关键词
Chiplets、RISC-V、HPC、AI、NoC、Open-Source
据估算,第三代 Ogopogo 的开源实现方案可达到 10.3 DP-TFLOP/s 的峰值性能和 41.1 DP-GFLOP/s/mm²(每平方毫米双精度浮点每秒十亿次运算)的峰值计算密度——当归一化到我们的 7 nm 目标工艺节点时,该密度比英伟达(Nvidia)的 B200 GPU[22]高 19%。

论文信息
本文提出了面向高性能计算(HPC)和人工智能(AI)的开源小芯片(chiplet)基 RISC-V 系统路线图,旨在缩小与专有设计的性能差距。(相关讨论也可在 智能 & 数据 & 云 板块延伸阅读)
背景:为何需要“开源芯粒 + 2.5D”?
AI 与 HPC 的计算需求激增,单芯片封装在面积、良率等方面受限,2.5D 集成成为趋势,但 现有开源设计存在性能短板。
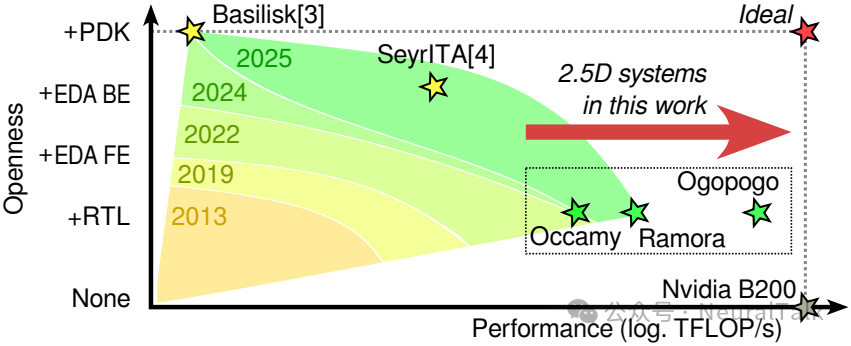
图 1:开放性-性能权衡概览(开源设计提升开放性可能带来性能下降)。本文提出的 Ogopogo,其归一化计算密度已超过 B200 GPU;剩余差距可在一定程度上通过增大芯片绝对尺寸弥补,详见 4.B。
三代系统路线图总览(Occamy → Ramora → Ogopogo)
核心内容围绕三代系统展开:
- 【第一代】Occamy:首个硅验证的 12nm 双小芯片 RISC-V 众核,432 核支持多 ISA 扩展,峰值性能 876 DP-GFLOP/s;但交叉开关互连限制扩展性。
- 【第二代】Ramora:采用 2D 网状片上网络(NoC),同面积集群数增 33%,峰值性能达 1.29 DP-TFLOP/s,D2D 带宽提升 16 倍。
- 【第三代】Ogopogo:7nm 四小芯片概念设计,峰值性能 10.3 DP-TFLOP/s,计算密度超 B200 19%(节点归一化),并新增三类数据移动加速扩展。
此外,论文还探索开源边界扩展,包括仿真、EDA 工具、PDKs 等,并指出先进工艺开源 PDK 缺乏和开源 PHY 设计是主要挑战。
本文目录
- 关键问题
- 问题 1:开源 PDK 与 PHY 瓶颈下,全栈开源目标是否沦为空谈?生态主导地位能否实现?
- 问题 2:不依赖工艺迭代与尺寸扩大,架构与 NoC 设计是否存在性能天花板?更大规模集群协同能否实现?
- 一、引言
- 1.1 Occamy——首款基于芯粒的系统
- 1.2 Ramora——第二代双芯粒系统
- 1.3 Ogopogo——一款概念架构
- 本文的贡献
- 二、OCCAMY:双芯粒硅验证原型
- A. 架构
- B. 实现
- C. 验证
- D. 与当前最先进技术的对比与讨论
- 三、RAMORA:一种可扩展的跨芯粒网状架构
- 3.A 架构
- 3.B 实现
- 3.C 评估
- 3.D 与最先进水平(SoA)的对比与讨论
- 四、OGOPOGO:一种四芯粒概念架构
- 4.A 架构
- 4.B 评估与最先进水平(SoA)对比
- 五、迈向端到端开源芯粒
- 5.1 仿真(Simulation)
- 5.2 电子设计自动化(EDA)
- 5.3 工艺设计套件(PDKs)
- 5.4 芯粒外物理层(Off-die PHYs)
- 六、结论
- 参考文献

关键问题
问题 1:开源 PDK 与 PHY 瓶颈下,全栈开源目标是否沦为空谈?生态主导地位能否实现?
论文中 Ogopogo 虽实现节点归一化计算密度超英伟达 B200 19%,但依赖 TSMC 7nm 商业 PDK 和专有高速 PHY 设计,而先进工艺开源 PDK 缺乏、开源 PHY 设计难是明确瓶颈。若无法突破这两大封闭性限制,开源小芯片 RISC-V 系统即便在性能上追平专有设计,是否永远只能停留在“可替代方案”而非“生态主导者”,且其“全栈开源”的核心目标是否会沦为空谈?
