本文将以算法工程师的独特视角,探讨面对“安逸家乡”与“一线核心”两类Offer时,如何跳出静态思维陷阱,在动态的职业路径中构建渐进式最优决策。
最近,作为一名985院校统计专业的毕业生,我在纠结几个新收到的Offer。这种情况非常典型,估计也是许多算法同学的缩影:
- Offer A(家乡):离家近,生活安逸,岗位在公司的AI部门。但所在组属于辅助性质,技术栈偏旧,发展上限清晰可见。
- Offer B(一线):离家远,位于一线城市的制造业核心研究院。组内技术氛围好,技术栈广,能接触到业界前沿技术。
- Offer C(家乡):离家最近,银行信息科技岗,福利保障完善,工作生活平衡,但薪酬总包较低。(已拒)
为了更清晰地表达这个选择框架,我画了一个示意图:
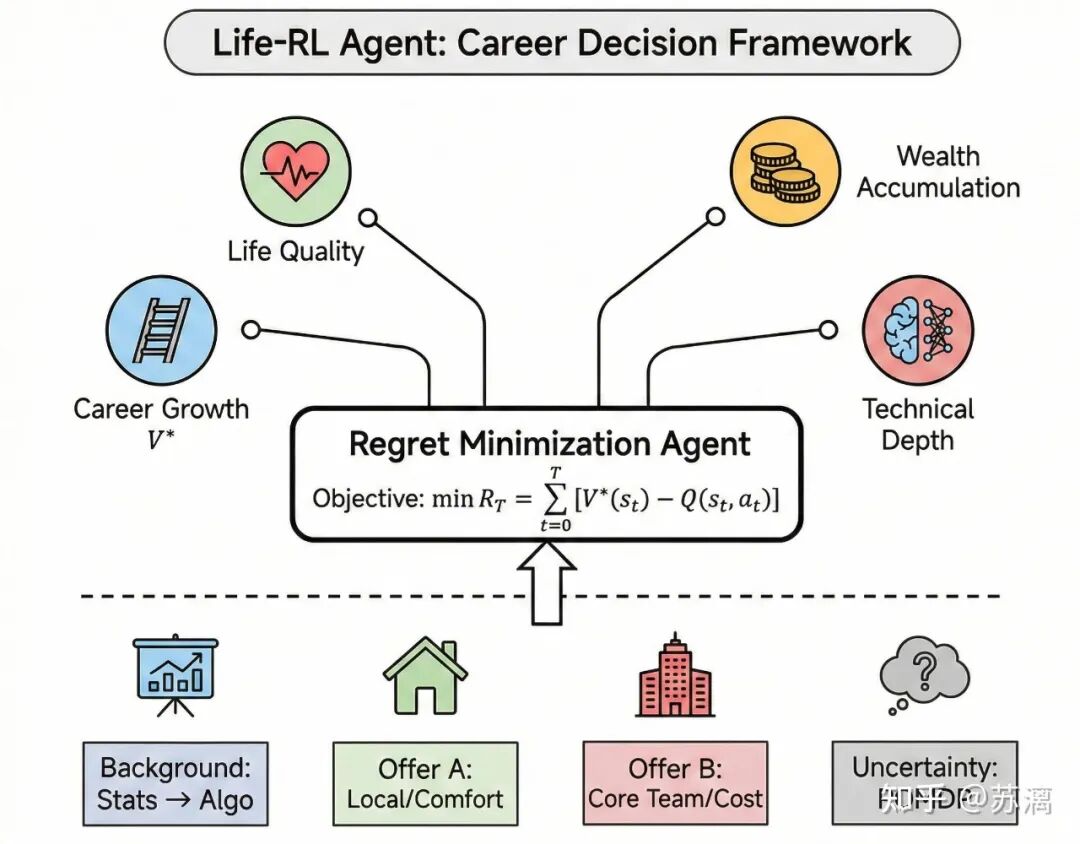
基于此,我陷入了严重的内耗,试图用统计学方法去计算不同选择的期望收益 E[Utility]。
直到一位前辈对我说了一句话,彻底改变了我的心态:“只考虑Package(薪资包)是无法支撑你走下去的。现在的权衡一万次,也只是在找局部最优解,谁能知道全局最优解是什么呢?乐呵乐呵得了。”
是啊,我们算法工程师天天研究非凸优化,怎么到了自己的人生选择上,却妄图用贪心算法一步到位呢?
