
在理解了 MySQL 的整体架构之后,很多人会继续追问:一条查询 SQL 从发出去到拿到结果,中间到底经历了哪些环节?每一步是谁负责、会做哪些关键决策?
下面以一条最常见的查询为例,按 客户端 → Server 层 → 存储引擎层 的链路,把 MySQL 中一条 SQL 的执行路径拆开说明。
SQL 执行流程图
为了聚焦核心流程,这里将 MySQL 简化为三层:客户端、Server 层、存储引擎层(暂不展开系统文件层)。
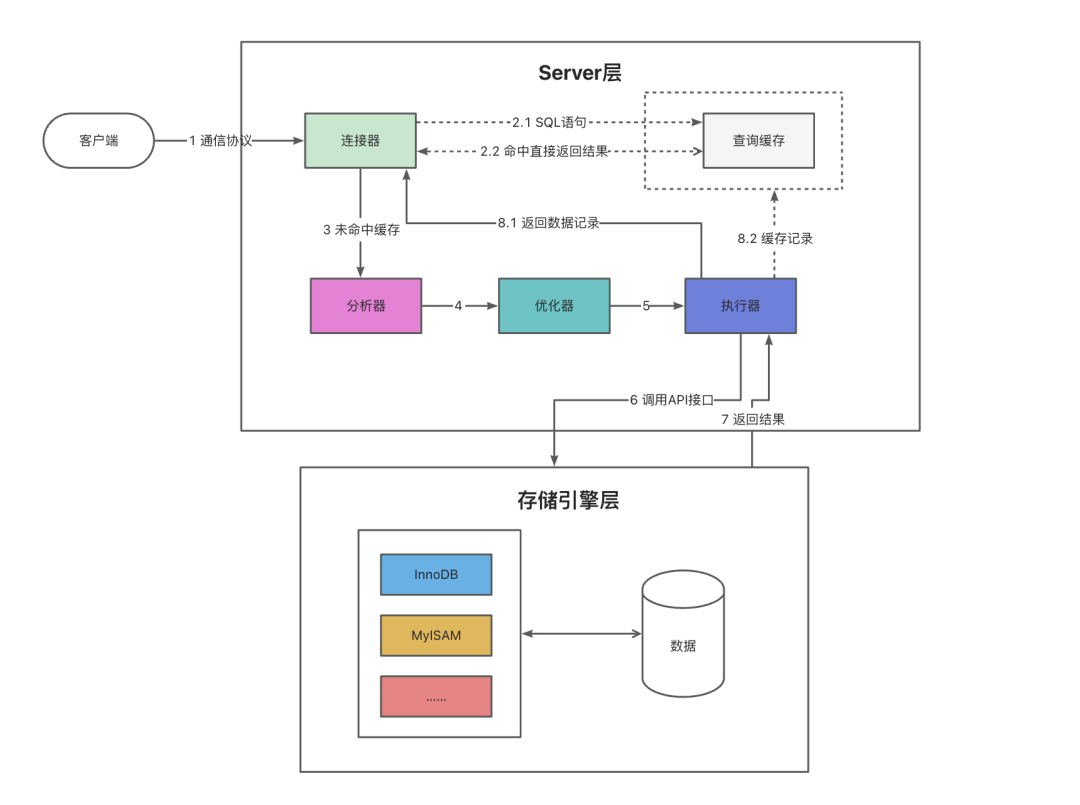
图:SQL执行流程图
结合流程图,下面按步骤分析 MySQL 中 SQL 执行的完整过程。
客户端
客户端可以是图形化工具、命令行,或各类编程语言的驱动/类库。以如下 SQL 为例:
SELECT * FROM users WHERE id = 1;
在执行 SQL 之前,客户端会先与 MySQL 服务器建立连接,需要提供用户名、密码等参数。随后由 MySQL 的连接器完成身份认证与权限获取。
如果使用的是长连接,那么在连接有效期内,即便管理员修改了该用户的权限,也不会立刻影响这个连接里后续的权限判断;只有重新建立连接时,才会读取最新权限。
由于数据库连接属于稀缺资源,实践中通常会配合长连接与连接池来提高连接复用率。
连接器
连接器负责两件事:
- 管理客户端与 MySQL 的连接(会话)
- 做认证与权限校验
客户端发来 SQL 后,连接器会先验证身份与权限;一旦连接建立,后续所有权限判断都基于此时读到的权限信息,因此连接期间权限变更不会即时生效。
为了避免频繁创建/销毁线程带来的性能损耗,MySQL5.5 引入了线程池:缓存已创建的线程,让少量线程服务大量连接。
连接器还会处理一些常见问题,例如:
- 用户名/密码不正确:提示类似 “Access denied for user”
- 连接长时间未使用(默认 8 小时)被断开:客户端再次发请求时可能收到 “Lost connection to MySQL server during query”
在 MySQL 8.0+ 中,当连接器建立连接成功后,会将 SQL 请求交给 Server 层的分析器与优化器(更早版本中,中间还可能经过查询缓存这一步)。
查询缓存(MySQL 8.0 已移除)
在 MySQL 早期版本(MySQL 8.0 之前),为了提高查询响应速度,会缓存特定 SQL 的整个结果集。当有完全相同的 SQL 语句再次请求时,直接从缓存返回结果。
执行到这一步时,MySQL 会把示例 SQL 拿去查询缓存中查找:如果命中缓存,就直接返回结果给客户端;如果未命中,则继续后续流程。
但多数场景不建议依赖查询缓存,因为它的失效频率非常高:当表发生 INSERT、UPDATE、DELETE 等更新时,会自动清除该表相关缓存,避免返回过期结果。写操作频繁时,缓存反而容易带来额外开销。
因此,MySQL 官方从 MySQL 5.6 开始默认禁用查询缓存,并在 MySQL 8.0 中删除了该功能。
分析器(Parser)
分析器的任务是:把 SQL 语句从文本转换为 MySQL 可理解的结构化表示,并检查语法与基本合法性。一般包含以下环节。
1. 词法分析(Lexical Analysis)
词法分析会把 SQL 字符串拆成“词法单元”(Tokens),例如关键字、表名/列名、运算符、常量等。
对 SELECT * FROM users WHERE id = 1;,会拆解为:
SELECT —— 标识符,表示查询动作* —— 通配符,表示查询所有字段FROM —— 标识符,表示查询来源表users —— 表名WHERE —— 标识符,表示过滤条件id —— 列名称= —— 条件运算符1 —— 整型字面值; —— SQL 语句结束符
拿到 Tokens 后,分析器会继续处理它们之间的结构关系。
2. 语法分析(Syntax Analysis)
语法分析会根据 MySQL 的 SQL 语法规则检查结构是否正确,并构建语法树(Parse Tree)。语法树用于描述 SQL 的层次结构及各组件之间的关系。
对 SELECT * FROM users WHERE id = 1;,语法树通常包含:
- 根节点:表示这是一个
SELECT 查询