论文明确将“先进工艺开源 PDK 缺乏”和“开源高速 PHY 设计难”列为全栈开源的核心瓶颈(第五节),但并未否定全栈开源的可行性,而是给出分阶段推进的实践路径。因此,“全栈开源沦为空谈”的结论并不成立;生态主导地位更依赖“混合演进 + 瓶颈突破”的双轨策略。
从当前进展看,团队已在低先进度工艺中验证端到端开源的可能性:基于 IHP 130nm 开源 PDK 实现 Basilisk SoC(第三节),并通过 Yosys(逻辑合成)、OpenROAD(布局布线)等开源 EDA 工具完成 22nm 节点集群架构的初步实现(第五节)。对于先进工艺(如 Ogopogo 采用的 TSMC 7nm),团队采取 “核心逻辑开源 + 非核心组件过渡” 的策略——逻辑核心(集群、NoC、DMA)保持全开源 RTL,而 PHY、HBM 控制器等依赖商业 IP 的组件,通过“开源工具适配”逐步替代:例如 Verilator 等开源模拟器已支持核心逻辑的 RTL 仿真,混合信号 PHY 的开源设计也已通过 Efabless 流程验证可行性(第五节)。
生态主导地位的关键不在于“100%无商业组件”,而在于“开源核心的可替代性与兼容性”。
- 论文提出的 Open Chiplet Architecture 兼容标准(引言)使开源芯粒可与商业 chiplet 混搭,降低生态接入门槛;
- Ogopogo 在节点归一化计算密度上超越 B200 19%(第四节)为开源核心提供“性能话语权”。长期看,若先进工艺 foundry 开放成熟节点 PDK,且开源 PHY 在带宽、能效上追平商业产品,开源小芯片有机会从“可替代方案”升级为“生态主导者”;
- 即便短期难以突破瓶颈,“开源核心 + 标准化接口”仍可在学术研究、定制化 HPC 等细分市场形成优势。
问题 2:不依赖工艺迭代与尺寸扩大,架构与 NoC 设计是否存在性能天花板?更大规模集群协同能否实现?
Ramora 通过 2D mesh NoC 解决了 Occamy 交叉开关的扩展性问题,Ogopogo 进一步扩展为四小芯片架构并新增数据移动加速,但对比 B200 40 DP-TFLOP/s 的峰值性能,Ogopogo 10.3 DP-TFLOP/s 的性能仍依赖“增大芯片面积”的粗放式 scaling。请问在不依赖工艺节点迭代和单纯扩大芯片尺寸的前提下,现有 RISC-V 小芯片的集群架构、NoC 设计是否存在根本性的性能天花板?其数据移动加速方案能否支撑 8 小芯片及以上更大规模系统的高效协同,而非陷入延迟累积或带宽浪费?
论文通过三代架构演进证明:不依赖工艺迭代与尺寸扩大,RISC-V 小芯片确实存在“由架构优化驱动的性能上限”,但该上限远未触及。 Ogopogo 的设计也为 8 小芯片及以上规模协同提供了支撑,数据移动加速方案可用于缓解延迟累积与带宽浪费。
首先,性能天花板并非由架构“本质”决定,而更多由“互连效率 + 数据移动开销”的平衡关系定义。Ramora 用 2D mesh NoC 替代 Occamy 的交叉开关,在相同芯粒面积下实现 33% 集群数量提升、16 倍 D2D 带宽增长(第三节),说明互连架构优化是突破“尺寸依赖”的关键路径。Ogopogo 进一步引入三个数据移动加速扩展(in-router collectives、in-stream DMA、packed irregular streams),将 NoC 带宽利用率提升 4.8 倍(不规则流场景)、数据处理延迟降低 32 倍(元素级缩放场景)(第四节),把系统瓶颈从“算力堆叠”转向“数据高效流动”。
对于更大规模(8 小芯片及以上)协同,Ogopogo 架构预留扩展性:16×8 mesh NoC 支持跨芯片的静态路由与虫洞转发,D2D 接口通过 LVDS PHY 实现 2.05 Tb/s/链路的带宽扩展(第四节),且路由器 fork/join 原语可直接处理跨芯片广播、barrier 同步,无需端点干预,从而减少大规模协同中的延迟累积。论文测算,若将 Ogopogo 从 4 小芯片扩展至 8 小芯片,仅需增加边缘 D2D 链路数量(保持单芯片架构不变),峰值性能可线性提升至 20.6 DP-TFLOP/s,HBM 总带宽同步扩展至 6.56 TB/s,未出现明显带宽瓶颈或延迟激增。
综上,架构与 NoC 的性能天花板是“动态可扩展”的:通过互连优化、数据移动加速、标准化接口,开源芯粒可在不依赖工艺与尺寸的前提下持续提升上限。(关于 NoC/互连与体系结构基础概念,可参考 计算机基础)