问题定义:序贯决策下的终身遗憾最小化
作为一名从统计专业转向算法领域的同学,当面临“离家近但发展受限”与“一线核心组但成本高昂”这两个Offer时,我看到的不是一个简单的二选一问题,而是一个部分可观测的序贯决策问题。
我们的目标,是试图最小化整个职业生涯的终身遗憾函数:
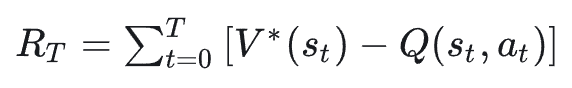
其中,V* 代表潜在的最优人生路径价值,而在每个职业发展的节点 s_t 上,我们只能基于不完全的信息(公司前景、团队氛围、个人成长空间等),做出决策动作 a_t。
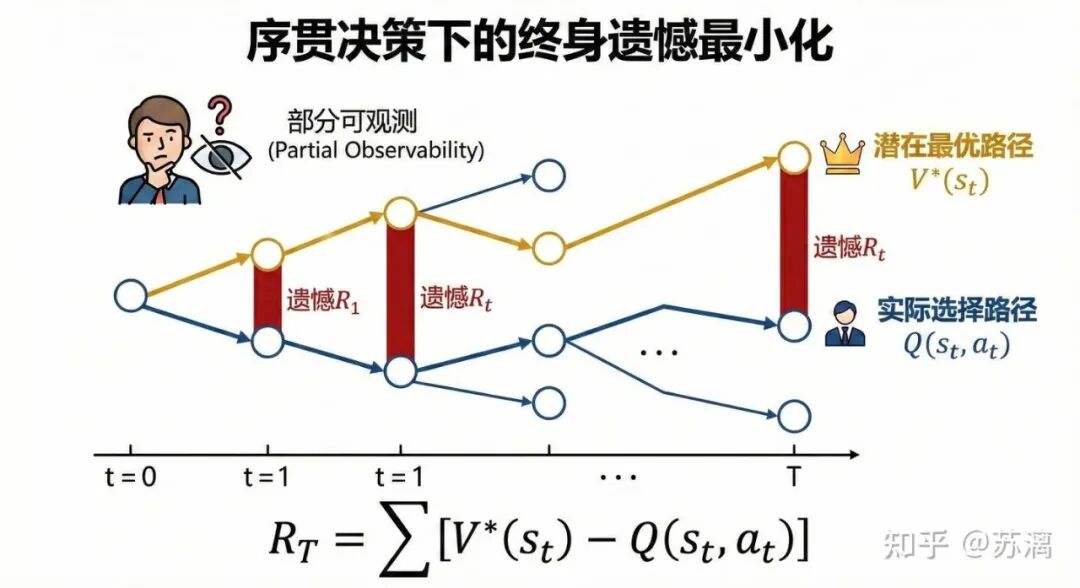
我们都被困在了“局部最优”里
从优化理论的角度来看,现在的焦虑本质上源于我们试图在一个高维、非凸、且随时间动态变化的目标函数 J(θ_t) 中寻找全局最小值。
手中的Offer,就像是不同的模型初始化参数:
- 选择家乡(Offer A):这好比选择了一个较小的学习率,步长稳健,梯度平滑。好处是容易收敛到一个局部极小值——生活舒适,父母在侧。但风险在于,你可能会陷入这个“舒适区”的局部最优而难以跳出,若干年后当你想探索新可能时,会发现“梯度”已经消失。
- 选择一线核心组(Offer B):这更像是一个带有动量的初始化。这里的“梯度”大,更新快,你可能迅速下降到更低的损失区域(获得更高的技术成就与薪酬)。但地形也更为崎岖,充满了鞍点,稍有不慎就可能遭遇“梯度爆炸”(职业倦怠)。
我们当下的纠结,就像是站在 t=0 这个起点,试图用有限的“验证集”(短暂的实习体验、网络上的风评)去拟合未来20年的“测试集”。这本身就是一个病态问题。
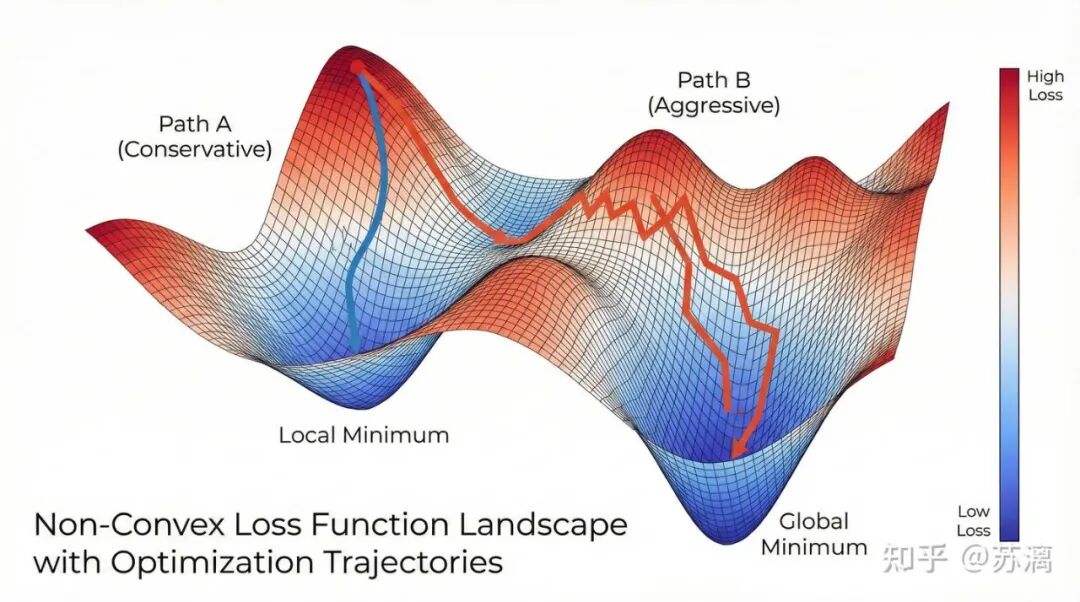
所谓的“全局最优”,根本不存在解析解
我们总是害怕选错,觉得选了安逸就“废了”,选了拼搏就“漂了”。但现实是,人生的目标函数是随时间变化的:
- 23岁时,目标函数中权重最大的可能是技术成长和薪资。
- 30岁时,“正则化项”可能就变成了家庭、健康或生活的稳定。
前辈说得对,只盯着Package看,就像训练模型时只看Training Loss而忽略Validation Loss。当下的高薪,并不代表长期的泛化能力强。支撑一个人长期走下去的,往往是那些难以量化的潜在特征:比如团队中令人舒适的协作氛围,解决一个复杂技术难题带来的成就感,或是家乡生活中那份简单的温暖。
如果执着于寻找那个根本不存在的“全局最优解”,就会像陷入死循环的程序,在原地抖动,最终耗尽“内存”。前辈说的“乐呵乐呵得了”,翻译成专业术语就是:增加职业决策系统的鲁棒性,而非盲目追求短期准确率。
所谓的“全局最优”,根本不存在一个封闭形式的解析解。 它是一个随时间 t 演变的随机过程。因此,与其纠结期望收入 E[Income] 和生活方差 Var[Life],不如引入一点模拟退火的思想:在“温度”(年龄和试错成本)还相对较高的时候,可以接受一定程度上的“次优解”(无论是去一线奋斗还是回老家沉淀),目的就是为了跳出当前思维的局部陷阱。
给生活加一点“随机扰动”
在强化学习中,有一个核心概念叫探索与利用:
- Offer A(家乡)更偏向于“利用”:利用现有已知的资源与环境,确保稳定收益。
- Offer B(一线)更偏向于“探索”:探索未知的边界,虽有风险,但能极大丰富和更新你的人生“Q-Table”(经验价值表)。
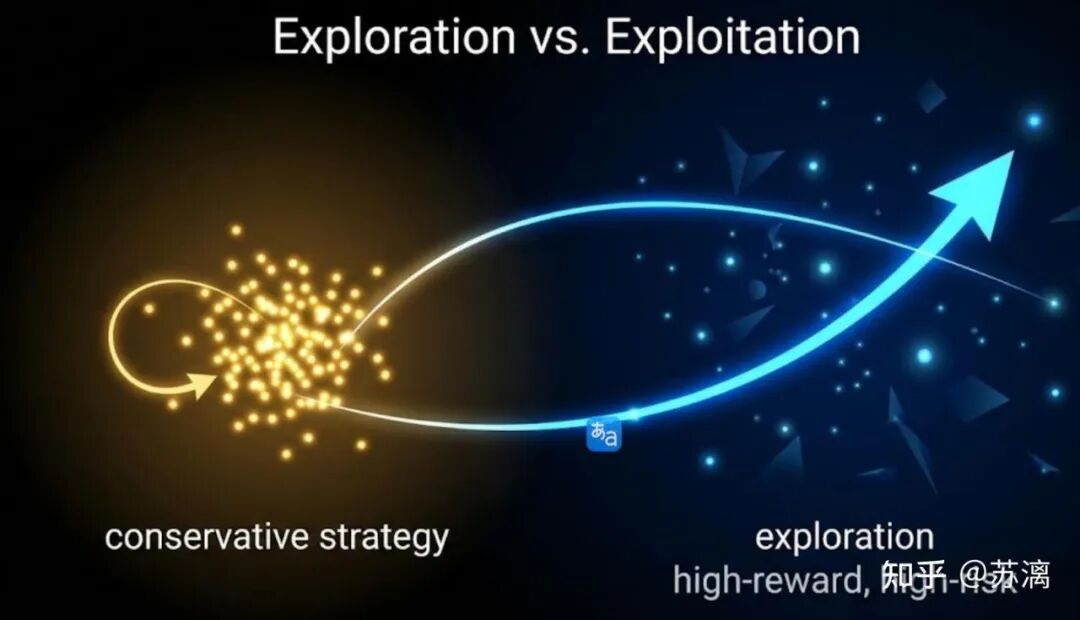
作为应届生,我们的人生“训练轮数”还很少,模型远未收敛。此时,适当调高一点“探索率”,去核心团队感受前沿技术的迭代速度,未必是坏事。即便未来发现一线城市难以长期立足,那也不过是优化过程中的一次正常震荡。梯度下降算法启示我们:有时震荡正是为了跳出当前的局部最优,去寻找更深、更广的谷底。
