Kafka生产级实践:高并发场景如何保证消息零丢失?
Kafka作为现代分布式架构的核心消息中间件,其消息的可靠性直接关系到整个系统的数据一致性。尤其在电商秒杀、实时监控等高并发场景下,如何构建一套从生产、存储到消费的完整防丢失体系,是每一位架构师和开发者必须掌握的技能。本文将深入剖析Kafka消息传递的各个环节,提供一套生产级可用的零丢失保障方案。
生产端:防止消息发送丢失
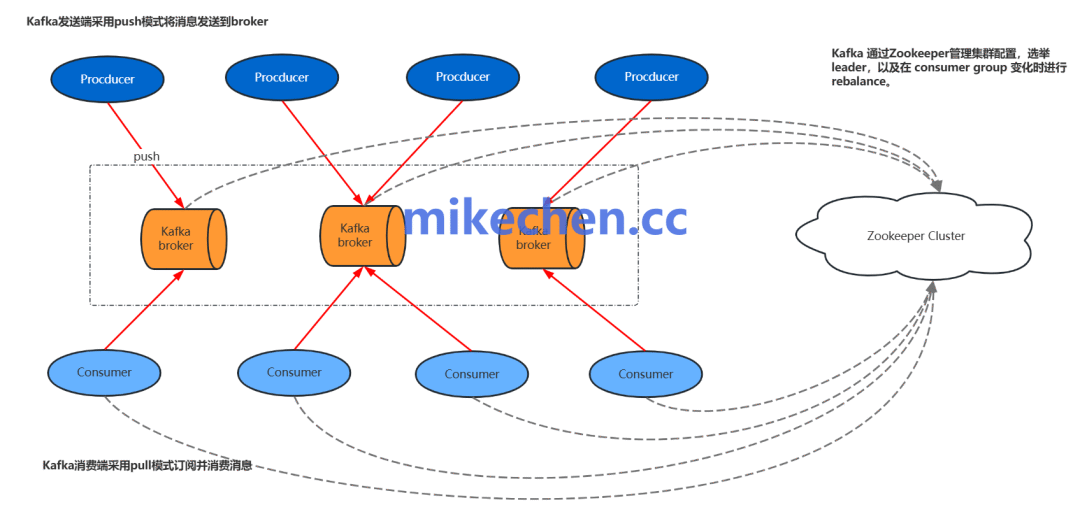
生产端是消息生命周期的起点,也是最容易因网络抖动、Broker故障等原因导致消息“凭空消失”的环节。如何才能确保我们发送的消息成功抵达Kafka呢?
-
同步发送与合理重试:
在发送消息时,优先考虑使用同步发送(send().get()),或者为异步发送配置合理的重试次数(retries参数,通常建议大于3)。这可以应对瞬时的网络故障或Broker Leader选举等场景。但请注意,单纯的重试可能会引入重复消息,因此需要与下一点的幂等性配合使用。
-
启用幂等生产者:
为了避免因重试导致的消息重复,Kafka从0.11版本开始支持幂等生产者。通过设置 enable.idempotence=true,Kafka会为每个生产者实例分配一个唯一ID(PID),并确保每条消息在单分区内具有严格的顺序性和唯一性。这意味着,即使在网络波动导致的重试过程中,同一条消息也只会被Broker成功写入一次,有效解决了因生产者重试带来的数据重复问题。
-
设置可靠的ACK确认机制:
这是生产端防丢失最关键的一环。acks 参数决定了生产者认为请求完成的条件:
acks=0:生产者不等待任何确认,消息发出即视为成功。延迟最低,但数据丢失风险最高。acks=1:默认值。Leader副本写入本地日志即返回成功。如果Leader在Follower同步前崩溃,仍会丢失数据。acks=all(或 acks=-1):生产环境推荐配置。要求分区Leader必须等待所有同步副本(ISR) 都将消息成功写入日志后,才向生产者返回确认。这确保了只要ISR中至少有一个副本存活,消息就不会丢失。
Broker端:防止消息存储丢失
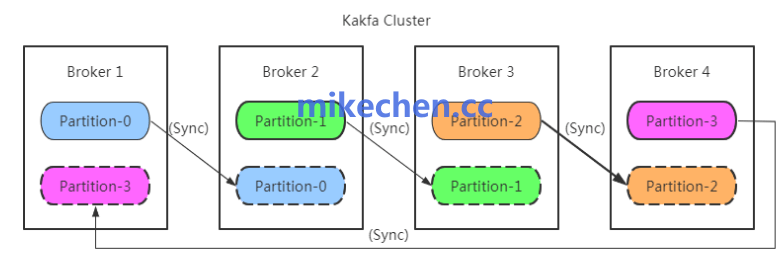
消息成功到达Broker后,我们的目标是在集群内部安全地持久化存储,即使部分节点宕机数据也能完好无损。
-
配置足够多的副本(Replication):
通过设置 replication.factor >= 3,可以为每个分区创建多个副本,并分布在不同Broker上。这样,单个甚至多个Broker故障,只要其他存有该分区副本的Broker正常,数据就是安全的。这是实现高可用和数据冗余的基石。
-
维持稳定的ISR集合与最小同步副本数:
- ISR(In-Sync Replicas):指与Leader副本保持同步的副本集合。我们需要通过监控确保ISR集合稳定,没有副本频繁掉队。
- min.insync.replicas:这个参数与生产端的
