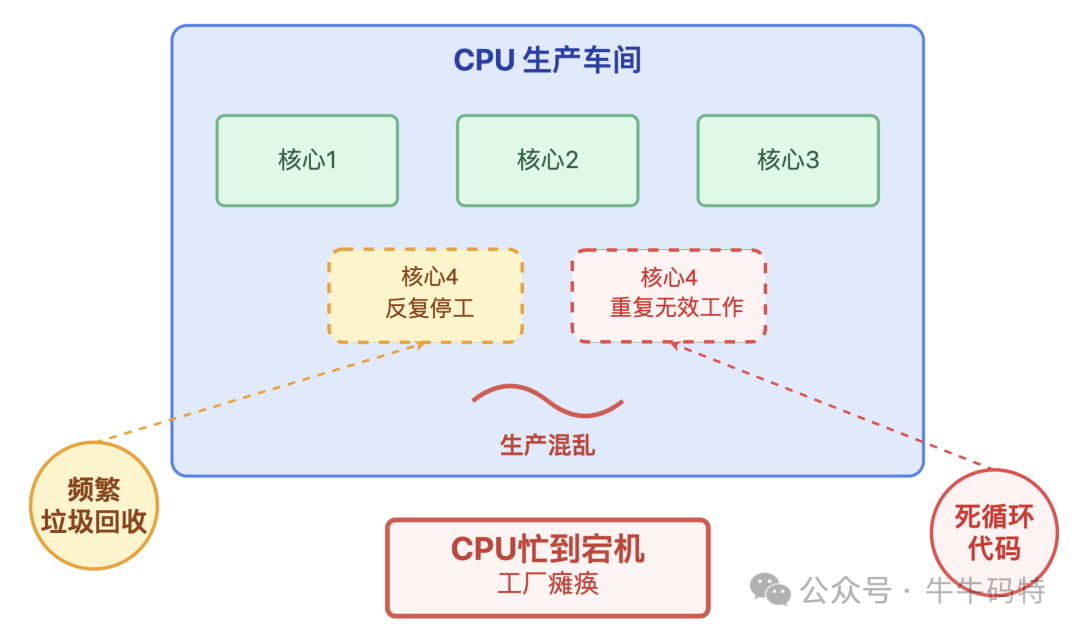
更隐蔽的是,有些程序还会进行“违规操作”,长期霸占生产线不放:
- 陷入死循环的代码导致某条生产线被强制锁定,一直机械地重复无效工作,却不释放算力资源。
- 频繁的垃圾回收(GC)则造成生产线在运行中反复停工去“整理物料”,既影响效率又浪费资源。
这些行为让本就紧张的算力资源雪上加霜,最终可能导致CPU这个生产车间彻底“忙到宕机”。
看到CPU满载,你或许会问:调度器难道不管管这些混乱吗?实际上,它一直在背后默默工作。
第二站:调度员登场——CPU调度器的核心使命
调度器的核心工作,就是解决“生产线(核心)永远不够用”的难题。它围绕着三个核心目标展开:
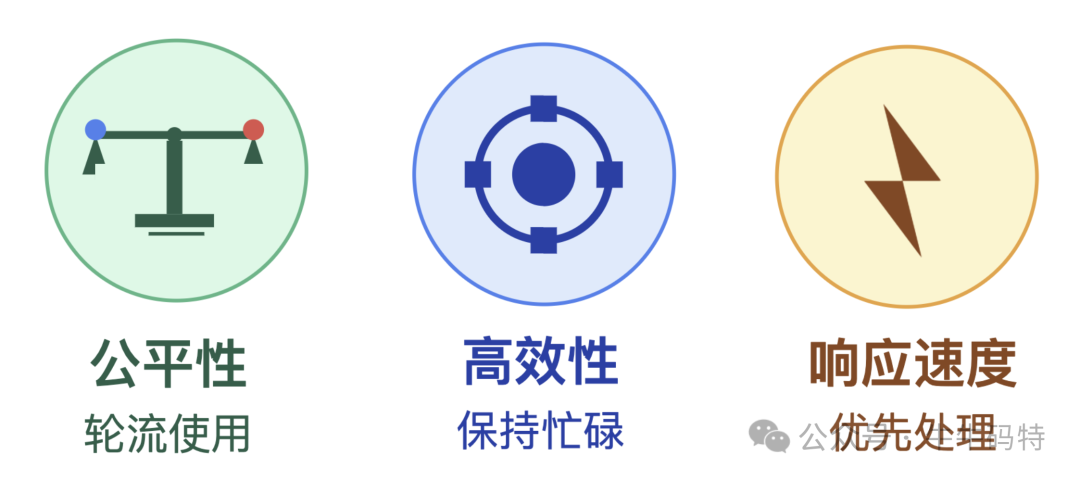
- 公平性:确保每个任务都有机会使用CPU资源。例如,后台下载任务不能一直抢占前台交互操作所需的算力,各类任务需按规则轮流使用“生产线”。
- 高效性:调度器绝不会让生产线空转,它会时刻监控CPU的空闲状态,一旦有任务等待,就立刻安排资源,力求让每条“生产线”都保持忙碌。
- 响应速度:对于用户点击、键盘输入这类“加急订单”,调度器会优先安排。而像文档自动保存这类可以“错峰处理”的任务,则会被安排在你停笔的间隙利用碎片时间完成。
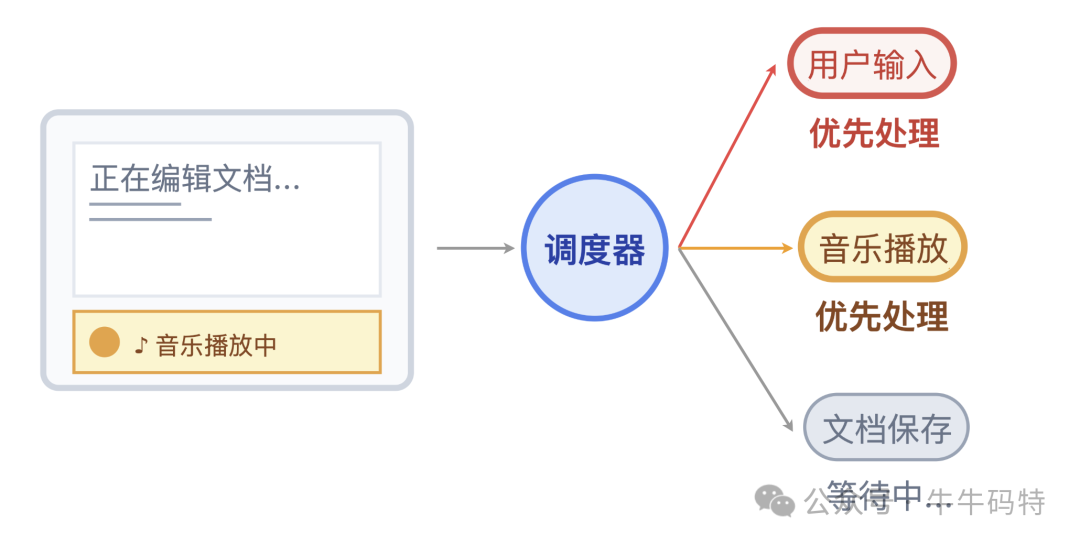