一、引言
人工智能(AI)和高性能计算(HPC)领域中激增的计算需求与快速增长的数据集,正逐渐超越技术缩放所带来的性能与内存带宽提升。随着技术缩放速度放缓,这一差距不断扩大,系统设计者正转向规模越来越大、功能越来越专用的架构,以满足性能与能效需求。然而,单芯片封装已成为瓶颈,在面积、良率和互联性方面限制了设计空间[1]。
这些限制推动行业向 2.5D 集成转型:在 2.5D 集成架构中,多个独立芯粒通过中介层实现短距离、细间距互联。2.5D 系统的良率、规模和芯粒间(D2D)带宽远超单芯片封装,为进一步架构扩展提供可能。正如“开放芯粒架构(Open Chiplet Architecture)”[2]所提出的,标准化接口与生态系统将使芯粒成为可互换的构建模块,从而实现更深度的架构专用化,并持续提升性能与能效。
开放、可组合的芯粒生态系统理念与开源硬件目标天然契合[3]。开源芯粒有望成为未来 2.5D 系统的重要构建模块,并带来设计高透明度、低集成成本以及低设计协作门槛等优势[1]。
图 1:开放性-性能权衡概览
当前开源设计的主要短板在于性能有限:如图 1 所示,已通过硅验证的开源系统与当前最先进(SoA)系统之间存在显著性能差距,且随着开放性程度的提升,这一差距会进一步扩大。采用开源 EDA 工具(如 SeyrITA[4])设计的系统最多仅包含少数处理单元;而 Basilisk[3](采用开源 PDK 的端到端开源设计)也仅集成单个核心。为推动开源芯粒普及并充分发挥其优势,设计者必须研发具备竞争力的开源芯粒设计,缩小性能差距。
本文提出面向 HPC 与 AI 工作负载的 开源 2.5D RISC-V 众核处理器演进路线图,目标是在优先保障高计算利用率、高能效与高计算密度的前提下,持续逼近 SoA。
1.1 Occamy——首款基于芯粒的系统
研究始于 Occamy[5]:首款经硅验证的开源 2.5D RISC-V 众核处理器。Occamy 包含 432 个计算核心,支持多种 ISA 扩展,可处理混合规则性计算,峰值性能达 876 DP-GFLOP/s。在规则工作负载上峰值 FPU 利用率达 89%,在不规则工作负载上峰值 FPU 利用率达 42%–83%。
尽管 Occamy 的计算架构被证明极具效能,但其基于集中式交叉开关的互联结构,限制了架构向更大规模系统的扩展。
1.2 Ramora——第二代双芯粒系统
为解决扩展性,提出 Ramora[6]:第二代双芯粒系统,采用可扩展、低开销的 2D mesh NoC。Ramora 在相同芯粒面积下集群数增加 33%,峰值时钟频率提升 11%,计算密度提高 43%,峰值性能达到 1.29 DP-TFLOP/s,并支持 16 倍速的 1.04 Tb/s D2D 接口。
尽管具备这些优势,仍可通过扩展计算网格并加速 NoC 中的数据传输进一步优化。
1.3 Ogopogo——一款概念架构
基于上述洞见提出 Ogopogo:概念架构,将 Ramora 计算网格扩展为 7 nm FinFET 工艺的四芯粒、四 HBM3 系统,峰值性能达 10.3 DP-TFLOP/s。除峰值性能与计算密度的大幅提升外,Ogopogo 引入三项轻量级扩展以加速 NoC 常见通信模式:打包不规则流、流内 DMA 操作、路由器内聚合操作。其节点归一化计算密度超过 B200 GPU 19%。
在此基础上,论文将关注点转向提升 2.5D 设计开放性:除开源 RTL 逻辑核心外,还探索开源仿真、开源 EDA、开源 PDK 乃至开源片外 PHY 的可行路径。
本文的贡献
- 回顾 Occamy(第二节):经硅验证的双芯粒、双 HBM2E、12 nm FinFET RISC-V 众核处理器,峰值性能 876 DP-GFLOP/s,并讨论其基于分层交叉开关互联的扩展性局限。
- 提出 Ramora(第三节):以 2D mesh NoC 将集群铺砌为可扩展互连,在相同芯粒面积下集群数 +33%,D2D 链路速度 +16 倍,峰值性能 1.29 DP-TFLOP/s。
- 提出 Ogopogo(第四节):7 nm 四芯粒、四 HBM3 概念架构,峰值性能 10.3 DP-TFLOP/s,并引入三项轻量级数据传输扩展;归一化计算密度超过 B200 19%。
- 探索如何提升未来芯粒架构的开放性(第五节):从开源 RTL 扩展到开源仿真、开源 EDA、开源 PDK 与片外 PHY。
