1. 引言:为什么需要 Tasklet?
在进入实现细节前,先问一个关键问题:为什么 Linux 内核需要 tasklet 这种机制?
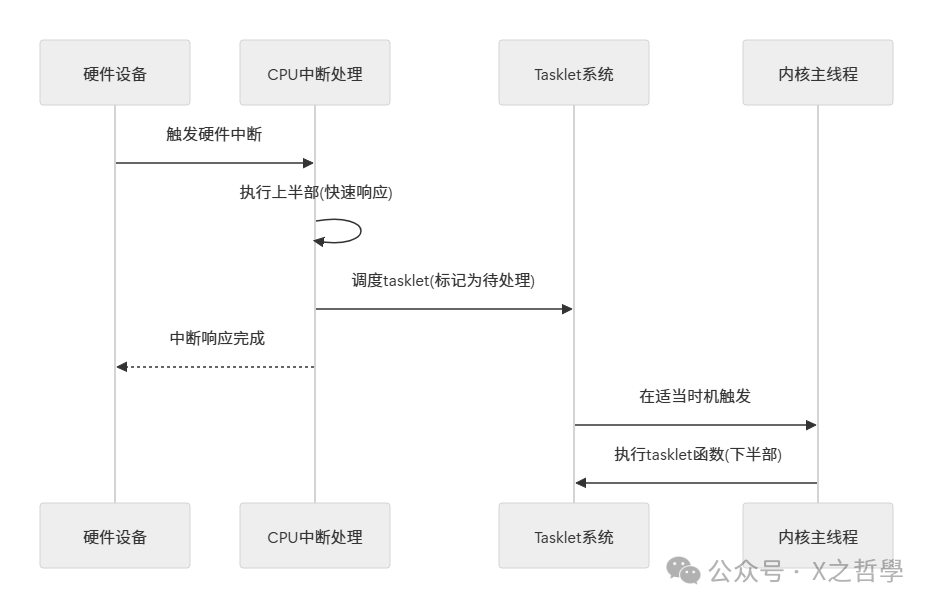
可以把中断处理类比成做饭时被门铃打断:你正在厨房做饭(CPU 执行主要任务),门铃响了(硬件中断)。你去开门签收(中断上半部),但拆箱整理很耗时(后续处理)。更合理的做法是先快速签收,然后回到厨房继续做饭,等空下来再拆箱(延迟处理耗时部分)。
这种“先快后慢”的哲学,是 Linux 中断处理的核心思想:把中断处理拆成两段。
| 部分 |
名称 |
特点 |
类比 |
| 上半部 |
Top Half |
紧急、快速、不可中断 |
快递签收 |
| 下半部 |
Bottom Half |
延迟、可中断、较耗时 |
拆箱整理 |
Tasklet 正是多种“下半部”机制之一。下面这张时序图可以帮助你建立直觉:
2. Tasklet 的设计哲学
2.1 核心设计原则
Tasklet 的设计围绕几个关键点展开:
- 串行化执行:同一个 tasklet 在多个 CPU 上不会并发执行
- 原子性调度:调度过程原子化,尽量避免竞争条件
- 轻量级:相比内核线程,tasklet 开销更小
- 确定性与可靠性:机制简单,行为更可预测
2.2 与其他下半部机制的对比
理解 tasklet 的一个高效方式,是把它与 softirq、workqueue 等放在一起对比:
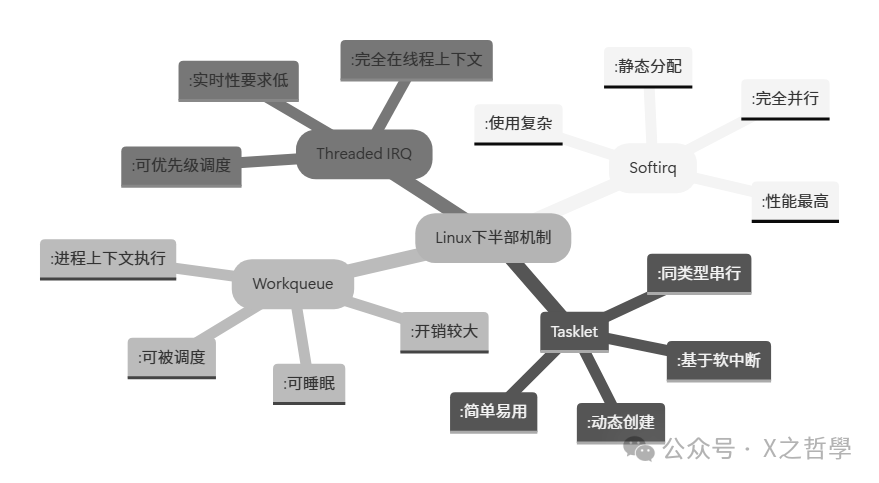
| 特性 |
软中断 (Softirq) |
Tasklet |
工作队列 (Workqueue) |
线程化中断 |
| 执行上下文 |
中断上下文 |
中断上下文 |
进程上下文 |
进程上下文 |
| 可睡眠 |
否 |
否 |
是 |
是 |
| 并发性 |
完全并行 |
同类型串行 |
取决于实现 |
线程调度 |
| 性能开销 |
最低 |
很低 |
较高 |
最高 |
| 使用难度 |
困难 |
简单 |
中等 |
简单 |
| 适用场景 |
网络、块设备等高性能需求 |
通用设备驱动 |
需要睡眠的操作 |
实时性要求不高的驱动 |
3. Tasklet 的核心数据结构
3.1 基础结构体
先看内核源码中的定义(位于 include/linux/interrupt.h):
/* 位于 include/linux/interrupt.h */
struct tasklet_struct {
struct tasklet_struct *next; // 链表指针
unsigned long state; // 状态标志
atomic_t count; // 引用计数器
void (*func)(unsigned long); // 实际的处理函数
unsigned long data; // 传递给函数的参数
};
结构体不复杂,但字段的组合决定了 tasklet 的行为模型:
| 字段 |
类型 |
描述 |
next |
struct tasklet_struct * |
指向下一个 tasklet,用于链表管理 |
state |
unsigned long |
状态标志,控制 tasklet 生命周期 |
count |
atomic_t |
原子计数器,为 0 时 tasklet 才可执行 |
func |
void (*)(unsigned long) |
实际要执行的回调函数 |
data |
unsigned long |
传递给回调函数的参数 |
这类实现细节属于典型的 Linux 内核 并发/中断路径设计:结构体很小,但配套的状态位、原子操作和 per-CPU 队列决定了整体语义。
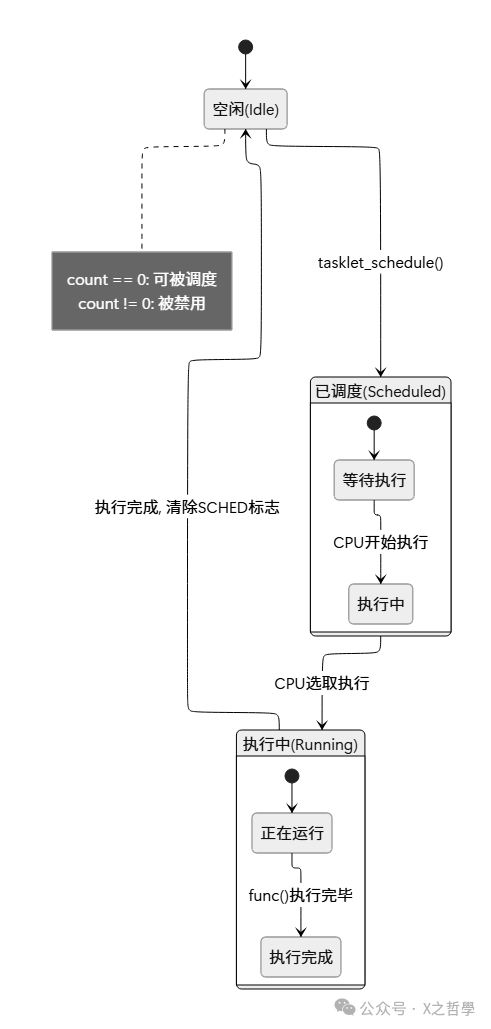