这种在各类任务间动态调配资源的“平衡术”,正是CPU调度器的精髓。但既然有调度器,CPU为何仍会陷入混乱?这就好比交通系统,即便有红绿灯和交警,早晚高峰依然可能拥堵。
第三站:调度员的“失灵时刻”——CPU 100%满负荷的真相
调度器“失灵”的关键在于,那些理想化的调度规则,常被任务的“违规操作”和“突发状况”打乱节奏。具体可归结为四类典型问题:
问题1:任务“耍赖不放手”——死循环和无限资源申请
调度器本应按照“时间片轮转”规则(每个任务轮流使用CPU一段固定时间后让出资源)运作。但有些任务就像霸占生产线不换班的工人。例如下面这段遗漏了退出条件的代码:
//错误示例:缺少退出条件的死循环
while (true) {
//执行一些重复操作,但永远没有结束的判断
System.out.println("正在处理任务...");
//此处忘记添加 break 或退出循环的条件判断
}

生产线被这类代码死死占着,其他任务只能在队列里干等,越积越多,时间片轮转规则完全失效。
问题2:任务“互不相让”——锁竞争和资源死锁
调度器能分配CPU资源,却管不了任务间私下的“资源争夺”。例如两个任务陷入循环等待:
- 任务A持有数据库连接锁,需要等待任务B释放文件锁。
- 任务B持有文件锁,需要等待任务A释放数据库连接锁。
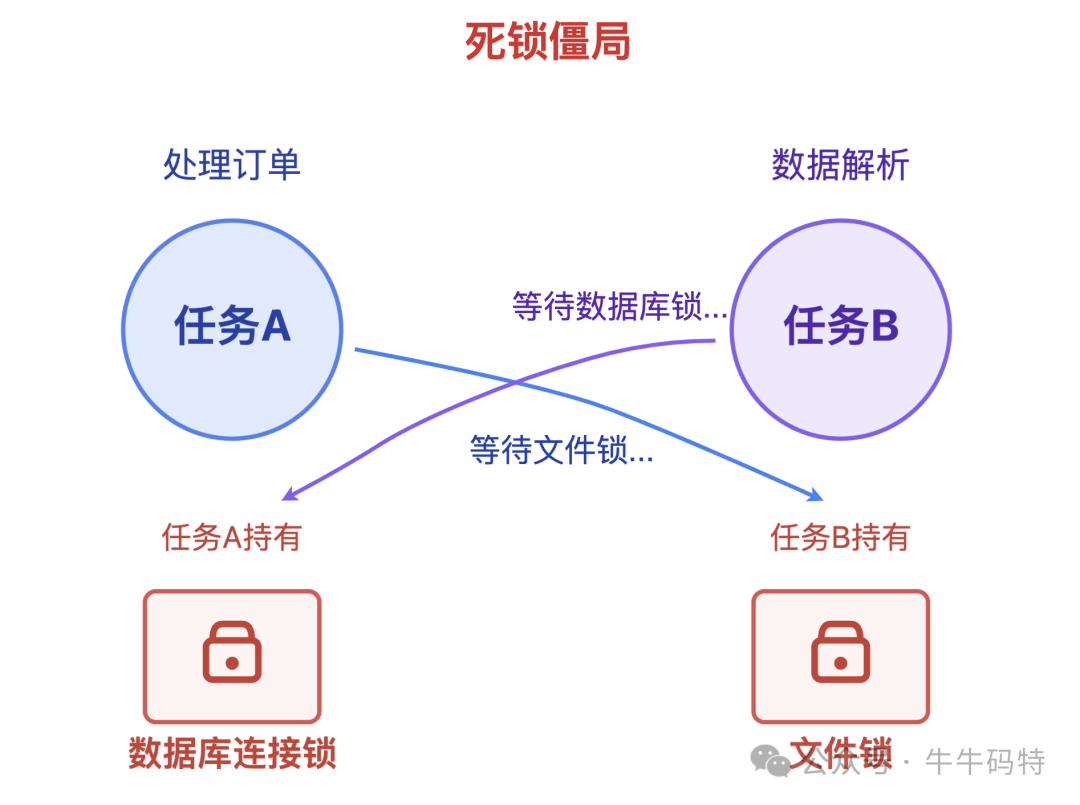