写在最后:在不确定性中构建渐进一致性
作为一名统计背景的算法工程师,经过这番思考,我有以下几点感悟:
- 不存在绝对的最优解,只存在特定先验和信息条件下的贝叶斯最优决策。
- 核心团队提供的不是确定的成功路径,而是更丰富、高质量的“观测数据”,能帮助你更快地更新对行业和自身的“后验认知”。
- 遗憾边界分析:选择核心团队所带来的最大遗憾通常是有界的(例如,试错成本),而选择安逸的局部最优所带来的潜在遗憾(错过机会)可能是无界增长的。
- 拥抱随机性:既然无法计算出全局最优,那就承认当前的选择只是一个“小批量”的训练步骤,后续还有调整和优化的空间。
- 关注“收敛速度”不如关注“训练心情”:前辈说得对,“只考虑Package,无法支撑你走下去”。真正能提供长期动力的,是工作中的心流体验和成就感。如果热爱钻研技术,可选B;如果偏好结合业务,且珍视家庭生活,可选A。
人生不是Kaggle竞赛,没有公开的排行榜。无论选择A还是B,只要别让自己的“心态梯度”消失,能够持续学习、持续迭代,就是一个好的方向。毕竟,即使是随机游走,只要步数足够多,也能以此为基点,探索到世界的边界。
既然我们无法预知全局最优,那就给自己的人生损失函数加一个 “Dropout” 吧——随机扔掉一部分焦虑,扔掉一部分对完美的执念。
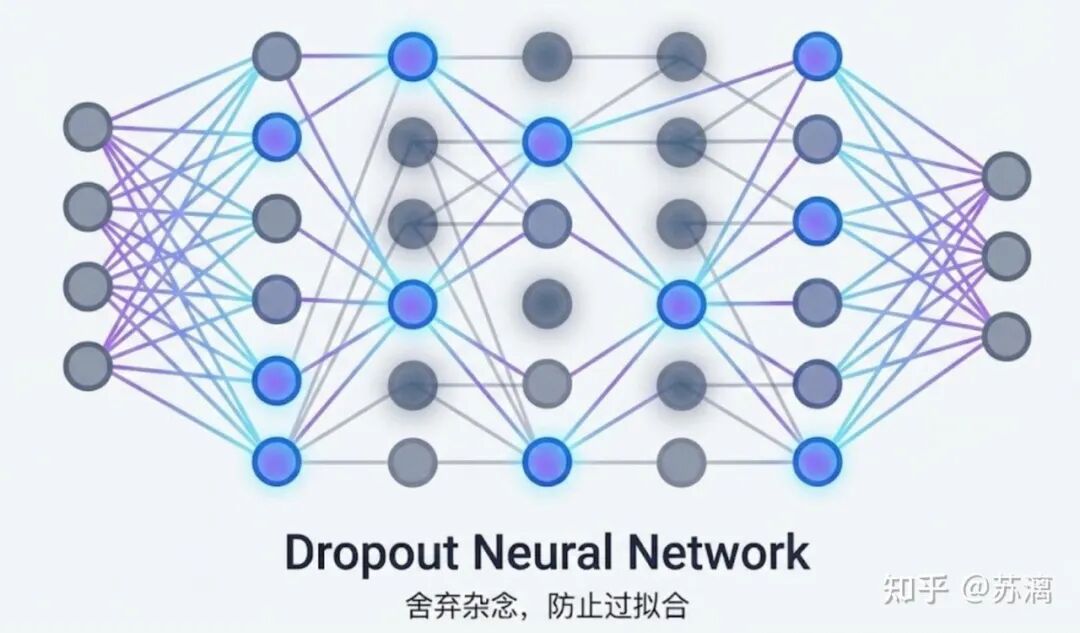
保持心情愉快,才是防止人生“过拟合”于单一价值观的最强正则化项。 无论你的选择是什么,都可以在云栈社区找到更多关于职业规划与人工智能技术发展的讨论与分享。
作者:苏漓
来源:https://zhuanlan.zhihu.com/p/1995099114715763138
 发表于 2026-1-19 19:14:18
|
查看: 188|
回复: 0
发表于 2026-1-19 19:14:18
|
查看: 188|
回复: 0