- 子节点:字段列表(
*)、表名(users)、过滤条件(id = 1)
如果语法不符合规则(例如缺少必要成分),分析器会报错并终止执行。
3. 合法性检查
分析器阶段还会做基础检查,例如:
- 表
users 是否存在
id 列是否存在于 users 表中* 是否有效(通常表示所有列)
完成解析与检查后,分析器会生成 SQL 的内部结构表示,并交给下一步的 优化器(Optimizer)。
优化器(Optimizer)
优化器的职责是:生成高效的查询执行计划,决定“怎么查更省”。
它会基于 SQL 结构与表的元数据(表结构、索引信息等),评估多种执行方案并估算代价,选出成本最低的路径。
以 SELECT * FROM users WHERE id = 1; 为例,优化器可能在以下方案中选择:
- 全表扫描(Full Table Scan):如果
users 表没有合适索引,可能需要扫描整张表逐行判断 id = 1。代价较高,但对小表或无索引场景可能是唯一选择。
- 索引查找(Index Lookup):如果
users.id 上有索引(尤其是主键/唯一索引),可直接定位到目标记录,通常成本更低。
优化器会利用存储引擎提供的统计信息(例如行数、索引选择性)来估算成本。如果 id 是唯一值,往往会更偏向索引查找。
当表存在多个索引时,优化器还需要决定用哪个索引;当涉及多表查询(如 JOIN)时,还要决定表的访问顺序与连接方式(例如 Nested Loop Join、Index Nested Loop Join、Hash Join 等)。
如果 SQL 带有 ORDER BY 或 LIMIT(本例没有),优化器还会考虑:
- 是否可使用索引满足排序,减少额外排序成本
- 是否可使用覆盖索引,避免回表
- 是否需要临时表
最终,优化器会输出执行计划,内容通常包括:
- 使用哪些索引
- 扫描范围
- 是否需要排序/临时表
- 多表读取顺序(若有)
- 结果返回路径
想直观看到优化器的选择,可以用 EXPLAIN 查看执行计划:
EXPLAIN SELECT * FROM users WHERE id = 1;
注意:优化器只负责“制定计划”,不负责真正“读数据”;实际读取由执行器驱动存储引擎完成。优化器也不会直接控制存储引擎缓存(例如 InnoDB 的 Buffer Pool)。
执行器
执行器按优化器生成的计划执行,并通过存储引擎接口逐步读取数据。
典型过程如下:
- 执行器确定目标表(这里是
users),并与对应存储引擎交互:例如表使用 InnoDB,则调用 InnoDB 的引擎接口。
- 真正执行前,执行器会再次检查当前用户是否拥有对
users 表的查询权限(SELECT 权限)。若无权限,直接报错终止。
- 根据执行计划向存储引擎发起读请求:
- 如果计划使用索引,则按索引定位记录
- 否则按全表扫描逐行读取
- 对存储引擎返回的数据逐行处理:判断是否满足条件。本例中检查
id = 1,满足则加入结果集,否则跳过。
在索引查找场景下,很多无关记录可能已在引擎侧过滤掉,因此这一步会更轻。
- 将结果返回客户端:
- 执行器持续向引擎请求记录
- 每获取一条就可以立即传给客户端(流式返回),不一定要等完整结果集构建完
- 所有数据处理完毕(或达到
LIMIT 上限)后结束
如果你想进一步系统理解与排查这类链路问题,可以在 MySQL 相关主题下按“连接/解析/优化/执行”维度梳理与讨论。
小结
以 SELECT * FROM users WHERE id = 1; 为例,MySQL 的执行流程可以概括为:
- 客户端:发起 SQL 请求,将
SELECT * FROM users WHERE id = 1; 发送到服务端
- 连接器:建立连接、认证身份、读取并固化会话权限
- 查询缓存:MySQL 8.0 之前可能检查是否命中缓存;8.0 已移除此功能
- 分析器:词法/语法分析生成语法树,并做基础合法性检查
- 优化器:评估多种路径并选择成本最低的执行计划(索引/扫描、连接顺序等)
- 执行器:按计划调用存储引擎读取数据,逐步返回结果给客户端
 发表于 2026-1-20 19:21:56
|
查看: 296|
回复: 0
发表于 2026-1-20 19:21:56
|
查看: 296|
回复: 0