双方都停在原地动弹不得,调度器看到生产线空转却无法强制它们让步,这就是典型的“死锁僵局”。
问题3:任务“谎报需求”——内存泄漏引发的“GC风暴”
有些任务会“偷偷申请资源不还”。例如代码创建了大量临时对象却不及时释放,导致内存泄漏。此时,系统的垃圾回收(GC)机制不得不频繁出动,而执行GC的线程本身会占用大量CPU资源来“分拣、清理垃圾”。
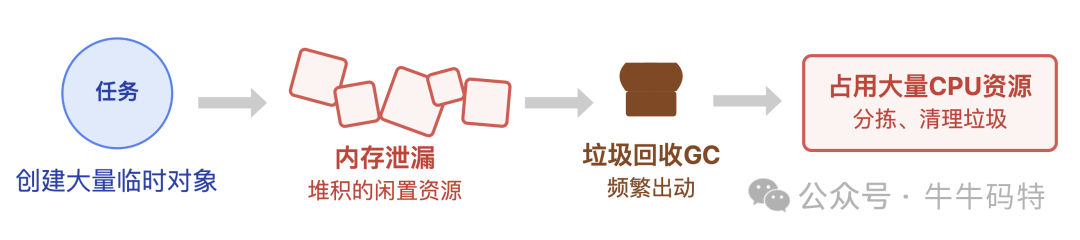
本该正常推进的任务被严重拖慢,整个车间的效率大打折扣。
问题4:调度规则的“盲区”——优先级反转和上下文切换过载
有时,调度规则本身也会“顾此失彼”:
- 优先级反转:高优先级任务被低优先级任务“卡住”,因为后者先占用了关键资源(如锁)。调度器的“优先级规则”在此刻失效。
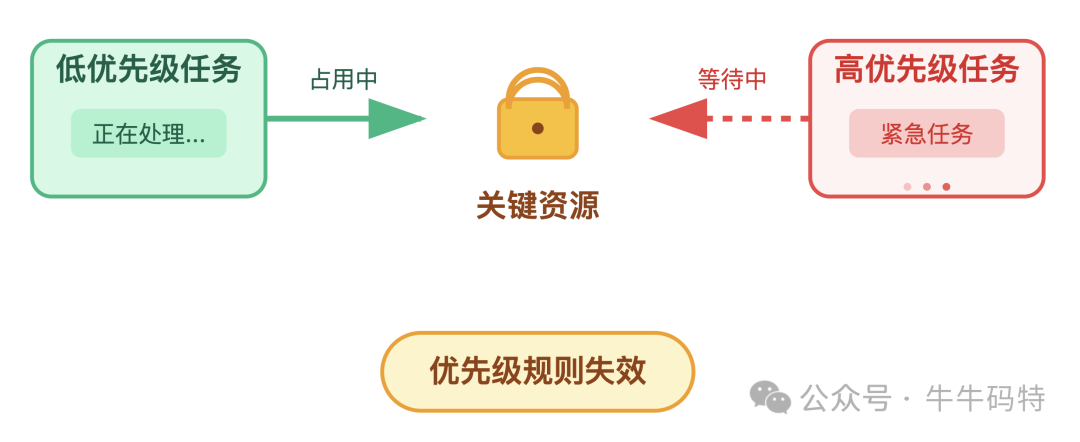
- 上下文切换过载:当同时运行的任务(线程)过多时,调度器不得不频繁切换生产线。每次切换都要保存当前任务进度、加载新任务状态(即“上下文切换”)。这就像工人频繁换岗,花在“交接”上的时间比干活还长,效率骤降。
无论是任务“耍赖”、线程“互不相让”,还是规则存在“盲区”,最终都会导致同一个后果——CPU不堪重负而“罢工”。因此,当故障发生时,快速定位根源是化解危机的关键。
第四站:故障排查——拆解CPU“罢工”的三步溯源技巧