3.2 状态标志详解
state 字段用位掩码表达 tasklet 的不同状态:
/* tasklet 状态标志 */
enum {
TASKLET_STATE_SCHED, /* Tasklet 已被调度, 等待执行 */
TASKLET_STATE_RUN, /* Tasklet 正在执行中 */
TASKLET_STATE_PENDING /* 已废弃, 旧版内核使用 */
};
tasklet 的生命周期可以用状态图来理解:
3.3 每个 CPU 的数据结构
Tasklet 的调度依赖 per-CPU 队列,这是性能和扩展性的核心:
/* 每个CPU的tasklet链表 */
struct tasklet_head {
struct tasklet_struct *head;
struct tasklet_struct **tail;
};
/* 每个CPU有两个tasklet链表 */
static DEFINE_PER_CPU(struct tasklet_head, tasklet_vec);
static DEFINE_PER_CPU(struct tasklet_head, tasklet_hi_vec);
这里有个容易忽略但很关键的设计:两个优先级队列。
tasklet_vec:普通优先级tasklet_hi_vec:高优先级
紧急的 tasklet 可以更快被处理。
4. Tasklet 的实现机制深度解析
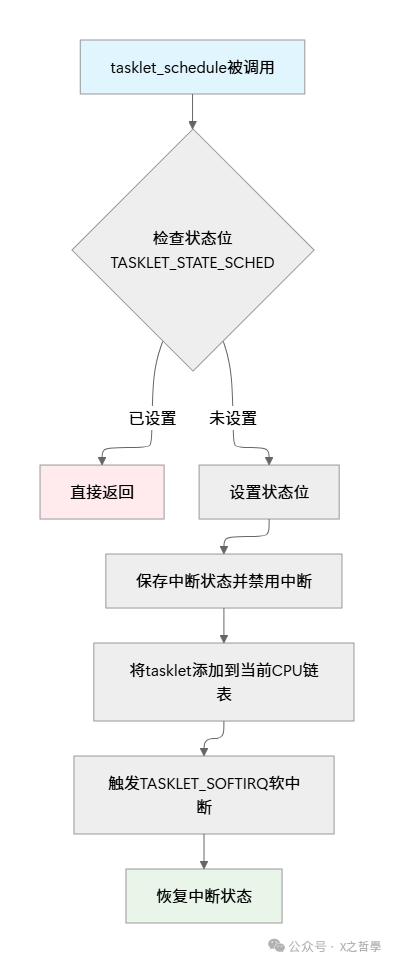
4.1 调度过程:tasklet_schedule()
tasklet 的生命周期从“调度”开始:
void tasklet_schedule(struct tasklet_struct *t)
{
/* 1. 检查tasklet是否已被调度 */
if (test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
return; /* 已经在调度队列中, 直接返回 */
/* 2. 添加到当前CPU的链表中 */
__tasklet_schedule(t);
}
EXPORT_SYMBOL(tasklet_schedule);
真正把 tasklet 放入 per-CPU 队列的是 __tasklet_schedule():
void __tasklet_schedule(struct tasklet_struct *t)
{
unsigned long flags;
/* 获取当前CPU的ID */
local_irq_save(flags); /* 保存中断状态并禁用本地中断 */
/* 将tasklet添加到当前CPU的链表中 */
t->next = NULL;
*__this_cpu_read(tasklet_vec.tail) = t;
__this_cpu_write(tasklet_vec.tail, &(t->next));
/* 触发软中断 */
raise_softirq_irqoff(TASKLET_SOFTIRQ);
local_irq_restore(flags); /* 恢复中断状态 */
}
用流程图看会更清晰:
4.2 执行过程:tasklet_action()
软中断触发后,最终会调用 tasklet_action() 执行普通优先级 tasklet:
static __latent_entropy void tasklet_action(struct softirq_action *a)
{
struct tasklet_struct *list;
/* 1. 禁用本地中断并获取当前CPU的tasklet链表 */
local_irq_disable();
list = __this_cpu_read(tasklet_vec.head);