二、OCCAMY:双芯粒硅验证原型
Occamy[5] 是首款经硅验证的开源 2.5D RISC-V 众核处理器。
- 系统包含两个 12 nm FinFET 计算芯粒,位于 65 nm 被动式中介层上;每个芯粒搭配 16 GiB HBM2E DRAM,并通过全数字 D2D 链路互联。
- 432 个 RV32G 计算核心支持多种 ISA 扩展,可处理稀疏计算与混合精度计算:
- 稠密工作负载峰值 FPU 利用率 89%
- 稀疏工作负载峰值 FPU 利用率 42%–83%
这些核心被组织为 48 个集群,通过分层交叉开关互联,并采用基于 DMA 的数据传输方式。
A. 架构
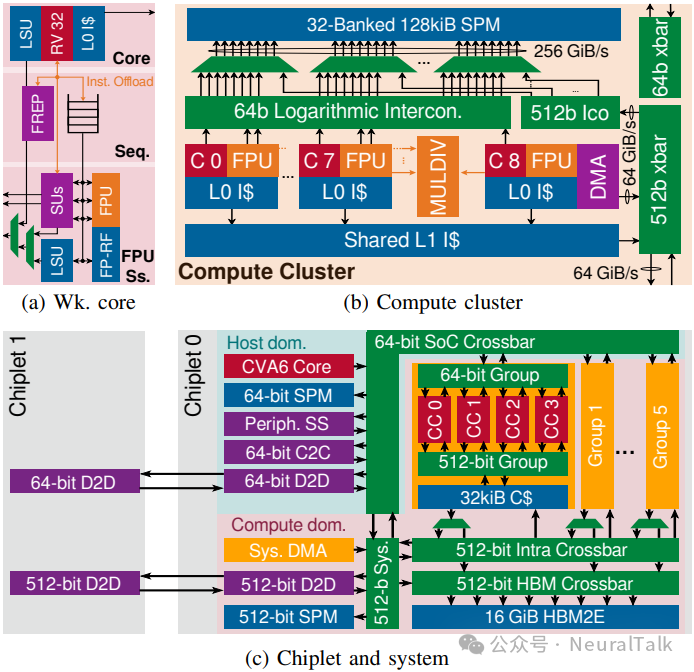
图 2:Occamy 的分层架构。(a)工作核心;(b)计算集群;(c)芯粒与系统
图 2b 展示 Occamy 的计算集群:每集群包含 8 个工作核心与 1 个 DMA 控制核心,共享 32 存储体、128 KiB SPM 与 8 KiB L1 指令缓存。
如图 2a,每个工作核心配备 64 位宽 SIMD FPU,支持 FP8 到 FP64 的精度转换;除标准乘加外,还支持 widening sum-dot-product 与 three-addend summation[9]。两项 ISA 扩展用于最大化规则/不规则负载的 FPU 利用率:浮点硬件循环[7]与三个支持稀疏性的流处理单元[8]。
三个流处理单元支持对共享 SPM 的 4D 步幅访问以加速规则负载;其中两个还支持带 8 位到 32 位索引的间接流,适配 scatter-gather 访问。它们还能协同加速稀疏张量交并集运算,并可输出联合索引。每核心流处理单元对共享 SPM 的 sustained bandwidth 可达 24 B/s。
DMA 控制核心配备 512 位 DMA 引擎[10],支持外部内存与集群 SPM 的异步二维及以下传输,用于协调细粒度低延迟 SPM 访问与对延迟不敏感的 DMA 批量传输(双缓冲 tile)。为减少互联背压,DMA 引擎可同时访问 8 个存储体的连续块,每周期传输高达 64 字节。
图 2c 展示芯粒级架构,包含计算域与主机域。计算域分为 6 组,每组 4 集群;组内通过两个 AXI4 交叉开关实现全带宽访问(512 位用于 DMA/指令缓存;64 位用于原子/同步/消息传递)。在芯粒级,交叉开关桥接 64 位与 512 位网络并提供对系统 DMA、系统 SPM 与 D2D 端口的访问。主机域以支持 Linux 的 RV64GC CVA6 核心[11]为核心。
D2D 链路包含 64 位窄段与 512 位宽段,两段均将 AXI4 事务序列化为 AXI-Stream 传输;每个 PHY 为全数字、源同步双工接口。宽段配备通道分配器以实现容错:可检测并禁用故障 PHY。窄段与宽段有效双工带宽分别可达 1.33 Gb/s 与 64 Gb/s。
B. 实现
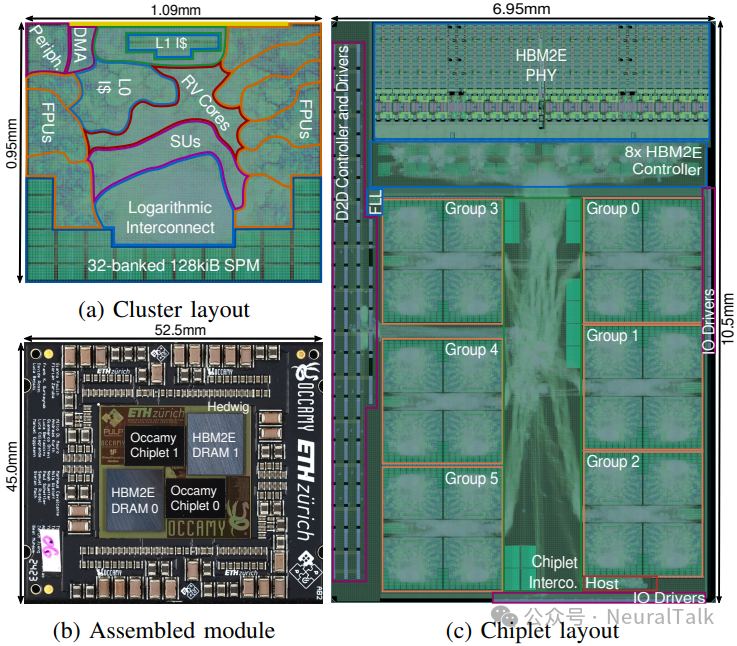
图 3:Occamy 的物理实现。(a)集群布局;(b)组装模块;(c)芯粒布局
完整 2.5D Occamy 系统与载板一同制造,形成图 3b 所示计算模块。两个计算芯粒(各搭配美光 Micron MT54A16G808A00AC-32 HBM2E)安装在 GlobalFoundries 的 4 层 65 nm 被动式中介层(PKG-25SI,“Hedwig”)上。
计算芯粒采用 GF 12 nm LP+ FinFET 工艺,使用 Synopsys Fusion Compiler 进行设计,采用 Arm 7.5 轨标准单元,并集成 Rambus 的 HBM2E IP(控制器与 PHY)。标称计算时钟目标 1 GHz:典型条件 0.8 V、25 °C 时可达 1.14 GHz;最坏条件 0.72 V、125 °C 时可达 0.95 GHz。
集群面积 1.0 mm × 1.0 mm,主要由 9 个计算核心(44%)与 SPM(17%)占据。顶层芯粒布局面积主要由计算组(39%)、HBM2E 接口(25%)与 D2D 链路(11%)占据。
C. 验证
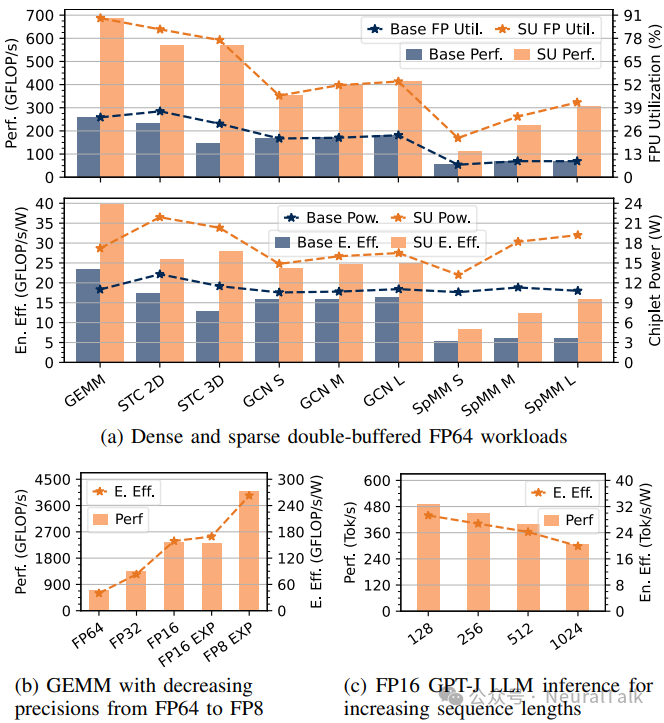
图 4:Occamy 的性能、功耗与能效结果。(a)FP64 双缓冲负载;(b)不同精度 GEMM;(c)FP16 GPT-J 推理吞吐与能效