我们需要像经验丰富的设备巡检员,沿着“观察异常→精准检测→定位根源”的路径快速行动。
第一步:看异常现象
首先判断异常是否由CPU引起,可从业务和系统两个维度观察。
业务侧异常通常很直观:用户反馈“支付按钮点不动”;接口超时率从0.1%飙升到30%;消息队列严重堆积;后台定时任务迟迟跑不完。这些都可能是CPU资源不足的信号。
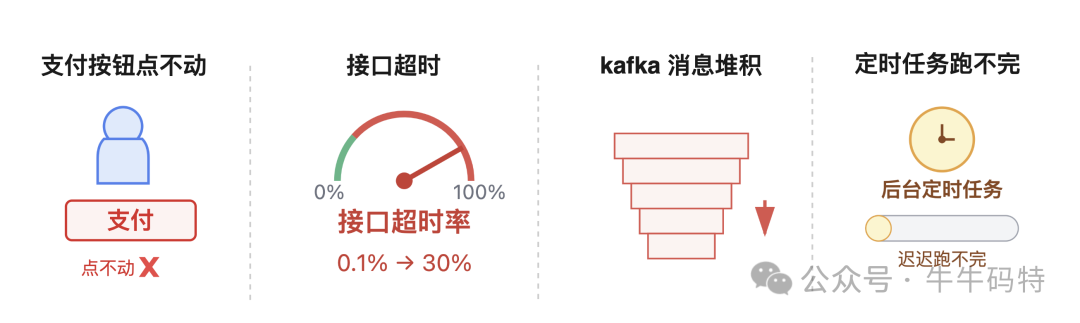
系统侧异常需要通过命令工具top和vmstat查看。
top命令是Linux下的实时进程监控工具。重点关注以下指标:
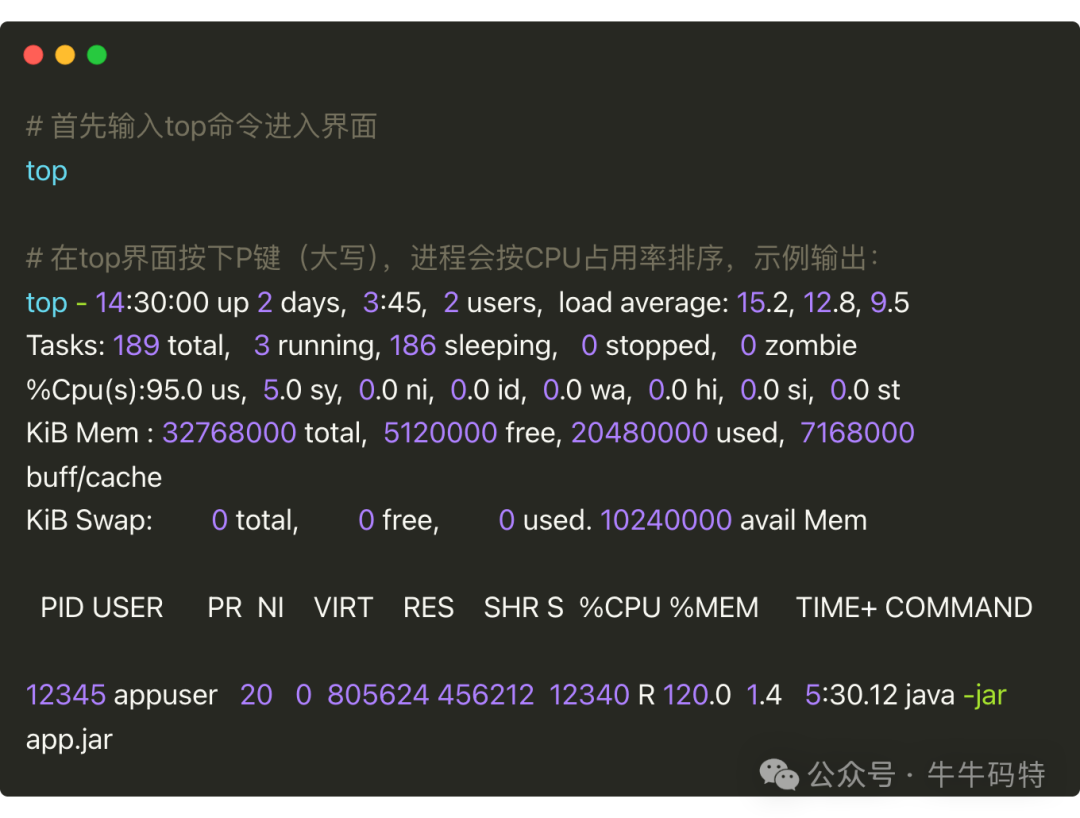
%Cpu(s)行:若us(用户进程占用)+ sy(系统进程占用)= 100%,且id(空闲率)为0,说明CPU已被完全占满。load average: 例如15.2,对于8核CPU,意味着平均有15.2个任务在争夺CPU,负载已超处理能力。- 进程列表:若某个Java进程的
%CPU高达120%,远超单核承载力,则其代码可能存在问题。
vmstat命令专注于报告系统整体状态,如虚拟内存、进程活动、CPU情况。
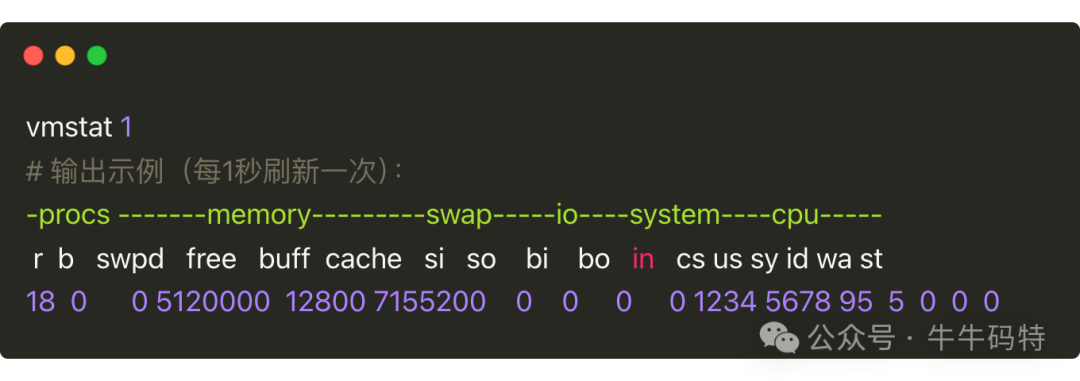
重点关注r列(等待运行的任务数)。示例中r=18,对于8核CPU已严重超负荷。
第二步:找到“问题线程”