__this_cpu_write(tasklet_vec.head, NULL);
__this_cpu_write(tasklet_vec.tail, this_cpu_ptr(&empty_tasklet_vec.head));
local_irq_enable();
/* 2. 遍历链表执行所有tasklet */
while (list) {
struct tasklet_struct *t = list;
list = list->next;
/* 3. 检查tasklet是否可执行 (count == 0) */
if (tasklet_trylock(t)) {
/* 4. 确保它仍被调度 (可能被tasklet_kill取消) */
if (!atomic_read(&t->count)) {
/* 5. 清除调度状态 */
clear_bit(TASKLET_STATE_SCHED, &t->state);
/* 6. 设置运行状态并执行 */
set_bit(TASKLET_STATE_RUN, &t->state);
/* 执行用户提供的处理函数 */
t->func(t->data);
/* 7. 清除运行状态 */
clear_bit(TASKLET_STATE_RUN, &t->state);
}
tasklet_unlock(t);
}
/* 8. 重新检查链表, 处理新添加的tasklet */
local_irq_disable();
t->next = NULL;
*__this_cpu_read(tasklet_vec.tail) = t;
__this_cpu_write(tasklet_vec.tail, &(t->next));
list = __this_cpu_read(tasklet_vec.head);
if (!list)
__this_cpu_write(tasklet_vec.tail, this_cpu_ptr(&empty_tasklet_vec.head));
__this_cpu_write(tasklet_vec.head, NULL);
local_irq_enable();
}
}
这个执行路径里有几个“必须盯住”的点:
- 原子性保护:
local_irq_disable/enable() 包住关键区,避免本地中断打断队列摘取与拼接
- 同一 tasklet 的并发禁止:
tasklet_trylock() 保证同一 tasklet 不会跨 CPU 并发执行
- 重入处理:执行过程中可能又调度了新 tasklet,所以需要重新检查链表
4.3 禁止和启用:tasklet_disable() / tasklet_enable()
tasklet 的启用/禁用通过原子计数器 count 实现:
void tasklet_disable(struct tasklet_struct *t)
{
/* 原子增加计数器 */
atomic_inc(&t->count);
/*
* 同步屏障: 确保在计数器增加后,
* 任何正在运行的tasklet都能看到这个变化
*/
smp_mb__after_atomic();
/*
* 等待正在运行的tasklet完成
* 这是一个忙等待, 但通常很快
*/
while (test_bit(TASKLET_STATE_RUN, &(t->state)))
cpu_relax();
}
void tasklet_enable(struct tasklet_struct *t)
{
/*
* 同步屏障: 确保在计数器减少前,
* 所有内存操作都已完成
*/
smp_mb__before_atomic();
/* 原子减少计数器 */
atomic_dec(&t->count);
}
它的语义非常直接:
- 禁用:
count++,并等待正在运行的那次执行结束