在多种稠密、稀疏与混合规则性工作负载上验证 Occamy 的性能、功耗与能效,对比启用/未启用流处理单元(SU)加速,验证基于标称 1 GHz 与典型条件(25 °C、0.8 V)。
图 4a:在规则性降低的 FP64 工作负载上:
- SU 将稠密 GEMM 加速 2.7 倍,FPU 利用率接近理想值(89%),性能 686 GFLOP/s,能效 39.8 GFLOP/s/W
- 模板计算(STC)加速 3.9 倍,FPU 利用率 83%,性能 571 GFLOP/s,能效 28.1 GFLOP/s/W
- GCN 层加速 2.3 倍,FPU 利用率 54%,性能 413 GFLOP/s,能效 25.0 GFLOP/s/W
- 稀疏-稠密矩阵乘法加速 4.6 倍,FPU 利用率 42%,性能 307 GFLOP/s,能效 16.0 GFLOP/s/W
图 4b:不同精度 SU 加速 GEMM:
- 精度降低带来性能/能效提升,但存在轻微转换与打包开销
- FP8(带扩展累加)吞吐 4.1 QP-TFLOP/s,能效 263 QP-GFLOP/s/W
- FP16 GEMM:带扩展累加模式能效高 6.5%(得益于扩展点积单元[9])
图 4c:SU 加速 FP16 GPT-J 推理(非自回归),基于文献[12]实现并采用 FlashAttention2:
- 序列长度 128 token:峰值吞吐 490 tok/s,能效 29.3 tok/s/W
- 随序列长度增加,吞吐与能效下降(注意力计算二次方缩放、softmax 时间占比上升)
D2D 链路验证:
- 16 KiB 传输任务中,64 Gb/s 宽段利用率 96%,能效 1.6 pJ/b
- 窄段主机访问另一个芯粒主机 SPM:延迟 27 周期;宽段 DMA 传输:延迟 61 周期
D. 与当前最先进技术的对比与讨论
Occamy 是通用系统,能高效处理宽稀疏度范围内的单侧与双侧稀疏操作,并具备数据流灵活性。峰值性能远超多数 RISC-V 学术原型,与 Sophon SG2042[13]等商业产品相当。
在稠密负载上,Occamy 的 FPU 利用率(89%)与 SoA CPU/GPU 持平,能效与 A100[14]大致相当。在模板代码上,SU 使其 FPU 利用率比 A100 高 1.7 倍[15],面积效率比 A100 高 1.2 倍[16]。在稀疏-稠密线性代数任务上,FPU 利用率比领先竞品高 5.2 倍[17],节点归一化面积效率高 11 倍[18]。
但扩展性问题逐渐显现:计算域 31% 面积用于交叉开关,仅 65% 面积用于计算核心。交叉开关面积随 requestor 与 endpoint 数量乘积增长,会压缩可用于计算的面积;集中式架构带来全局布线变长与拥塞;也会限制片外带宽(尤其与高带宽 D2D、HBM2E 同时集成时实现难度陡增)。
因此,下一代采用 mesh-based NoC 更适合大规模系统:规模线性扩展,分布式路由,易于邻接拼接。
三、RAMORA:一种可扩展的跨芯粒网状架构
Ramora[6] 保留 Occamy 高效集群架构,但采用二维网状 NoC 降低互连开销并提升可扩展性。
与 Occamy 相比,Ramora 在相同芯粒面积上实现:
- 集群数量 +33%
- 时钟速度 +11%
- 计算密度 +43%
- 峰值性能 1.29 DP-TFLOP/s
其 0.15 pJ/B/hop 的 NoC 在低/高流量下将 HBM2E 带宽利用率分别提升 11% 和 22%,并适配改进后的四端口 D2D 链路架构,实现 16 倍提升的 1.04 Tb/s 宽数据带宽。
3.A 架构
Ramora 采用 FlooNoC[6]:宽链路网状 NoC,可对窄(64 位)与宽(512 位)AXI4 事务进行串行化处理。每链路包含三条静态路由物理通道:单向 req 与 rsp 通道传输请求与 64 位数据,双向宽通道传输 512 位批量数据。FlooNoC 提供带/不带 ROB 的两种 NI;无 ROB 的 NI 必要时会暂停传出请求以保证顺序,因此需要请求源具备乱序处理能力以维持吞吐。
Ramora 复用 Occamy 集群设计,并为集群扩展集成式 NI 与路由器,使其能拼接为网状结构(图 5a)。集群 NI 不含 ROB:为避免 ROB 面积开销,DMA 引擎扩展为可将传输任务分配到多个后端[10]以支持乱序处理。集群路由器五端口全互连,支持多种静态路由算法与虫孔路由,并对三个物理通道分别路由以确保网络级隔离。