确定是CPU问题后,需从高耗进程里揪出具体线程。
首先,定位进程内的高耗线程。 使用top -Hp [进程PID]命令。
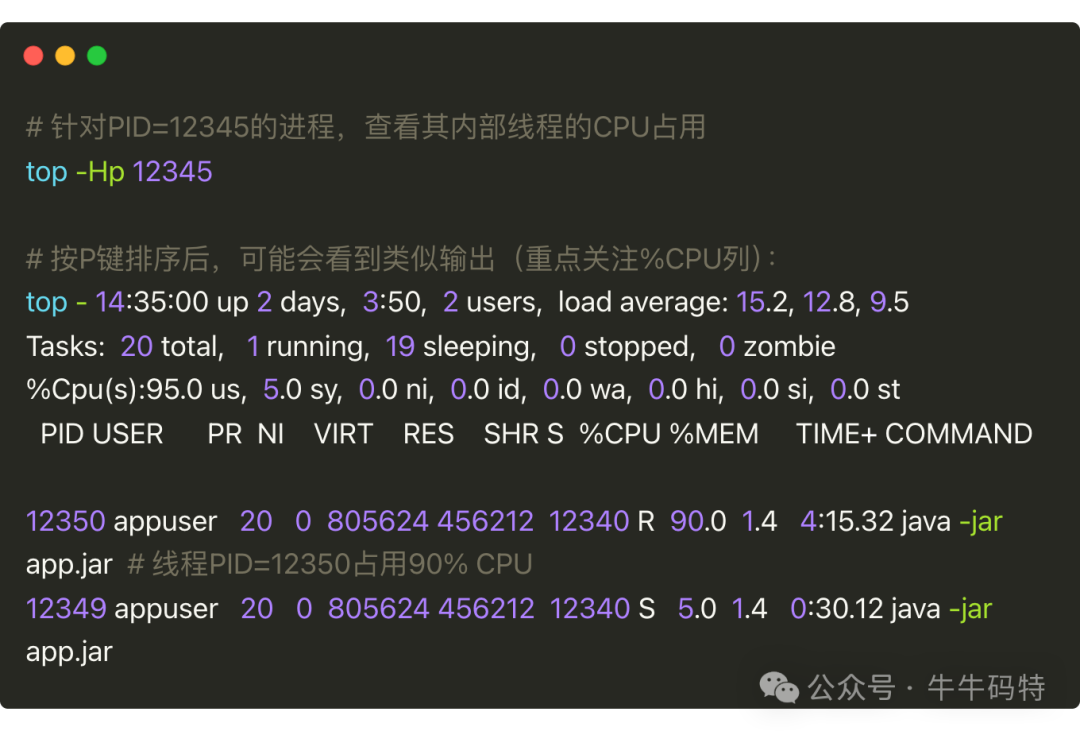
从输出中可找到CPU占用率异常高的线程(如PID=12350,占用90%),记下此线程PID。
接着,查看线程的“运行现场”。 先将线程PID转为16进制(如printf "%x\n" 12350得到0x4f6a)。对于Java进程,使用jstack工具导出线程栈信息分析。
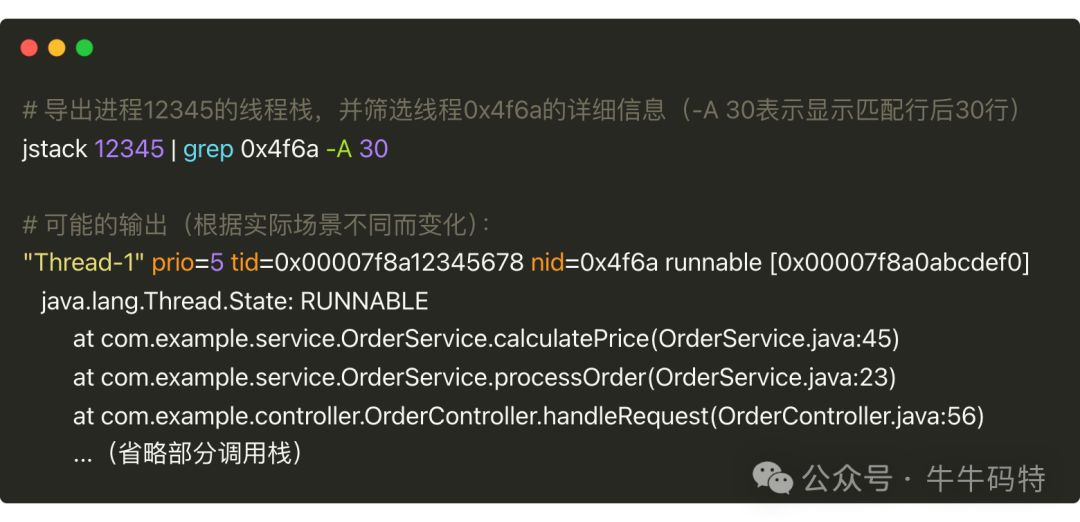
从调用栈可快速判断问题类型:
- 线程死循环:线程在某个方法内无限循环且无退出条件。
- 线程阻塞:日志中出现
waiting for monitor entry字样,说明线程在争抢资源锁。
- GC风暴:出现
GC task thread#0等GC线程活跃信息。

第三步:从线程栈追溯到代码逻辑
找到问题线程后,需顺着调用栈深挖代码根源。
- 死循环验证:直接查看线程栈定位到的代码位置,判断是否存在无限循环。
- 锁竞争验证:通过监控工具观察锁竞争情况。若大量线程阻塞在同一个加锁方法,且持有锁的线程长时间不释放,则锁设计可能有问题。
- GC风暴验证:若线程栈显示GC线程频繁活动,需进一步定位。
- 先用
jstat监控垃圾回收频率。