- 启用:
count--,不需要等待
- 执行条件:只有
count == 0 时才会执行
4.4 整体架构图解
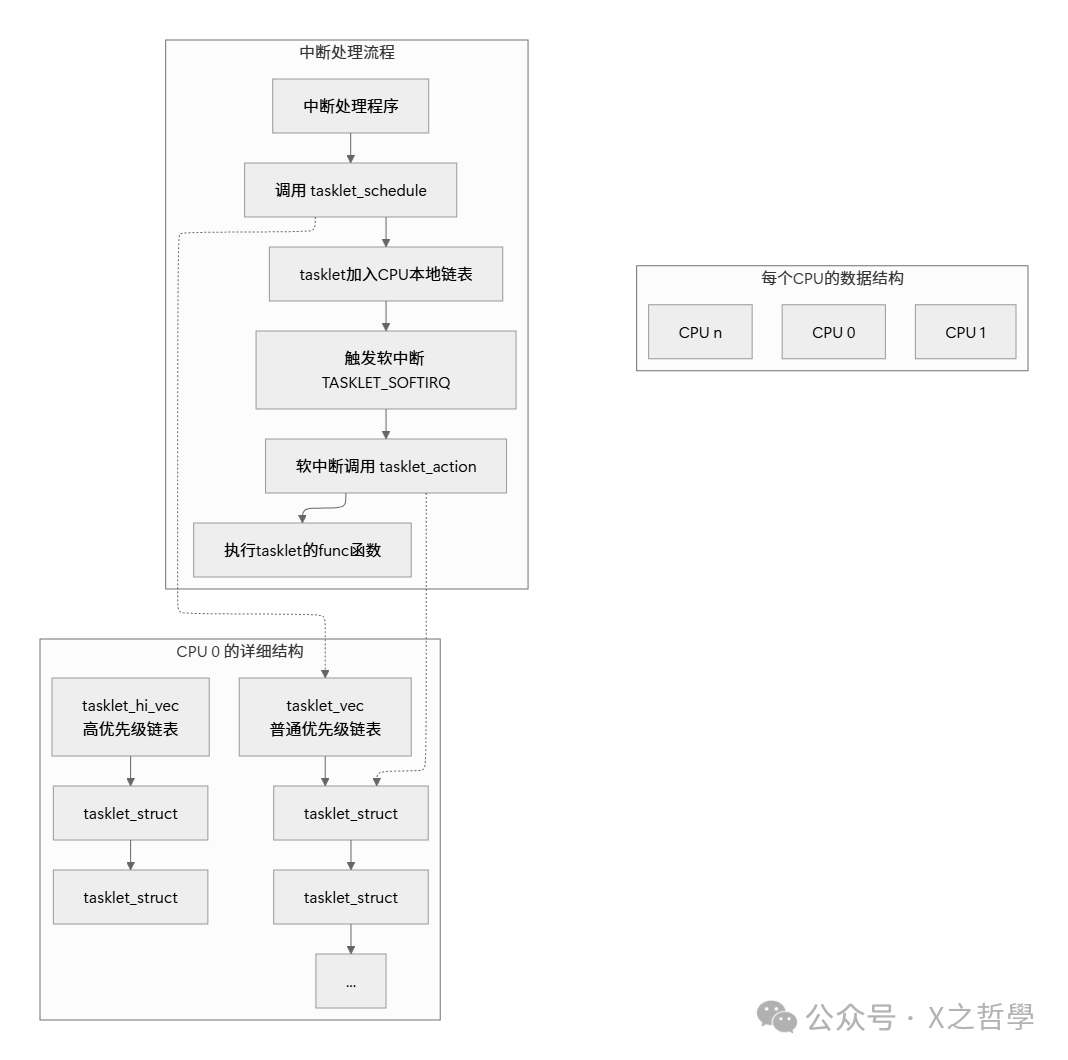
5. Tasklet 的典型使用场景和实例
5.1 何时使用 Tasklet?
tasklet 适合这些场景:
- 中断处理的后半部分:上半部必须快速返回
- 中小型数据处理:数据量不大,但希望尽快处理
- 设备驱动异步操作:比如 DMA 完成后的收尾处理
- 定时器回调的轻量处理:需要快速执行的小任务
5.2 一个简单的字符设备驱动示例
下面是一个示例:模拟字符设备收到数据触发中断,上半部只做快速采集与调度,真正处理放在 tasklet:
示例代码为典型 C 风格驱动写法,涉及结构体、回调与并发语义,想系统梳理相关语法与习惯用法,可参考 C/C++ 相关专题。
#include <linux/module.h>
#include <linux/init.h>
#include <linux/interrupt.h>
#include <linux/fs.h>
#include <linux/cdev.h>
#include <linux/uaccess.h>
/* 定义我们的设备结构 */
struct my_device {
struct cdev cdev;
dev_t devno;
struct tasklet_struct my_tasklet;
char buffer[256];
int data_ready;
};
static struct my_device my_dev;
/* Tasklet 处理函数 */
static void my_tasklet_handler(unsigned long data)
{
struct my_device *dev = (struct my_device *)data;
printk(KERN_INFO "Tasklet 执行: 处理缓冲区数据\n");
/* 这里应该处理设备数据 */
/* 例如: 解析数据、唤醒等待进程等 */
/* 标记数据已处理 */
dev->data_ready = 0;
}
/* 模拟的中断处理程序 */
static irqreturn_t my_interrupt_handler(int irq, void *dev_id)
{
struct my_device *dev = (struct my_device *)dev_id;
printk(KERN_INFO "中断上半部: 接收数据\n");
/* 模拟从硬件读取数据 */
snprintf(dev->buffer, sizeof(dev->buffer),
"数据来自中断, 时间戳: %lld", ktime_get_ns());
dev->data_ready = 1;
/* 调度 tasklet 进行后续处理 */
tasklet_schedule(&dev->my_tasklet);
return IRQ_HANDLED;
}
/* 文件操作: 读取函数 */
static ssize_t my_read(struct file *filp, char __user *buf,
size_t count, loff_t *f_pos)
{
struct my_device *dev = filp->private_data;
int ret;
/* 等待数据就绪 */
while (!dev->data_ready) {
if (filp->f_flags & O_NONBLOCK)
return -EAGAIN;
/* 在实际驱动中, 这里应该使用等待队列 */
msleep(10);
}
/* 将数据复制到用户空间 */
if (count > sizeof(dev->buffer))
