内核开发是一个持续降低开销的过程;任何被内核占用的资源都无法用于用户真正需要运行的工作负载。为此,用于管理内存的 page 结构一直被设计得尽可能小巧。即便如此,页结构通常仍占用可用内存的1.5%以上,对某些用户而言这一比例仍过高。此前,社区探讨过 DMEMFS 作为降低此开销的一种方案,但这并非唯一的探索。目前,两位开发者正各自独立开发补丁,专门针对巨页相关的开销进行优化,这些思路对深入理解操作系统的内存管理机制颇有启发。
内存映射与尾页
如前所述,page 结构存储着内核对系统中每个内存页面的绝大部分信息:使用状态、在不同链表中的位置、后备存储(backing store)位置等。因此,系统中每个物理页面都对应一个 page 结构;在常见配置中,这相当于每 4096 字节的页面就有一个 64 字节的结构,这部分开销正是优化的重点。
在 Linux 早期,内核会分配一个简单的页结构数组,其大小恰好对应系统中安装的内存容量;这种方式之所以可行,是因为物理内存本身就像一个简单的页面数组。然而自那时起,内存管理子系统的工作变得更加复杂。NUMA 系统中的节点拥有独立的内存区域,之间可能存在巨大间隙。内存可以在运行时插入系统(或从中移除)。虚拟化客户机在运行期间也可能动态注入(或移除)内存。因此,原本简单的线性内存模型已不再适用。
内核随时间演变出几种不同的内存映射模型。当前 64 位系统的首选模型称为“sparsemem-vmemmap”;它利用系统的内存管理单元(MMU)重建一个简单线性映射(称为“vmemmap”)的假象。具体而言,每个架构在内核地址空间保留一部分用于此映射;例如,在使用四级页表的 x86-64 架构中,该映射位于 0xffffea0000000000。每当向系统添加内存时(包括内核在启动时发现的内存),都会分配相应数量的 page 结构,并将整个集合映射到 vmemmap 区域。这样,不连续的内存块就能呈现为连续状态,从而简化了许多底层管理功能。
最终效果大致如下所示:
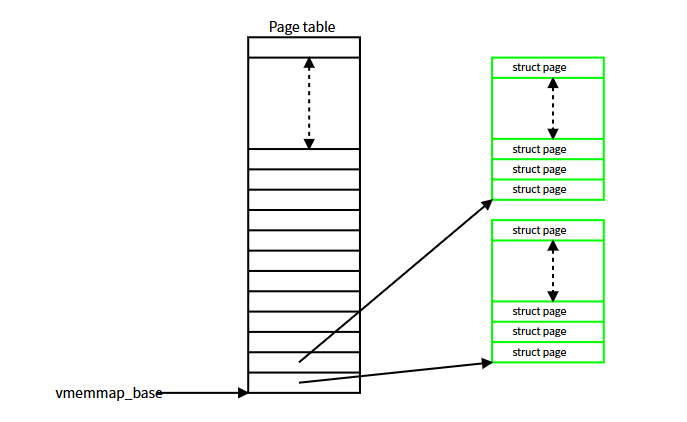
在页大小为 4096 字节且 struct page 为 64 字节的系统中,每 64 个 page 结构就需要分配一个内存页并映射到 vmemmap 数组中。完成映射后,任何给定页面的 page 结构都可通过其页帧号作为 vmemmap_base 的偏移量来定位(x86 系统)。
复合页使情况变得复杂。当一组相邻页面被合并为更大单元时,就形成了复合页。最常见的应用是实现巨页——即由系统 CPU 和 MMU 支持的大尺寸页面。例如 x86-64 架构支持 2MB 和 1GB 巨页,使用它们可带来显著的性能提升。每当从一组单页(“基页”)创建巨页时,相关的 page 结构会被修改以反映它们现在代表的复合页。
复合页中的第一个基页称为“头页”,其余所有页面称为“尾页”。因此,一个 2MB 巨页由一个头页和 511 个尾页组成。头页的 page 结构被标记为复合页,代表整个集合。而尾页的 page 结构仅包含指向头页的指针(严格来说,前几个尾页包含部分复合页元数据,但此处可忽略)。
因此,与 2MB 巨页关联的 512 个 page 结构中,511 个本质上只是写着“请查看另一处”的相同标识副本。这些结构自身占用 8 个内存页,其中 7 页仅代表尾页且包含完全重复的数据。