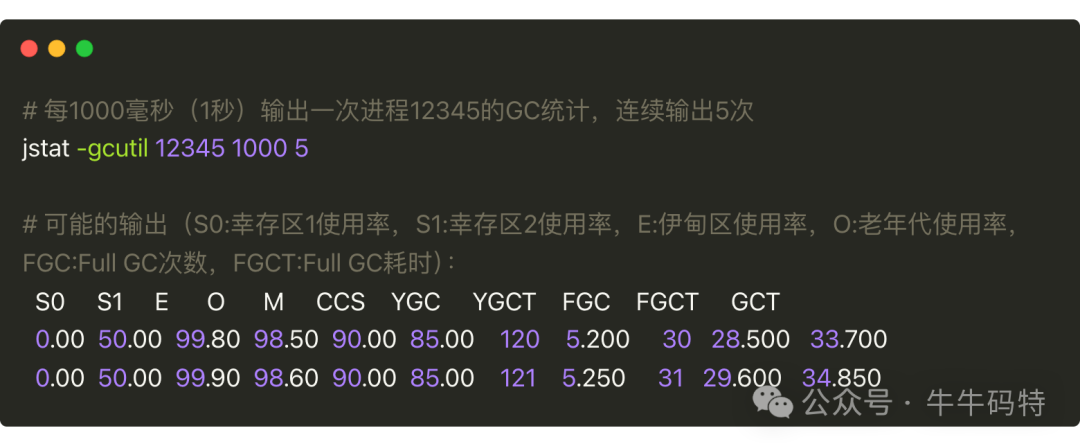
关注FGC(Full GC次数)和FGCT(Full GC总耗时)。示例中1秒内FGC增加1次,耗时近1秒,属于典型GC风暴。
- 再用
jmap查看对象分布,确认内存泄漏。
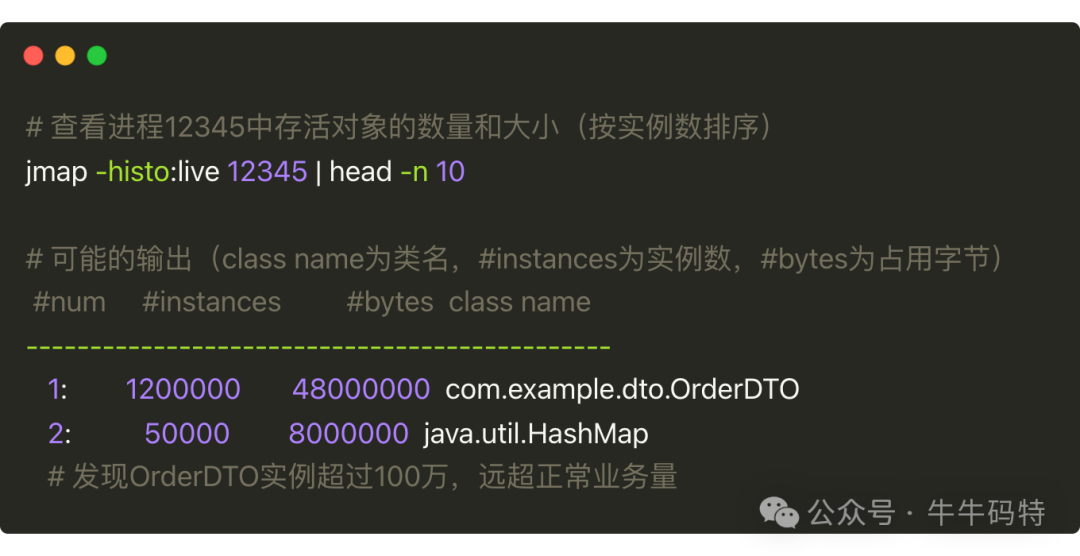
输出显示OrderDTO实例超过100万,远超正常业务量,说明对象未被及时回收,触发频繁Full GC。
通过以上三步,我们就能锁定CPU“罢工”的根源。但找到问题只是第一步,更关键的是如何快速化解危机。
第五站:算力突围——化解CPU“罢工危机”的修复指南
处理CPU“罢工”需分两步走:先临时止损恢复业务,再长期修复根治问题。
第一步:临时止损——5分钟内让CPU“喘口气”
当故障已影响业务时,需快速执行简单有效的操作。
1. 给“故障工序”紧急停机
若确定是某个特定进程(如陷入死循环的Java进程)导致问题,可先保存日志再重启。
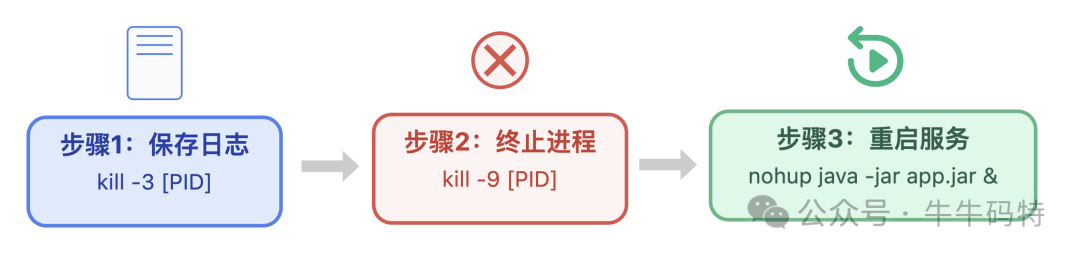
- 通过
kill -3 [进程PID]保存线程日志以便复盘。
- 用
kill -9 [进程PID]强制终止故障进程。
- 最后重启服务,例如Java服务:
nohup java -jar app.jar &。
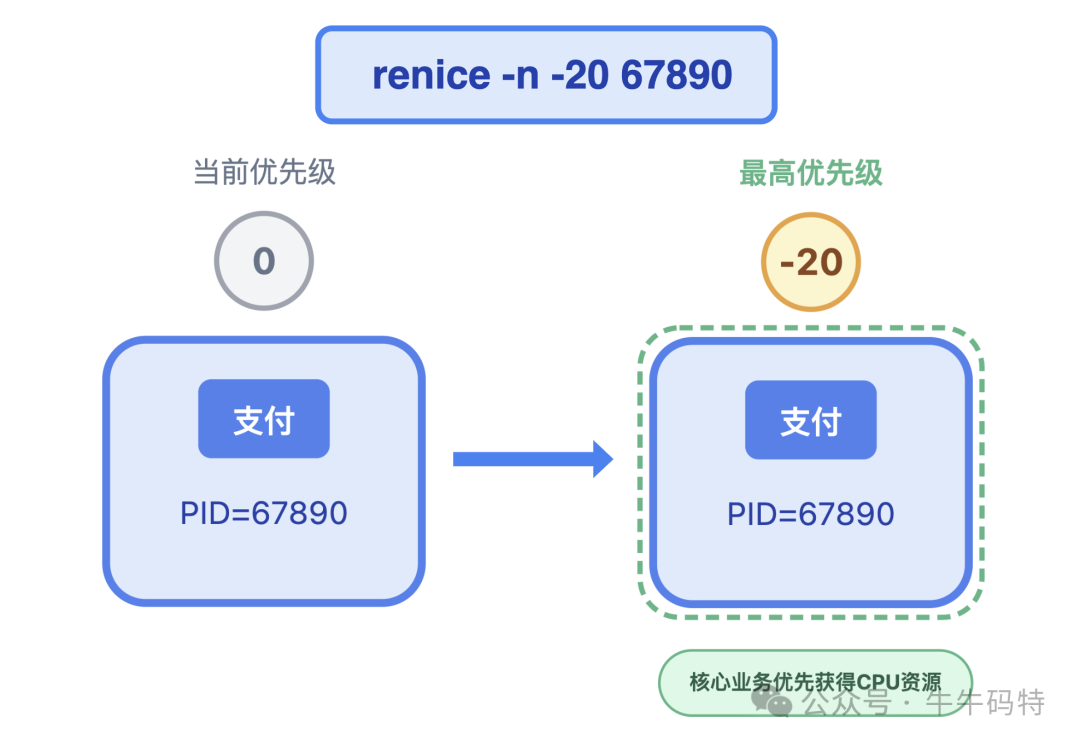