acks=all 配合使用,定义了写入成功所需的最少同步副本数。例如,设置 min.insync.replicas=2,结合 acks=all,意味着一次成功写入至少需要Leader和另一个Follower都确认。这样即使Leader立刻宕机,也还有一个最新的同步副本可以选举为新Leader,防止数据丢失。此值通常设置为 replication.factor - 1。
-
合理的日志刷盘(Flush)策略:
Kafka的消息最终需要持久化到磁盘。虽然Kafka依靠操作系统的Page Cache来提升性能,但为了应对机器断电等极端情况,需要权衡性能与可靠性来配置刷盘策略。
log.flush.interval.messages / log.flush.interval.ms:控制强制刷盘的频率。频繁刷盘保证数据安全但影响吞吐。- 生产环境中,通常更依赖
replication 和 min.insync.replicas 来保证数据可靠性,而对刷盘策略采用相对宽松的配置,以换取更高的性能。在极端追求可靠性的场景(如金融交易),可以考虑更激进的刷盘策略或使用支持同步刷盘的硬件/文件系统。
运维与架构保障
除了客户端和Broker的配置,从运维和全局架构层面审视,能为消息的持久化再加一道保险。
-
跨集群数据复制与容灾:
对于核心业务数据,单集群可能无法应对地域性灾难(如整个机房断电)。可以使用 MirrorMaker 或 Confluent Replicator 等工具,将Kafka集群中的数据实时镜像到另一个物理位置的备用集群,实现异地容灾。
-
建立完善的监控与告警体系:
运维的“眼睛”必须时刻明亮。需要重点关注以下监控指标并设置告警:
- ISR变化:监控每个分区ISR副本数量的波动,如有副本被踢出ISR需立即报警。
- Under Replicated Partitions:未完全复制的分区数量,理想情况下应为0。
- Consumer Lag:消费者滞后量,滞后过大可能意味着消费端处理能力不足或存在故障。
- Broker磁盘使用率:避免磁盘写满导致服务不可用。
-
制定数据备份与恢复预案:
对于极其关键的数据,可以考虑定期使用Kafka工具(如 kafka-dump-log)或自研脚本,将特定Topic的数据导出到更安全的长期存储(如对象存储、数据仓库),并定期演练数据恢复流程,真正做到有备无患。
总结
保证Kafka消息在高并发下不丢失,不是一个单一的参数配置,而是一套覆盖 “生产者 -> Broker存储 -> 运维架构” 的端到端体系。核心要点包括:生产者启用 acks=all 和幂等性、Broker端设置多副本与 min.insync.replicas、以及架构上规划容灾与监控。
消息中间件 Kafka 的可靠性是构建健壮的 分布式系统架构 的关键一环。理解并实施上述方案,你的系统在面对流量洪峰时,数据链路将更加坚如磐石。
当然,架构设计永无止境。除了防丢失,如何平衡性能、处理海量积压、优化消费端逻辑等都是值得深究的课题。如果你想了解更多关于高可用架构、微服务或 Kafka 的深度实践,欢迎持续关注云栈社区,与众多开发者一起交流成长。 |  发表于 2026-1-20 00:15:35
|
查看: 203|
回复: 0
发表于 2026-1-20 00:15:35
|
查看: 203|
回复: 0