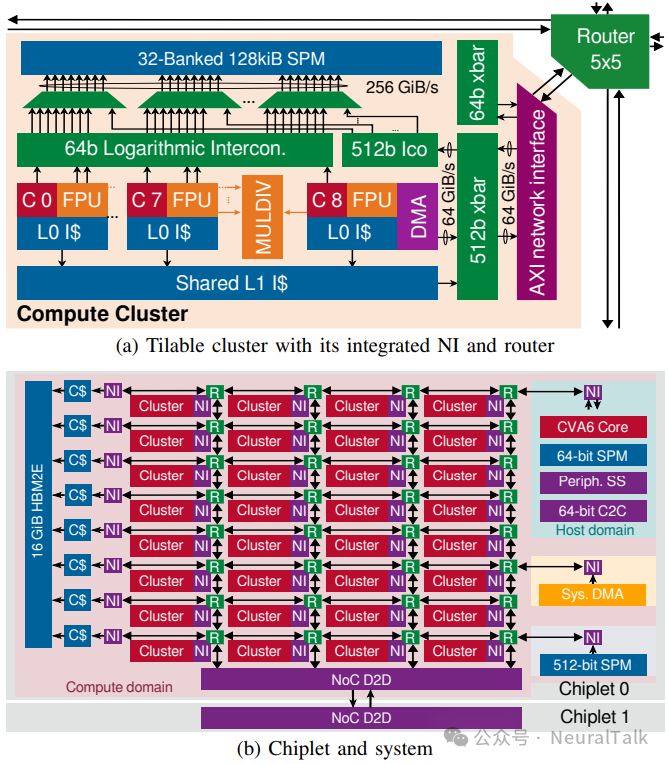
图 5:Ramora 采用分层架构
图 5b 展示 Ramora 计算芯粒:NoC 显著降低面积开销,使得在不增加芯粒面积情况下,将每芯粒集群数从 24 增至 32,并排列为 8×4 网格。左边缘连接 8 个 HBM2E 控制器(各自通过独立 NI 与 32 KiB 常量缓存接入 NoC);右边缘连接主机域、1 MiB 系统 SPM 与系统 DMA;底边缘通过四条 NoC 链路将改进后的 D2D 接口连接到另一个芯粒。
网状 NoC 更高边缘带宽,使吞吐更高的 D2D 接口成为可能:用串行 4 Gb/s LVDS PHY 替代 Occamy 并行 D2D PHY。保持 D2D 宏单元面积 9.6 mm²,为每个 NoC 链路的宽通道、req、rsp 分别提供 96 对、20 对、18 对 PHY,并适配数字 PHY 前端以直接传输 NoC flit,形成跨两个芯粒的虚拟 16×4 网状结构。总体而言,Ramora D2D:宽传输 1.04 Tb/s,有效全双工;窄传输 137 Gb/s,有效全双工。
3.B 实现
在 GF 12 nm LP+ 工艺中实现 Ramora 的集群与计算域,并基于这些模块估算完整芯粒实现方案。使用 Synopsys Fusion Compiler 进行综合、布局布线,采用 Arm 7.5 轨标准单元并复用 Occamy 的 HBM2E 接口。标称 1 GHz:典型条件 1.26 GHz,最坏条件 0.85 GHz。
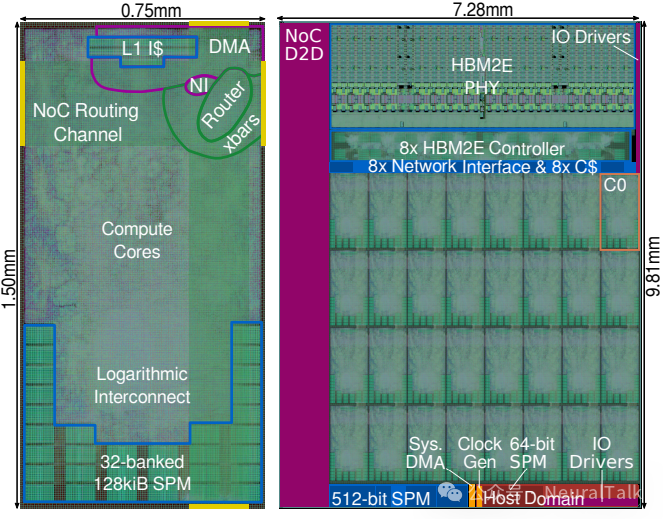
图 6:Ramora 的物理实现
图 6a:为匹配 HBM2E 接口高度,将集群宽高比调整为 2:1;为容纳路由器、NI 与多后端 DMA 扩展,集群面积增加 8.6%。NoC 链路在顶层金属层布线,利用逻辑与存储宏单元上方空闲资源。图 6b:为预留时钟树与全局控制信号布线空间,集群 tile 间留出小间隙并通过间隙连接 NoC 链路;同时估算并分配主机域、系统 SPM、HBM2E 粘合逻辑与芯粒外互连等模块面积,并维持 D2D 链路 9.6 mm²。最终芯粒面积 71 mm²,与 Occamy 几乎相同(仅小 2.1%),但实现 33% 计算能力提升与 16 倍宽传输 D2D 带宽提升。
3.C 评估
评估片内延迟、HBM 带宽利用率与峰值性能,并与 Occamy 对比。由于共享同一计算集群架构,评估重点放在 Ramora 的 NoC 优势。
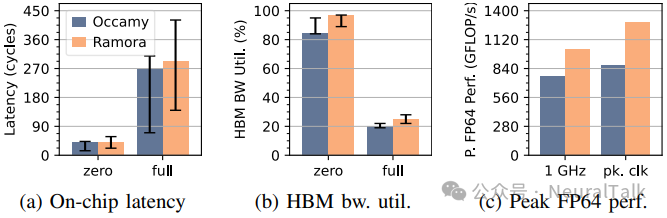
图 7:Ramora 与 Occamy 的集群间延迟、HBM 带宽利用率及峰值 FP64 性能对比(误差线为跨集群范围)
- 延迟(图 7a):Ramora 以适度延迟增加换取可扩展性。无负载平均延迟比 Occamy 低 0.4%;满负载平均延迟仅高 8.4%。
- HBM 带宽利用率(图 7b):满负载峰值利用率 25%(四集群共享 512 位链路)。无负载平均利用率从 84.7% 提升至 96.6%;满负载平均从 20.2% 提升至 24.8%。
- 峰值性能(图 7c):1 GHz 下峰值从 768 GFLOP/s 提升至 1024 GFLOP/s;在各自典型条件峰值频率下,Ramora 从 876 GFLOP/s 提升至 1290 GFLOP/s。
NoC 能效:布局后仿真中,一个空闲集群通过 DMA 向相邻 tile 传 4 KiB 数据;集群 tile 总功耗 128 mW,其中仅 15% 来自参与传输组件;路由器功耗 596 pJ,实现 0.15 pJ/B/hop。
3.D 与最先进水平(SoA)的对比与讨论
与 Piton[19]、Celerity[21]、ESP[20] 等二维网状 NoC 系统对比:
- Ramora 具备最高单向瓦片间带宽与能效,分别比第二名高 2.6 倍和 3.0 倍;
- NoC 功耗占比比 ESP 低 4.0 倍;面积开销仅次于 Piton(但 Piton 带宽更低且更窄);
- 同等先进工艺仅 ESP;峰值时钟超过 Ramora 的仅 Celerity。
论文认为:Ramora 的宽链路、低开销设计在带宽与能效上达到领先,但仍可进一步扩展网状规模、增加边缘链路以提升 HBM/D2D 带宽,并通过为集群/路由器/端点增加专用硬件降低 NoC 通信开销,从而同时提升性能与能效。