count = sizeof(dev->buffer);
ret = copy_to_user(buf, dev->buffer, count);
if (ret)
return -EFAULT;
dev->data_ready = 0;
return count;
}
static const struct file_operations my_fops = {
.owner = THIS_MODULE,
.read = my_read,
};
/* 模块初始化 */
static int __init my_module_init(void)
{
int ret;
printk(KERN_INFO "初始化 Tasklet 示例模块\n");
/* 初始化 tasklet */
tasklet_init(&my_dev.my_tasklet, my_tasklet_handler,
(unsigned long)&my_dev);
/* 分配设备号 */
ret = alloc_chrdev_region(&my_dev.devno, 0, 1, "my_tasklet_dev");
if (ret < 0) {
printk(KERN_ERR "无法分配设备号\n");
return ret;
}
/* 初始化字符设备 */
cdev_init(&my_dev.cdev, &my_fops);
my_dev.cdev.owner = THIS_MODULE;
ret = cdev_add(&my_dev.cdev, my_dev.devno, 1);
if (ret < 0) {
printk(KERN_ERR "无法添加字符设备\n");
unregister_chrdev_region(my_dev.devno, 1);
return ret;
}
/* 注册中断处理程序 (这里使用虚拟中断号) */
ret = request_irq(100, my_interrupt_handler, 0,
"my_tasklet_irq", &my_dev);
if (ret < 0) {
printk(KERN_ERR "无法注册中断\n");
cdev_del(&my_dev.cdev);
unregister_chrdev_region(my_dev.devno, 1);
return ret;
}
printk(KERN_INFO "模块初始化完成\n");
return 0;
}
/* 模块清理 */
static void __exit my_module_exit(void)
{
/* 禁用 tasklet */
tasklet_disable(&my_dev.my_tasklet);
/* 等待 tasklet 完成 */
tasklet_kill(&my_dev.my_tasklet);
/* 释放中断 */
free_irq(100, &my_dev);
/* 删除字符设备 */
cdev_del(&my_dev.cdev);
unregister_chrdev_region(my_dev.devno, 1);
printk(KERN_INFO "模块卸载完成\n");
}
module_init(my_module_init);
module_exit(my_module_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Linux Kernel Expert");
MODULE_DESCRIPTION("Tasklet 使用示例");
5.3 执行流程分析
这个示例体现了典型模式:
- 中断到来:
my_interrupt_handler 被调用
- 快速处理:只保存必要数据并调度 tasklet
- tasklet 入队:
tasklet_schedule 把 tasklet 加入 per-CPU 队列
- 软中断上下文执行:
my_tasklet_handler 异步运行
- 后续处理完成:处理数据并更新状态
6. Tasklet 的高级主题和内部细节
6.1 锁机制与并发控制
tasklet 的并发控制是精华之一,核心在 TASKLET_STATE_RUN 这个位:
/* tasklet_trylock 的实现 */
static inline int tasklet_trylock(struct tasklet_struct *t)
{
return !test_and_set_bit(TASKLET_STATE_RUN, &t->state);
}
/* tasklet_unlock 的实现 */
static inline void tasklet_unlock(struct tasklet_struct *t)
{
smp_mb__before_atomic();
clear_bit(TASKLET_STATE_RUN, &t->state);
}
要点集中在三句话:
test_and_set_bit 是原子操作:测试并设置一次完成- 内存屏障保证顺序性:避免乱序导致的“看见旧状态/旧数据”
- 它不是传统自旋锁那样的“忙等”,更像一次性互斥门闩
6.2 Tasklet 的优先级系统
Linux 提供两种 tasklet:
/* 高优先级 tasklet 的调度 */
void tasklet_hi_schedule(struct tasklet_struct *t)
{
/* 实现与 tasklet_schedule 类似, 但使用高优先级链表 */
}
/* 高优先级 tasklet 的处理 */
static void tasklet_hi_action(struct softirq_action *a)
{
/* 与 tasklet_action 类似, 但处理高优先级链表 */
}
优先级差异体现在软中断编号上:
| 软中断类型 |
软中断编号 |
优先级 |
用途 |
HI_SOFTIRQ |
0 |
最高 |
高优先级 tasklet |
TIMER_SOFTIRQ |
1 |
高 |
定时器 |
NET_TX_SOFTIRQ |
2 |
中 |
网络发送 |
NET_RX_SOFTIRQ |
3 |
中 |
网络接收 |
BLOCK_SOFTIRQ |
4 |
中 |
块设备 |
IRQ_POLL_SOFTIRQ |
5 |
中 |
IRQ 轮询 |
TASKLET_SOFTIRQ |
6 |
低 |
普通 tasklet |
SCHED_SOFTIRQ |
7 |
低 |
调度器 |
HRTIMER_SOFTIRQ |
8 |
低 |
高精度定时器 |
RCU_SOFTIRQ |
9 |
最低 |
RCU 回调 |
6.3 与其他机制的交互
Tasklet 并不是孤立存在的,它和软中断、驱动、协议栈等模块在同一条中断后处理链路上:

7. Tasklet 的调试和性能分析
7.1 调试工具和技术
7.1.1 Proc 文件系统接口
# 查看软中断统计信息
cat /proc/softirqs
输出示例:
CPU0 CPU1 CPU2 CPU3
HI: 5 2 3 1
TIMER: 123456 123450 123445 123440
NET_TX: 100 95 90 85
NET_RX: 1000 995 990 985
BLOCK: 50 45 40 35
IRQ_POLL: 0 0 0 0
TASKLET: 200 195 190 185
SCHED: 5000 4995 4990 4985
HRTIMER: 10 8 6 4
RCU: 30000 29995 29990 29985
7.1.2 Ftrace 跟踪
