适用范围
- 数据库版本:Oracle 11.2.0.4
- 操作系统版本:Linux x86_64
- 数据库架构:单机+文件系统(非归档模式)
问题概述
客户一套测试环境在清理日志时发生误操作,删除了两组 redo log 文件。其中一组日志状态为 active,并且客户随后自行重启数据库并尝试 clear 日志组,这导致在线日志文件彻底丢失。数据库实例因此无法以 OPEN 状态启动,而丢失的测试数据正是客户急需的。
问题原因
本次问题的根源在于客户误操作。如果在仅删除在线日志文件后不重启数据库实例,对应的文件句柄依然存在,通过文件复制即可恢复。但客户重启了实例,导致文件被彻底从磁盘上删除,只能通过非常规方式进行开库操作,数据丢失在所难免。与客户充分沟通并描述潜在后果后,在征得客户同意的前提下,决定使用隐含参数 _allow_resetlogs_corruption 进行非一致性恢复,强制打开数据库。
解决方案
环境检查与准备
首先检查数据库环境,确认为单机文件系统架构,运行在非归档模式。数据文件总大小约 40GB,但存储空间不足,无法进行全量备份。因此,先备份现有的 redo 日志和控制文件。在检查确认 redo 日志序列不连续后,将现有的 redo log 文件移走,为后续执行 open resetlogs 命令做好准备。
修改隐含参数
修改关键隐含参数,并重启数据库至 mount 状态使参数生效。这类 数据库故障处理 操作需要谨慎评估风险。
alter system set "_allow_resetlogs_corruption"=true scope=spfile;
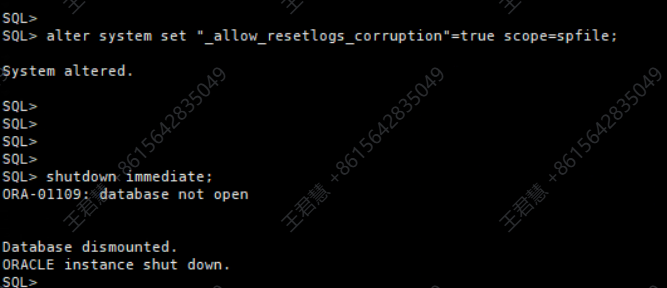
shutdown immediate;
startup mount;
resetlogs开启数据库尝试
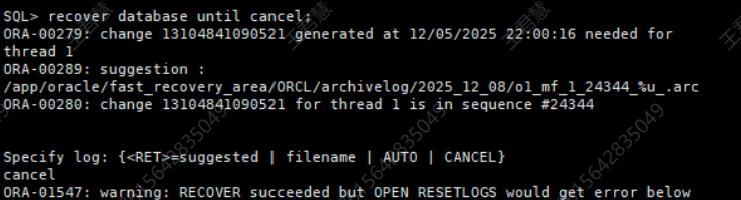
执行 recover database until cancel 命令。对于 resetlogs 开库方式,需要先触发恢复动作,但并不需要(也无法)真正应用归档日志。
recover database until cancel;
输入 cancel 中止恢复。
随后尝试以 resetlogs 方式打开数据库:
alter database open resetlogs;
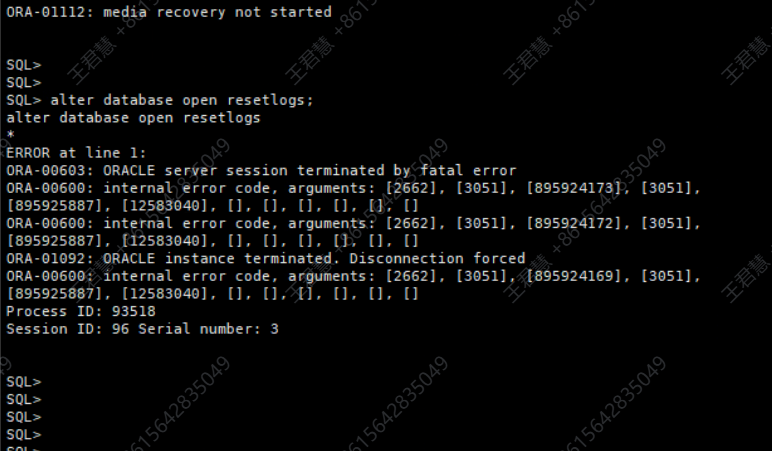
命令执行后报出 ORA-00600 [2662] 内部错误。这是一个在强制开库场景下比较常见的错误,原因在于当前系统的 SCN(系统更改号)与数据块中记录的 SCN 不一致。错误参数中,第二个地址代表当前SCN,第四个地址是数据块SCN,第五个地址是数据块地址。通常,如果两者相差不大,通过多次重启数据库,SCN 会逐步推进,可能解决问题。本例中两者相差不到2000,因此直接选择重启实例。
重启开库
重新启动数据库实例后,SCN 得以推进,数据库成功打开。
startup;
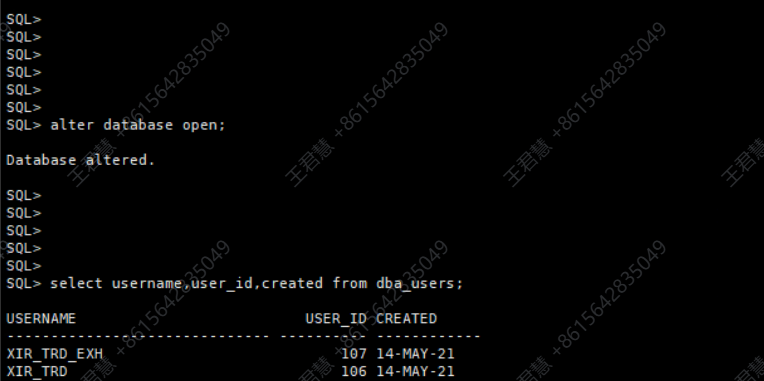
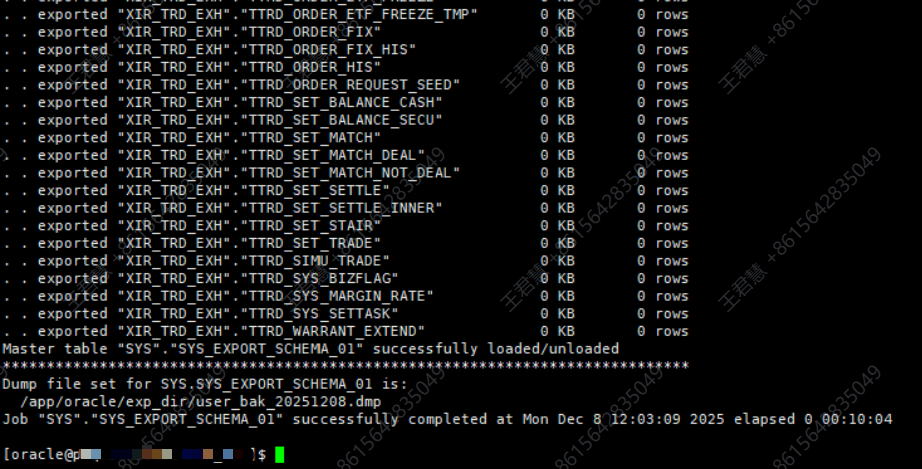
逻辑导出所有需要的用户数据
为防止后续重启再次出现不可预知的问题,立即通过逻辑导出工具备份所有关键用户的数据。这是数据恢复后的重要运维安全步骤。
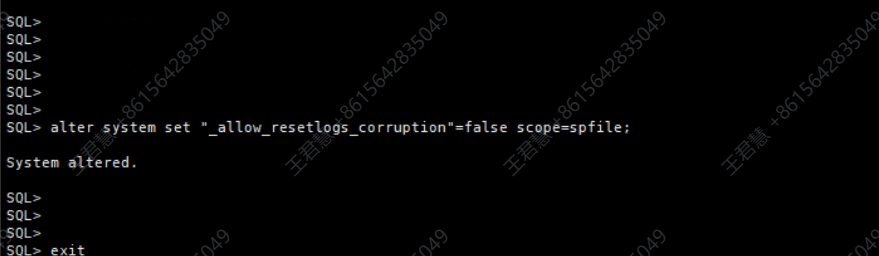
改回隐含参数并重启数据库
数据导出完成后,将之前修改的隐含参数改回默认值,并正常重启数据库,使数据库回到标准参数设置下运行。
alter system set “_allow_resetlogs_corruption“=false scope=spfile;
shutdown immediate;
startup;
检查数据库告警日志,确认无异常信息,至此恢复工作成功完成。
总结
本次故障主要由客户误操作引发,在删除在线日志后又重启数据库实例,导致文件物理丢失。在客户接受可能的数据丢失后果后,采用隐含参数进行非一致性开库,逻辑导出全部数据,最终恢复了数据库实例的正常运行。处理完成后,强烈建议客户将数据迁移至一个全新的、状态正常的数据库实例,以确保长期稳定性。
本文涉及到的恢复操作具有高风险性,请在充分理解原理、评估影响并做好备份的前提下,于测试环境先行验证。欢迎在 云栈社区 交流更多数据库运维与故障处理经验。
 发表于 2026-1-20 18:56:20
|
查看: 234|
回复: 0
发表于 2026-1-20 18:56:20
|
查看: 234|
回复: 0