四、OGOPOGO:一种四芯粒概念架构
Ogopogo 是采用 7 nm 工艺的四芯粒概念架构,将 Ramora 的计算网格扩展到 8 倍峰值性能。
该架构引入三项轻量级扩展以提升数据移动效率:
- 路由器内集合通信(in-router collectives)
- 流内 DMA 操作(in-stream DMA operations)
- 打包式非规则流(packed irregular streams)
为支撑更高边缘带宽,Ogopogo 将内存从 HBM2E 升级到 HBM3,使每芯粒带宽翻倍。
据估算,Ogopogo 的实现方案可达到 10.3 DP-TFLOP/s 峰值性能与 41.1 DP-GFLOP/s/mm² 峰值计算密度;当归一化到 7 nm 目标工艺节点时,该密度比 B200 GPU[22]高 19%。
4.A 架构
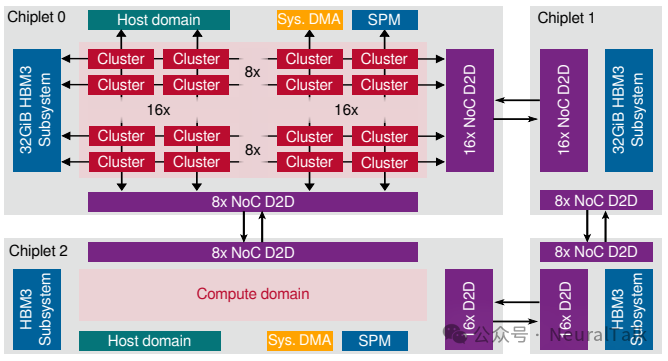
图 8:Ogopogo 芯粒与系统架构
图 8 展示 Ogopogo 概念架构:
- 每个 7 nm 芯粒包含 16×8 计算网格,复用 Ramora 的可扩展 NoC,并引入数据移动扩展技术;
- 网格左边缘配备 6.4 Gb/s/pin 的 HBM3 接口,更高带宽与并行度服务所有 16 个边缘路由器;
- 网格底边缘与右边缘复用 Ramora LVDS PHY 的 D2D 链路,为相邻芯粒提供 1.02 Tb/s 与 2.05 Tb/s 宽传输带宽;
- 网格顶边缘连接主机域、系统 DMA、系统 SPM 与芯粒外互连;主机域更新为 Cheshire 平台[23],支持多核主机、多端口 NoC 连接与额外外设。
三项轻量级硬件扩展:
- 路由器内集合通信:扩展 fork/join 原语,使 NoC 在路由器内部处理多播、广播、屏障同步等集合通信。实现多播/广播时,请求在路径上分支复制,响应在返回路径合并汇总;实现屏障同步时,路由器先合并在途请求,再将响应分支回所有源。开销适中:路由器面积增加 <10%,且不影响时序。
- 流内操作:为集群 DMA 引擎扩展流内向量单元,可实时执行按元素操作与归约(加/乘缩放、求和、按位与等)。一个 64 位整数流内单元仅增加 80 kGE 面积,却能将元素缩放加速 32 倍、算术归约加速 12 倍。
- 打包式非规则流:为 DMA 与 HBM3 端点扩展打包/解包,使 strided 与 indexed 流紧密打包到宽 NoC flit 中,提升非规则负载的链路利用率与有效吞吐。集群侧可生成并行窄(≤64 位)请求流,最多 8 个请求打包到一个宽数据帧;HBM 侧解包并通过 temporal coalescer 合并为最小 256 位访问。161 kGE 打包单元可将随机索引 scatter-gather 的带宽效率提升 4.8 倍,理论上最高 8 倍。
4.B 评估与最先进水平(SoA)对比
基于完整集群实现(Fusion Compiler)、Ramora 现有 D2D PHY 以及 B200 GPU[22]的 HBM3E 接口,在 TSMC 7 nm FinFET 工艺中估算 Ogopogo 计算芯粒面积与时序。尽管数据移动扩展带来显著性能优势,但总面积占比仅 5.3%。
估算显示:每芯粒面积 112 mm²,典型条件可运行至 1.26 GHz;系统峰值性能 10.3 DP-TFLOP/s,峰值计算密度 41.1 DP-GFLOP/s/mm²。
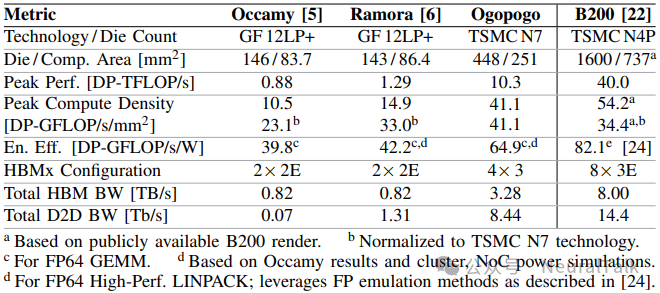
表 1:2.5D 多核设计从 Occamy 到 Ogopogo 的演进,以及与 B200 GPU 的对比
为提供更全面参考,论文还基于 Occamy 的硅片实测与集群/NoC 功耗仿真,估算 Ramora 与 Ogopogo 的 FP64 GEMM 能效:
- Ogopogo 峰值性能分别是 Ramora 与 Occamy 的 8.0 倍和 11.8 倍;计算密度分别是两者的 2.8 倍和 3.9 倍;能效分别高 54% 和 63%。
- 尽管 Ogopogo 峰值性能无法与 B200(芯片尺寸为 Ogopogo 的 3.6 倍)相比,但即便采用相对落后的工艺节点(TSMC N7 vs. N4P),其计算密度与能效也仅比 B200 低 24% 和 21%。