2. 给“核心订单”开绿色通道
- 使用
renice命令提升核心业务进程的优先级(数值越小优先级越高,范围-20到19)。例如,将支付进程(PID=67890)设为最高优先级:renice -n -20 67890。
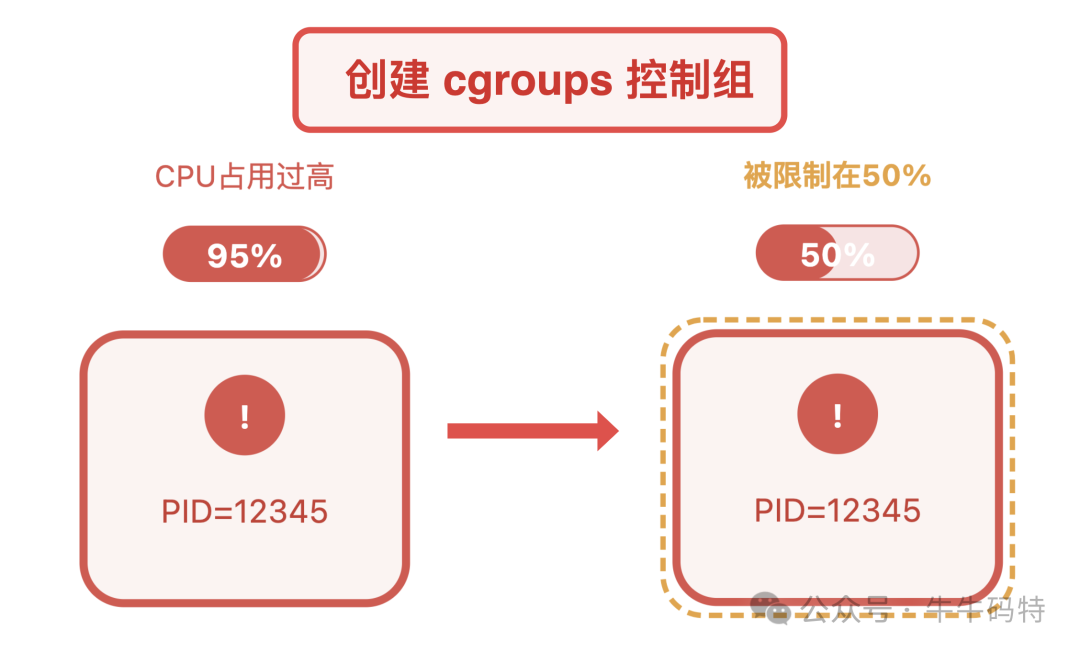
- 使用内核级资源管控工具
cgroups为问题进程设置资源上限。例如,创建一个控制组限制CPU使用率不超过50%,再将问题进程加入该组,能有效遏制资源滥用。
第二步:长期修复——从代码到架构的改造
要从根源上解决问题,需要进行系统性优化。
1. 针对死循环代码:加“超时闹钟”
在可能存在循环的逻辑中加入时间限制,避免无限占用资源。

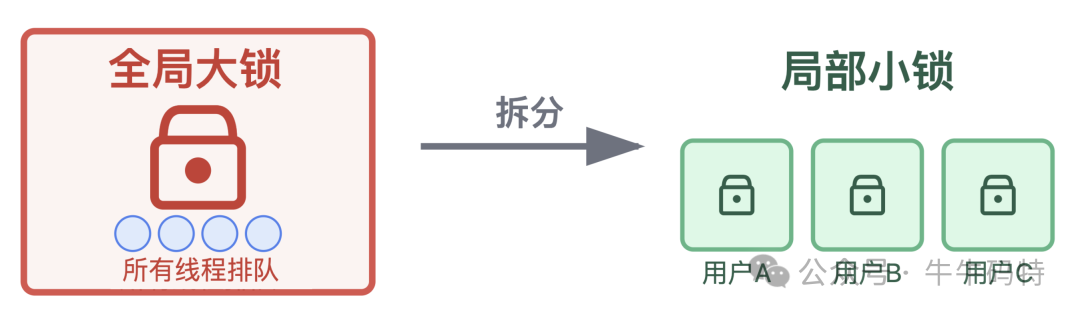
2. 针对锁竞争:把“全局大锁”拆成“局部小锁”
将一把让所有线程排队的全局锁,按业务场景(如用户ID)拆分为多把局部锁,减少竞争。或考虑使用无锁数据结构。
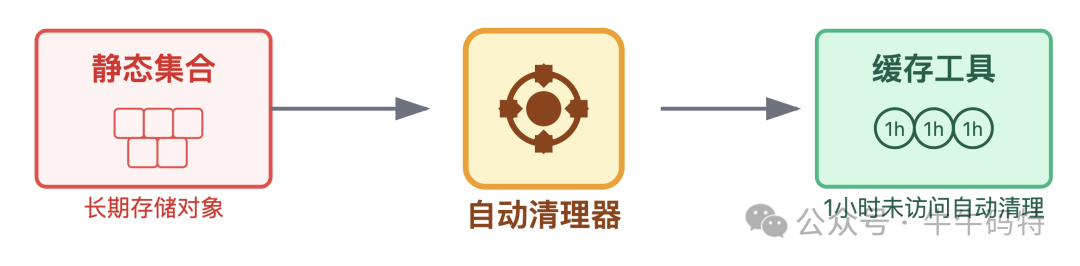
3. 针对GC风暴:给内存装“自动清理器”
避免使用静态集合长期存储对象。改用带过期机制的缓存工具(如Redis、Caffeine),设置合理的存活时间和最大容量。定期使用jmap等工具检测内存对象分布,提前发现泄漏风险。