# 启用 tasklet 跟踪
echo 1 > /sys/kernel/debug/tracing/events/irq/tasklet_entry/enable
echo 1 > /sys/kernel/debug/tracing/events/irq/tasklet_exit/enable
# 查看跟踪结果
cat /sys/kernel/debug/tracing/trace
7.1.3 动态打印调试
#include <linux/dynamic_debug.h>
/* 控制动态打印 */
static void debug_tasklet(struct tasklet_struct *t, const char *action)
{
pr_debug("Tasklet %ps %s on CPU %d, state: 0x%lx, count: %d\n",
t->func, action, smp_processor_id(), t->state,
atomic_read(&t->count));
}
/* 在调度时调用 */
debug_tasklet(t, "scheduled");
7.2 常见问题与解决方案
| 问题现象 |
可能原因 |
解决方案 |
| 系统延迟增加 |
Tasklet 处理时间过长 |
1. 优化处理函数;2. 考虑使用工作队列 |
| 死锁 |
Tasklet 中调用了可能睡眠的函数 |
1. 检查所有函数调用;2. 用工作队列替代 |
| 数据竞争 |
共享数据未正确保护 |
1. 原子操作;2. 自旋锁保护 |
| Tasklet 不执行 |
count 不为 0 或未调度 |
1. 检查 tasklet_disable/enable;2. 确认调度函数被调用 |
| CPU 使用率过高 |
tasklet 调度过于频繁 |
1. 合并请求;2. 增加调度延迟 |
7.3 性能优化技巧
- 批量处理:把多个小任务合成一个批处理
- 提高优先级:必要时使用
tasklet_hi_schedule
- CPU 亲和性:将处理尽量留在数据所在 CPU 上
- 监控统计:用
/proc/softirqs 观察趋势,而不是只看瞬时值
8. 实战案例分析:网络驱动中的 Tasklet
网络驱动是 tasklet 的经典落点:中断上半部越快越好,把包处理挪到下半部批量做。
/* 简化版的网络驱动 tasklet 处理 */
struct nic_private {
struct net_device *dev;
struct tasklet_struct tx_tasklet;
struct tasklet_struct rx_tasklet;
struct sk_buff_head tx_queue;
struct sk_buff_head rx_queue;
};
/* 发送 tasklet 处理函数 */
static void tx_tasklet_handler(unsigned long data)
{
struct nic_private *priv = (struct nic_private *)data;
struct sk_buff *skb;
/* 处理所有待发送的数据包 */
while ((skb = skb_dequeue(&priv->tx_queue))) {
if (nic_send_packet(priv, skb) < 0) {
/* 发送失败, 重新排队 */
skb_queue_head(&priv->tx_queue, skb);
break;
}
dev_kfree_skb(skb);
}
}
/* 接收 tasklet 处理函数 */
static void rx_tasklet_handler(unsigned long data)
{