论文强调:当归一化到 7 nm 工艺节点时,Ogopogo 计算密度比 B200 高 19%;总 HBM 与 D2D 带宽分别是 Ramora 的 4.0 倍与 6.4 倍,与 B200 处于同一水平。由此,论文将重心转向 2.5D 设计的开放程度。
五、迈向端到端开源芯粒
迄今为止,芯粒设计主要提供逻辑核心的可综合开源 RTL 描述。
但如果将后续设计阶段资源也开放共享,将进一步增强开源硬件优势:提升透明度、降低集成成本、减少协作壁垒。端到端开源设计(无需任何专有工具或 IP 即可复现)甚至能支持第三方进行零信任逐步验证[3]。因此,本节讨论提升 2.5D 设计开放程度的路径。
5.1 仿真(Simulation)
目前设计仍依赖商业仿真工具(如 Synopsys VCS),因其稳定性与功能完整性更强。开源仿真工具(Verilator、Icarus Verilog)仍受限于可扩展性,且对 SystemVerilog、testbench、门级结构支持不足。
不过开源工具在快速改进:Verilator 已能对逻辑核心进行基本 RTL 仿真,对断言检查与门级结构(如 UDP)支持也在开发中,未来有望实现完全基于开源工具的 RTL 与门级仿真。
5.2 电子设计自动化(EDA)
目前实现方案使用商业 EDA,其性能明显优于开源替代品。
但 Yosys(综合)与 OpenROAD(布局布线)在功能集与 QoR 上持续提升,逐步缩小与商业工具差距[3]。论文已在端到端开源 130 nm SoC 中验证 Cheshire 主机平台[3],并正使用开源 EDA 在 22 nm 节点实现集群架构[4]。因此,在成熟工艺节点上完全采用开源 EDA 实现完整逻辑核心,有望在近期成为可能。(更多 EDA/流程类资料可参考 技术文档)
5.3 工艺设计套件(PDKs)
近年来已有多个可制造工艺的开源 PDK 与开源标准单元库发布,包括 GF 180 nm、SkyWater 130 nm、IHP 130 nm,以及 ICsprout 55 nm。论文已在 IHP 开源工艺中验证主机子系统[3]。
但 ≥55 nm 的成熟节点难以满足 ≤12 nm 计算芯粒这类高复杂度设计需求。先进工艺开源 PDK 的缺失并非设计者能单方面解决,仍高度依赖代工厂开放策略。
5.4 芯粒外物理层(Off-die PHYs)
DRAM 与 D2D 接口的高速 PHY 可能是扩展开放性的最大障碍:数模混合设计需要专业能力,且与 EDA 工具和目标 PDK 高度耦合。现有开源 SoC 常通过较慢的全数字接口规避问题[3,23]。原则上基于开源 PDK 的数模混合设计可行,Efabless 的模拟设计流程[25]已证明这一点;因此开源 PHY 长期有望实现,但会受限于开源 EDA 与开源 PDK 的性能水平。
结论是:随着开源仿真与 EDA 逐步逼近 SoA,先进工艺开源 PDK 缺失与开源 PHY 的固有挑战将成为提升芯粒开放程度的主要瓶颈。
六、结论
本文提出面向 HPC 和 AI 工作负载的开源芯粒式 RISC-V 多核处理器演进路线图,目标是缩小与商用芯片的性能差距。
- Occamy:双芯粒、双 HBM2E、12 nm FinFET,峰值 876 DP-GFLOP/s;规则负载峰值 FPU 利用率 89%,不规则负载 42%–83%,验证集群式计算架构有效性。
- Ramora:以 0.15 pJ/B/hop 2D mesh NoC 替代交叉开关,在不增面积下峰值达 1.29 DP-TFLOP/s;计算密度、高负载 HBM 带宽与宽传输 D2D 带宽分别提升 43%、22%、16 倍。
- Ogopogo:7 nm 四芯粒、四 HBM3 概念架构,峰值 10.3 DP-TFLOP/s;引入路由器内集合通信、流内 DMA、打包式非规则流等轻量扩展;归一化计算密度比 B200 高 19%,同时具备相近能效与芯粒外带宽。
论文分析表明:开源 2.5D 设计的数字核心可以扩展到最先进水平。若继续追求端到端开源芯粒,仍需解决两大瓶颈:先进工艺开源 PDK 的缺失与开源 PHY 设计挑战。
参考文献(原文配图)


如需在社区内继续讨论芯粒、RISC-V 与 HPC/AI 架构演进,可访问一次:云栈社区。
 发表于 2026-1-20 16:32:33
|
查看: 319|
回复: 0
发表于 2026-1-20 16:32:33
|
查看: 319|
回复: 0