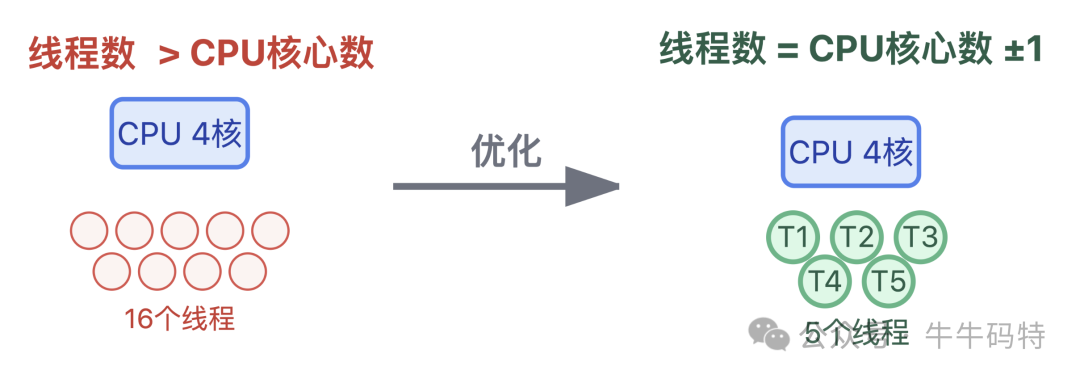
4. 针对上下文切换过载:控制“同时开工的工序数量”
合理设置线程池大小。若线程数远超CPU核心数,会导致频繁的上下文切换。通常可设置为CPU核心数±1,以平衡资源利用与切换开销。这类资源调优的思维,与解决复杂的算法问题有异曲同工之妙,核心都是寻找最优解。
结语:CPU调度的终极思维
CPU使用率100%的危机,并非调度器“失职”,而是任务复杂性超出了既定规则的容错能力。真正的算力调度高手,不应只在告警后充当“救火队长”,而应通过系统性建设防患于未然:
- 监控预警:配置CPU使用率超过80%的预警;设置线程阻塞数超过阈值告警,以便及时介入。
- 代码规范:循环逻辑必须添加超时限制;使用锁时必须明确注释其粒度;大对象缓存需设置过期时间。
- 压测验证:上线前使用压力测试工具(如JMeter)模拟高并发场景,确保在峰值流量下CPU使用率仍有充足缓冲空间(例如低于70%)。
算力调度如同治理城市交通,最高明的方式不是在堵车后疏导,而是在规划时就避免堵点的产生。掌握这套主动防御的思维,并善用系统内核提供的强大工具,你才能真正从被动的故障处理者,转变为主动的算力“调度大师”。
 发表于 2026-3-3 11:31:06
|
查看: 160|
回复: 0
发表于 2026-3-3 11:31:06
|
查看: 160|
回复: 0