struct nic_private *priv = (struct nic_private *)data;
struct sk_buff *skb;
/* 处理所有接收到的数据包 */
while ((skb = skb_dequeue(&priv->rx_queue))) {
/* 传递给网络协议栈 */
netif_receive_skb(skb);
}
}
/* 中断处理程序 */
static irqreturn_t nic_interrupt(int irq, void *dev_id)
{
struct nic_private *priv = dev_id;
u32 status;
/* 读取中断状态 */
status = nic_read_status(priv);
if (status & TX_COMPLETE) {
/* 调度发送 tasklet */
tasklet_schedule(&priv->tx_tasklet);
}
if (status & RX_READY) {
/* 调度接收 tasklet */
tasklet_hi_schedule(&priv->rx_tasklet); /* 使用高优先级 */
}
return IRQ_HANDLED;
}
这个模式有三条经验结论:
- 中断上半部尽量只做:读状态、搬少量数据、触发下半部
- tasklet 适合做“队列批处理”:一次处理完一批 skb
- 接收路径往往比发送更敏感:高优先级更常见
9. 总结与最佳实践
9.1 Tasklet 的核心要点
| 特性类别 |
具体内容 |
| 设计目标 |
快速中断处理的延迟部分 |
| 执行上下文 |
软中断 / 中断上下文 |
| 调度方式 |
per-CPU 链表 + 原子操作 |
| 并发特性 |
同一 tasklet 不跨 CPU 并发执行 |
| 同步原语 |
原子计数器 + 状态位 |
| 优先级 |
普通 / 高优先级两种 |
| 生命周期 |
调度 → 执行 → 完成 |
| 调试支持 |
proc 接口、tracepoint、动态调试 |
9.2 最佳实践指南
-
何时使用 Tasklet:
- 处理时间在微秒级别
- 不需要睡眠
- 需要低延迟响应
- 数据量适中
-
何时避免 Tasklet:
- 处理时间超过 100 微秒
- 需要调用可能睡眠的函数
- 需要复杂同步机制
- 实时性要求不高(更适合 workqueue / 线程化)
-
性能优化建议(批量处理优先):
/* 不好的做法: 频繁调度小任务 */
for (i = 0; i < 100; i++) {
tasklet_schedule(&small_task);
}
/* 好的做法: 批量处理 */
void process_batch(unsigned long data) {
for (i = 0; i < 100; i++) {
process_item(i);
}
}
- 错误处理与退出清理(务必对称):
/* 总是检查tasklet状态 */
if (!test_bit(TASKLET_STATE_SCHED, &t->state)) {
/* 安全地调度 */
tasklet_schedule(t);
}
/* 在模块退出时正确清理 */
static void __exit my_exit(void) {
tasklet_disable(&my_tasklet);
tasklet_kill(&my_tasklet); /* 等待完成 */
/* 其他清理工作 */
}
想继续交流内核中断下半部、驱动并发与调试路径,也可以在 云栈社区 里检索相关主题进行讨论与补充案例。
 发表于 2026-1-18 19:24:36
|
查看: 246|
回复: 0
发表于 2026-1-18 19:24:36
|
查看: 246|
回复: 0