精简冗余页结构
本文讨论的两个补丁集采用了相同的节省内存思路。率先发布的是 Muchun Song 的补丁集,目前已更新至第八版。Song 意识到没有充分理由保留这些充满相同 page 结构的页面,特别是考虑到 vmemmap 机制已使用虚拟映射。设想上图的紧凑版本:
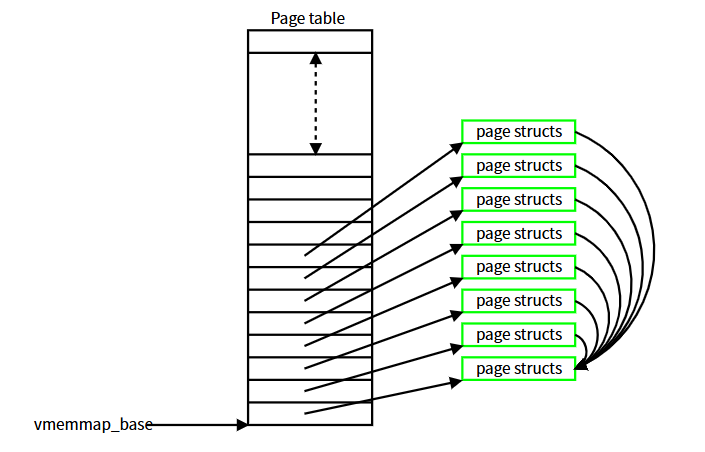
在此图中,一个 2MB 巨页由 8 页 page 结构表示,其中绝大部分对应尾页且仅指向头页结构。
应用 Song 的补丁集后,该结构发生变化。既然 8 页中有 7 页内容完全相同,它们可被单页替代;该单页可被映射 7 次以像之前一样填满 vmemmap 数组:
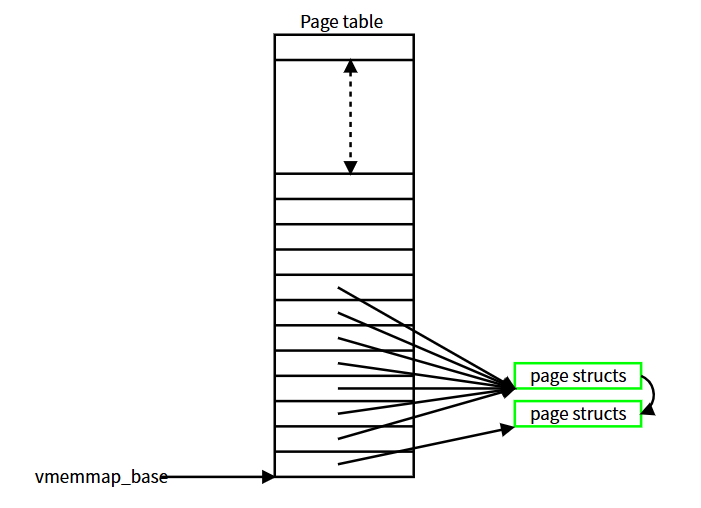
对内核其他部分而言,一切照旧——任何尾页的 page 结构看起来都与过去完全一致。但现在只要复合页继续存在,六页重复数据就可以释放给系统供其他用途使用。换言之,这个复合页的内存开销刚刚被削减了 75%。
对于 1GB 巨页,节省效果更为显著:原本代表尾页的 4096 页 page 结构中可以消除 4094 页。虽然通用系统通常较少使用 1GB 巨页,但在某些场景(包括部分虚拟化工作负载)中它们确实能发挥作用。对托管服务商而言,每个 1GB 巨页能节省近 16MB 开销的前景无疑极具吸引力。
巨页并非永恒存在,它们可能因多种原因被内核回收或拆分。当这种情况发生时,必须恢复完整的 page 结构集合。在 Song 的补丁集中,这项工作被推迟到工作队列中执行,以便在相对宽松的环境下分配所需页面。虽然这给巨页的分配与释放增加了一些计算时间开销,但 Song 提供的一组基准测试结果表明,这种开销“并不显著”。由于该补丁集禁用了 vmemmap 自身使用巨页的功能,也会产生额外开销——如果核心补丁集被采纳,这个问题显然会得到修正。
另一套补丁集来自 Joao Martins。它实现了相同的核心理念,即消除大部分存储尾页 page 结构的页面。不过,Song 的补丁集主要针对主内存,而 Martins 的工作专门面向 非易失性内存(NVRAM)。这类内存总是作为独立操作上线,因此无需从 vmemmap 中释放现有页面;相反,新设备从一开始就以巨页形式上线。这种做法通过省去动态修改 vmemmap 的所有逻辑简化了代码,但代价是降低了该技术的适用范围。
不过,以这种方式处理非易失性内存还有一个附带优势:当连接新内存阵列时,无需初始化大量 page 结构。这大幅加快了内存可供系统使用的进程。使用巨页还能显著加速将此类内存映射到内核空间的操作——当使用 DAX 直接访问子系统 时,这种操作会频繁发生。
两套补丁集似乎各有利弊。目前的问题是,内存管理开发者们极不可能对同时合并两者感兴趣。因此要么需要在二者中择一,要么必须设法将两套补丁集合并成满足所有人需求的单一方案。这种协调过程可能耗时良久,而合并底层内存管理精妙技巧的进程本身也非速成之事。所以这项工作短期内可能不会到来,但从长远看,它很可能为 Linux 系统节省大量内存。
欢迎在云栈社区继续探讨Linux内核与系统性能优化相关话题。
 发表于 2026-1-18 15:54:55
|
查看: 150|
回复: 0
发表于 2026-1-18 15:54:55
|
查看: 150|
回复: 0
